[STBC]



本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/475980.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
![241120学习日志——[CSDIY] [InternStudio] 大模型训练营 [09]](https://i-blog.csdnimg.cn/direct/3959ad7cb8e54ed79238fdc8c73efefb.png#pic_center)
241120学习日志——[CSDIY] [InternStudio] 大模型训练营 [09]
CSDIY:这是一个非科班学生的努力之路,从今天开始这个系列会长期更新,(最好做到日更),我会慢慢把自己目前对CS的努力逐一上传,帮助那些和我一样有着梦想的玩家取得胜利!!&…

PCB 间接雷击模拟
雷击是一种危险的静电放电事件,其中两个带电区域会瞬间释放高达 1 千兆焦耳的能量。雷击就像一个短暂而巨大的电流脉冲,会对建筑物和电子设备造成严重损坏。雷击可分为直接和间接两类,其中间接影响是由于感应能量耦合到靠近雷击位置的物体。间…

IDEA2019搭建Springboot项目基于java1.8 解决Spring Initializr无法创建jdk1.8项目 注释乱码
后端界面搭建 将 https://start.spring.io/ 替换https://start.aliyun.com/
报错 打开设置 修改如下在这里插入代码片 按此方法无果 翻阅治疗后得知 IDEA2019无法按照网上教程修改此问题因此更新最新idea2024或利用插件Alibaba Clouod Toolkit 换用IDEA2024创建项目 下一步…

单向C to DP视频传输解决方案 | LDR6500
LDR6500D如何通过Type-C接口实现手机到DP接口的单向视频传输 在当今数字化浪潮中,投屏技术作为连接设备、共享视觉内容的桥梁,其重要性日益凸显。PD(Power Delivery)芯片,特别是集成了Type-C接口与DisplayPort…

Leetcode 第 143 场双周赛题解
Leetcode 第 143 场双周赛题解 Leetcode 第 143 场双周赛题解题目1:3345. 最小可整除数位乘积 I思路代码复杂度分析 题目2:3346. 执行操作后元素的最高频率 I思路代码复杂度分析 题目3:3347. 执行操作后元素的最高频率 II题目4:33…

Spark 之 Aggregate
Aggregate
参考链接:
https://github.com/PZXWHU/SparkSQL-Kernel-Profiling
完整的聚合查询的关键字包括 group by、 cube、 grouping sets 和 rollup 4 种 。 分组语句 group by 后面可以是一个或多个分组表达式( groupingExpressions )…

【IDEA】解决总是自动导入全部类(.*)问题
文章目录 问题描述解决方法 我是一名立志把细节说清楚的博主,欢迎【关注】🎉 ~
原创不易, 如果有帮助 ,记得【点赞】【收藏】 哦~ ❥(^_-)~
如有错误、疑惑,欢迎【评论】指正探讨,我会尽可能第一时间回复…
如何快速将Excel数据导入到SQL Server数据库
工作中,我们经常需要将Excel数据导入到数据库,但是对于数据库小白来说,这可能并非易事;对于数据库专家来说,这又可能非常繁琐。
这篇文章将介绍如何帮助您快速的将Excel数据导入到sql server数据库。 准备工作
这里&…

在centos7中安装SqlDeveloper的Oracle可视化工具
1.下载安装包 (1)在SqlDeveloper官网下载(Oracle SQL Developer Release 19.2 - Get Started)对应版本的安装包即可(安装包和安装命令如下): (2)执行完上述命令后&#x…

【动手学深度学习Pytorch】4. 神经网络基础
模型构造 回顾一下感知机。 nn.Sequential():定义了一种特殊的module。 torch.rand():用于生成具有均匀分布的随机数,这些随机数的范围在[0, 1)之间。它接受一个形状参数(shape),返回一个指定形状的张量&am…

Spring Boot + Vue 基于 RSA 的用户身份认证加密机制实现
Spring Boot Vue 基于 RSA 的用户身份认证加密机制实现 什么是RSA?安全需求介绍前后端交互流程前端使用 RSA 加密密码安装 jsencrypt库实现敏感信息加密 服务器端生成RSA的公私钥文件Windows环境 生成rsa的公私钥文件Linux环境 生成rsa的公私钥文件 后端代码实现返…

