Title
题目
Geometry-Aware Attenuation Learning forSparse-View CBCT Reconstruction
稀疏视角CBCT重建的几何感知衰减学习
01
文献速递介绍
稀疏视角锥形束计算机断层扫描(CBCT)重建的几何感知学习方法
锥形束计算机断层扫描(CBCT)广泛应用于临床诊断领域,如牙科、脊柱和血管疾病诊断。相比传统的扇束CT(FBCT),CBCT可以在较短的扫描时间内提供高分辨率图像。CBCT扫描的过程中,X射线源沿弧形轨迹均匀移动,每次角度步进发射锥形X射线束穿过身体,检测器记录二维投影。因此,CBCT重建本质上是一个逆问题,目标是从这些二维投影恢复三维解剖信息。传统方法通常需要数百个投影才能生成高质量的CBCT图像,但这会带来辐射暴露的风险,因此,稀疏视角CBCT重建逐渐受到关注,以减少投影数量并降低辐射剂量。
传统CBCT重建方法多采用滤波反投影(FBP)算法,但这些方法高度依赖大量投影视角。为解决这一局限,一些基于迭代优化的方法被提出,尽管它们能在稀疏输入下提供改进的重建结果,但存在时间效率低、细节不足的问题。近年来,深度学习的兴起使得研究者探索端到端学习投影与CBCT图像映射的技术,但这些方法直接连接多视角信息,忽略了CBCT系统的几何特性,导致结构性误差。与此同时,3D视觉领域的神经渲染技术(如NeRF)已在新视角合成和多视角重建方面取得进展,类似于CBCT重建的概念,但这些方法需对每次CBCT扫描单独优化,耗时较长,尤其在极稀疏视角输入时效果不佳。
稀疏视角CBCT重建面临两大挑战:(1) 如何弥合多视角二维投影与三维CBCT图像之间的维度差异;(2) 如何解决极稀疏视角输入导致的信息不足问题。为此,本研究提出了一种几何感知编码-解码框架,结合了神经渲染的多视角一致性和深度学习的泛化能力。具体而言,框架首先采用二维卷积神经网络(CNN)编码器从不同的X射线投影中提取多视角特征,然后将这些特征回投影到三维空间,弥合维度差异。由于不同视角提供的信息量不同,引入了一种自适应特征融合策略以聚合多视角特征,从而构建三维体积特征,并通过三维CNN解码器解码为三维CBCT图像。
该框架的几何感知确保了从多视角X射线投影中准确提取信息,同时利用大量数据集的先验知识,即使在仅有5或10个视角的极稀疏输入下,仍能很好地泛化到不同患者。对两个模拟数据集和一个真实数据集的实验验证了该方法的有效性和时间效率。
Aastract
摘要
Cone Beam Computed Tomography (CBCT)plays a vital role in clinical imaging. Traditional methodstypically require hundreds of 2D X-ray projections to reconstruct a high-quality 3D CBCT image, leading to considerable radiation exposure. This has led to a growing interestin sparse-view CBCT reconstruction to reduce radiationdoses. While recent advances, including deep learning andneural rendering algorithms, have made strides in this area,these methods either produce unsatisfactory results orsuffer from time inefficiency of individual optimization. Inthis paper, we introduce a novel geometry-aware encoderdecoder framework to solve this problem. Our frameworkstarts by encoding multi-view 2D features from various2D X-ray projections with a 2D CNN encoder. Leveragingthe geometry of CBCT scanning, it then back-projects themulti-view 2D features into the 3D space to formulate acomprehensive volumetric feature map, followed by a 3DCNN decoder to recover 3D CBCT image. Importantly, ourapproach respects the geometric relationship between 3DCBCT image and its 2D X-ray projections during featureback projection stage, and enjoys the prior knowledgelearned from the data population. This ensures its adaptability in dealing with extremely sparse view inputs withoutindividual training, such as scenarios with only 5 or 10X-ray projections. Extensive evaluations on two simulateddatasets and one real-world dataset demonstrate exceptional reconstruction quality and time efficiency of ourmethod.
