导读:本系列是Spark系列分享的第三期。第一期分享了Spark Core的一些基本原理和一些基本概念,包括一些核心组件。Spark的所有组件都围绕Spark Core来运转,其中最活跃的一个上层组件是Spark SQL。第二期分享则专门介绍了Spark SQL的基本架构和原理。从第三期开始,后续的分享都围绕着Spark SQL展开,尤其是Spark SQL的优化。Spark作为一个常用的批处理大数据引擎,在各大公司的这个业务线上,存在于离线计算及一些机器查询的场景,而这些场景下最常用的方式就是兼具易用性和学习门槛低等特点的 Spark SQL。今天的分享是关于解析层及其优化,解析层处于Spark SQL处理流程的第一个阶段,和后续将要分享的优化内容相比,较为简单且易于大家理解。
本次分享主要分为五个部分:
-
产品介绍
-
Spark SQL解析层原理
-
优化案例
-
总结
-
Q&A环节
一、产品介绍
首先介绍数新网络与Spark SQL相关的两个主要产品。
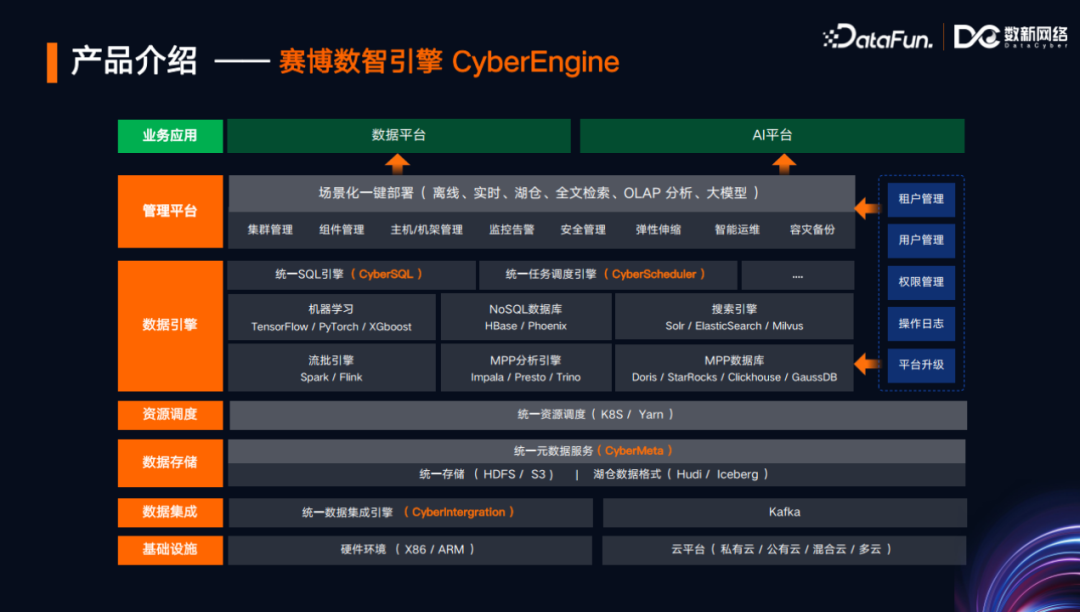
第一个是CyberEngine,也叫Cyber数智引擎。Cyber数智引擎旨在构建一个基于云原生的数据湖底座,可以支持用户更好地去分析和挖掘数据,提升自身在市场和商业上的竞争力。Spark自从开源以来很快成为大数据领域的事实标准,CyberEngine支持对Spark SQL的管理。数新网络基于Spark SQL实现了统一的SQL查询平台,即CyberSQL。

