DNN概述
深度神经网络DNN来自人脑神经元工作的原理,通过在计算机中逻辑抽象出多个节点,接收处理并向后传递信息,实现计算机的自我学习,类比结构见下图:

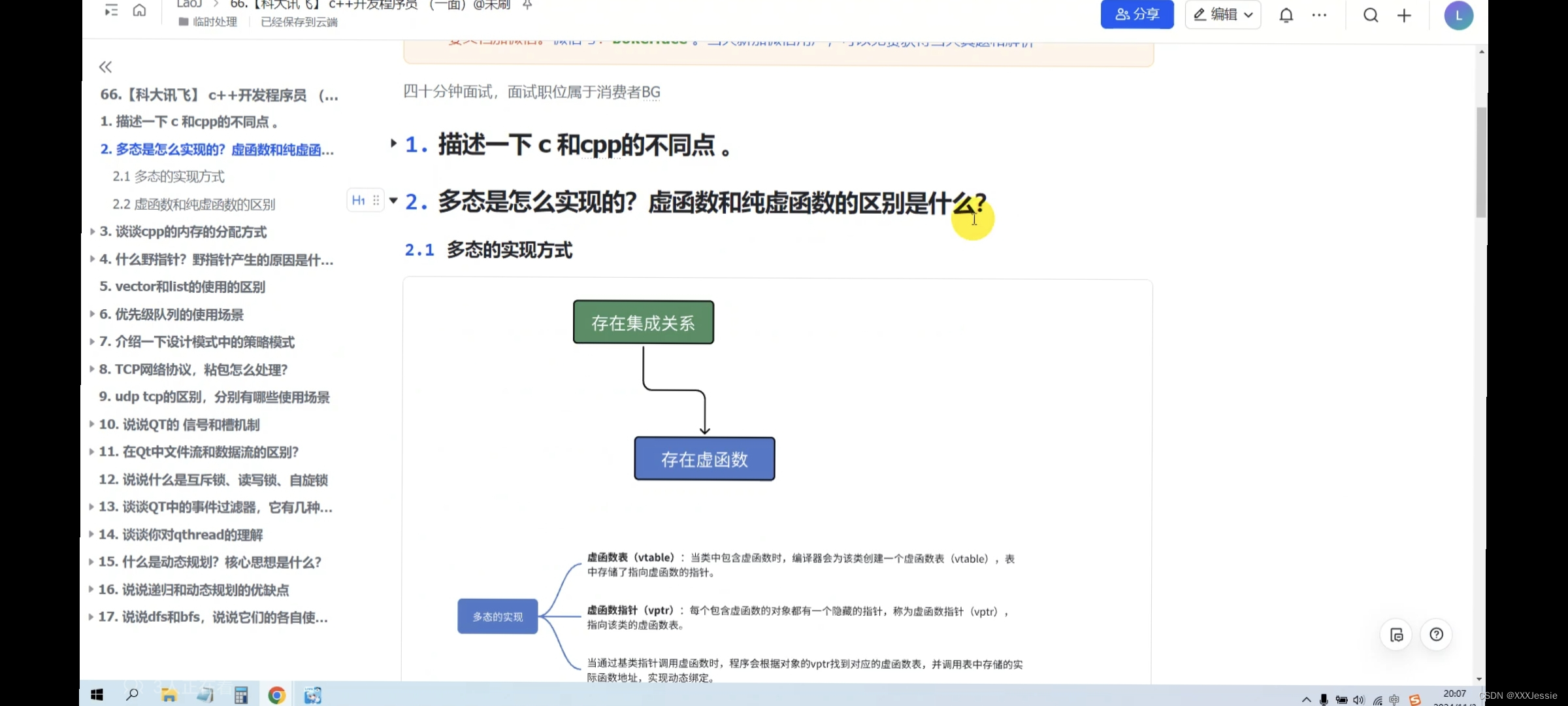
该方法通过预测输出与实际值的差异不断调整节点参数,从而一步步调整整体预测效果,节点预测输出的过程称为前向传播,根据差异调整参数的过程称为反向传播,而又因为节点计算公式y=wx+b为线性的,如果每个节点都向后传递该值,那最终的输出也可以表示为wx+b,故要体现每个节点的特殊性,需要引入非线性处理,即激活函数,根据在该过程中对学习率步长的设置调整、更新参数依靠样本的选择等区别,产生了多种不同的优化算法。
一般的机器学习流程如下图:

DNN网络训练
首先导入一般需要的包
import torch.nn as nn
import torch
import pandas as pd
import numpy as np
所有参数和模型的文档都可以在官网查看,查找前记得在选项中选择自己使用pytorch的版本:

数据集导入
大致流程为:
1,使用pandas从文件中读取数据
2,将带标签的数据退化为数组,并转换类型
3,将数组转换为张量
4,数据搬到显卡上进行加速
代码分别如下:
df=pd.read_csv("文件路径")
arr=df.values.astype(np.float32)
ts=torch.tensor(arr)
ts=ts.to('cuda')
划分训练集与测试集
首先根据比例划分训练集与测试集大小,为了避免数据前后关联,最好打乱样本的顺序,然后分别按行读取样本到数据集集合中,代码如下:
tran_size=int(len(ts)*0.8) # 训练集大小,0.8为比例系数
test_size=len(ts)-tran_size # 测试集大小
ts=ts[torch.randperm(ts.size(0)),:] # 打乱数据
train_data=ts[:tran_size] # 训练集数据
test_data=ts[tran_size:] # 测试集数据
搭建网络
根据输入和输出特征搭建网络,需注意相邻网络的输入输出需对应,网络需继承nn.Module模块,继承后重写网络模型到初始化函数中,定义向前传播forward调用网络并返回预测,示例代码如下:
class DNN(nn.Module):def __init__(self):super(DNN, self).__init__() # 初始化父类self.network = nn.Sequential(nn.Linear(28*28, 512), # 第一层线性层nn.ReLU(), # 第一层激活函数nn.Linear(512, 1024), # 第二层线性层nn.Sigmoid(), # 第二层激活函数)def forward(self, x):x = self.network(x) # 第三层无激活函数return xDNN=DNN() # 创建网络对象实例
优化器算法
首先定义损失函数loss_fn,具体的选项见官方文档,然后设置学习速率learning_rate和optimizer优化器,通过torch.optim设置优化算法,示例代码如下:
loss_fn=nn.MSELoss()
learning_rate=0.001
optimizer=torch.optim.Adam(DNN.parameters(), lr=learning_rate)
训练网络
网络的训练往往要经过多次循环,所以通常先设置一个epochs循环次数,为了将学习成果可视化,一般也设置一个列表用于存储损失函数的变化过程,然后对数据的输入输出特征进行划分,将数据除最后一列的值作为输入,最后一列的值升级为二维作为输出,代码如下:
epochs=100
loss_list=[]x=train_data[: , : -1] # 取出所有行,除最后一列的所有列
y=train_data[: , -1].reshape((-1,1)) # 取出所有行,最后一列,升级为二维
最后在循环中计算前向传播预测值,使用损失函数计算损失,反向传播计算梯度,优化模型参数,最后清空梯度,示例代码如下:
for epoch in range(epochs):y_pred=DNN(x)loss=loss_fn(y_pred, y)loss.backward() # 反向传播optimizer.step() # 更新参数optimizer.zero_grad() # 清空梯度缓存print(f"Epoch: {epoch}, Loss:{loss}") # 打印当前epoch和损失值loss_list.append(loss.item()) # 将损失值添加到列表中
测试方法为:首先声明关闭梯度计算功能,将预测值与真实值进行比较,统计正确信息,示例代码如下:
with torch.no_grad(): # 关闭自动求导功能test_x=test_data[: , : -1]test_y=test_data[: , -1].reshape((-1,1))pred_y=DNN(test_x)
制作数据集DataSet
前面我们使用的是批量梯度下降,每次参数更新使用所有样本,为了提高训练效率,我们在实践中多使用小批量梯度下降,这要求我们分批加载数据,加上我们为了复用代码和更好地管理数据,数据集应该也使用框架管理起来,该功能可以借助DataSet实现。
我们的数据集必须继承DataSet类,同时要重写__init__加载数据集、__getitem__获取数据索引和__len__获取数总量方法,示例代码如下:
from torch.utils.data import Dataset, DataLoaderclass Data(Dataset):def __init__(self,filename): # 根据文件路径加载数据集super(Data, self).__init__()df = pd.read_csv(filename)arr = df.values.astype(np.float32)ts = torch.tensor(arr)ts = ts.to('cuda')tran_size=int(len(ts)*0.8)ts=ts[torch.randperm(ts.size(0)),:]self.x=ts[:tran_size,:-1]self.y=ts[:tran_size,-1].reshape((-1,1))self.xlength=len(self.x)self.ylength=len(self.y)def __getitem__(self, index):return self.x[index], self.y[index]def __len__(self):return self.xlength,self.ylength
加载数据集时使用Data=Data("路径")创建数据集对象,train_size,test_size= len(dataset)读取文件长度,使用train_loader=DataLoader(dataset,batch_size=100,shuffle=True)和test_loader=DataLoader(dataset,batch_size=100,shuffle=False)分别读取训练集和测试集,shuffle表示是否洗牌,训练集可用,测试集无需洗牌。
使用该方法加载数据集,训练测试时直接可用for (x,y) in train_loader循环,因为其中已经包含了两个元素,代码更简洁。
CNN卷积神经网络
该网络顺应机器学习的图像处理潮流而生,传统神经网络需要将图像展为一列,该方式会忽略图像原本二维排布时的关系,更不必说如今的彩色图像可能有多个通道,传统方法更无法处理,基于保留临近位置像素点关系的想法,产生了卷积神经网络。
卷积核
该方法本质上是神经网络的变形,只是其表现形式有所区别,原本的权重w变成了卷积核,图像像素与卷积核逐位相乘求和,再进行偏置计算,原本的激活函数此时变成了池化层pool,直观展示如下:

构建网络时使用nn.Conv2d(输入通道数,输出通道,卷积核大小,填充,步长)来添加卷积层,由于卷积核的数值也是训练的一部分,故无需手动设置,由随机初始化完成,使用示例如下:
model = nn.Sequential(nn.Conv2d(1,20,5),nn.ReLU(),nn.Conv2d(20,64,5),nn.ReLU())
其他卷积层见官方文档。
池化层
该层功能与激活函数类似,用于获取特征,比如选出最大值,求平均等操作,如nn.MaxPool1d(),详见官方文档,可惜是英文的,而且信息量太大,每个函数都值得学一会。
输出尺寸计算
此外为了使图像与卷积核大小相符,增加了填充padding,和卷积核的移动步长stride,现在整合所有参数,输入图像尺寸(H,W),卷积核大小(FH,FW),填充p,步幅s,输出图像大小(OH,OW)的计算方法如下:


滤波器
彩色图像等多通道时使用相应通道数的卷积核即可,但此时卷积核又有了新的名字——滤波器Filter,即输入数据与滤波器通道设置为相同的值时,输出仍为一维,输出时再使用滤波器,即可实现升维。
经典网络
LeNet-5
AlexNet
GoogLeNet
ResNet
答疑—清空梯度
上次模型构建我们讨论了反向传播的具体作用,这次我又对清空梯度这步有了疑问,每个epoch梯度清空,那是否i多次实验彼此独立,又如何收敛呢?经过查询得出如下结论。
首先重申,清空的是梯度,而非模型参数,pytorch默认使用的是梯度累加的方法,即多次训练的梯度累加计算,并允许手动清零,该方式允许硬件条件不允许的项目使用小的batch_size,多次循环累加梯度可以实现较好的效果,而我们手动清零后可以避免多个数据集对模型参数优化的影响,实现全新的二次训练。
总结
本次算是初学pytorch的第二次实践,对于一些方法和原理有了更进一步的理解:
清空梯度避免干扰,小批量时可不清空;
继承方法建立模型和数据集;
卷积核用于保存图像空间上的相邻关系,池化层选特征;
多通道用滤波器降维,学习后再升维。
至此觉得可以算是入门了,但仍然路漫漫,学习网络模型结构的搭建,各种优化算法和损失函数,池化操作,步长卷积核大小的设置,这些的工作才是大头,此外将深度学习与什么相结合,这更是关键。











![使用pip安装项目时,遇到以下错误的解决方案:error: [Errno 13] Permission denied](https://i-blog.csdnimg.cn/direct/daaefb0e7d03481789e8a5773d79859a.png)