随着 AI 的飞速发展,我们面临着前所未有的挑战。如今,大型语言模型生成的文本与人类撰写的文本越来越难以区分,这导致了引导公众舆论、传播虚假新闻以及学术不端等一系列问题。为此,腾讯 AI Lab 和浙江大学、西湖大学、香港大学的研究员们提出了一种用于检测给定文本是否为机器所生成的判别工具。该工具旨在准确识别模型生成的虚假文本,进而过滤造谣信息,净化传播环境,为维护言论的真实性及公信力提供强大支持。
此检测工具的开发建立在论文提出的 AI 文本检测方法测试平台上(Deepfake Text Detection Testbench)。而这个测试平台依托于大量的数据基础:论文收集了不同的大模型(例如 GPT 系列和 LLaMA 系列等等)在各种写作任务上生成的文本,以及对应的人类撰写文本,构建一个系统真实的 AI 生成文本检测平台,并深入研究了这些机器生成的文本与人类撰写的文本之间的差异。

论文传送门:
https://arxiv.org/abs/2305.13242

太长了不想读
论文收集了各种写作任务下的人类撰写和机器生成文本,并系统分析人类与机器撰写文本差异,在不使用 GPT4 数据的情况下检测器竟能实现 86% GPT4 作品检测准确率!

数据收集
论文探究了人类撰写(human-written)的文本和机器生成(machine-generated)的文本之间是否存在本质差异,并且希望能够消除格式、主题和内容等因素对判别结果产生的影响。同时,论文还研究了现有主流检测方法是否能够捕捉到这种差异。在实际的应用场景中,这些检测器会遇到各种各样的文本,而并不知道这些文本的意图、主题和模型来源。
因此,测试平台需要尽可能涵盖不同的写作任务以及覆盖到尽可能多样的大语言模型(LLMs),来考核检测器在实际应用场景的性能。为了实现这个目标,本工作通过收集来自不同人类作品和由不同语言模型生成的深度伪造文本(deepfake text),构建了一个用于深度伪造文本检测的实际测试平台。数据集由来源广泛的 447,674 篇人类撰写和机器生成的文本组成:
人类撰写的文本来自 10 个数据集,涵盖了广泛的写作任务,例如新闻文章写作、故事生成、科学写作等。
机器生成的文本由 7 个来源的 27 个主流语言学习模型生成,例如 ChatGPT、LLaMA 和 Bloom 等。
例如,下面是以“The Apple Card starts rolling out today”为标题,人类撰写的新闻和机器生成的新闻:
Apple's new credit card will begin a preview roll out today and will become available to all iPhone owners in the US later this month. A random selection of people will be allowed to go through the application process, which involves entering personal details which are sent to Goldman Sachs and TransUnion. Applications are approved or declined in less than a minute. The Apple Card is meant to be broadly accessible to every iPhone user, so the approval requirements will not be as strict as other credit cards. Once the application has been approved, users will be able to use the card immediately from the Apple Wallet app. The physical titanium card can be requested during setup for free, and it can be activated with NFC once it arrives.
Today marks the beginning of a new era of financial technology: Apple Card is now available to all users in the United States. The long-awaited credit card from Apple, which was announced earlier this year, is now available for everyone to sign up and use. With features such as cash back on purchases and robust security measures, Apple Card could revolutionize how people make payments. This could be the start of a new wave of digital payment options.