另一个Spark相关产品是CyberData。CyberData是一个数据开发平台,基于批流一体、湖仓一体、数智一体,支持公有云、私有云、混合云,并且支持各种大数据文件格式,包括结构化、半结构化和非结构化数据,在此基础上,提供了各种数据治理、数据服务、数据调度和数据开发的能力。
二、Spark解析层原理
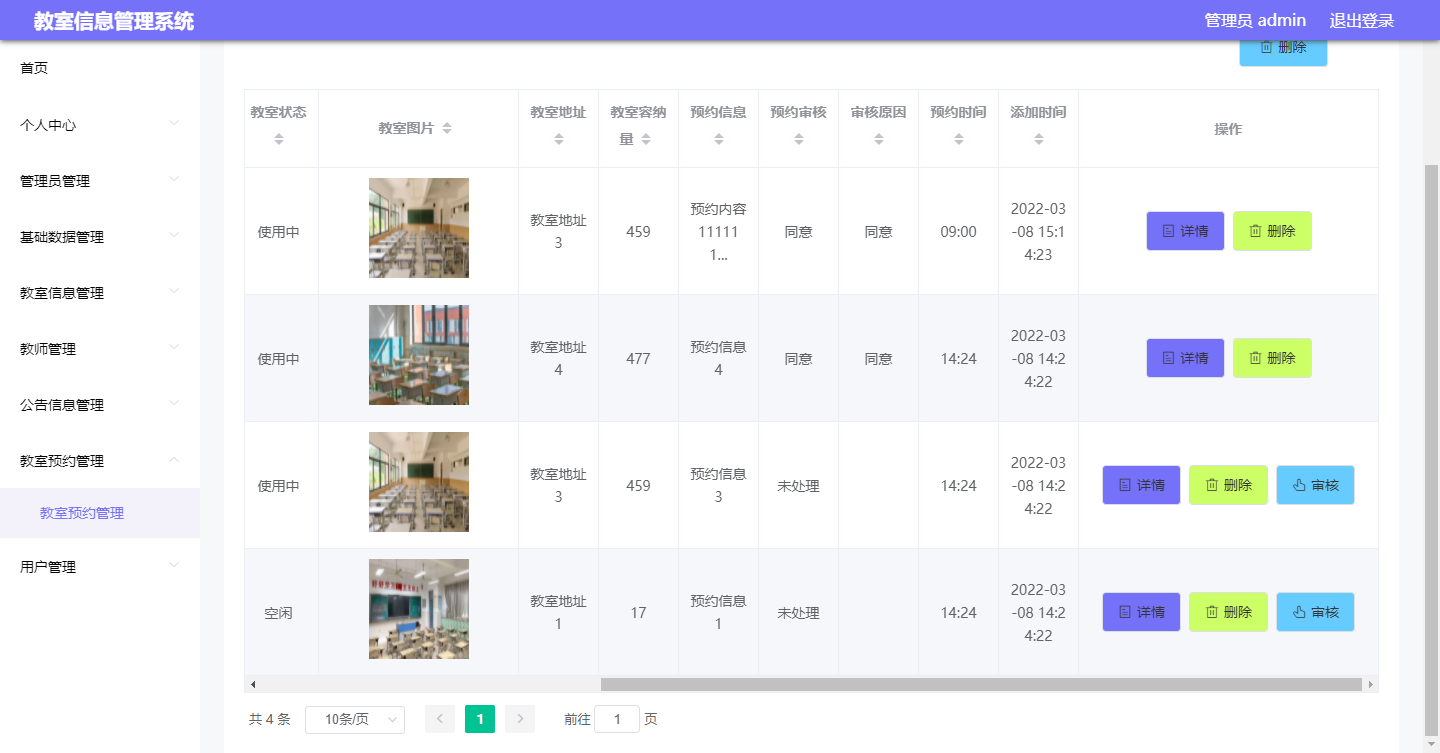
1. Spark SQL执行流程
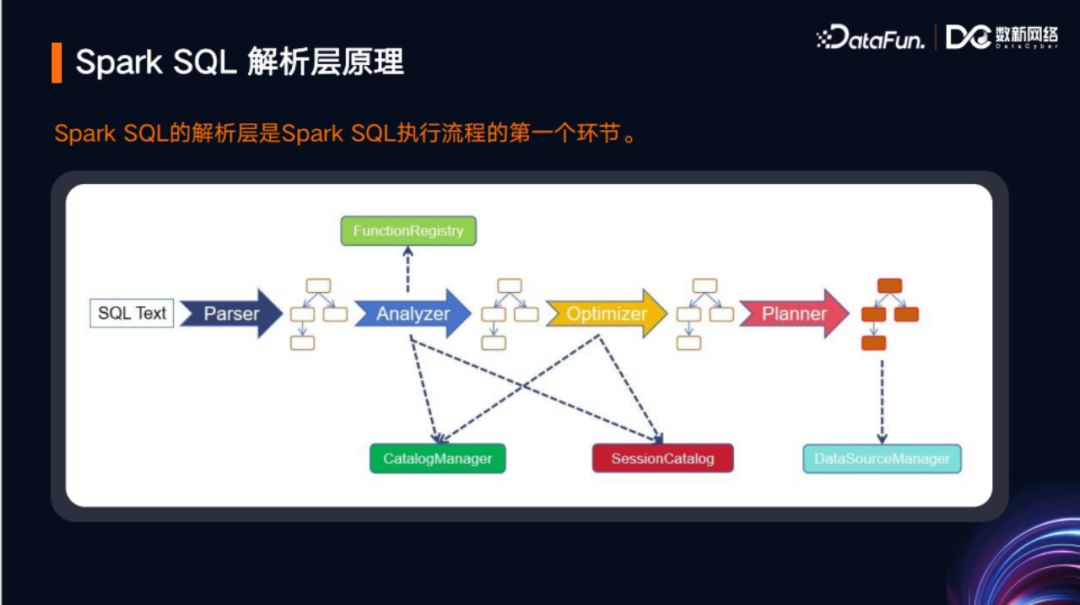
Spark SQL的执行流程经过了解析层、优化层、执行计划层,直到最后成为真正可执行的物理进程(例如JVM进程或Native进程)。执行流程的第一步就是解析层,解析层中的Spark SQL Parser作为最前端的组件,该组件封装了很多子组件,其中很多是基于 ANTLR 实现的。在此基础上,Spark SQL 实现了对 SQL 的解析。
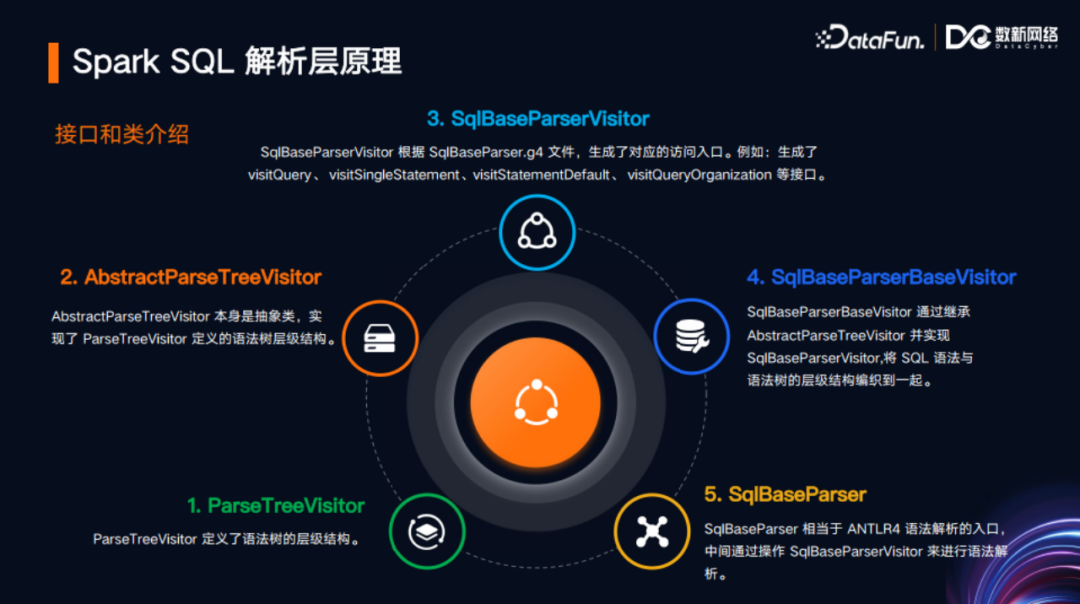
2.ANTLR4编译生成的核心接口和抽象实现
ANTLR4 对SQL语言提供支持,首先需要定义语法模板。ANTLR4语法模板的以.g4作为文件后缀名。例如上图中,简要截取了Spark SQL自定义的SqlBaseLexer.g4和SqlBaseParser.g4这两个.g4文件。在早期,只存在一个.g4文件,即SqlBaseParser.g4文件,该文件包含了词法分析的定义和语法分析的模板。