锥形束计算机断层扫描(CBCT)在临床成像中发挥着重要作用。传统方法通常需要数百个二维X射线投影来重建高质量的三维CBCT图像,从而导致大量的辐射暴露。这引发了对稀疏视角CBCT重建的兴趣,以减少辐射剂量。尽管近年来包括深度学习和神经渲染算法在内的进展在该领域取得了成果,但这些方法要么效果不理想,要么因个体优化的时间低效而受限。在本文中,我们引入了一种新颖的几何感知编码器-解码器框架来解决这一问题。该框架首先通过二维卷积神经网络(CNN)编码器对来自多个二维X射线投影的多视角二维特征进行编码。利用CBCT扫描的几何结构,该框架将多视角二维特征回投影到三维空间以形成综合的体积特征图,随后通过三维CNN解码器恢复三维CBCT图像。重要的是,我们的方法在特征回投影阶段遵循三维CBCT图像与其二维X射线投影之间的几何关系,并借鉴了数据总体中的先验知识。这确保了其在极端稀疏视角输入(例如仅有5或10个X射线投影)情况下的适应性,无需单独训练。基于两个模拟数据集和一个真实数据集的大量评估,验证了我们方法出色的重建质量和时间效率。
Method
方法
Fig. 3 shows the design of our proposed method. Given aset of sparse-view X-ray projections {**Pi} N i=1, our objectiveis to reconstruct the CBCT image V*pred* ∈ R 1×W×H×**D tobe as close as possible to the ground truth one V*gt*. Wefirst extract their features using a shared 2D CNN encoder.Then, we build the 3D feature map by combining feature backprojection module with an adaptive feature fusion process.After this, the 3D feature map is processed by a 3D CNNdecoder to recover the target CBCT image. In particular, onekey step of our method is the feature back projection, whicheffectively bridges the dimensional gap between 2D X-rayprojections and 3D CBCT image. It is crucial for achieving anatomically precise reconstructions. Secondly, the priorknowledge learned from datasets by deep learning, equips ourmodel with the capability to adapt to new patients withoutindividual optimization. It is particularly beneficial in handlingsparse-view inputs with limited information, especially whendealing with 5 or 10 views. These two factors are the primaryreasons why our model could produce satisfactory results withsparse input. Furthermore, our volume-wise CNN decoder actsas a learnable filter to reduce noise and extract more robustfeature representations. It helps us better capture the globalstructure information of the target CBCT image, mitigating streaky artifacts. We will delve into the details of our methodin the following.
图 3 展示了我们提出的方法的设计。给定一组稀疏视角的 X 射线投影 {Pi},我们的目标是将重建的 CBCT 图像 Vpred ∈ R1×W×H×D 尽可能接近真实图像 Vgt。我们首先通过共享的 2D CNN 编码器提取其特征。然后,通过将特征反投影模块与自适应特征融合过程相结合,构建 3D 特征图。在此之后,3D 特征图将通过 3D CNN 解码器处理,以恢复目标 CBCT 图像。特别地,我们方法的一个关键步骤是特征反投影,它有效地弥补了 2D X 射线投影与 3D CBCT 图像之间的维度差距。这个步骤对于实现解剖精确的重建至关重要。其次,通过深度学习从数据集中学习的先验知识,使我们的模型能够适应新患者,而无需个性化优化。在处理有限信息的稀疏视角输入时尤其有利,特别是在处理 5 或 10 个视角时。这两个因素是我们模型能够在稀疏输入下产生令人满意结果的主要原因。此外,我们的体积级 CNN 解码器充当可学习的滤波器,以减少噪声并提取更强健的特征表示。它有助于我们更好地捕捉目标 CBCT 图像的全局结构信息,减轻条纹伪影。我们将在后续部分详细介绍我们的方法。
Conclusion
结论
In this paper, we introduced a novel framework for sparseview CBCT reconstruction. Our method respects the inherentnature of X-ray perspective projection during the featureback projection, ensuring accurate information retrieval frommultiple X-ray projections. Moreover, by leveraging the priorknowledge learned from our extensive dataset, our frameworkefficiently tackles the challenges posed by sparse-view inputs,delivering high-quality reconstructions. The effectiveness andtime efficiency are thoroughly validated through extensivetesting on both simulated and real-world datasets.
