Meta发布了LLaMA的新版本。该版本将被称为LLaMA 2,并且可以免费用于研究和商业用途。这是Meta和Microsoft联合发布的成果。
我认为微软希望垄断所有第三方LLM,并将它们作为SaaS(软件即服务)保留在自己的平台上作为商业产品。现在,OpenAI和LLaMA都将成为微软产品系列的一部分。
新内容
将包含预训练模型和会话微调版本的模型权重和起始代码。
这意味着不再需要去4chan获取权重并构建自己的模型。这个模型的架构和模型权重都可以免费用于商业目的。
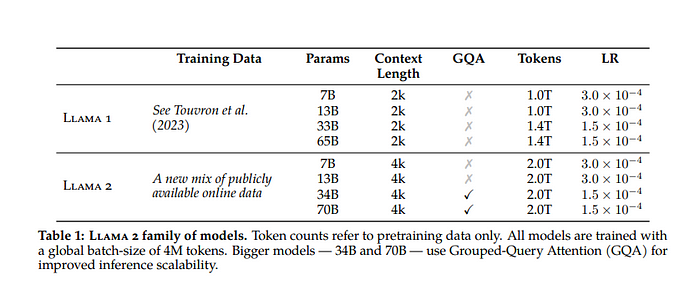
该模型有3个版本 — LLaMA-2–7B LLaMA-2–13B LLaMA-2–70B 所有这些模型都将作为基础模型和相应的CHAT模型发布。因此,总共将会在六个月内发布。
最小的7B和13B版本应该适合现代消费级GPU,而较大的70B版本应该适合A100 GPU。
默认情况下,上下文长度为4096,但可以增加。
该模型训练了2万亿个标记。
7B和13B的架构与它们的旧版本类似,但70B是一个新发布的版本。
该模型经过针对Chat使用场景的微调,并使用了100,000个样本和超过一百万人类偏好进行了监督式微调。
性能:
这个模型应该与大多数开源模型不相上下。特别是与Falcon-40B(目前的冠军)相比,该模型在所有任务上表现明显更好。
标准测试
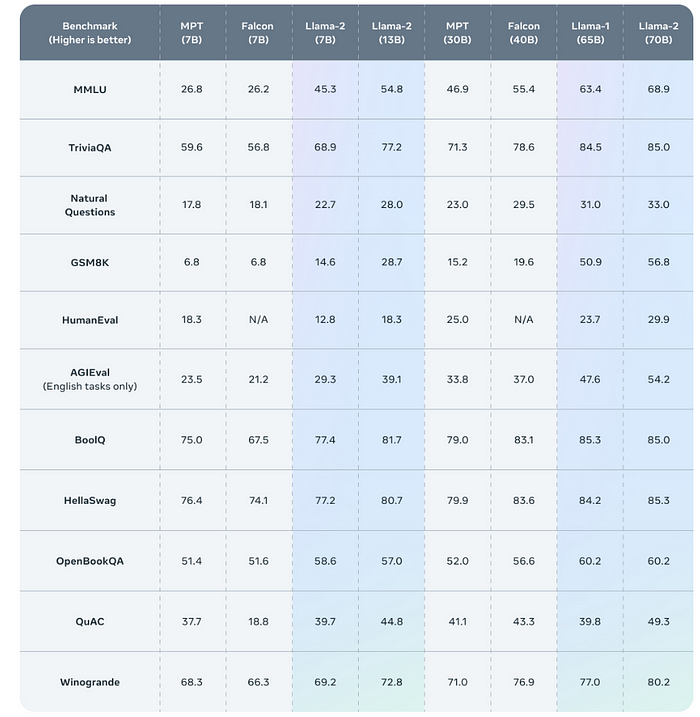
人工评估结果
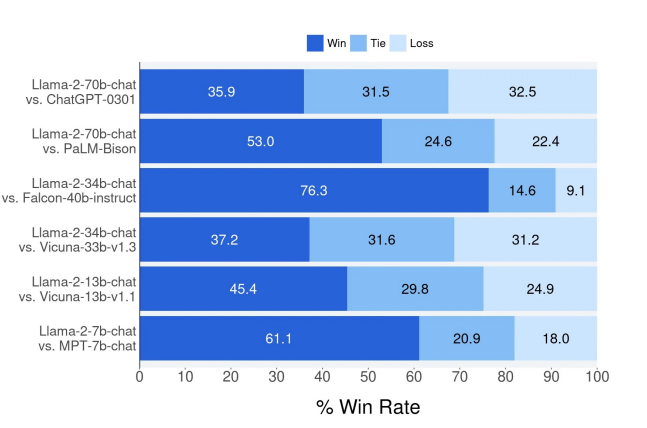
人工评估员在约4,000个提示上对模型的不同版本进行了比较,其中包括单一回合和多回合的提示。该评估的95%置信区间在1%到2%之间。在审查这些结果时,需要注意人工评估可能存在噪音,这是由于提示集的限制、评估准则的主观性、个体评估员的主观性以及比较不同版本的固有难度所导致的。