后来Spark社区为了对其在定义上进行解耦,以及便于易于维护,将其分为两个文件。SqlBaseParser.g4文件,需要引用词法分析里定义的一些变量和函数,包括一些token(例如SELECT关键字、ANTLR4的GC文件中定义的函数和变量名)。

首先介绍词法分析,即左边绿色文件的主要内容。该文件包含一个members作用域,定义了很多在Parser代码中复用的变量和函数,此外文件还包含了一些Token定义(例如SELECT、FROM等关键字),在上图中已省略。其次介绍语法分析,即右边蓝色文件主要内容,内容中options引用了左边文件的词法分析的内容,members作用域定义了一些变量和函数,其中还包含了语法定义(如DQL、DEL、DML、Spark SQL自定义语法等等)。

以上是SqlBaseParser.g4文件的摘要。为了便于分享展示,从2000行代码中挑选了最易于理解、最关键的语法定义片段。下图展示的是SQL查询语句的语法定义,其中包括了singleStatement、statement、query、queryOrganization等语法块。ANTLR4对其进行编译之后,会生成一些接口和抽象类实现,开发者针对这些接口和抽象类,可以实现自定义的操作。
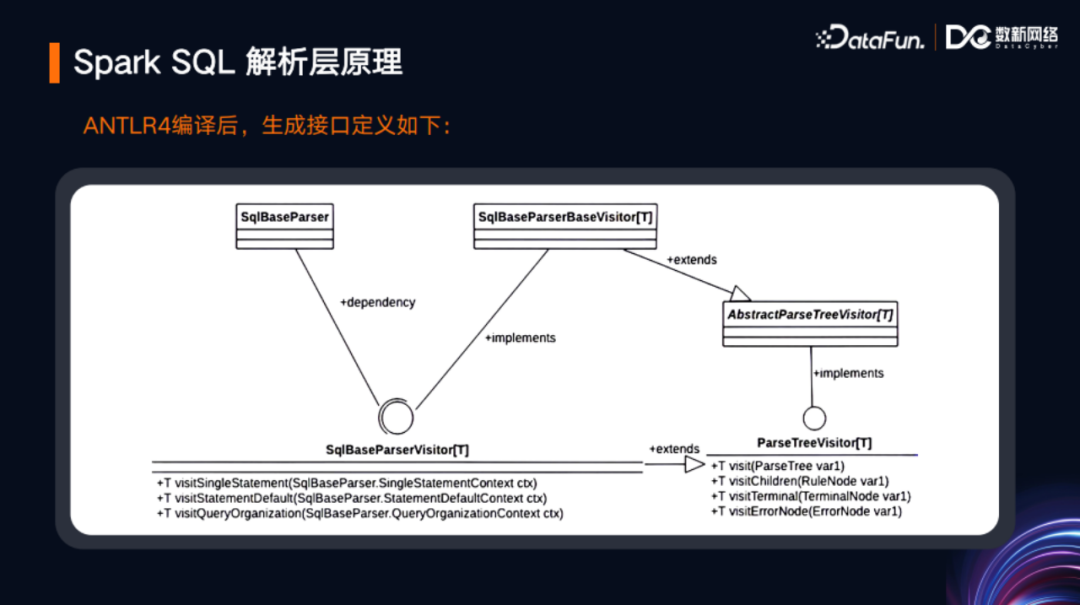