在本文中,我们提出了一种用于稀疏视角CBCT重建的新颖框架。该方法在特征回投影过程中遵循X射线透视投影的固有特性,确保从多个X射线投影中准确提取信息。此外,通过利用从大量数据集中学习的先验知识,该框架有效地应对稀疏视角输入带来的挑战,提供高质量的重建效果。通过对模拟数据集和真实数据集的大量测试,我们充分验证了其有效性和时间效率。
Results
结果
parison of 3D CBCT images reconstructed in axial slices fromcase #10 of dental dataset. It is evident that the FDK approach struggles with sparse-view input, leading to significantstreaky artifacts because of the limited number of input views.Although SART reduces these artifacts, it often loses finedetails in the process. When it comes to neural renderingbased methods, NAF achieves decent results with 20 viewsby incorporating neural rendering with hash encoding. Yet,its performance greatly diminishes with very few input views(such as 5 or 10), as it is optimized for individual objectsand lacks prior knowledge learned from the data population.SCOPE3D shows similar performance, as the re-projectionstrategy offers negligible new information. SNAF demonsratesimprovements due to its view augmentation strategy but stillstruggles with 10 or 5 views. PatRecon ignores geometricrelationships among multi-view projections, which results inblurry reconstructions with erroneous structures. Benefitingfrom CNN layers, PixelNeRF enjoys prior knowledge andmaintains multi-view consistency. But it tends to producenoticeable streaky artifacts due to its point-wise MLP decodingand 2D supervision. DIF-Net builds upon the principles ofPixelNeRF, achieving better results due to its 3D supervision.The results with 20 views input are comparable to ours,with slight blurriness and noise as highlighted in the orangebox. However, its performance degrades with sparser inputs,such as 5 views, exhibiting streaky artifacts due to its pointwise MLP decoding approach. This is because the point-wiseMLP independently decodes the attenuation of each querypoint, disregarding the spatial relationships among neighboringvoxel points in CBCT image. MLP decoder is also unable tocapture the global structure information of CBCT image withthe point-wise 3D supervision. As a result, it would deliverstreaky artifacts, especially when facing extremely sparse inputlike 5 views. In contrast, our CNN-based decoding moduleconsiders interactions among neighboring points, effectivelyacting as a learnable filter to mitigate noise and extract morerobust feature representations. Moreover, 3D CNN decoder iscapable of capturing the global structure information with thevolume-wise 3D