#引用BeautifulSoup更方便提取html信息;requests模块,发生http请求;os模块,文件写入import requests
from bs4 import BeautifulSoup
import os#当使用requests库发送请求时,如果不设置User - Agent,默认的User - Agent可能会被网站识别为爬虫,从而限制访问。
#可在浏览器中右键选择 设置,在 网络 窗口下找到User-Agent,复制到脚本中来
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36 Edg/130.0.0.0"
}# 获取单章内容并自动获取下一章内容,直到整本小说下载完成
#输入的网址为第一章的网址
def download_chapters(first_chapter_url):chapter_num = 1current_chapter_url = first_chapter_url#设置下载章节数while chapter_num<=10 and current_chapter_url :response = requests.get(current_chapter_url, headers=headers)#获取 HTTP 请求返回的状态码,200表示请求已被服务器成功接受if response.status_code == 200:#创建一个soup对象,将html中的内容传递到此soup = BeautifulSoup(response.text, 'html.parser')#查找title div标签,获取此章节的题目和内容#获取标签内的文本内容chapter_title = soup.find('title').get_text()chapter_content = soup.find('div',class_='Readarea ReadAjax_content',id='chaptercontent').get_text()#打开文件,如果没有就创建,写入内容with open('小说.txt','a',encoding='UTF-8') as f:f.write(chapter_title)f.write("\n")f.write(chapter_content)f.write("\n")f.write("-------------------------------------------------------------------------------------")f.write("\n")print(f"第{chapter_num}章 {chapter_title} 下载成功")f.close()# 查找下一章的链接next_chapter= soup.find('div',class_='Readpage pagedown')if next_chapter:next_chapter_link=next_chapter.find('a',id="pb_next",class_="Readpage_down js_page_down")if next_chapter_link:current_chapter_url = next_chapter_link.get('href')#因为html源代码的的链接不完整,手动补全,如果代码完整则不需要此步骤current_chapter_url="https://www.3bqg.cc"+current_chapter_urlchapter_num += 1else:current_chapter_url = Noneelse:print(f"第{chapter_num}章下载失败,状态码:{response.status_code}")current_chapter_url = Noneif __name__ == "__main__":# 替换为实际的第一章网址first_chapter_url ="https://www.3bqg.cc/book/10814/1.html"download_chapters(first_chapter_url)成果展示

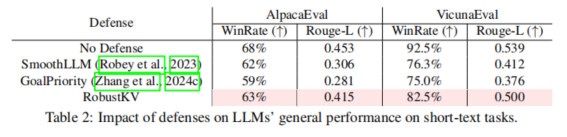
以上使用beatifulsoup模块
接下来使用正则表达式
import requests
import re
import osheaders = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0",
}# 获取单章内容并自动获取下一章内容,直到整本小说下载完成
# 输入的网址为第一章的网址
def download_chapters(first_chapter_url):chapter_num = 1current_chapter_url = first_chapter_url#提前打开文件避免重复开关文件出现差错with open('正则小说.txt', 'a', encoding='utf-8') as file:# 设置下载章节数while chapter_num <= 10 and current_chapter_url:response = requests.get(current_chapter_url, headers=headers)# 获取 HTTP 请求返回的状态码,200表示请求已被服务器成功接受if response.status_code == 200:html_txt = response.text#通过正则表达式获取标题 内容 下一张的链接 re.DOTALL表示能够匹配包括换行符\n在内的所有字符patter_title = re.compile(r'<title>(.*?)</title>', re.DOTALL)patter_content = re.compile(r'<div id="chaptercontent" class="Readarea ReadAjax_content">(.*?)</div>',re.DOTALL)pattern_next_url = re.compile( r'<a href="(.*?)" id="pb_next" class="Readpage_down js_page_down">下一章</a>')#使用正则表达式对象的search方法进行匹配patter_title_match = patter_title.search(html_txt)patter_content_match = patter_content.search(html_txt)pattern_next_url_match = pattern_next_url.search(html_txt)if patter_title_match:file.write(patter_title_match.group(1))file.write("\n")if patter_content_match:file.write(patter_content_match.group(1))file.write("---------------------------------------------------------------------------------------------")file.write("\n")file.write("\n")print(f"第{chapter_num}章下载成功")#因为原网页链接不完整,所以要加上部分链接if pattern_next_url_match:current_chapter_url = "https://www.3bqg.cc"+ pattern_next_url_match.group(1)chapter_num += 1else:print(f"第{chapter_num}章下载失败")current_chapter_url=Nonefile.close()if __name__ == "__main__":first_chapter_url = "https://www.3bqg.cc/book/10814/1.html"download_chapters(first_chapter_url)
成果展示


使用正则会将html中其他符号叶下载下来,beautifulsoup则不会