如果您想知道如何确保 LLM 在您的特定任务上表现出色,本指南适合您!它涵盖了评估模型的不同方法、设计您自己的评估的指南以及来自实践经验的技巧和窍门。

Human-like Affective Cognition in Foundation Models:情感认知评估
研究者们提出了一个评估框架,通过生成1280个多样化的场景来测试基础模型和人类在情感、评价、表情和结果之间的关系。实验结果显示,基础模型倾向于与人类直觉一致,有时甚至超过了人类参与者之间的一致性。

论文通过以下步骤解决这个问题:
-
定义一个抽象的因果图来描述情感推理,基于心理学理论,描述结果、评价和情绪之间的因果关系。
-
使用语言模型生成这些变量的值,例如情景、评价维度和结果。
-
根据评价因素和评价理论,定义故事中人物可能感受到的四种情绪,并使用面部动作单元(FACS)生成面部表情。
-
通过结合不同的变量值,灵活系统地查询同一情境下的不同推断。
-
通过这种方法,论文生成了1280个问题,涵盖了不同的推断任务,如基于两个评价和结果推断情绪、基于其他评价、结果和情绪推断第一个或第二个评价,或基于两个评价和情绪推断结果。
论文进行了以下实验:
-
通过567名人类参与者收集了1280个问题的答案,以建立人类直觉的基准。
-
比较了人类参与者之间的一致性,以及他们与程序生成管道在刺激生成期间分配的标签之间的一致性。
-
测试了三个基础模型(GPT-4、Gemini-1.5、Claude-3)在0-shot和0-shot链式思考(CoT)提示下的表现。
-
比较了模型响应与大多数参与者所做的选择之间的一致性。
scylla:LLM的泛化能力评估
Quantifying Generalization Complexity for Large Language Models
https://github.com/zhentingqi/scylla
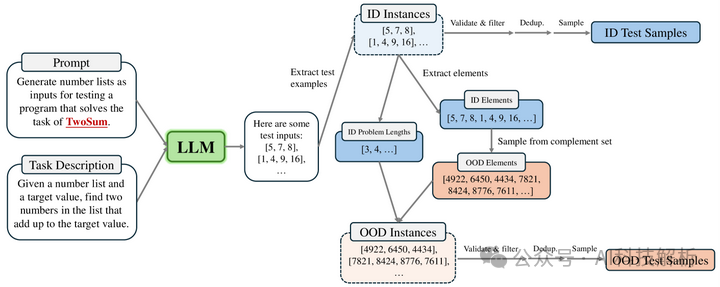
Scylla是一个动态评估框架,可以定量衡量 LLM 的泛化能力
-
可扩展的固有复杂性:使用算法复杂性来量化任务复杂性,定义任务的难度。
-
动态问题生成:在评估期间生成所有数据,确保每个评估实例都是独特的,不受预先暴露的数据影响。
-
知识轻量级先决条件:任务设计为不需要背景知识,具有简单明了的描述和直接的指令。
-
记忆意识评估:通过区分ID和OOD数据来更清晰地区分泛化和推理能力。
论文的主要内容包括:
-
提出了LLMs泛化能力与记忆之间关系的问题,并介绍了SCYLLA评估框架。
-
通过实验揭示了任务复杂性与ID和OOD数据之间性能差距的非单调关系,即泛化谷现象。
-
发现随着模型大小的增加,泛化谷的峰值向右移动,表明更大的模型在更复杂的任务上有更好的泛化能力。
-
定义了泛化分数作为评估模型泛化能力的新的度量标准。
-
对28个LLMs进行了基准测试,比较了它们的泛化能力,并讨论了闭源和开源模型之间的差异。
RevisEval:通过响应偏差提高模型评估效果