GPT-4基于的安全性评估
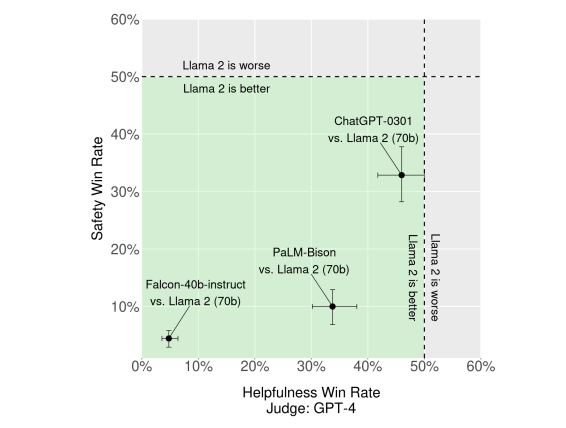
为了补充人工评估,我们使用GPT-4对LLaMA-2进行了比较。绿色区域表示根据GPT-4的评估,我们的模型表现更优。为了排除平局,我们使用胜利次数/总数。为了减轻偏见,模型响应的展示顺序被随机交换。
安全性评价
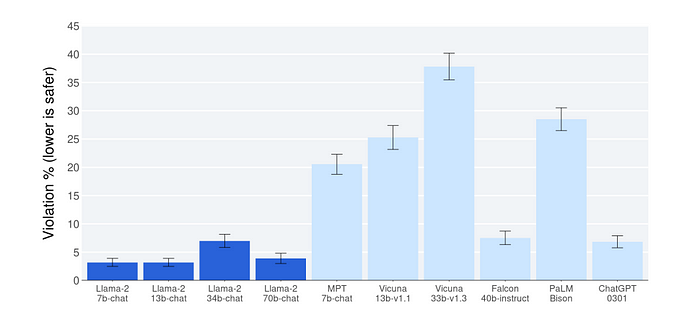
Llama 2-Chat 与其他开源和闭源模型相比的安全评估结果。
.
评估员对大约2,000个敌对性提示的模型生成结果进行了安全性违规的判断,其中包括单一回合和多回合的提示。需要注意,这些安全性结果可能存在来自LLM评估固有偏见的限制,这是由于提示集的限制、评估准则的主观性和个体评估员的主观性所导致的。此外,这些安全性评估是使用可能偏向Llama 2-Chat模型的内容标准进行的。
训练方案
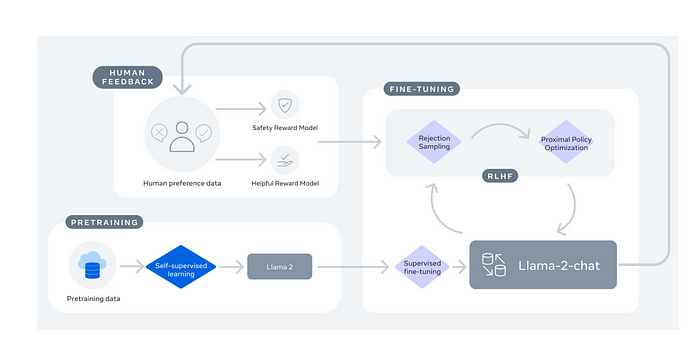
Llama 2-Chat 的训练
- 预训练:该过程从使用公开可用的在线资源对Llama 2进行预训练开始。 监督式微调:通过应用监督式微调创建Llama 2-Chat的初始版本。 强化学习:随后,使用强化学习与人类反馈(RLHF)方法对模型进行迭代优化,具体包括拒绝抽样和近端策略优化(PPO)。在整个RLHF阶段,累积迭代奖励建模数据与模型增强并行进行是至关重要的,以确保奖励模型保持在分布范围内。
训练时间
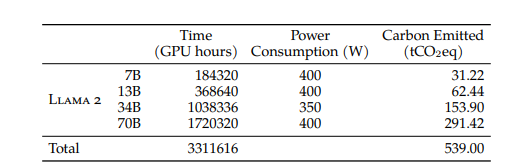
训练一个规模是原来的10倍,模型成本是线性的(GPU小时和碳足迹均为1,720,320/184,320)。然而,在各个任务领域中的改进幅度从14%(常识推理)到130%(编码)不等。训练一个规模是原来的10倍大的模型主要集中在编码任务、数学问题和AGI评估方面获得了显著提升。而在常识推理、世界知识和阅读理解方面的改进最小。在模型尺寸扩大10倍的情况下,MMLU(平均最小路径长度)和BBH(平均宽度平衡高度)得分有了适度的提升。
