🌟欢迎来到 我的博客 —— 探索技术的无限可能!
🌟博客的简介(文章目录)
大数据实战——MapReduce案例实践
- 一.过程分析(截图)
- 1. 确定Hadoop处于启动状态
- 2. 在/usr/local/filecotent下新建child_parent文件,并写入以下内容
- 3. 将/usr/local/filecontent/child_parent上传到hdfs的data目录中
- 4. 查看data目录下的内容
- 5. 编写SingleTableLink.java并运行文件
- 5.1进入eclipse
- 5.2默认workspace(这里必须是Hadoop用户下,如果是个人用户名下,就代表前面错误,你不是在Hadoop下完成的操作,会显示没有java路径)
- 5.3新建class
- 5.4编写SingleTableLink.java
- 6. 打成jar包并指定主类,在linux中运行
- 7. 查看输出文件内容
- 8. 将/home/hadoop/Downloads/Dedup.txt上传到hdfs的data目录中
- 9. 查看data目录下的内容
- 10. 编写SingleTableLink.java并运行文件
- 10.1新建class
- 10.2编写Dedup.java
- 11. 打成jar包并指定主类,在linux中运行
- 12. 查看输出文件内容
- 二.解题思路
- 2.1关系连接
- 2.2数据去重
一.过程分析(截图)
1. 确定Hadoop处于启动状态

图1:打开hdfs
在终端输入./sbin/start-dfs.sh启动hdfs。

图2:确定Hadoop处于启动状态
通过输入jps确定Hadoop处于启动状态。
关系连接
2. 在/usr/local/filecotent下新建child_parent文件,并写入以下内容
在终端输入sudo vi hellodemo新建child_parent文件,并写入以下内容:
Tom Lucy
Tom Jack
Jone Lucy
Jone ack
Lucy Mary
Lucy Ben
Jack Alice
Jack Jesses
Terry Alice
Terry Jesses
Philip Terry
Philip Alma
Mark Terry
Mark Alma

图3:新建child_parent文件

图4:进入child_parent文件

图5:写好内容进child_parent文件

图6:按 ESC 保存,然后 shift+:wq
3. 将/usr/local/filecontent/child_parent上传到hdfs的data目录中

图7:上传到hdfs的data目录
在终端输入命令:bin/hdfs dfs -put /usr/local/filecontent/child_parent data将刚刚写的child_parent文件上传到hdfs的data目录下。
4. 查看data目录下的内容

图8:查看data目录下的内容
在终端输入命令:bin/hdfs dfs -ls data查看data目录下的内容,可以看到我们已经成功将刚刚写的child_parent文件上传到hdfs的data目录下。

图9:查看child_parent文件内容
在终端输入命令:bin/hdfs dfs -text data/child_parent查看child_parent文件内容。
5. 编写SingleTableLink.java并运行文件
5.1进入eclipse