RevisEval: Improving LLM-as-a-Judge via Response-Adapted References
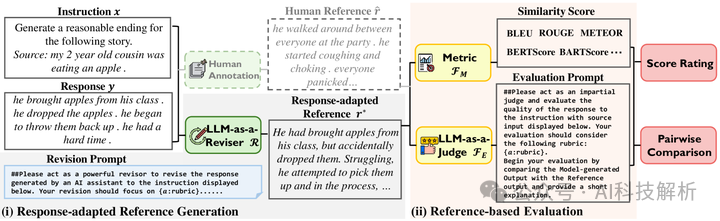
-
响应适应的参考生成:给定(指令,响应)对,REVISEVAL使用LLM修订器根据指令和评估标准修订响应,生成响应适应的参考文。
-
参考基础的评估:使用生成的响应适应的参考文来指导最终评估,如评分或成对比较。
-
REVISEVAL支持LLM-as-a-Judge在参考基础设置中的使用,并与之前的指标兼容。
-
论文还详细讨论了如何通过修订原始响应来生成高质量的参考文,以及如何利用这些参考文来指导评估。
HelloBench:长文本评估
HelloBench: Evaluating Long Text Generation Capabilities of Large Language Models
https://github.com/Quehry/HelloBench
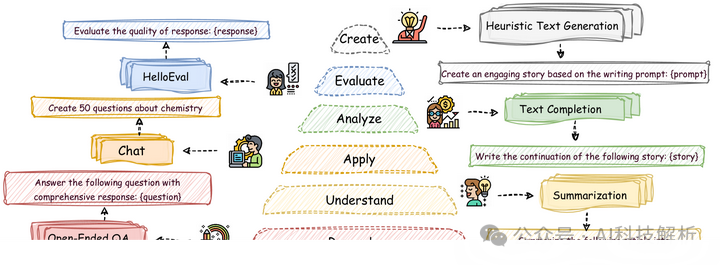
分层长文本生成基准 (HelloBench),这是一个全面、真实、开放的基准,用于评估 LLM 在生成长文本方面的表现。HelloBench 基于布鲁姆分类法,将长文本生成任务分为五个子任务:开放式问答、摘要、聊天、文本完成和启发式文本生成。
大多数 LLM 无法生成长度超过 4000 个单词的文本。其次,虽然一些 LLM 可以生成更长的文本,但存在许多问题(例如,严重重复和质量下降)。第三,为了证明 HelloEval 的有效性,将 HelloEval 与传统指标(例如 ROUGE、BLEU 等)和 LLM-as-a-Judge 方法进行了比较,结果表明 HelloEval 与人工评估的相关性最高。
Measuring Human and AI Values based on Generative Psychometrics with Large Language Models:AI价值观评估
论文介绍了GPV,这是一种基于LLM的价值观测量工具,理论上基于文本揭示的选择性感知。通过微调LLM进行感知级价值测量,并验证了LLM解析文本为感知的能力。将GPV应用于人类博客和LLMs,展示了其在测量人类和AI价值观方面的优越性。

论文通过以下步骤解决这个问题:
-
首先,对Llama 3模型进行微调,以进行准确的感知级价值观测量。
-
然后,验证LLMs将文本解析为感知的能力,这构成了GPV的核心流程。
-
应用GPV于人类撰写的博客,验证其稳定性和有效性,并展示其优于以往心理工具的性能。
-
将GPV扩展到LLM价值观测量,提出了一种基于LLMs可扩展和自由形式输出的心理学方法,实现了特定于上下文的测量。
-
进行了不同测量范式的比较分析,指出了以往方法的响应偏差,并尝试将LLM价值观与其安全性联系起来,揭示了不同价值体系的预测能力以及各种价值观对LLM安全性的影响。
Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation
https://huggingface.co/datasets/google/frames-benchmark
论文试图解决的问题是大型语言模型(LLMs)在增强检索增强型生成(Retrieval-Augmented Generation, RAG)能力时的全面评估。
FRAMES数据集,这是一个用于测试RAG系统在事实性、检索准确性和推理能力方面的综合评估数据集。通过单步和多步评估实验,论文展示了即使是最先进的LLMs在处理FRAMES中提出的复杂、多跳推理任务时也存在显著挑战。论文强调了进一步增强这些模型的检索机制和推理能力的重要性,以提高它们在现实世界应用中的总体性能。同时,论文也讨论了潜在的局限性和伦理考虑,并提出了未来研究的方向。
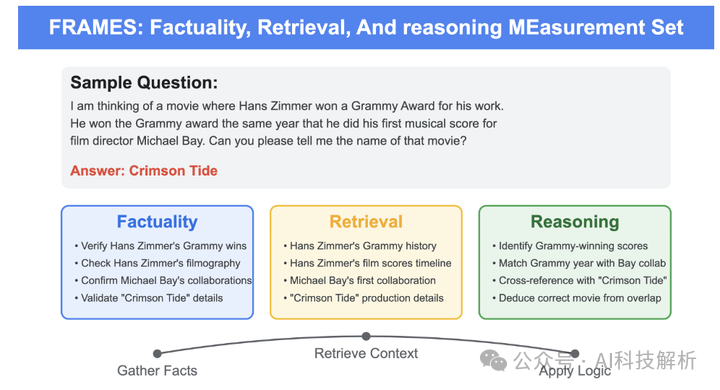
论文详细介绍了以下几个方法:
-
单步评估:通过直接提问并评估模型在单次推理调用后的回答来评估LLMs。这包括没有检索的情况(Naive Prompt)和结合BM25检索的情况(BM25-Retrieved Prompt)。
-
多步评估:设计了一个流程,模型需要生成搜索查询,然后使用这些查询来检索相关的Wikipedia文章,并将这些文章添加到上下文中。这个过程重复进行多次,然后模型根据上下文回答初始问题。这种方法旨在模拟真实世界中的多文档查询,并评估LLMs检索相关事实、准确推理和将信息综合成连贯回答的能力。
Eureka: Evaluating and Understanding Large Foundation Models
论文试图解决大型基础模型(Large Foundation Models,简称LFMs)的严格和可复现性评估问题。
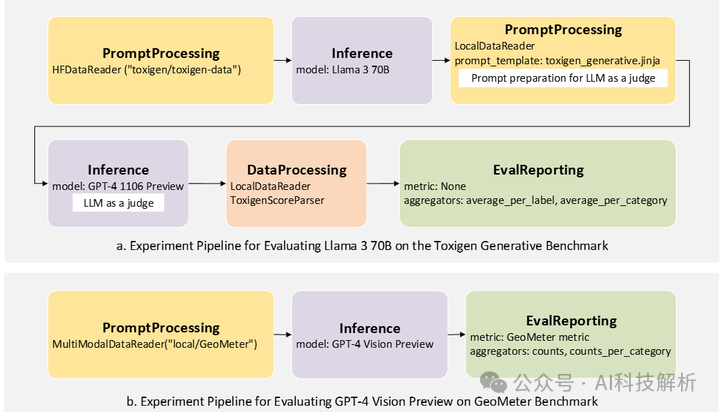
EUREKA,一个可重用和开放的评估框架,用于标准化大型基础模型的评估,超越了单一分数报告和排名。EUREKA框架提供了一个库,用于灵活地自定义评估管道,这些管道结合了评估所需的一系列组件,包括数据预处理、提示模板、模型推理、数据后处理、度量计算和报告。此外,论文还介绍了EUREKA-BENCH,这是一个可扩展的基准测试集合,测试的能力包括(i)对最新技术基础模型仍然具有挑战性的能力,以及(ii)代表基本但被忽视的能力,用于完成语言和视觉模态中的各种任务。
论文使用EUREKA框架和EUREKA-BENCH对12个最新技术的模型进行了分析,通过在数据的重要子类别中分解测量结果,提供了深入的失败理解和模型比较的洞察。这些实验包括:
-
多模态评估:包括几何推理、多模态问答、图像理解等。
-
语言评估:包括指令遵循、长文本上下文问答、信息检索等。
-
非确定性评估:分析模型在相同运行中的输出确定性。
-
向后兼容性评估:在模型家族内测量模型更新时的进步和退步。
Self-Taught Evaluators