差异逐渐减小,难度逐级增加
为了尽可能模拟真实的应用场景,论文设计了六种不同难度的测试环境。这些测试环境从理想状态开始,逐步趋近于实际应用场景,以此来对模型进行全方位的验证和挑战。
随着收集到的机器生成数据在领域和样本量上的增加,机器生成和人类撰写的文本差异逐渐变小。这意味着需要挖掘更深层次的差异,来更精确地区分机器生成的文本和人类撰写的文本。这也是该研究平台的一个重要方向。例如,当数据只包含一个写作(观点论述)的人类撰写文本,和单一模型生成的机器文本时,两者在命名实体分布上有明显的差异:
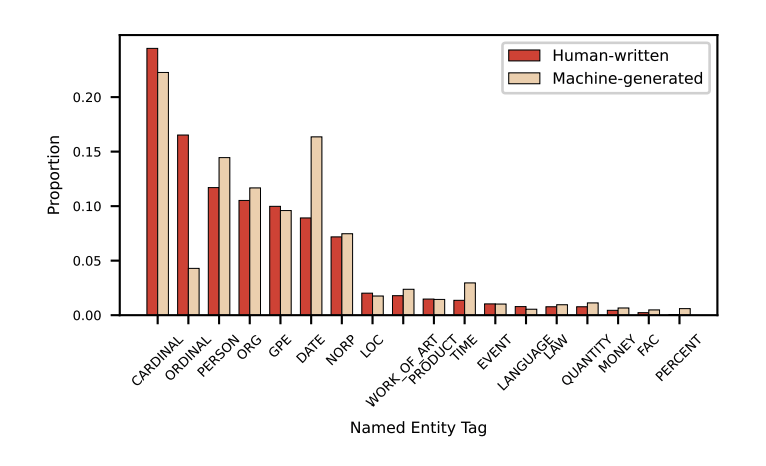
▲ 图1. CMV观点论述写作任务下,两类文本的命题实体标签分布
然而,当测试数据包含了多种写作任务和大型模型时,人类撰写的文本与机器生成的文本之间的语言学差异几乎被消除:
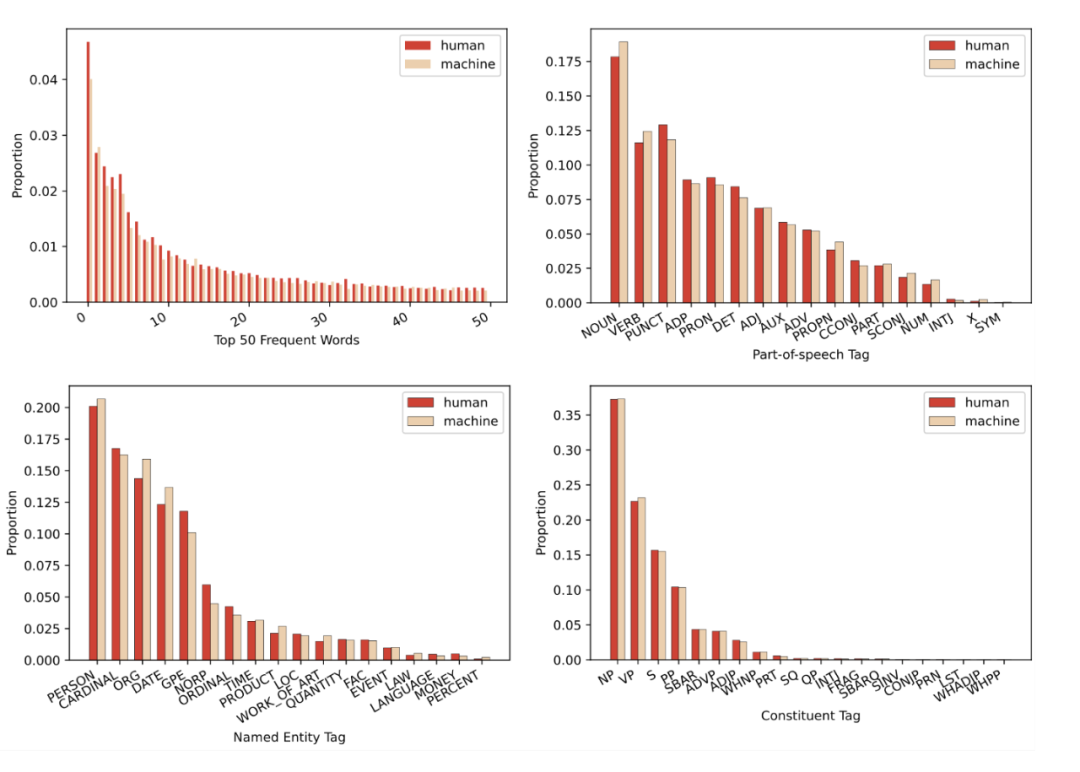
▲ 图2. 全量数据下,两类文本的语言学特征分布(高频词、词性标签、命名实体标签和成分句法标签)。

人能判断吗?
英语相关专业的标注员和 GPT-3.5 被邀请来判断是人类撰写还是机器生成,结果如下表所示:
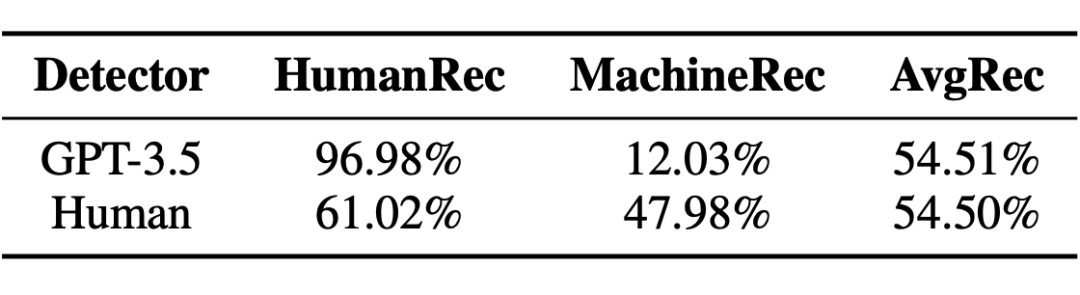
▲ 表2. 英语专业标注人员和 ChatGPT 在检测 AI 生成文本上的表现略胜于随机猜测。
从实验结果可以看到,人和 GPT-3.5 都没有办法判断文本的来源,其平均召回率仅仅略胜于随机猜测(50%)。