supervision. Consequently, our reconstructedCBCT images exhibit higher quality with less streaky artifacts.Notably, our approach surpasses all other methods, providingreconstruction quality comparable to the ground truth with 20input views. However, recovering details with high fidelitybecomes challenging for our method when facing 10 or 5views. Despite this limitation, our method still maintains aclear advantage over the competition, showing less streakyartifacts and preserving a better global structure.
图 5 展示了来自牙科数据集第 10 号病例的 3D CBCT 图像在轴向切片中的并排比较。显然,FDK 方法在稀疏视角输入下效果较差,因输入视角数量有限导致显著的条纹伪影。虽然 SART 方法能够减少这些伪影,但在处理过程中常常会丢失细节。对于基于神经渲染的方法,NAF 在 20 个视角的情况下通过将神经渲染与哈希编码结合,达到了较好的效果。然而,当输入视角非常少(例如 5 或 10 个)时,其性能急剧下降,因为它是针对单个物体优化的,且缺乏从数据集群体中学习的先验知识。SCOPE3D 表现相似,因为其重新投影策略带来的新信息微乎其微。SNAF 通过视角增强策略有所改善,但在 10 个或 5 个视角时仍然表现不佳。PatRecon 忽视了多视角投影之间的几何关系,导致重建图像模糊,结构错误。借助 CNN 层,PixelNeRF 利用了先验知识,保持了多视角一致性,但由于其点式 MLP 解码和 2D 监督,它会产生明显的条纹伪影。DIF-Net 基于 PixelNeRF 的原理进行改进,得到了更好的结果,因为它具有 3D 监督。20 个视角输入下的结果与我们的结果相当,稍微有一些模糊和噪声(如橙色框中所示)。然而,当输入视角更稀疏(如 5 个视角)时,其性能下降,出现条纹伪影,原因在于其点式 MLP 解码方法。点式 MLP 独立解码每个查询点的衰减,忽略了 CBCT 图像中相邻体素点之间的空间关系。MLP 解码器也无法捕捉 CBCT 图像的全局结构信息,因此会产生条纹伪影,尤其是在输入视角极其稀疏(如 5 个视角)时。相比之下,我们基于 CNN 的解码模块考虑了相邻点之间的相互作用,能够有效地作为可学习的滤波器来减轻噪声,并提取更强健的特征表示。此外,3D CNN 解码器能够通过体积级 3D 监督捕捉全局结构信息。因此,我们重建的 CBCT 图像具有更高的质量,条纹伪影较少。值得注意的是,我们的方法在所有其他方法中表现最佳,且在 20 个输入视角下的重建质量与真实图像相当。然而,当面对 10 或 5 个视角时,我们的方法在恢复高保真细节时面临挑战。尽管如此,我们的方法仍然保持了相对于其他方法的明显优势,条纹伪影较少,并且保留了更好的全局结构。
Figure
图

Fig. 1. CBCT scanning and reconstruction. In the CBCT imaging process, CBCT scanning (a) would generate a sequence of 2D X-ray projections(b). These projections are utilized to reconstruct 3D CBCT image (c)
图1:CBCT扫描与重建。在CBCT成像过程中,CBCT扫描(a)会生成一系列二维X射线投影(b)。这些投影用于重建三维CBCT图像(c)。
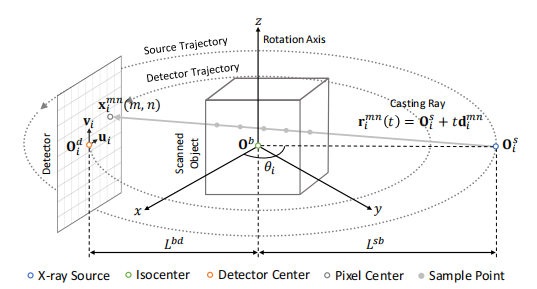
Fig. 2. Geometric configuration of CBCT scanning and X-ray projectionsimulation.
图2:CBCT扫描和X射线投影模拟的几何配置。
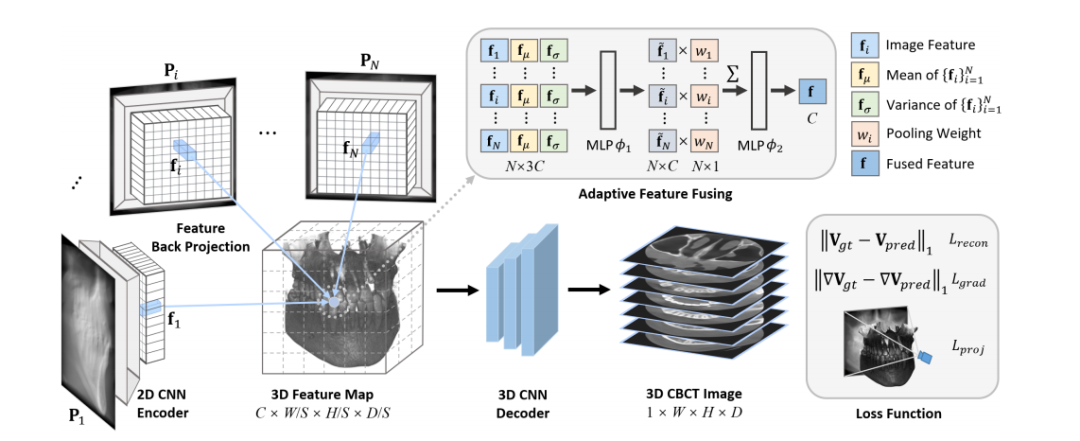
Fig. 3. Overview of our proposed method. A 2D CNN encoder first extracts feature representations from multi-view X-ray projections. Then, webuild a 3D feature map by feature back projection and adaptive feature fusing. Finally, this 3D feature map is fed into a 3D CNN decoder to producethe final CBCT image.
图3:我们提出的方法概述。首先,二维卷积神经网络(CNN)编码器从多视角X射线投影中提取特征表示。然后,我们通过特征回投影和自适应特征融合构建三维特征图。最后,将该三维特征图输入三维卷积神经网络解码器,以生成最终的CBCT图像。
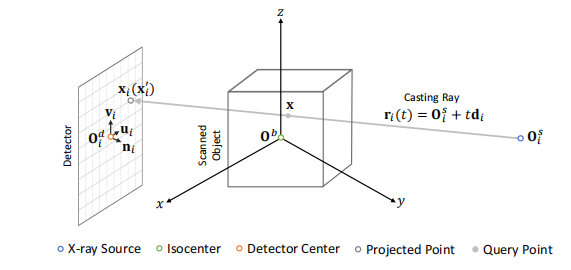
Fig. 4. Coordinate transformation of query point for feature backprojection.