ANTLR4,SqlBaseParser.g4文件进行编译之后,会根据文件名生成SqlBaseParser抽象类。该抽象类封装了一些组件,其中有一个ParseTreeVisitor,即一个的访问者模式的树结构接口,在该接口上有一个抽象的实现,即AbstractParseTreeVisitor,在这个抽象的实现下,有一个更具体的子类SqlBaseParserBaseVisitor。然后在SqlBaseParserBaseVisitor的基础上,有一个更进一步的实现,即SqlBaseParserVisitor。其中关键点在于,ParseTreeVisitor接口里面中定义了visitChildren等方法,这些方法定义了树的父子层级的访问模式。SqlBaseParserVisitor继承了该接口,并定义了更多的抽象,例如visitSingleStatement,这其实就与SqlBaseParser.g4文件中定义的语法块名相关。这些抽象就需要第三方开发者(如Spark)来具体实现。SQL解析入口是SqlBaseParser,当Spark接收到SQL文本之后,先传递给SqlBaseParser,调用其方法,然后传递给ANTLR4去生成抽象语法树(AST)。以下两张图是对上述整个过程的总结。
3.Spark SQL解析核心实现类
前文讲到了SqlBaseParserBaseVisitor,Spark在其最新代码中的实现是DataTypeAstBuilder。在此前的代码中,AstBuilder直接实现了SqlBaseParserBaseVisitor,后来为了代码的优雅性,其实现切换为了DataTypeAstBuilder,AstBuilder则是继承了DataTypeAstBuilder。DataTypeAstBuilder中实现了与类型相关的一些方法,例如类型访问、单独数据类型访问等等。
