目录
1、Selenium介绍
2、Selenium环境安装
3、创建浏览器、设置、打开
4、打开网页、关闭网页、浏览器
5、浏览器最大化、最小化
6、浏览器的打开位置、尺寸
7、浏览器截图、网页刷新
8、元素定位
9、元素交互操作
10、元素定位
(1)ID定位
(2)NAME定位
(3)CLASS_NAME定位
(4)TAG_NAME定位
(5)LINK_TEXT定位
(6)PARTIAL_LINK_TEXT定位
(7)CSS_SELECTOR定位
(8)XPATH定位
1、Selenium介绍
(1)自动化:自动化是指使用技术手段模拟人工。执行重复性任务,准确率100%,高于人工。
(2)自动化应用场景:自动化测试;自动化运维;自动化办公;自动化游戏
(3)Selenium:是web自动化中的知名开源库,通过浏览器驱动控制浏览器,通过元素定位模拟人工交换;支持多种浏览器;跨平台、兼容性高;以实现web自动化(无焦点状态依然执行)
2、Selenium环境安装
(1)浏览器的安装
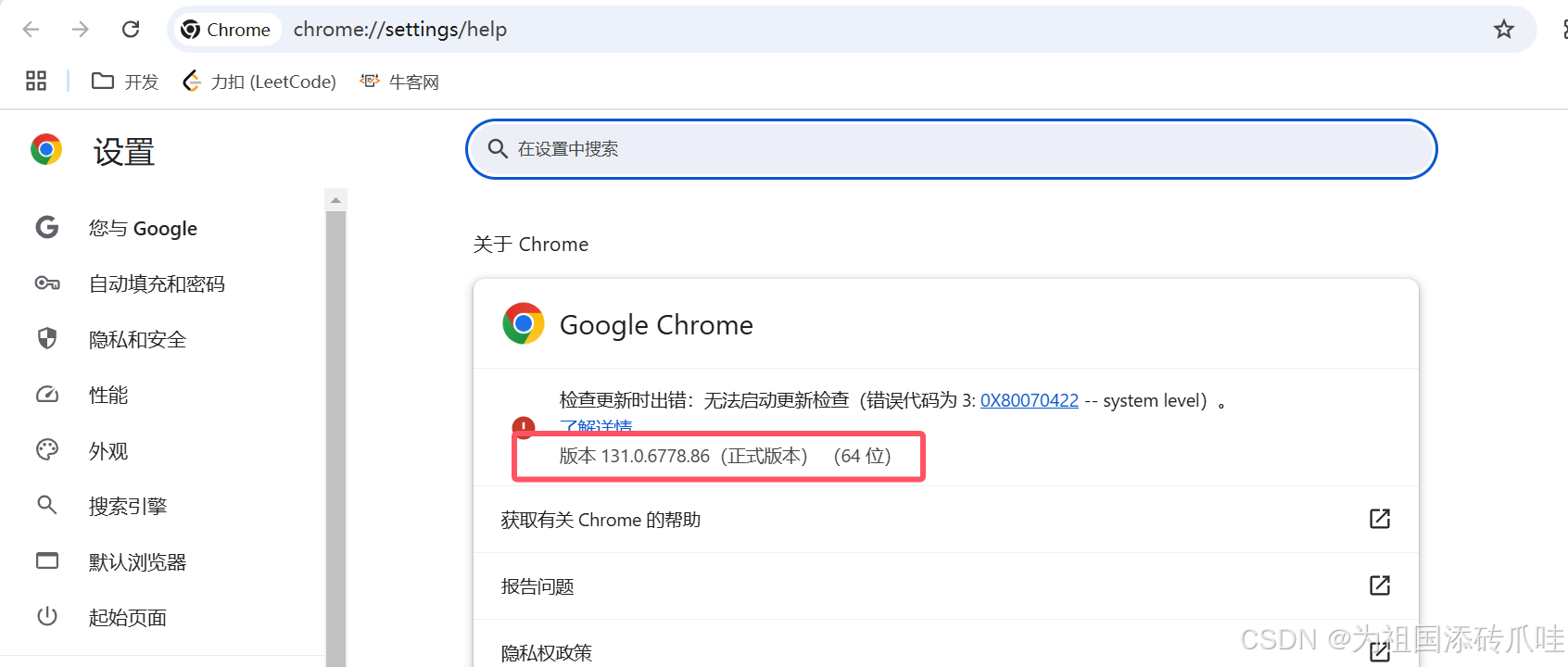
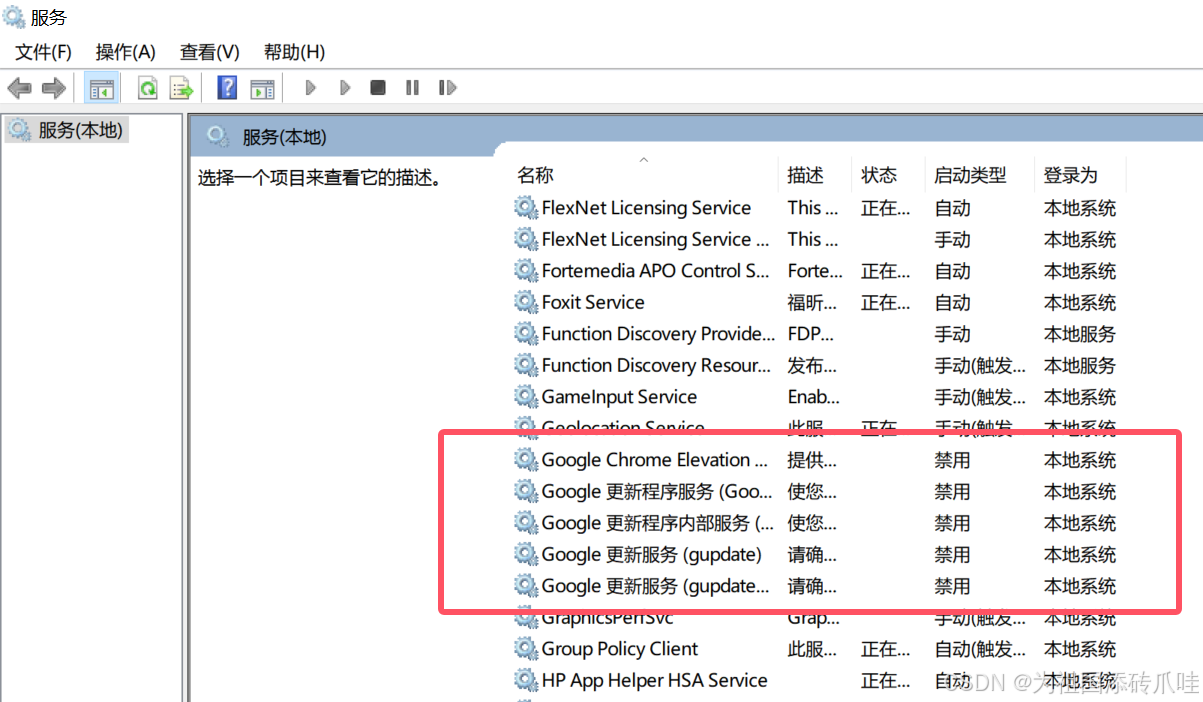
安装好了看版本右上角三个点->[帮助]->[关于Google Chrome ],然后关闭Chrome浏览器自动更新服务[开始搜索‘服务’,关于Chrome的都可以禁用]!!!
(2)浏览器驱动的安装
Chrome for Testing availability
保证浏览器与驱动大版本一致
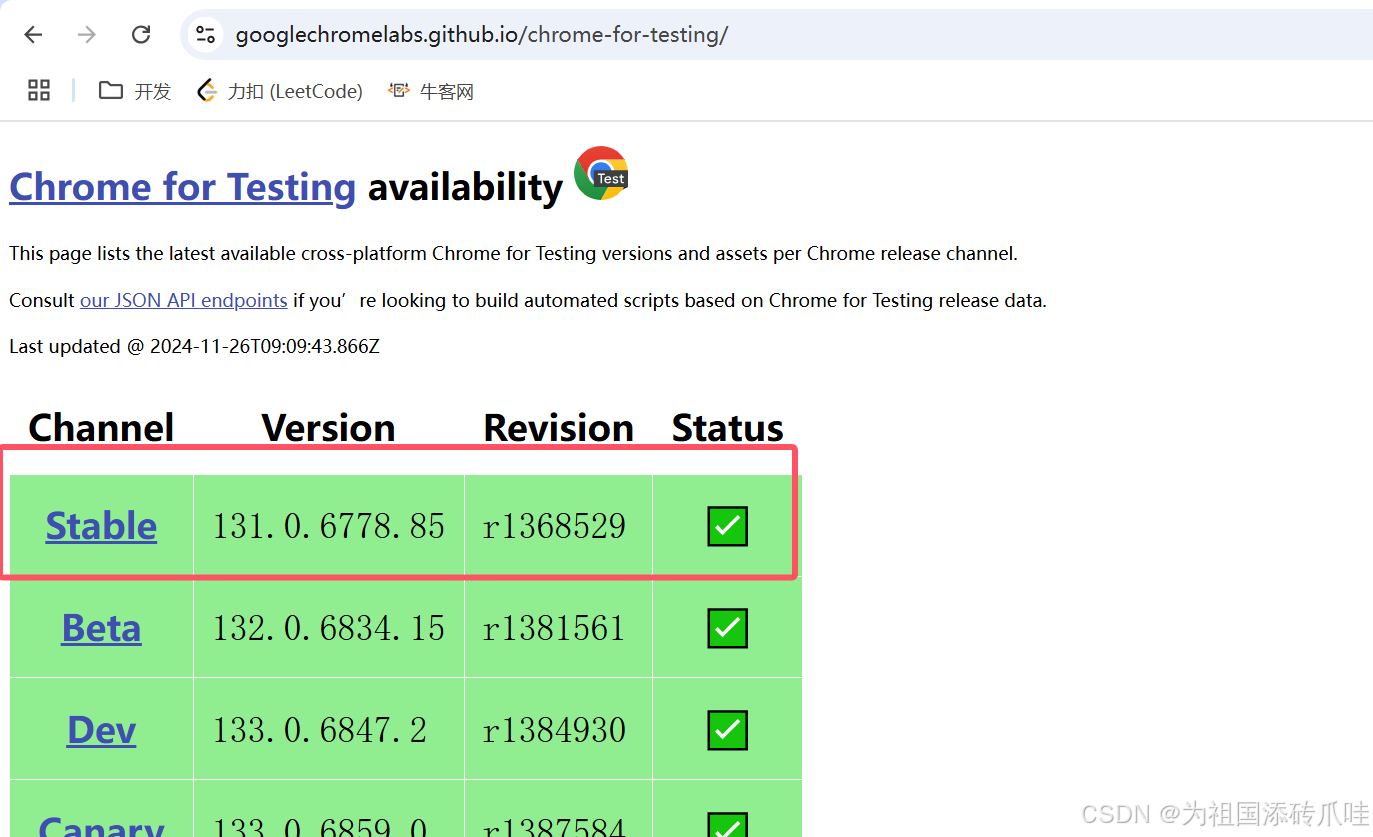
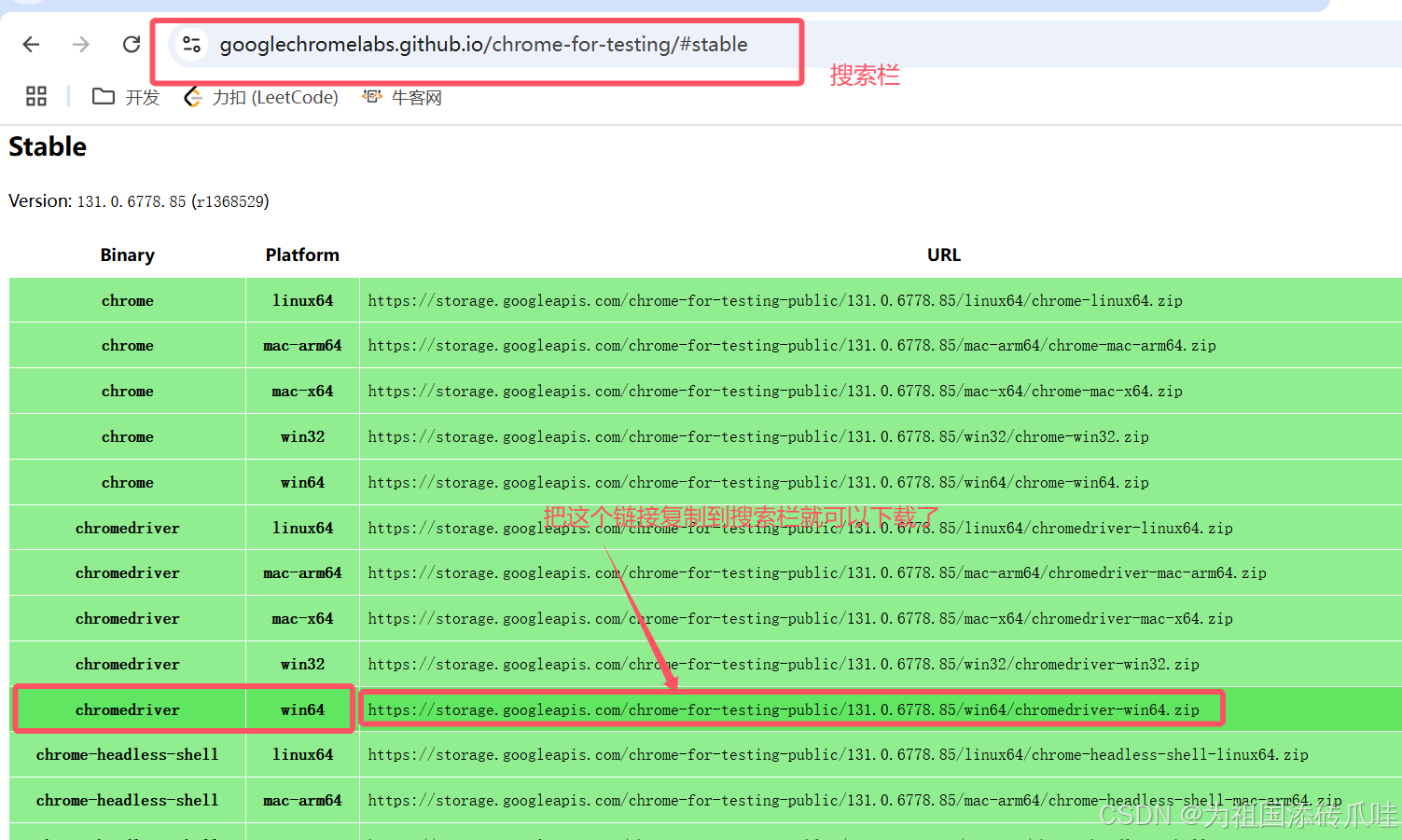
下载后就可以拖到工程项目中了