图4. 特征后投影查询点的坐标变换。
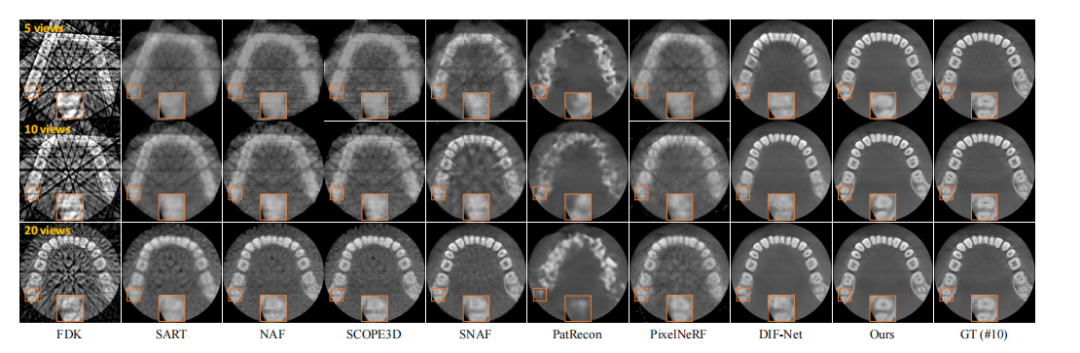
Fig. 5. Qualitative comparison on case #10 from dental dataset (axial slice). Window: [-1000, 2000] HU.
图5:牙科数据集案例#10的定性比较(轴向切片)。窗宽:[-1000, 2000] HU。
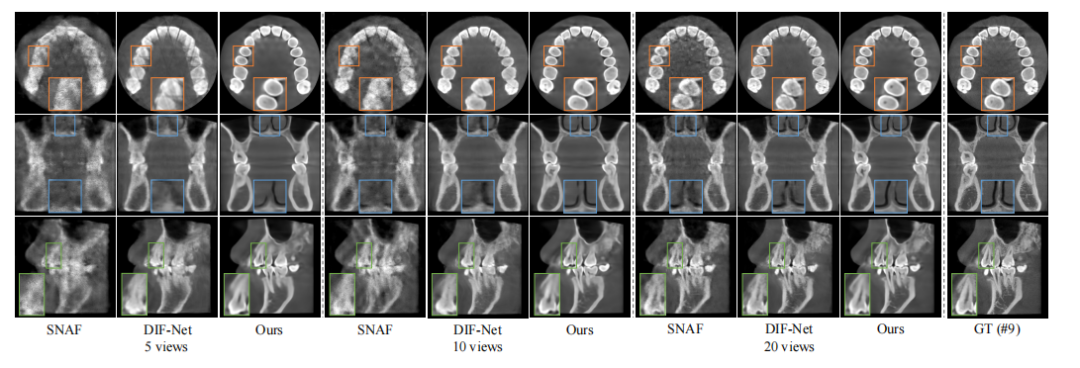
Fig. 6. Qualitative comparison with SNAF and DIF-Net on case #9 from dental dataset. From top to bottom: axial, coronal, and sagittal slices.Window: [-1000, 2000] HU.
图6:在牙科数据集的案例#9上与SNAF和DIF-Net的定性比较。从上到下分别为轴向、冠状和矢状切片。窗宽:[-1000, 2000] HU。
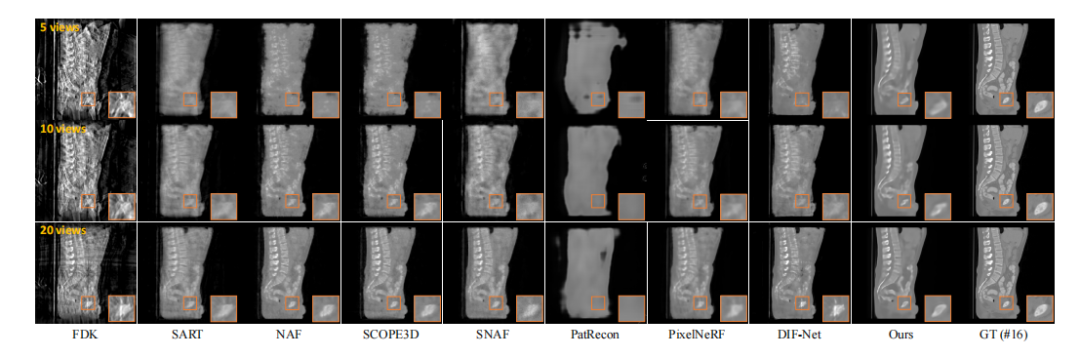
Fig. 7. Qualitative comparison on case #16 from spine dataset (sagittal slice). Window: [-1000, 1000] HU.