哪种检测方法最优?
如前文所述,在简单的测试环境中,包括 DetectGPT [1] 在内的分类器已经能够准确地区分两种文本。然而,随着测试数据来源逐渐变得更加复杂,各个分类方法的性能都受到了不同程度的影响。当考虑全部数据时(即模型会遇到各种各样写作任务下不同模型生成的文本),只有基于预训练模型(Longformer)的检测器仍然保持良好的分类性能(平均召回率接近 90%,AUROC为0.99)。
在两个分布外(out-of-distribution)的测试环境中,模型将面临训练集中未见过的写作任务或者是大模型来源。在这个场景下,即便是性能优越的预训练分类器的分类性能也大打折扣。例如,当预训练分类器遇到新的写作任务,平均召回率从 90.53% 降到 68.40%。但意外的是,虽然平均召回率很低,模型仍然取得了一个较高的 AUROC(0.93)。这意味着模型仍然能将两种类型的文本进行区分,但是需要对决策边界进行调整。
基于这个发现,论文通过留一法交叉验证(Leave-One-Out Cross Validation)的方法重新选定了决策阈值,成功地平均召回率提升到 81.78%。
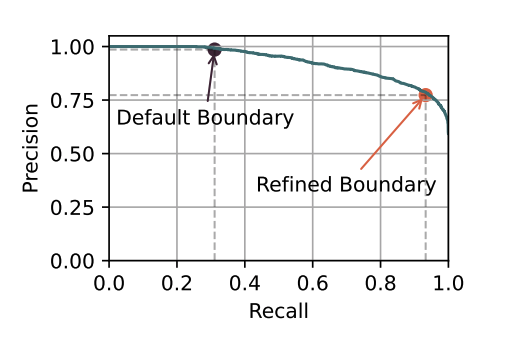
▲ 图3. 重新调整角色边界后的检测器在两类文本上的表现更加均衡。

如何才能骗过检测器?
1) 更强大的AI
更强大的 AI 能生成更加逼真的文本,从而更难被检测。因此,作者从实际应用场景出发,调用当下最强大的模型 GPT4 来生成新闻,扮演角色进行对话,制作虚假科学问答以及编写虚假电影评价。
2) 改写
为了防止抄袭被发现,用户写作时经常使用改写工具来逃过查重检测。最近有工作 [2] 指出,检测器很容易被机器改述(paraphrase)后的文本欺骗。为此,作者使用 ChatGPT 来对之前的测试文本进行改写,进一步提高了文本的误导性,提高检测难度。模型的效果如下:
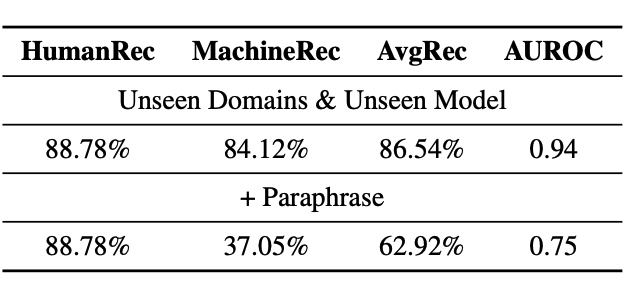
▲ 表3. 检测器能够识别GPT4生成的文本,但基本是无法判断经过改写的文本
尽管检测器从未遇到过这些新增的写作任务,也没有接触过 GPT4 生成的伪数据,但它仍然能够高效地检测出 GPT4 生成的文本。然而,对于改写过的文本,检测器的性能会大幅下降。这些新挑战因素使得检测平台更加适应真实世界中复杂情况和未来可能发展趋势。