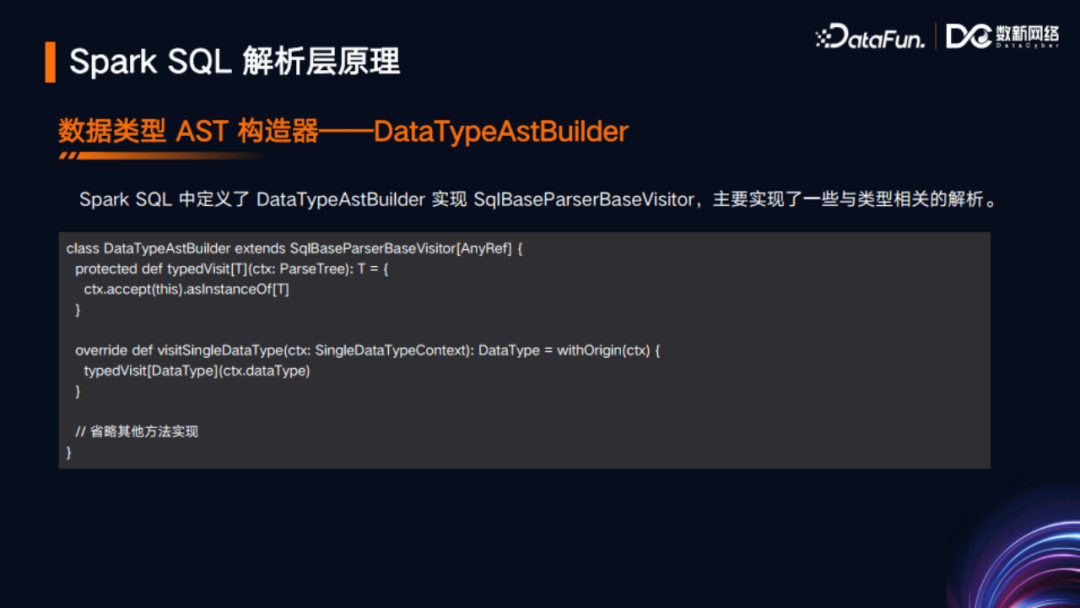
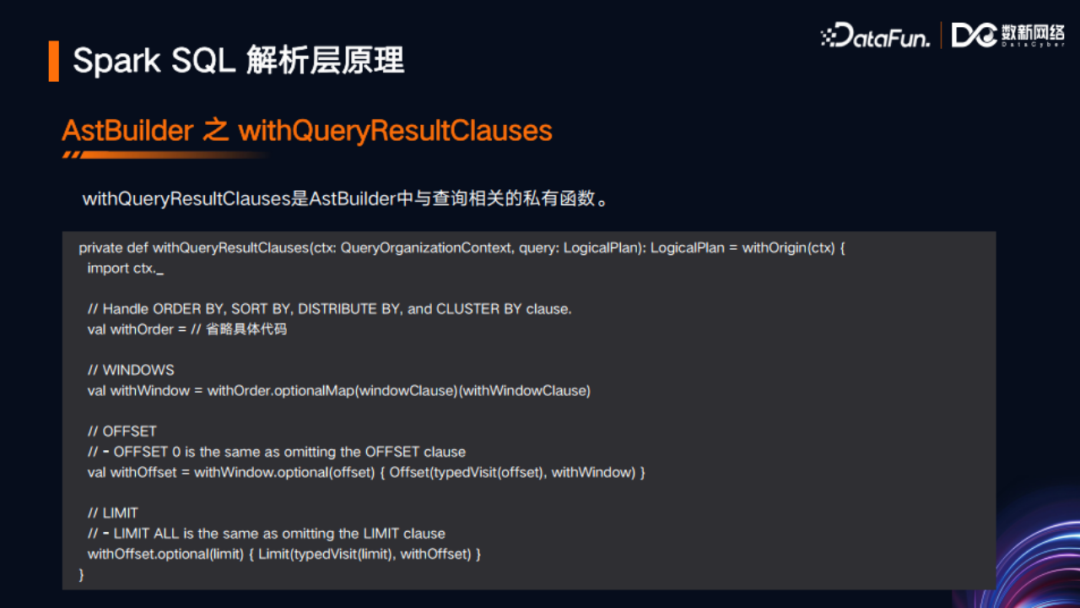
AstBuilder中有一个visitQuery方法,这是与SQL中SELECT查询语法最紧密的接口实现,这个方法会调用其他一些方法,最终返回LogicPlan类型。LogicPlan是Spark内部的逻辑计划表示,其本身是一个树形结构,可以理解为AST的一个具体实现。在visitQuery方法中,有一部分是withQueryResultClauses,这部分就是对查询结果从句的处理。下图展示了其关键代码。可以看到,其中有对ORDER BY、SORT BY、DISTRIBUTE BY、CLUSTER BY、窗口函数、OFFSET、LIMIT等语法的处理。
另外,在visitQuery方法中,还有一部分是withCTE,以下是其关键代码。CTE即公用的表表达式,比如针对一个表做了查询,且这个查询在整个SQL中需重复多次使用。那么在此类场景下,CTE语法就非常有用,可以把一个针对表的查询定义成表达式或变量以复用。

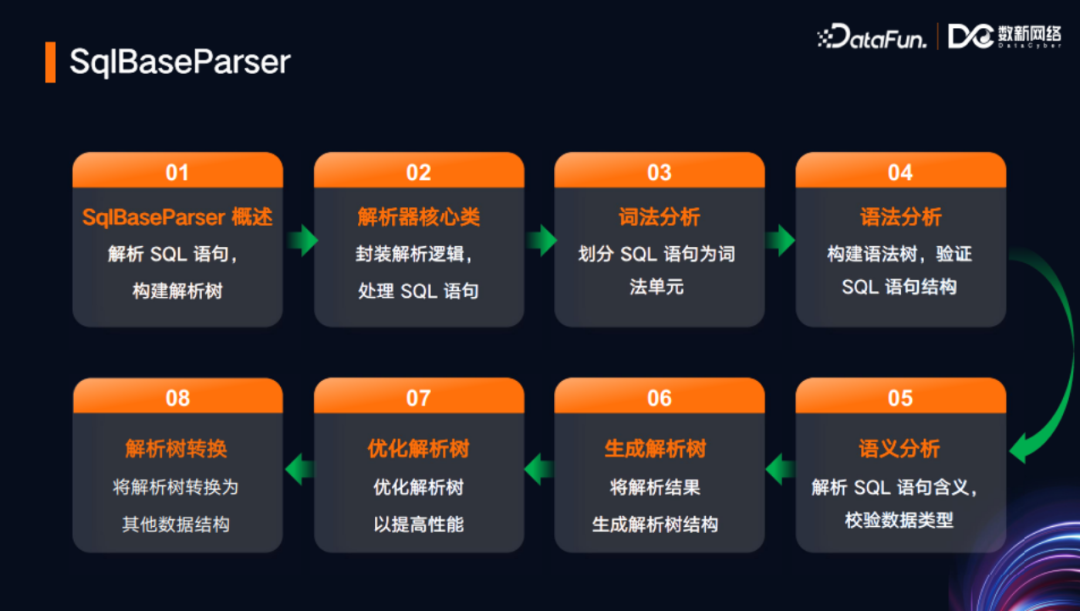
再介绍一下SqlBaseParser入口。SqlBaseParser的父类AbstractParser定义了parse函数,可以针对DDL、DML等类型的语法进行处理。首先进行词法分析(包括Token的划分),然后进行语法解析,返回解析后的结果,具体而言,子类会返回一个LogicPlan。