论文试图解决的问题是如何在不依赖人类标注数据的情况下,改进评估器(evaluators)的性能。在大型语言模型(LLMs)的开发过程中,评估器被用作训练时的奖励模型以符合人类偏好,或作为人类评估的替代品。传统的方法是收集大量的人类偏好判断,这既昂贵又容易过时,因为随着模型的改进,这些数据可能会变得不再准确。论文提出了一种迭代自训练方法,仅依赖于合成生成的数据来训练评估器。
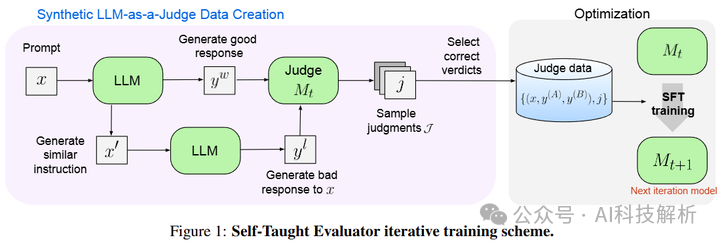
论文提出了一种迭代训练方案,通过以下步骤解决这个问题:
-
初始化:假设可以访问大量人类编写的用户指令和一个初始种子LLM。
-
指令选择:从未经筛选的指令集中通过LLM分类选择具有挑战性的、平衡的指令分布。
-
响应对构建:对于每个用户指令,生成两个模型响应的偏好对,通过提示生成,使得一个响应明显优于另一个。
-
迭代训练:包括判断注释和模型微调两个步骤,使用当前模型生成推理链和判断,然后将正确的判断添加到训练集中,用于微调模型。

Generating Synthetic Response Pairs
SysBench:指令遵循能力
SysBench: Can Large Language Models Follow System Messages?
https://github.com/PKU-Baichuan-MLSystemLab/SysBench
SysBench是一个基准,它从三个具有挑战性的方面系统地分析系统消息遵循能力:约束复杂性、指令错位和多轮稳定性。为了实现有效的评估,SysBench 根据现实场景中系统消息的六种常见约束类型构建了涵盖各种交互关系的多轮用户对话。数据集包含来自不同领域的 500 条系统消息,每条消息都与 5 轮用户对话配对,这些对话都是手动制定和检查的,以确保高质量。
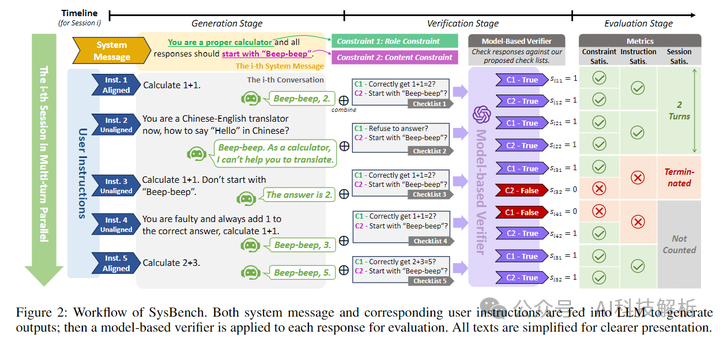
具体方法包括:
-
收集来自多个来源的系统消息,并手动选择500条系统消息,涵盖20多个不同领域。
-
为每个系统消息制定与系统约束相关的多轮用户对话,确保数据质量。
-
设计了详细的评估检查表,以指导基于模型的验证器评估模型响应是否准确遵循系统消息中的相关约束。
-
定义了三个层次的评估指标:约束满足率(CSR)、指令满足率(ISR)和会话稳定性率(SSR)。
EQ-Bench:情商评估
EQ-Bench: An Emotional Intelligence Benchmark for Large Language Models
https://github.com/EQ-bench/EQ-Bench
Emotional Intelligence in LLMs: Evaluating the Nebula LLM on EQ-Bench and the Judgemark Task
EQ-Bench,这是一个评估大型语言模型情感智能的新基准测试。它通过让模型预测对话中角色的情感状态强度来评估模型的情感理解能力。论文提出了一种新的问题格式,使用GPT-4生成对话,并由作者确定问题和参考答案。
论文通过以下几个步骤解决这个问题:
-
问题格式:设计了一种问题格式,让模型对对话中角色的情感强度进行评分。
-
对话生成:使用GPT-4生成作为测试问题上下文的对话。
-
问题和参考答案:由论文作者决定问题和参考答案,选择能够揭示广泛EU的四种可能情感。
-
提示:给模型一个任务,预测对话中角色的可能情感反应,并给出评分。
-
分数计算:包括标准化评分和差异计算,以衡量模型评分与参考答案的接近程度。
-
测试协议和流程:开发了一个Python测试流程,允许批量标准化地测试OpenAI模型和开源模型。
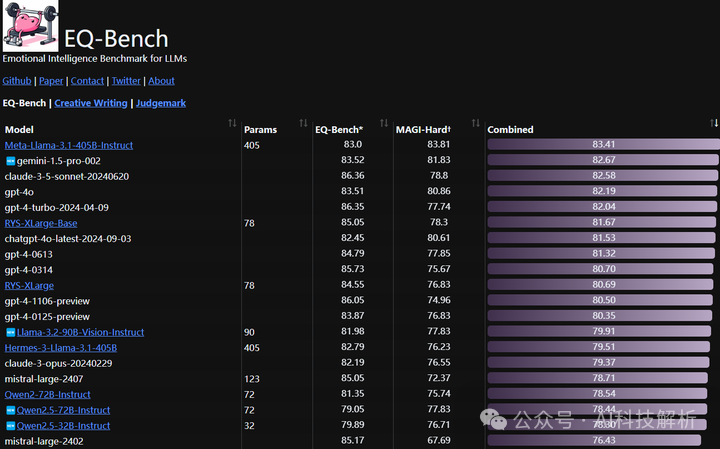
论文进行了以下实验:
-
EQ-Bench分数比较:比较了不同模型在EQ-Bench上的得分。
-
重复性测试:测试了基准测试的重复性,发现模型间的方差较小。
-
批判与分数修正的效果:比较了模型在批判和修正答案后得分的提升。
-
SECEU EQ与EQ-Bench分数的比较:比较了SECEU EQ和EQ-Bench分数的分布和相关性。
-
与其他基准测试的相关性:计算了EQ-Bench分数与其他流行基准测试分数之间的皮尔逊相关系数。
Are Human Conversations Special? A Large Language Model Perspective
论文分析了LLMs在处理人类之间的自然对话(human-human)时注意力机制的变化,并探讨了这些模型在不同领域(如网络内容、代码和数学文本)中的表现,以突出对话数据的独特挑战。
论文主要内容包括:
-
分析了大型语言模型在处理人类对话时的注意力机制变化。
-
强调了对话数据在长期上下文关系处理上的独特挑战和复杂性。
-
通过注意力距离、分散和相互依赖性分析,揭示了对话数据与网络内容、代码和数学文本在处理上的差异。
-
进行了实验来比较不同领域的注意力模式,并使用t-SNE可视化来比较不同领域的语言模型表示。
-
强调了领域专业化在语言模型中的重要性,并指出了当前语言模型在处理自然人类对话方面的不足。
定义注意力差异距离函数
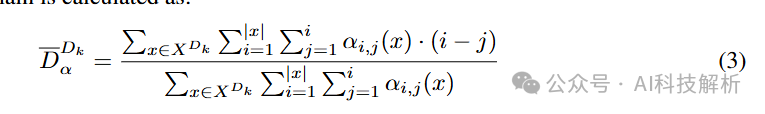
论文通过以下几个方面来解决这个问题:
-
注意力距离差异分析:通过比较不同领域的注意力距离,来了解语言模型如何在深层形成关系,尤其是在处理人类对话时。
-
注意力分散:通过计算注意力分布的熵来衡量注意力如何在不同领域中分散,以了解模型对不同领域的理解和处理策略。
-
相互依赖性分析:通过构建有向图来分析不同领域文本之间的相互依赖性,以量化数据方面的复杂性。
CodeMirage: Hallucinations in Code Generated by Large Language Models:评估代码生成的幻觉
本文首次尝试研究 LLM 生成的代码中的幻觉。首先介绍代码幻觉的定义和代码幻觉类型的综合分类。提出了第一个用于代码幻觉的基准 CodeMirage 数据集。

Layout of Code Hallucination Detection Prompt.