为什么基于预训练模型的检测器表现优异?
实验发现基于预训练的检测方法可以利用其“困惑度偏见(perplexity bias)”获得比其他方法更优秀的性能。论文作者用直接用没有微调过的预训练模型计算了两种文本的困惑度,如图(b)所示。可以发现,机器生成文本的困惑度分布和人类撰写文本呈现两个峰,机器生成文本的平均困惑度明显低于人类撰写文本。换句话说,“机器看机器写的文本更顺眼,而人类撰写的文本让机器更困惑”。
这种特性使得基于预训练模型的检测器在微调以前就具备的一定的偏见。这种偏见也有坏处,例如当检测器遇到新的写作任务时(Unseen Domains),检测器过分自信的认为困惑度低的就是机器写的,困惑度高的就是人写的,如图(a)所示,因此在机器生成的文本上召回率接近 100%,但是在人类撰写文本上的召回率仅有 38.05%。
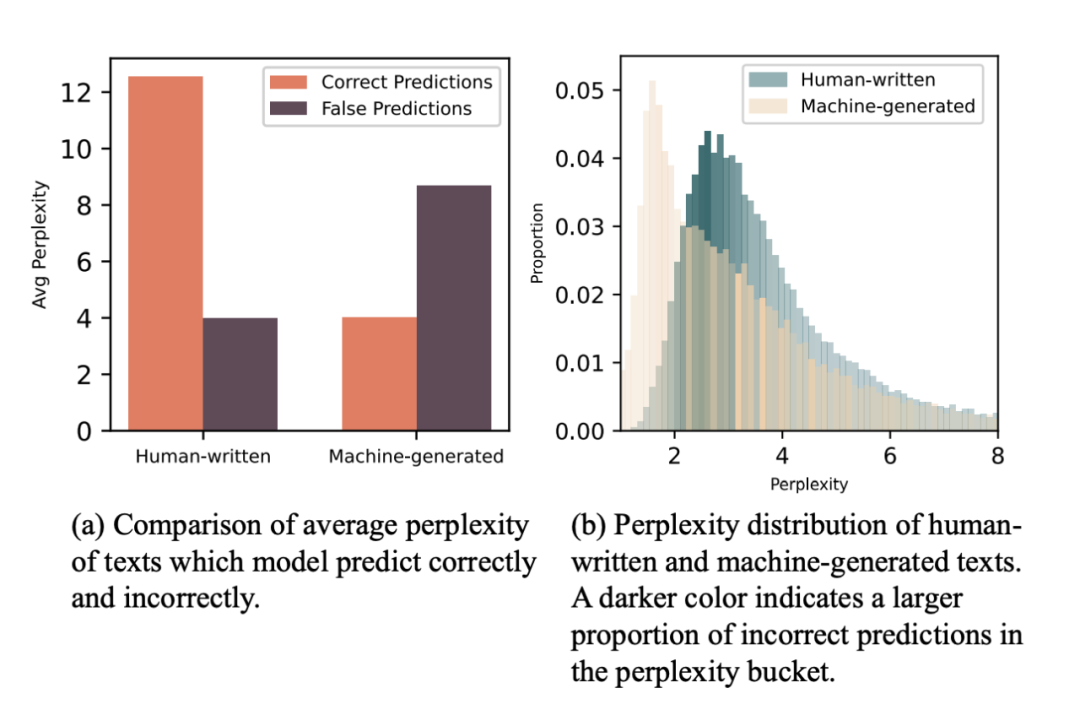
▲ 图4. 模型的困惑度偏见:”困惑度低的文本极大概率是机器写的,反之是人写的“。