图7:脊柱数据集案例#16的定性比较(矢状切片)。窗宽:[-1000, 1000] HU。
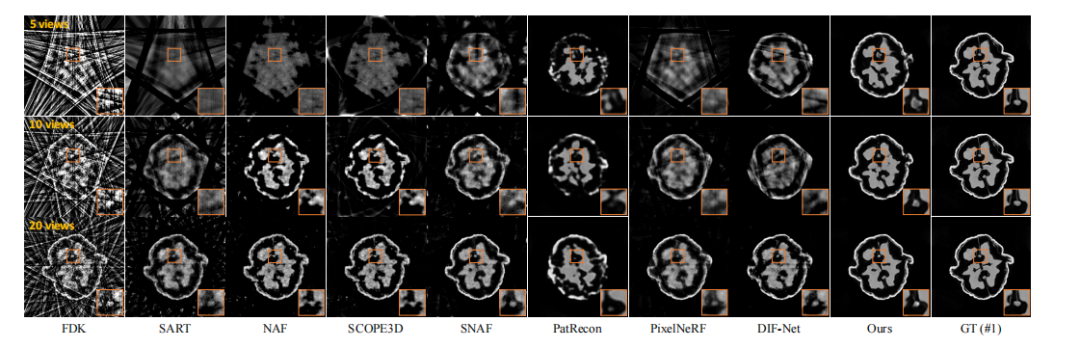
Fig. 8. Qualitative comparison on case #1 from walnut dataset (axial slice). Window: [-1000, 2000] HU
图8:核桃数据集案例#1的定性比较(轴向切片)。窗宽:[-1000, 2000] HU。
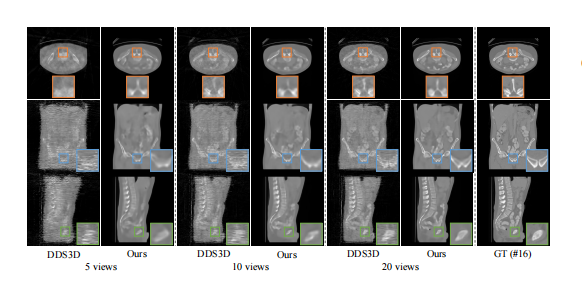
Fig. 9. Qualitative comparison with DDS3D on case #16 from spinedataset. From top to bottom: axial, coronal, and sagittal slices. Window:[-1000, 1000] HU.
图9:脊柱数据集案例#16与DDS3D的定性比较。从上到下分别为轴向、冠状和矢状切片。窗宽:[-1000, 1000] HU。
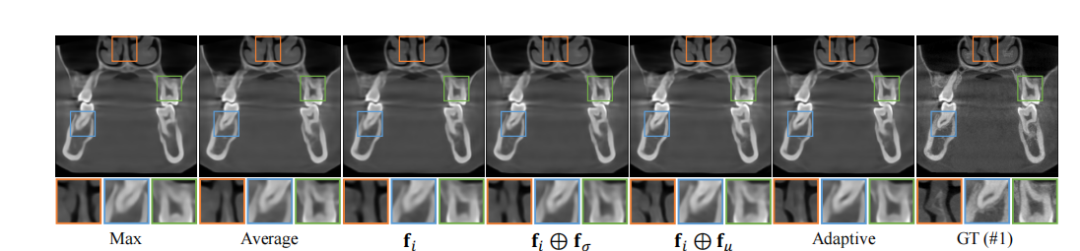
Fig. 10. Qualitative results of ablation study on feature fusing strategy on case #1 from dental dataset (coronal slice). Window: [-1000, 2000] HU.