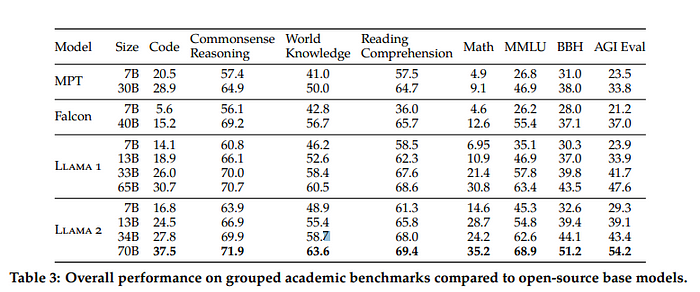
这个模型发布了所有关于训练、微调、安全调优、碳足迹等方面的细节。这个模型很可能在新通过的欧盟合规要求上得分更高。
输出模型
采用提示(包括上下文)和模型生成输出的配对。这对配对根据响应的质量得分,包括对响应生成的有用性和安全性的评分。这与OpenAI对GPT-3、3.5和4所做的练习相同。虽然没有明确说明,但我怀疑用于评定LLaMA-2生成的响应的方法也是相同的。这是一种强化学习的类型,但是训练的决策空间更加集中和受限。这也被称为RLHF(Reinforcement Learning with Human Feedback),旨在更好地训练模型与人类偏好相一致。
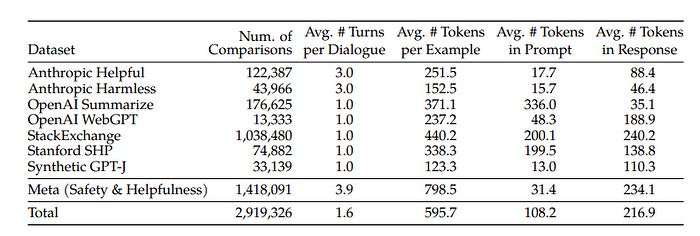
输出模型的人工偏好数据统计。
输出模型使用了开源和内部收集的人工偏好数据,上面已列出。二元人工偏好比较包含2个响应(选择和拒绝),它们共享相同的提示,包括先前对话的上下文。否则,所有示例都由一个提示(包括先前对话,如果有的话)和一个响应组成,这是输出模型的输入。
用于输出模型的两个算法:
- 近端策略优化(Proximal Policy Optimization,PPO)(Schulman等人,2017),是RLHF文献中的标准算法。
- Rejection Sampling fine-tuning:这涉及模型生成的K个样本输出,选择最佳候选者,然后使用选定的输出进行梯度更新。获得最高奖励分数的样本被视为黄金标准。
这两个算法在以下方面不同:
- 广度 — 一个样本输出与多个样本输出和抽样
- 深度 — 在拒绝抽样微调中,只使用选定的样本来更新模型的梯度。
