文章目录
- 一、链表的分类
- 二、双链表的实现
- 1.双链表结构的定义
- 2.双链表的初始化和销毁
- 初始化函数1
- 初始化函数2
- 销毁函数
- 3.双链表的打印以及节点的申请
- 打印函数
- 节点的申请
- 4.双链表的头插和尾插
- 头插函数
- 尾插函数
- 5.双链表的查找和判空
- 查找函数
- 判空函数
- 6.双链表的头删和尾删
- 头删函数
- 尾删函数
- 7.双链表指定节点位置的操作
- 删除指定的节点
- 在指定节点前插入数据
- 三、单链表和双链表的简单对比
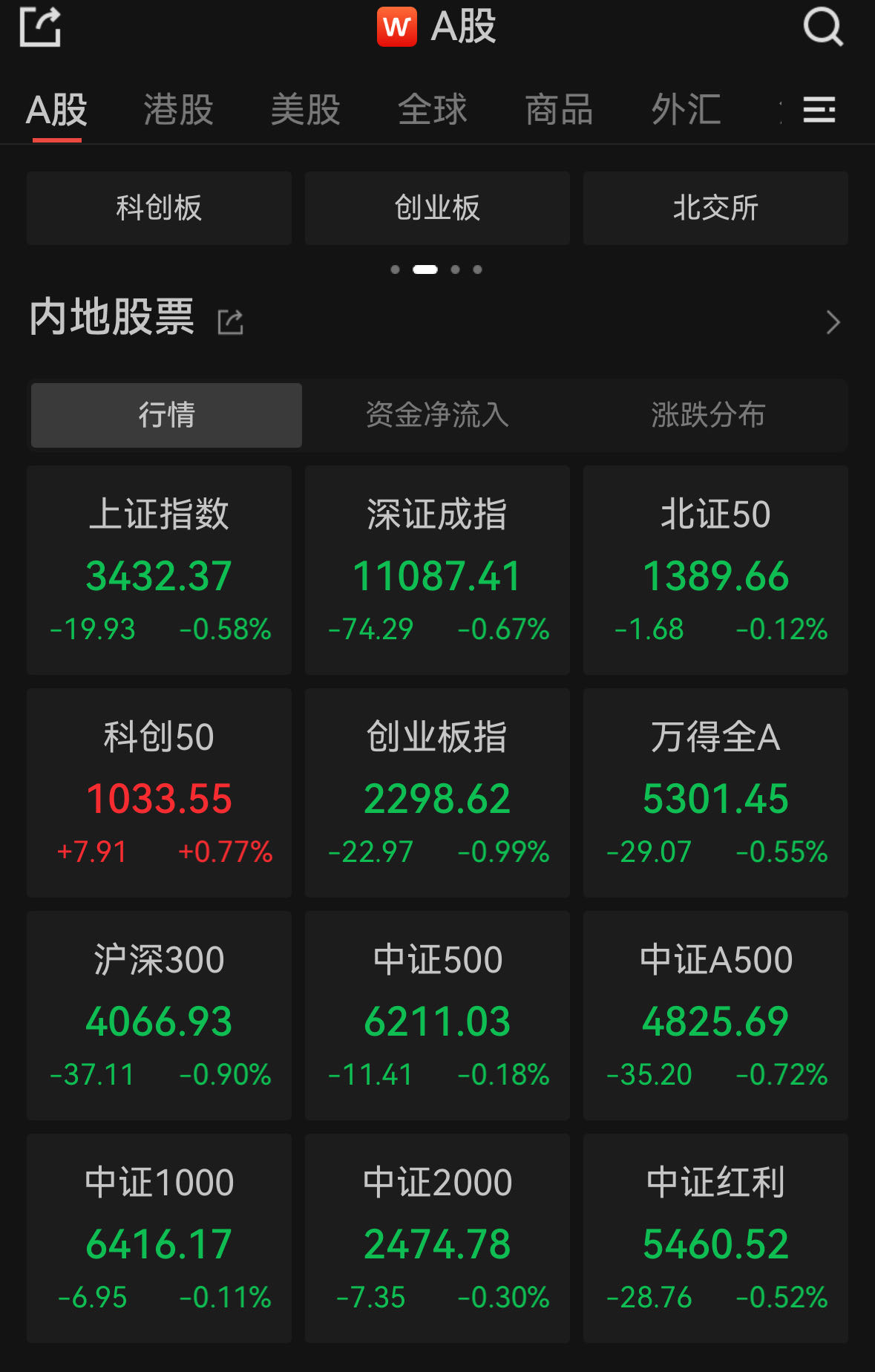
一、链表的分类
在上一篇中,我们简单了解了单链表,但是我们没有仔细的对链表的分类进行分析,因为我们是第一次接触到链表这种结构,所以我们先简单了解一下单链表,实现一下,现在才能对我们链表的分类有清晰的认知
接下来我们来了解一下链表的具体分类,然后从分类中找出我们上节课实现的单链表,如下:

在上面的属性中,让它们进行组合一共就会有8种分类,比如带头单向循环链表,带头单向不循环链表,带头双向循环链表等等,这里就不一一列举了,我们主要来解释一下分类里面的每组名词是什么意思
- 带头和不带头:带头和不带头不是我们之前说的头结点,之前我们的头结点是链表中存储数据的第一个节点,这里的带头是我们在创建链表时会申请一个头结点,这个头结点不存放数据,它只代表链表的头,无论我们进行删除还是增加都让它指向链表的头,它也叫哨兵位
- 单向和双向:单向链表的意思就是它只有一个next指针指向后节点,前节点可以通过next指针找到后节点,但是后节点找不到前节点。双向链表的意思就是它不仅有一个next指针指向后节点,还有一个prev指针指向前节点,前后节点可以互相访问
- 循环和不循环:不循环链表就是它的尾结点指向空指针,不会产生循环。循环链表就是它的尾结点指向头结点,这样的话整个链表就形成了循环
根据上面的分类和各种名词的解释,我们现在来判断一下我们上节课讲的单链表属于哪个分类,首先我们没有创建一个不保存数据的头节点一直指向链表头不改变,之前说的头结点是要存放数据的,并且之前的头结点有可能被改变,所以并不属于带头的链表
我们实现单链表的结构时,只有一个next指针指向下一个节点,没有prev指针指向上一个节点,所以我们可以判断出单链表属于单向的链表
最后,由于我们实现的单链表的尾结点指向空,所以它是不循环链表,最后综合一下上面的分析,我们上一篇实现的单链表其实全称应该是单向不带头不循环链表
所以我们现在就知道了,通常说的单链表虽然只说了单,但是其实它完整的名字是单向不带头不循环链表,那么我们今天要学习的双链表属于哪个类别呢?
这里就不卖关子了,我们平常说的双链表跟单链表完全是两个反面,它属于双向带头循环链表,我们在实际应用中最常用的也是双向链表,因为它的每个方法的时间复杂度都基本达到了O(1),效率比较高,只是多了一点点空间的开销,接下来我们就来学习双链表的实现
二、双链表的实现
在上面我们已经说过了,平常所说的双链表就是双向带头循环链表,它的特点我们上面已经介绍过了,接下来我们就来实现它,它的实现和单链表的实现的思路差不多,如果吃透了单链表,双链表的实现就不难了
1.双链表结构的定义
我们在上面说过,双链表属于双向链表,不仅有一个指向下一个节点的next指针,还有一个指向上一个节点的prev指针,其余和单向链表的定义差不多,如下:
typedef int LTDateType;typedef struct ListNode
{LTDateType data;struct ListNode* prev;struct ListNode* next;
}LTNode;
2.双链表的初始化和销毁
我们之前写的单链表没有初始化,但是双链表是有初始化的,因为我们说过,双链表的是带头的,初始化的目的就是为了给我们的双链表申请一个不保存数据的哨兵位
初始化函数1
初始化函数就是为了帮我们申请一个哨兵位节点,所以它可以有两种方式,一种就是我们在主函数中创建好一个节点指针,默认置为空,然后我们通过传参的方式将这个指针传给初始化函数,由初始化函数给它申请哨兵位