图10:启动eclipse
在终端输入启动命令:./eclipse启动eclipse。
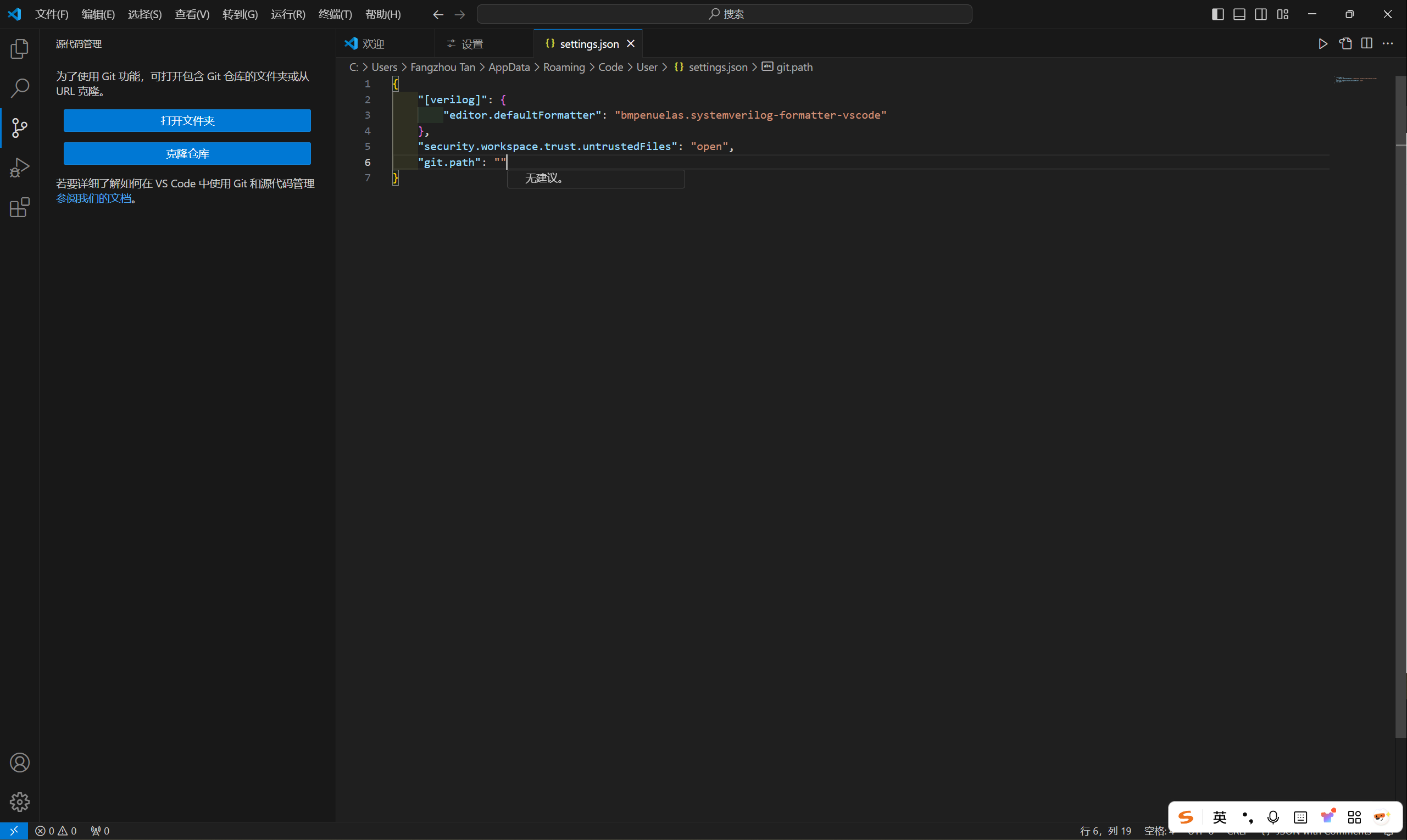
5.2默认workspace(这里必须是Hadoop用户下,如果是个人用户名下,就代表前面错误,你不是在Hadoop下完成的操作,会显示没有java路径)

图11:默认workspace
默认workspace点击launch进入下一步。
5.3新建class

图13:给新建class起名SingleTableLink
5.4编写SingleTableLink.java

图14:编写WordCountTest.java

图15:注意要把位置写对
6. 打成jar包并指定主类,在linux中运行

图16:选择“export”
在Eclipse工作界面左侧的“Package Explorer”面板中,在工程名称“SingleTableLink”上点击鼠标右键,在弹出的菜单中选择“Export”。

图17:选择“Runnable JAR file”
在该界面中,选择“Runnable JAR file”,然后,点击“Next>”按钮。

图18:SingleTableLink工程打包生成child_parent.jar
在该界面中,“Launch configuration”用于设置生成的JAR包被部署启动时运行的主类,需要在下拉列表中选择刚才配置的类“SingleTableLink”。在“Export destination”中需要设置JAR包要输出保存到哪个目录,这里设置为“/usr/local/hadoop/myapp/child_parent.jar”。在“Library handling”下面选择“Extract required libraries into generated JAR”。然后,点击“Finish”按钮完成打包。