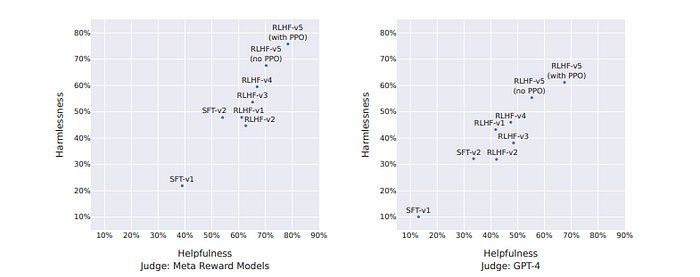
增量强化学习与人工反馈(Incremental RLHF)的收益
强化学习与人工反馈(RLHF)通过5个步骤(分别标记为RLHF-V1、V2,...,RLHF-V5)进行,逐步使用更多的可用样本,结果逐渐改善,显示了更多微调数据的重要性。
人工评估
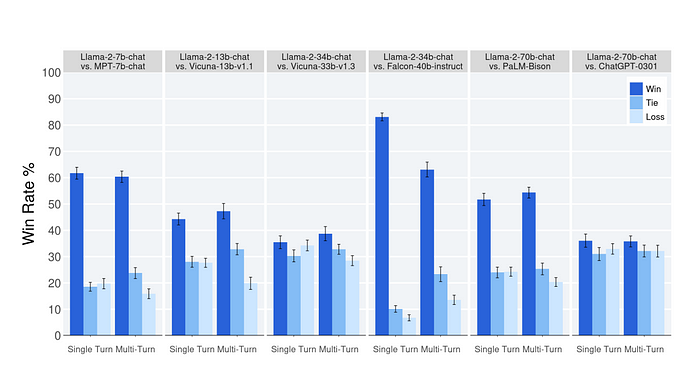
Llama 2-Chat模型与开源和闭源模型在约4,000个有益提示上进行了人工评估,每个提示有三个评估者。
其中最重要的部分是与ChatGPT-0301(基于GPT-3和3 turbo的ChatGPT的三月发布版本)的比较,70B参数模型以微弱优势击败了它。
安全性
虽然安全性可能不是一个令人激动的话题,但我们还是要谈谈它。该模型已经采取了一些措施来解决模型安全性问题。Meta在训练这些模型时没有使用用户数据,该模型还试图解决代词、身份(宗教、性别、国籍、种族和民族)、以及人口统计偏见等问题。
该模型已经进行了真实性、有害性和偏见的基准测试,其得分优于以往所有开源模型的版本。较大的模型表现比较小的模型更好。安全性微调使用了监督式安全微调、强化学习与人类反馈和上下文蒸馏。上下文蒸馏是通过在提示前加入安全性预先提示“您是一个安全和负责任的助理”来生成更安全的模型响应。
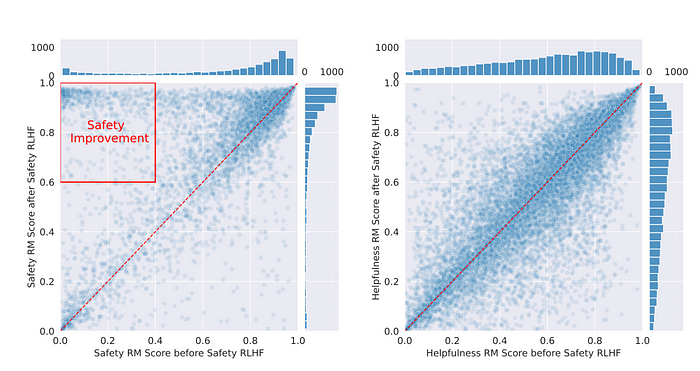
安全性强化学习与人类反馈(RLHF)的影响通过奖励模型分数分布来衡量。左图:Meta安全测试集上生成结果的安全奖励模型分数。样本在左上角的聚集表明模型的安全性有所改善。右图:Meta有益性测试集上生成结果的有益性奖励模型分数。
随着数据量的增加,安全性普遍得到改善。
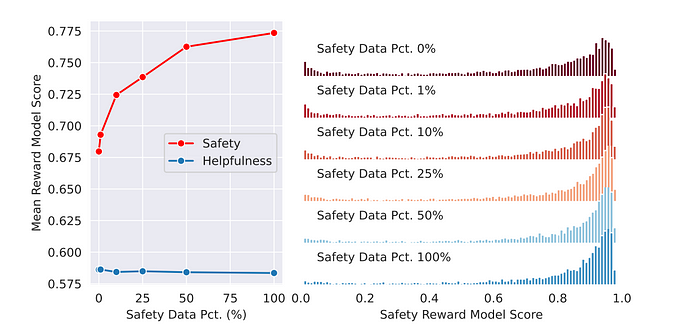