最后通过一个图来总结ANTLR4和Spark SQL的融合解析流程。左边是两个.g4文件之间的引用关系,经过ANTLR4编译构建之后,生成一些接口和抽象类。右边图例说明其具体实现是交给Spark SQL完成的。

三、优化案例
前文介绍了Spark SQL解析层的原理,接下来将围绕这些原理介绍一个优化案例。
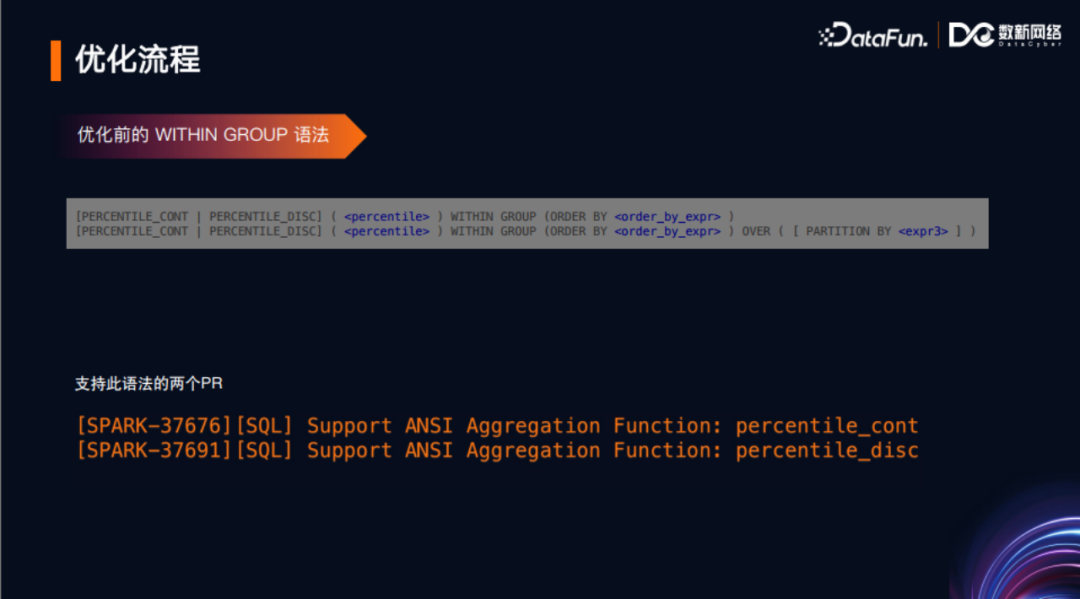
本人在Spark 3.2版本向社区陆续贡献了两个语法PR。最早是在语法定义模板里修改了部分定义实现相应功能,增加了percentile_cont和percentile_disc这两个函数作为聚合函数和窗口函数的一些功能。

观察上图左边的代码可以看到,优化之前这两个函数(可作为聚合函数也可以作为窗口函数)的一些代码逻辑定义,处于表达式的模板定义之下。当时为了实现这两个函数的这些功能,做了如下操作。针对ANTLR编译之后生成的visitPercentile接口,在AstBuilder中进行了实现,包括解析层、分析层、优化层。这里只展示了解析层的内容。Spark选择了Scala语言来实现,对代码优雅性、代码质量要求非常高,这种实现引入了一些额外代码,总共约20-30行,被社区要求改进。观察到Spark的AstBuilder中,有一个较为通用的functionCall函数,以下展示了其具体代码。