图10:牙科数据集案例#1上关于特征融合策略的消融研究的定性结果(冠状切片)。窗宽:[-1000, 2000] HU。
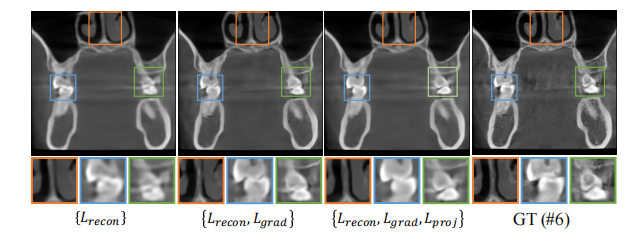
Fig. 11. Qualitative results of ablation study on loss term on case #6from dental dataset (coronal slice). Window: [-1000, 2000] HU.
图11:牙科数据集案例#6上关于损失项的消融研究的定性结果(冠状切片)。窗宽:[-1000, 2000] HU。
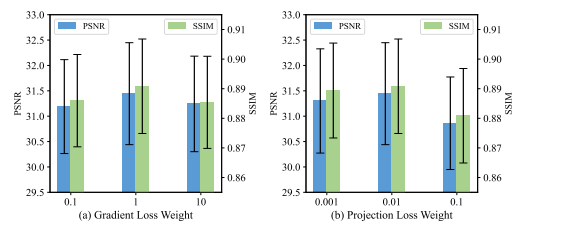
Fig. 12. Quantitative results of ablation study on (a) gradient lossweight and (b) projection loss weight on dental dataset
图12:牙科数据集上关于(a) 梯度损失权重和(b) 投影损失权重的消融研究的定量结果。
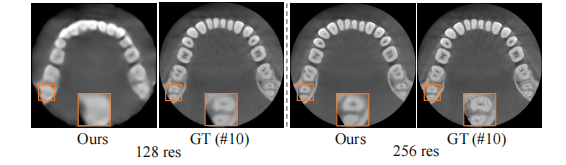
Fig. 13: Model robustness to noisy data.
图13:模型对噪声数据的鲁棒性。
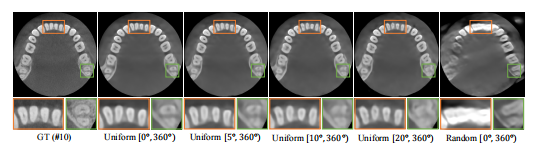
Fig. 14. Qualitative results of robustness analysis on angle samplingon case #10 from dental dataset (axial slice). Window: [-1000, 2000] HU.
图14:牙科数据集案例#10上关于角度采样的鲁棒性分析的定性结果(轴向切片)。窗宽:[-1000, 2000] HU。
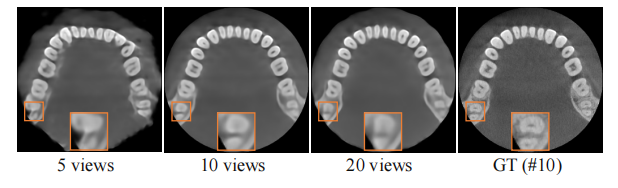
Fig. 15. Qualitative results of robustness analysis on number of inputviews on case #10 from dental dataset (axial slice). Window: [-1000,2000] HU
图15:牙科数据集案例#10上关于输入视角数量的鲁棒性分析的定性结果(轴向切片)。窗宽:[-1000, 2000] HU。
Table
表
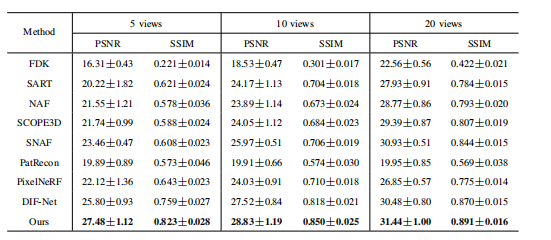
TABLE I table iquantitative comparison on dental dataset. the best performance is shown in bold
表1:牙科数据集上的定量比较。最佳性能以粗体显示。
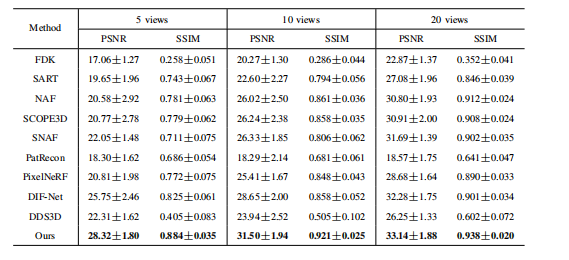
TABLE II quantitative comparison on spine dataset. the best performance is shown in bold
表2:脊柱数据集上的定量比较。最佳性能以粗体显示。
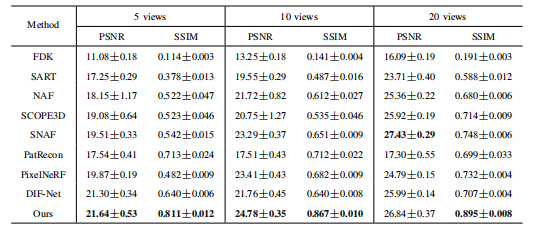
TABLE III quantitative comparison on walnut dataset. the best performance is shown in bold.