在初始化的时候我们要注意一点,就是我们的双向链表属于循环链表,不能把它的prev和next指针置为空,要把它们都指向哨兵位自己,否则就不循环了,至于哨兵位的数据部分是什么都不重要,可以不管,最后由于我们会改变这个指针,所以我们要传二级指针,如下:
void LTInit1(LTNode** pphead)
{assert(pphead);*pphead = (LTNode*)malloc(sizeof(LTNode));if(*pphead == NULL){perror("malloc");return;}(*pphead)->next = (*pphead)->prev = *pphead;
}
初始化函数2
还有另一种方式就是,不用接收任何参数,直接在初始化函数中创建新节点,初始化后将其返回即可,在主函数中直接接收即可,我们也推荐使用这种方式,具体原因后面再说,代码如下:
LTNode* LTInit2()
{LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));if(*pphead == NULL){perror("malloc");return;}newnode->prev = newnode->next = newnode;return newnode;
}
销毁函数
链表有初始化就有销毁,就是没有初始化也要销毁,因为链表中的所有节点都是动态申请的,如果不释放就会导致内存泄漏,在销毁时有一个细节要注意,就是双链表的尾结点不是指向空的,而是指向哨兵位
如果我们开始就从哨兵位开始释放,那么就找不到停止释放的条件了,所以我们可以从哨兵位的下一个节点开始释放,也就是存放数据的第一个节点,一直释放到它的next指针指向哨兵位,最后我们再释放哨兵位,如下:
void LTDestroy(LTNode** pphead)
{assert(pphead);LTNode* pcur = (*pphead)->next;while (pcur->next != *pphead){LTNode* del = pcur;pcur = pcur->next;free(del);del = NULL;}free(*pphead);*pphead = NULL;
}
3.双链表的打印以及节点的申请
打印函数
打印函数还是一样的简单,只是要根据双链表的特性来做,双链表有哨兵位,所以打印要从哨兵位的下一个节点开始打印,直到遇到的节点的next指针指向哨兵位,代码如下:
void LTPrint(LTNode* phead)
{assert(phead);LTNode* pcur = phead->next;while (pcur != phead){printf("%d ", pcur->data);pcur = pcur->next;}
}
节点的申请
节点的申请还是叫我们的BuyNode,形象生动,节点的申请跟单链表差不多,只是多了一个prev指针,把它一起置为空,如下:
LTNode* LTBuyNode(LTDateType x)
{LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));if(newnode == NULL){perror("malloc");return NULL;}newnode->data = x;newnode->next = newnode->prev = NULL;return newnode;
}
4.双链表的头插和尾插
我们的双链表多增加了一个prev指针,可能在上面的方法中还没有发现它的作用,在后面的函数中就会发现它有大用,基本上可以把所有函数的时间复杂度降到O(1),但是相对于单链表而言双链表的方法实现就要难一点
头插函数
由于我们的双链表有哨兵位占位子,所以我们无论是插入还是删除节点都不会影响哨兵位,不会影响哨兵位我们就可以都传一级指针,这也是哨兵位最重要的功能之一
我们也可以想到,头插就是往哨兵位的后一个位置去插入,哨兵位一直都不修改,用来表示链表的开始,由于我们双链表的指针比较多,所以我们的第一步就是来梳理一下哪些节点会受到影响