是否存在其他的文本特征?
除了语言学特征外,论文还探究了其他可能存在的特征差异,可以用来帮助文本检测。例如,前人工作发现 ChatGPT 的文风更加正式,情感更加中立 [3]。然而,本工作的实验发现,如果在开放集层面考虑两类文本的差异(不管文本是何种写作任务、由何种模型生成),这些差异变得非常微弱,以至于无法作为检测依据。例如,用现成的情感分析工具对文本的情感倾向进行分析,模型生成的文本有输出正向情感的倾向,但并不明显,两类文本的情感倾向大致接近:
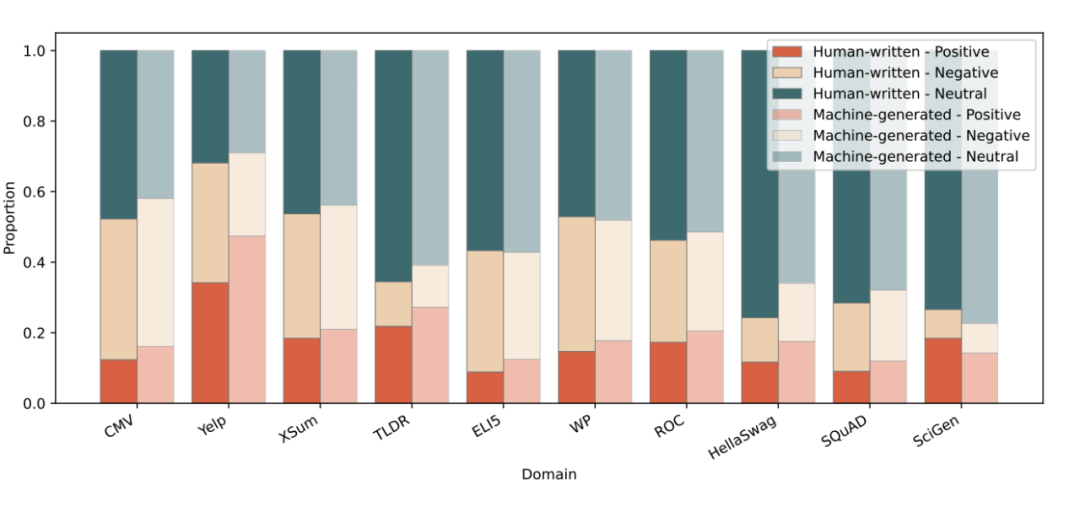
同时,论文分析了两类文本的语法正确性,在大规模数据下,机器并没有比人类写作更加正式。在一些文风正式的写作任务(例如 XSum 新闻写作和 SciGen 科学写作)上,人类比模型更加正式。而少输较为口语化的写作任务上(例如 Yelp 点评)模型相较于人类而言”正式”:
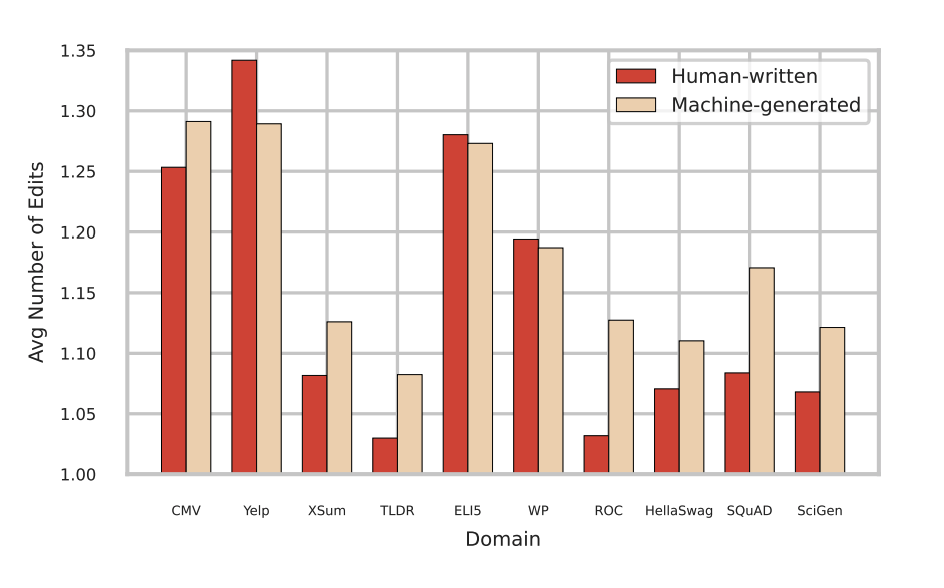
▲ 图6. 两类文本的语法准确度:平均编辑次数越高表示语法错误越多。

Take-away
总的来说,为了测试 AI 生成文本检测在实际应用场景中的表现,文章作者收集了大规模的人类撰写文本和机器生成文本,并进行了比较。这篇工作首次在大规模大范围的数据尺度下,对人类撰写文本和机器生成文本进行比较。实验发现机器生成的文本已经与人类撰写的文本没有明显差异。目前来看,提出的检测器虽然已经取得了优异的效果,但如何提高这类检测器的泛化能力,特别是在分布外场景下的泛化能力,以适应日常应用中更加复杂多变的情况,则成为未来亟待研究和解决的重要问题。

参考文献
[1] Mitchell, Eric, et al. "Detectgpt: Zero-shot machine-generated text detection using probability curvature." arXiv preprint arXiv:2301.11305 (2023).
[2] Sadasivan, Vinu Sankar, et al. "Can ai-generated text be reliably detected?." arXiv preprint arXiv:2303.11156 (2023).
[3] Guo, Biyang, et al. "How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection." arXiv preprint arXiv:2301.07597 (2023).
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·