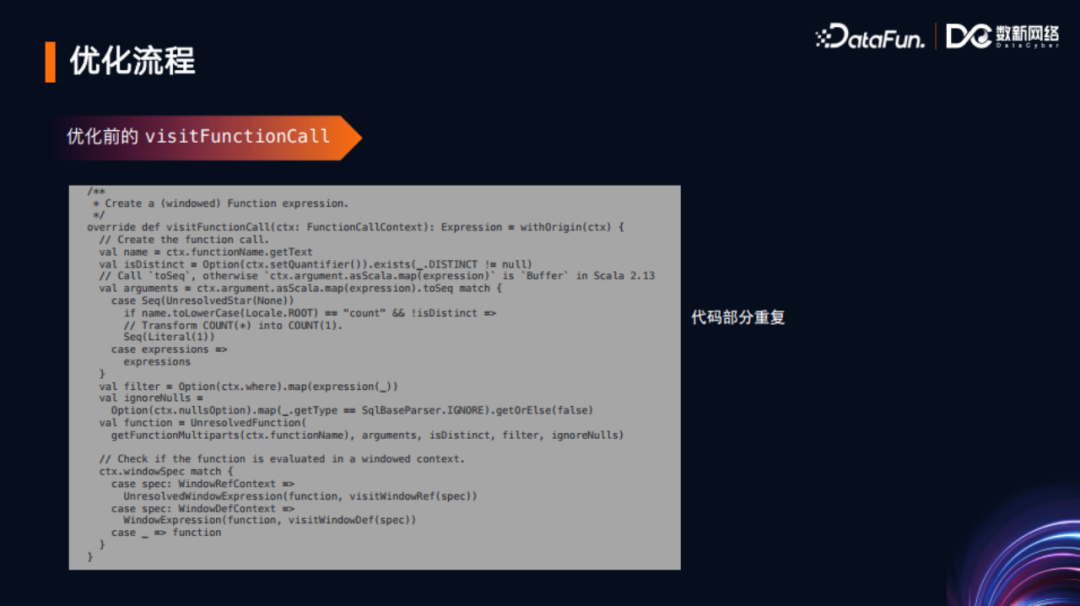
把该代码与visitPercentile代码进行对比,可以发现很多重复代码,也是需要去改进的。因此,考虑复用此代码进行功能实现,对visitFunctionCall代码进行修改,针对要修改的两个函数做定制化处理。
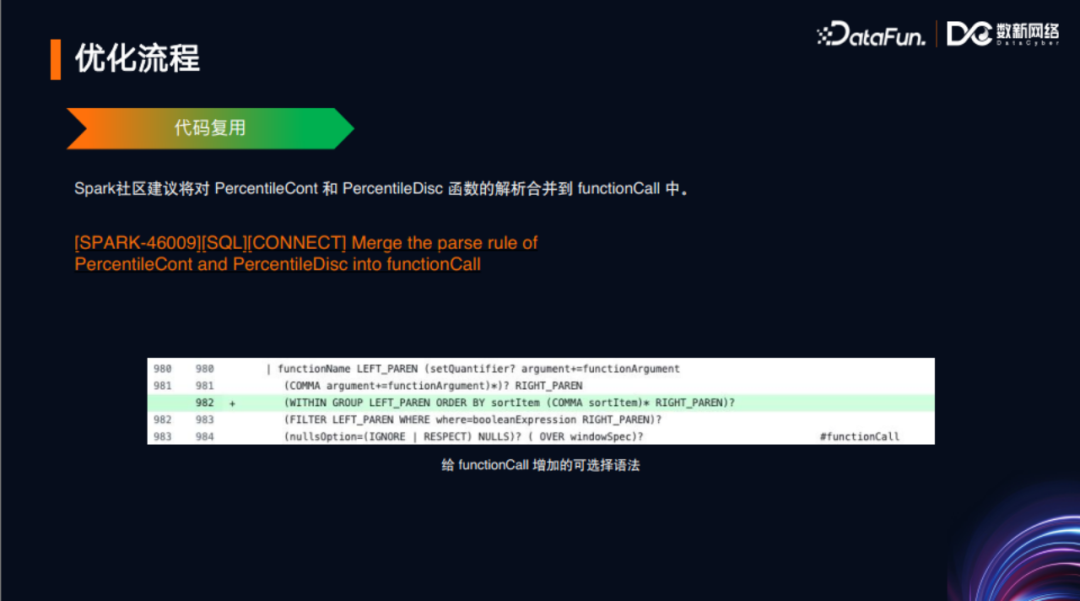

优化后,在语法层使得原来增加的6-7行代码变为只需一行代码;而针对visitFunctionCall,只需要变动2行代码。从代码角度来说,相比优化前的近30行代码,总共仅需变动3行代码,这样的优化更为合理且代码也更为优雅。在图片中可以看到整个优化过程,就是通过复用代码,让代码更加的精巧和优雅。从这个优化可以看出,一个软件尤其是大型软件的性能优势其实都是日积月累起来的。
四、总结
本次分享介绍了Spark SQL解析层的原理。主要包括Spark SQL与ANTLR4之间的协作关系、ANTLR4生成的接口和抽象类、Spark SQL的具体实现类、Spark SQL的解析入口和解析流程等,最后通过一个优化案例介绍了Spark解析层的优化。Spark SQL经过ANTLR4的语法校验和类型校验后,通过parse方法解析得到抽象语法树,并将其交给分析层处理,那么关于分析层优化将在下一期分享继续介绍,之后也会有更多性能相关优化,欢迎大家继续关注。

五、Q&A环节
Q1:如何计算一个Spark SQL的资源消耗,从而对比不同SQL的性价比?