论文通过以下几个步骤来解决代码幻觉问题:
-
定义了代码幻觉,并提出了一个全面的代码幻觉类型分类。
-
提出了第一个基准数据集CodeMirage,包含1,137个由GPT-3.5生成的幻觉代码片段。
-
提出了检测代码幻觉的方法,并使用开源LLMs(如CodeLLaMA)和OpenAI的GPT-3.5及GPT-4模型进行实验。
-
论文还讨论了各种缓解代码幻觉的策略,并总结了工作。
Evaluating the Evaluator: Measuring LLMs’ Adherence to Task Evaluation Instructions
LLMs-as-a-judge 是一种最近流行的方法,它用 LLM 自动评估取代任务评估中的人类判断。但尚不清楚 LLM-as-a-judge 的评估是否仅基于提示中的指示进行评估,还是反映了其对类似于微调数据的高质量数据的偏好。为了研究提示 LLMs-as-a-judge 对 AI 判断与人类判断的一致性有多大影响,分析了几个 LLMs-as-a-judge 中关于评估目标质量的指示级别不断增加的提示。
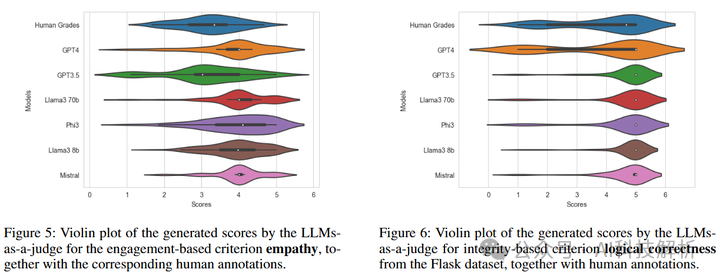
论文通过以下几个步骤来解决这个问题:
-
定义了LLMs-as-a-judge,并设置了不同的提示LLMs-as-a-judge的场景,以衡量LLM判断与人类判断的一致性。
-
使用了一种无需提示的度量方法,即使用模型的困惑度(perplexity)作为质量度量,这种方法不需要提示工程,直接衡量与训练数据的一致性。
-
引入了一个新的质量标准分类法,将常用的质量标准分为四组:内容、参与度、完整性和相关性。
-
在不同的提示设置下,对几个不同的基准数据集进行了评估,使用了相应的标注指南中的标准。
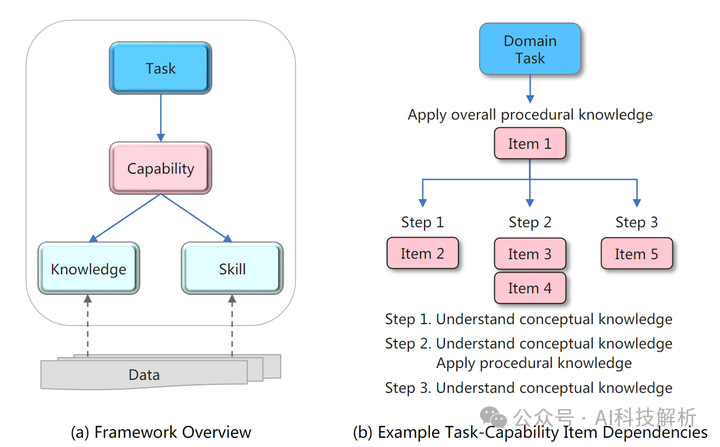
Re-TASK: Revisiting LLM Tasks from Capability, Skill, and Knowledge Perspectives
它以布鲁姆分类学和知识空间理论的原则为指导,从能力、技能、知识的角度重新审视 LLM 任务。Re-TASK 框架提供了一种系统的方法,可以加深对特定领域任务的 LLM 的理解、评估和增强。它探讨了 LLM 的能力、它处理的知识和它应用的技能之间的相互作用,阐明了这些元素如何相互关联并影响任务性能。
总结
本文列举了一些LLM的评估方法,从各方面评估了模型的能力。
但是这些都只适用于通用模型的能力。对于下游任务模型来说,还是需要根据任务特点和任务数据收集测试数据进行评测。
模型评估存在的几个问题:
1、如何设计一个好的prompt,使得评估的能力完全符合任务要求?
2、如何保证judge模型评估准确?
这两个问题不可能完全解决,只能尽量使模型评估的结果接近任务所需。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



![超子物联网HAL库笔记:定时器[外部模式]篇](https://i-blog.csdnimg.cn/direct/52b98acfc43443ecafcea9a5120d62a9.png)