图19:查看是否打包成功
在进入myapp目录下终端输入命令:ls,可以看到,“/usr/local/hadoop/myapp”目录下已经存在一个child_parent.jar文件。
7. 查看输出文件内容

图20:使用hadoop jar命令运行程序
在终端输入命令:./bin/hadoop jar ./myapp/child_parent.jar运行打包的程序。

图21:运行结果
结果已经被写入了HDFS的“/user/hadoop/out2”目录中。

图22:查看输出文件内容
在终端输入命令:bin/hdfs dfs -cat /out2/*查看输出文件内容,结果入图22所示,自此关系连接程序顺利运行结束。
数据去重
8. 将/home/hadoop/Downloads/Dedup.txt上传到hdfs的data目录中

图23:上传到hdfs的data目录
在终端输入命令:bin/hdfs dfs -put /home/hadoop/Downloads/Dedup.txt data将刚刚写的child_parent文件上传到hdfs的data目录下。
9. 查看data目录下的内容

图24:查看data目录下的内容
在终端输入命令:bin/hdfs dfs -ls data查看data目录下的内容,可以看到我们已经成功将刚刚写的Dedup.txt文件上传到hdfs的data目录下。
10. 编写SingleTableLink.java并运行文件
10.1新建class

图25:给新建class起名Dedup
10.2编写Dedup.java

图26:编写Dedup.java
注意输入输出的地址。
11. 打成jar包并指定主类,在linux中运行

图27:查看是否打包成功
在进入myapp目录下终端输入命令:ls,可以看到,“/usr/local/hadoop/myapp”目录下已经存在一个Dedup.jar文件。
12. 查看输出文件内容

图28:使用hadoop jar命令运行程序
在终端输入命令:./bin/hadoop jar ./myapp/Dedup.jar运行打包的程序。

图29:运行结果
结果已经被写入了HDFS的“/user/hadoop/out3”目录中。

图30:查看输出文件内容
在终端输入命令:bin/hdfs dfs -cat /out3/*查看输出文件内容,结果入图30所示,自此数据去重程序顺利运行结束。

图31:关闭hdfs
关闭eclipse后,在终端输入./sbin/stop-dfs.sh关闭hdfs。
二.解题思路
2.1关系连接
只有连接左表的parent列和右表的child列,才能得到grandchild和grandparent的信息。
因此需要将源数据的一张表拆分成两张表,且左表和右表是同一个表。
• 所以在map阶段将读入数据分割成child和parent之后,将parent设置成key,child设置成value进行输出,并作为左表;
再将同一对child和parent中的child设置成key,parent设置成value进行输出,作为右表。
为了区分输出中的左右表,需要在输出的value中再加上左右表的信息,比如在value的String最开始处加上字符1表示左表,加上字符2表示右表。
这样在map的结果中就形成了左表和右表,然后在shuffle过程中完成连接。
reduce接收到连接的结果,其中每个key的value-list就包含了"grandchild–grandparent"关系。
取出每个key的value-list进行解析,将左表中的child放入一个数组,右表中的parent放入一个数组,
最后对两个数组求笛卡尔积得到最后的结果
2.2数据去重
存储系统的重复数据删除过程一般是这样的:首先将数据文件分割成一组数据块,为每个数据块计算指纹,然后以指纹为关键字进行Hash查找,匹配则表示该数据块为重复数据块,仅存储数据块索引号,否则则表示该数据块是一个新的唯一块,对数据块进行存储并创建相关元信息。这样,一个物理文件在存储系统就对应一个逻辑表示,由一组FP(指纹)组成的元数据。当进行读取文件时,先读取逻辑文件,然后根据FP序列,从存储系统中取出相应数据块,还原物理文件副本。从如上过程中可以看出,Dedupe的关键技术主要包括文件数据块切分、数据块指纹计算和数据块检索。