一键部署 200+ 开源软件的 Websoft9 面板,Github 2k+ 星星
Websoft9面板是一款基于Web的PaaS/Linux面板,可用于在自己的服务器上一键部署200多种热门开源应用,在Github上获得了2k星星。 特点与优势
丰富的开源软件集成:涵盖数据库、Web服务器、企业建站、电商系统、教育系统、中间件、大数据工具等多…
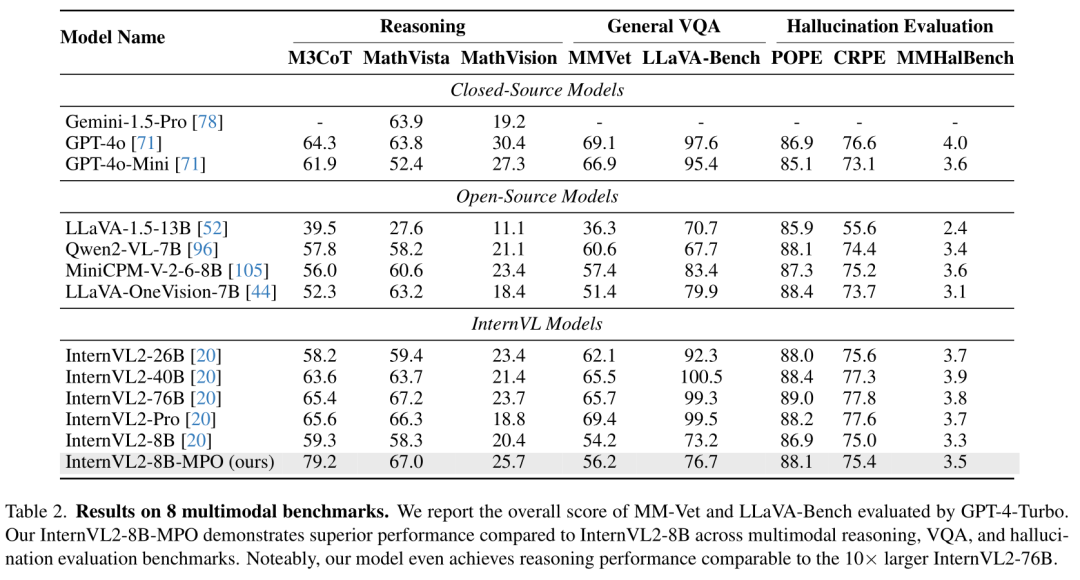
NLP论文速读(MPO)|通过混合偏好优化提高多模态大型语言模型的推理能力
论文速读|Dynamic Rewarding with Prompt Optimization Enables Tuning-free Self-Alignment of Language Models 论文信息: 简介: 本文探讨的背景是多模态大型语言模型(MLLMs)在多模态推理能力上的局限性,尤其是在链式…

动态规划子数组系列一>等差数列划分
题目: 解析: 代码: public int numberOfArithmeticSlices(int[] nums) {int n nums.length;int[] dp new int[n];int ret 0;for(int i 2; i < n; i){dp[i] nums[i] - nums[i-1] nums[i-1] - nums[i-2] ? dp[i-1]1 : 0;ret dp[i…

用 React18 构建Tic-Tac-Toe(井字棋)游戏
下面是一个完整的 Tic-Tac-Toe(井字棋)游戏的实现,用 React 构建。包括核心逻辑和组件分离,支持两人对战。
1. 初始化 React 项目:
npx create-react-app tic-tac-toe
cd tic-tac-toe2.文件结构
src/
├── App.js…

前端—Cursor编辑器
在当今快速发展的软件开发领域,效率和质量是衡量一个工具是否优秀的两个关键指标。今天,我要向大家推荐一款革命性的代码编辑器——Cursor,它集成了强大的AI功能,旨在提高开发者的编程效率。以下是Cursor编辑器的详细介绍和推荐理…

uniapp页面样式和布局和nvue教程详解
uniapp页面样式和布局和nvue教程
尺寸单位
uni-app 支持的通用 css 单位包括 px、rpx
px 即屏幕像素。rpx 即响应式px,一种根据屏幕宽度自适应的动态单位。以750宽的屏幕为基准,750rpx恰好为屏幕宽度。屏幕变宽,rpx 实际显示效果会等比放大…

Kubernetes 安装配置ingress controller
> 对于Kubernetes的Service,无论是Cluster-Ip和NodePort均是四层的负载,集群内的服务如何实现七层的负载均衡,这就需要借助于Ingress,Ingress控制器的实现方式有很多,比如nginx, Contour, Haproxy, trafik, Istio。…

js批量输入地址获取经纬度
使用js调用高德地图的接口批量输入地址获取经纬度。
以下的请求接口的key请换成你的key。
创建key:我的应用 | 高德控制台 ,服务平台选择《Web服务》。 <!DOCTYPE html>
<html lang"en"><head><meta charset"UTF-…

天润融通携手挚达科技:AI技术重塑客户服务体验
业务爆发式增长,但座席服务却跟不上,怎么办?
智能充电领导者的挚达科技就面临过 这样的问题,让我们来看看如何解决。
2010年以来,国内新能源汽车市场进入高速发展期,作为新能源汽车的重要配件,…
推荐文章
- # SpringBoot中懒加载对@PostConstruct的影响
- #Z0463. 巡逻1
- (二十)大数据实战——Flume数据采集的基本案例实战
- (基于安卓app开发项目)英语学习记单词软件的毕业设计(java+j2ee+mysql)附源码+论文
- (接上一篇)前端弄一个变量实现点击次数在前端页面实时更新
- (蓝桥杯)STM32G431RBT6(TIM4-PWM)
- (免费领源码)java#SSM#MYSQL私家车位共享APP 51842-计算机毕业设计项目选题推荐
- (七)Python运算符和优先级
- (三) Markdown插入互联网或本地视频解决方案
- (生物信息学)R语言绘图初-中-高级——3-10分文章必备——饼图(初级)
- (一)docker:建立oracle数据库
- (一)十分简易快速 自己训练样本 opencv级联haar分类器 车牌识别