表3:核桃数据集上的定量比较。最佳性能以粗体显示。
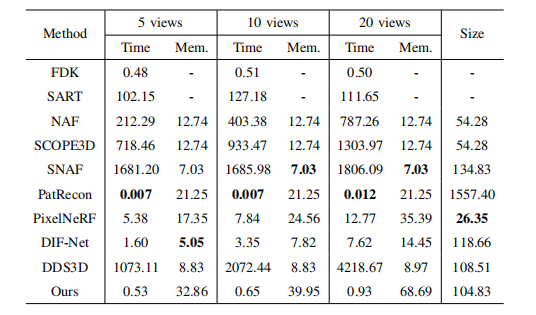
TABLE IV efficiency analysis. the best-performing is shown in bold. unit: time (s); mem. (gb): gpu memory consumption in training; size (mb).
表4:效率分析。最佳性能以粗体显示。单位:时间(秒);内存(GB):训练中GPU内存消耗;大小(MB)。
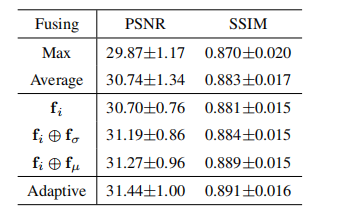
TABLE V quantitative results of ablation study on feature fusing strategy on dental dataset.
表5:牙科数据集上关于特征融合策略的消融研究的定量结果。

TABLE VI quantitative results of ablation study on loss term on dental dataset.
表6:牙科数据集上关于损失项的消融研究的定量结果。
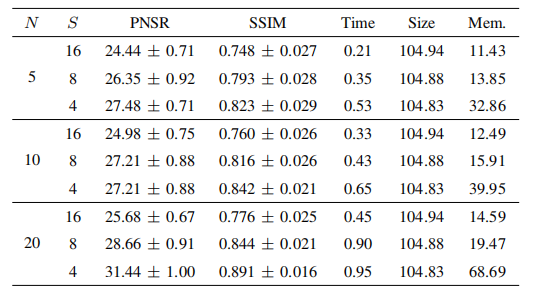
TABLE VII ablation study on downsampling rate s. unit: time (s); size (mb); mem. (gb): gpu memory consumption in training.
表7:关于下采样率S的消融研究。单位:时间(秒);大小(MB);内存(GB):训练中GPU内存消耗。
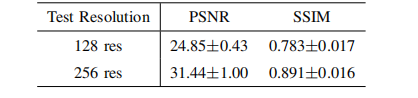
TABLE VIII q reconstruction resolution on dental dataset quantitative results of robustness analysis on.
表8:牙科数据集上重建分辨率的鲁棒性分析的定量结果。
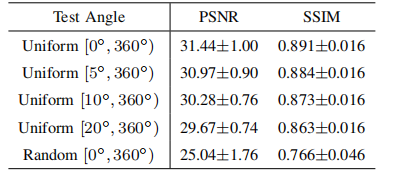
TABLE IX quantitative results of robustness analysis on anglesampling on dental dataset.
表9:牙科数据集上关于角度采样的鲁棒性分析的定量结果。
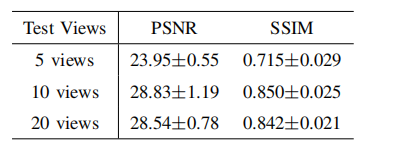
TABLE X quantitative results of robustness analysis on number of input views on dental dataset.
表10:牙科数据集上关于输入视角数量的鲁棒性分析的定量结果。