首先我们对新节点的指向进行操作,这样不会影响原链表的结构,那么新节点的prev指针要指向哨兵位,新节点的next指针指向原链表中第一个存储数据的节点,如图:

接着我们就要对原链表的指向进行修改,哨兵位的next指针要指向新节点,原链表中第一个保存数据的节点的prev指针也指向新节点
但是我们要注意一个点,就是如果我们直接修改哨兵位的next指针,就找不到原链表中第一个保存数据的节点了,所以我们要先通过哨兵位找到那个节点,然后让它的prev指针指向新节点,最后让哨兵位的next指针指向新节点,如图:

有了以上的思路,我们现在直接来写代码,如下:
void LTPushFront(LTNode* phead, LTDateType x)
{assert(phead);LTNode* newnode = LTBuyNode(x);newnode->next = phead->next;newnode->prev = phead;phead->next->prev = newnode;phead->next = newnode;
}
尾插函数
尾插函数的思想也和头插差不多,在单链表中,我们如果想要找到尾结点就必须遍历整个链表,直到遇到next指针为空的节点,导致我们的时间复杂度只能是O(N),但是在双链表中要找到尾结点就很简单了,因为哨兵位的prev指针就指向了尾结点
由于是尾插,所以我们要让新节点成为尾结点,那么新节点的prev指针就要指向原本的尾结点,next指针就要指向哨兵位,如图:

新节点的指向设置好之后我们就来修改原链表,首先就是尾结点的next指针要指向新节点,哨兵位的prev指针要指向新节点,如图:

有了上面的思路我们就来实现一下代码,如下:
void LTPushBack(LTNode* phead, LTDateType x)
{assert(phead);LTNode* newnode = LTBuyNode(x);newnode->next = phead;newnode->prev = phead->prev;phead->prev->next = newnode;phead->prev = newnode;
}
当我们写完头插和尾插后,不知道大家感受到没有,我们的头插和尾插基本上只修改了指针的指向,没有其它的开销,执行起来非常快,这就是双向链表的优势
5.双链表的查找和判空
这里我们先把查找和判空方法写出来,后面的方法可能会用到,链表的查找和判空很简单,我们一起来分析
查找函数
我们在查找时肯定是查找有效的数据,所以我们查找是从哨兵位后一个节点开始的,查找方法也很简单,遍历整个双链表,看看能否找到相应的数据,找得到就返回对应节点,找不到就返回空,如下:
LTNode* LTFinde(LTNode* phead, LTDateType x)
{assert(phead);LTNode* pcur = phead->next;while (pcur != phead){if (pcur->data == x){return pcur;}pcur = pcur->next;}return NULL;
}
判空函数
双链表的判空很简单,如果哨兵位的next指针指向自己,不就说明链表中没有数据吗,也就是链表为空,返回真,否则返回假
我们可以用一个巧妙的方法用一步就可以将上面的要求实现,如下:
bool LTEmpty(LTNode* phead)
{return phead == phead->next;
}
当phead等于它的next指针时,这个等式为真,刚好说明链表为空,返回真,当不相等时,等式为假,说明链表不为空,返回假,最后提醒一点,要使用bool类型,要包含头文件stdbool.h
6.双链表的头删和尾删
这里的两个方法都是删除,但是我们要强调一点,在删除的时候,是不会删除哨兵位的,它没有保存数据,帮我们把链表头存储起来而已,如果删除了下次还要特殊申请,更加麻烦了,所以我们要删除的都是哨兵位以外的节点,直到链表销毁才删除哨兵位