安全性RLHF的影响通过奖励模型分数分布来衡量。左图:Meta安全性测试集上生成结果的安全奖励模型分数。样本在左上角的聚集表明模型的安全性有所改善。右图:Meta有益性测试集上生成结果的有益性奖励模型分数。
总体而言,随着数据量的增加,安全性有所提升。
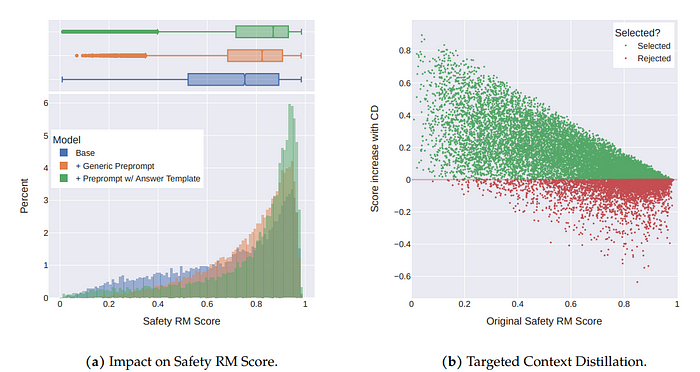
上图:上下文蒸馏分析。左图:基础模型中安全RM分数的分布,添加通用预提示后的分数,以及基于风险类别的、带有定制答案模板的预提示的分数。尽管通用预提示可以提高安全RM分数,但带有定制答案模板的预提示效果更好。右图:上下文蒸馏显著提高了初始得分较低样本的RM分数,但对初始得分较高的样本可能产生不利影响。因此,我们仅在能够提高RM分数的有针对性样本上应用上下文蒸馏。
需要注意的是,上下文蒸馏可能降低奖励模型的分数。因此,我们采用了选择性的上下文蒸馏(只在RM分数较低且能提高有效RM分数时应用)。
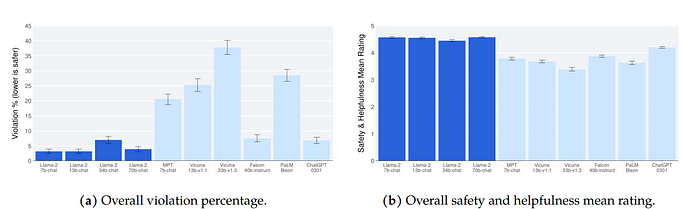
左图:不论模型规模,Llama 2-Chat的违规百分比都较低。右图:不论模型规模,Llama 2-Chat的安全性和有益性平均评分都较高。
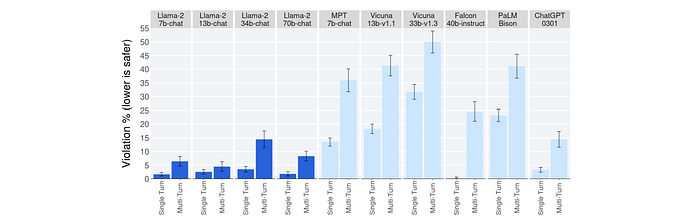
单匝和多匝违规百分比
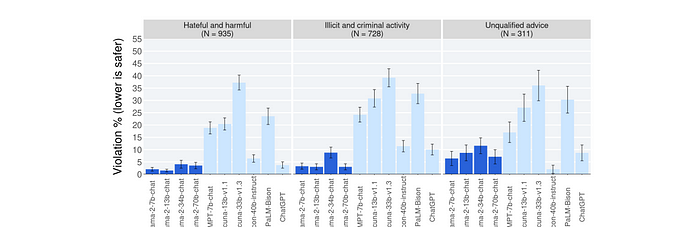
每个风险类别的违规百分比
必须注意的是,这些分类是基于审稿人以及审稿人的差异及其主观解释。
总结
总结思考
LLaMA是比早期版本更为先进的一步。通过为商业用途提供权重,Meta真正支持了创新者和开发者社区。此外,这是首次发布提供了有关模型、代码、架构、策略、规划、功耗和其他训练成本的所有细节。我希望能看到最后缺失的推理引擎和其碳足迹的信息。增加这一点可以使这篇论文成为一个几乎完美的模型发布示例,希望OpenAI、Microsoft可以向Meta学习,并实现透明化。