A1:现在 SparkSQL基本上大多数组件都是有度量系统的,Spark 内部的Spark Core,Spark SQL 里都有一个度量子架构,其中可以定义很多监控指标,或者称为度量信息。比如一个读数据的scan 相关的算子,在算子里面就会去计算读了多少字节、读了多少行、读了多少时间等。这些 metrics 也可以由用户自定义,通过这些 metrics 信息可以进行性能比较。另一方面,Spark SQL 目前也是支持基于TPC-DS数据集进行性能压测或性能对比。
Q2:怎么去评价SQL优化效果?
A2:评价SQL 的优化效果,主要看优化的目的是什么。如果优化目的是提高稳定性,比如优化之前这个 SQL 经常出现跑不出来、跑失败,优化后能跑出来就达到了预期的优化效果。还有一种是如果优化目的是希望能跑得更快,那么就用时间来评价,所以评价标准主要取决于自己的实际需求。
Q3:Spark向量化技术越来越多,老师怎么看?是不是未来的Spark作业都要使用Native引擎?
A3:Spark 使用Scala,其本质也是用JVM 运行的。对于JVM类语言,其天生最大的一个优势或者说在商业上最成功的一个点,就是语言的平台无关性。熟悉大数据运维的同学肯定有这样的体会,对于一些用 Java 语言开发的大数据组件,包括Spark、Flink、Hadoop、MR 这些组件,它们在任何硬件系统和操作系统上都可以跑。那对公司的商业层面来说,它的运维代价、部署代价、维护代价都很低,而且学习成本也很低,这些其实也是代表着公司的一个核心竞争力。那现在为什么很多公司会追求向量化?一方面是现在数据体量越来越大,也就意味着任务的执行可能耗时会更多,就可能导致对于硬件 CPU 的占用更多。对于大公司来说,尤其是本身就有云提供能力的厂商,他们都有自己的运维团队,花费的成本还是相对可控的。但是对于一些中小公司来说,就会使用付费的云服务,价格会更昂贵,那成本就会更高。在追求降本增效的环境下,对于大数据引擎,包括Spark及其他采用Java开发的大数据组件而言,它们在Native层面上的优化尝试日益增多。其实就是指通过深入挖掘计算机硬件和指令集的性能潜力,来实现成本降低与效率提升的双重目标。我认为还是要围绕公司架构,如果是ToC的业务,那么去做向量化或者native,这种更接近底层硬件的性能优化问题不大;但如果公司是ToB 的,大数据产品或者技术要输出到不同的公司客户,而不同客户又选择了不同的操作系统和不同的 CPU 架构,那这可能就会成为这个公司的噩梦。所以从长远看不管是 Spark 的向量化,还是原生的基于JVM方式的 Spark,两种方式各有优劣,针对不同的目的都会有其存在的价值。
Q4:ANTLR4有没有什么好的学习书籍推荐?
A4:作为一个搞开源的人,我建议可以去看ANTLR4官网,能够理解官网的全部内容,会比任何书都更有价值。
Q5:ANTLR4和Calcite的区别?
A5:我的理解是, Calcite 相比于 ANTLR4,它的功能会更多,它提供了一些优化规则方面的一些处理。ANTLR4其实只是一个解析层的东西,解析出来的东西如果不去进一步处理就没有任何价值,但 Calcite解析完之后,它还附带了一些比较基础的一些优化规则等。从这个角度来说,如果一个公司想要去开发一门语言,基于Calcite也许会比用ANTLR4的开发周期更短。
Q6:Spark的发展方向是什么?流批一体吗?
A6:目前Spark、Flink 都在向着流批一体的方向发展,其实Spark 的优势是在于批处理,而Flink则是在流的部分。因为Flink面对的业务场景较少,则市场占有率就会比较少,所以通过推出流批一体也可以来扩大市场。Spark社区在面对Flink 在批处理上的挑战时,也会去和Flink 在流的市场上做一些争夺,总之二者在这种商业角逐下,很多方面可以相互借鉴。
Q7:在数据量大时Spark易出现超出内存被Kill的情况,Shuffle时同样都有溢写到磁盘的功能,为什么 MR 很少出现问题?
A7:因为 MR 不怎么用内存,如果把MR 的JVM内存设置得比较小,也会出现被 Kill 的问题。至于Spark 容易超出内存被Kill,这个问题是因为可能与第三方资源管理(比如Yarn、K8S)有关。
Q8:SQL 解析是否提供了一些对外的接口?例如公司需要分析离线任务的血缘关系,是否有一些接口能深入解析过程拿到表名的?
A8:现在 Spark SQL 的这些解析层的组件,就是作为公共 API 方式存在的。Spark 社区为了便于用户使用,也在积极维护接口的向前兼容性,这其实是考虑到用户只是去做一层解析的使用场景,所以你完全可以这么使用的。









![HTB:Photobomb[WriteUP]](https://i-blog.csdnimg.cn/direct/7cc80387d0314bbb9ecb5105ca1263d7.png)