在删除之前我们都要对链表进行判空,如果链表为空肯定就不能删除,要结束程序,如果链表不为空才可以进行删除操作,我们的判空函数就有用处了,可以在头删和尾删的前面断言一下,如下:
assert(!LTEmpty(phead));
头删函数
头删函数就是让哨兵位的next指针指向第二个数据节点,然后第二个数据节点的prev指针指向哨兵位,最后释放掉原先的第一个数据节点,只需要改变两个指针的指向,当然,为了防止找不到要删除的节点了,我们最好把它保存一下,代码如下:
void LTPopFront(LTNode* phead)
{assert(!LTEmpty(phead));LTNode* del = phead->next;//要删除的节点LTNode* next = phead->next->next;//第二个数据节点phead->next = new;new->prev = phead;free(del);del = NULL;
}
尾删函数
尾删函数和头删函数的实现也差不多,要进行链表判空,尾删的本质就是让尾结点的前一个节点,也就是倒数第二个节点的next指针指向哨兵位,哨兵位的prev指针指向倒数第二个节点,然后把尾结点释放掉,如下:
void LTPopBack(LTNode* phead)
{assert(!LTEmpty(phead));LTNode* del = phead->prev;LTNode* prev = phead->prev->prev;prev->next = phead;phead->prev = prev;free(del);del = NULL;
}
7.双链表指定节点位置的操作
我们要对指定节点位置进行操作,有一个很关键的步骤就是怎么得到指定的节点,这个就可以使用我们之前写过的查找函数,通过查找函数找到指定的数据,然后返回值就是指定数据的节点,所以我们指定位置的操作是结合查找方法使用的
删除指定的节点
这个方法和头删尾删的方法其实查不了多少,我们通过拿到的指定节点就可以找到指定节点的前后节点,然后我们就让指定节点的前后节点连接起来,释放指定的节点即可,如下:
void LTErase(LTNode* phead, LTNode* pos)
{assert(!LTEmpty(phead));pos->prev->next = pos->next;pos->next->prev = pos->prev;free(pos);
}
当然,出来删除指定节点,还要删除指定节点前的节点和删除指定节点后的节点,方法类似,这里就不多讲了,可以自己去实现一下
在指定节点前插入数据
在指定节点前插入数据其实不难,只是可能稍微要绕一点点,所以我们画个图来解释一下更好,如图:


那么有了上图的分析,我们就来实现一下代码,如下:
void LTInsert(LTNode* phead, LTNode* pos, LTDateType x)
{assert(phead);LTNode* newnode = LTBuyNode(x);LTNode* prev = pos->prev;newnode->prev = prev;newnode->next = pos;prev->next = newnode;pos->prev = newnode;
}
当然,还可以在指定节点后插入一个节点,这里也不再不讲,方法类似,可以试着自己去实现一下
三、单链表和双链表的简单对比
虽然有这么多的链表的结构,但是我们实际中最常⽤还是两种结构:单链表和双向带头循环链表
- ⽆头单向⾮循环链表:一般称为单链表,结构简单,⼀般不会单独⽤来存数据,实际中更多是作为其他数据结构的⼦结构,如哈希桶、图的邻接表等等,另外这种结构在笔试⾯试中出现很多
- 带头双向循环链表:一般称为双链表,结构最复杂,⼀般⽤在单独存储数据,实际中使⽤的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使⽤代码实现以后会发现结构会带来很多优势,在上面的实现我们也验证了这一点
那么链表的内容我们就介绍到这里,如果有什么问题欢迎私信我,接下来的文章我们也会对链表的知识做一个融汇贯通,刷一些题
那么今天就到这里,bye~