3、创建浏览器、设置、打开
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动#创建设置浏览器对象
q1=Options()#禁用沙盒模式
q1.add_argument('--no-sandbox')#保持浏览器打开状态(默认是代码执行完毕后自动关闭)
q1.add_experimental_option('detach',True)#创建并启动浏览器
a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)点击运行就会打开Chrome浏览器
注意:沙盒模式在有些电脑必须设置的,因为存在某些冲突,所以必须设置,但是大多数电脑时可以不用添加的!
4、打开网页、关闭网页、浏览器
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
import time#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(3)
#关闭当前标签页[只会关闭一个标签页;当只有一个标签页时,就相当于关闭浏览器]
a1.close()
time.sleep(3)
#退出浏览器
a1.quit()
页面的渲染是需要花费时间的,所以大家酌情添加time.sleep(second)
5、浏览器最大化、最小化
from os import times_resultfrom selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
import time#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)
#浏览器的最大化
a1.maximize_window()
time.sleep(2)
#浏览器的最小化
a1.minimize_window()
6、浏览器的打开位置、尺寸
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
import time#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)
#浏览器的打开位置
a1.set_window_position(0,0)
#浏览器打开尺寸
a1.set_window_size(600,600)7、浏览器截图、网页刷新
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
import time#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)
#浏览器截图
a1.get_screenshot_as_file('1.png')
time.sleep(2)
#刷新当前网页
a1.refresh()8、元素定位
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)
#定位一个元素[找到的话返回结果,找不到的话就会返回空列表]
a2=a1.find_element(By.ID,'kw')
print(a2)#定位多个元素[找到的话返回列表,找不到的话直接报错]
a3=a1.find_elements(By.ID,'kw')
print(a3)9、元素交互操作
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)
a2=a1.find_element(By.ID,'kw');
#元素输入
a2.send_keys('自动化测试')
time.sleep(2)
#元素清空
a2.clear()
time.sleep(2)
#元素输入
a2.send_keys('测试')
#元素点击
a1.find_element(By.ID, 'su').click()10、元素定位
(1)ID定位
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)#元素定位——ID
#1、一般通过ID定位元素使比较准确的
#2、并不是所有的网页或者元素都有ID值
a1.find_element(By.ID,'kw').send_keys('自动化测试')(2)NAME定位
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)#元素定位——NAME
#1、一般通过name定位元素是比较准确的
#2、并不是所有的网页或者元素都有name值
a1.find_element(By.NAME,'wd').send_keys('自动化测试')(3)CLASS_NAME定位
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time
#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)#元素定位——CLASS_NAME
#1、class值不能有空格,否则报错
#2、class值会有重复的,所以需要切片处理
#3、class值有的网站是随机的,这时候就不得不用别的定位方式哦
a1.find_elements(By.CLASS_NAME,'c-font-normal')[1].click()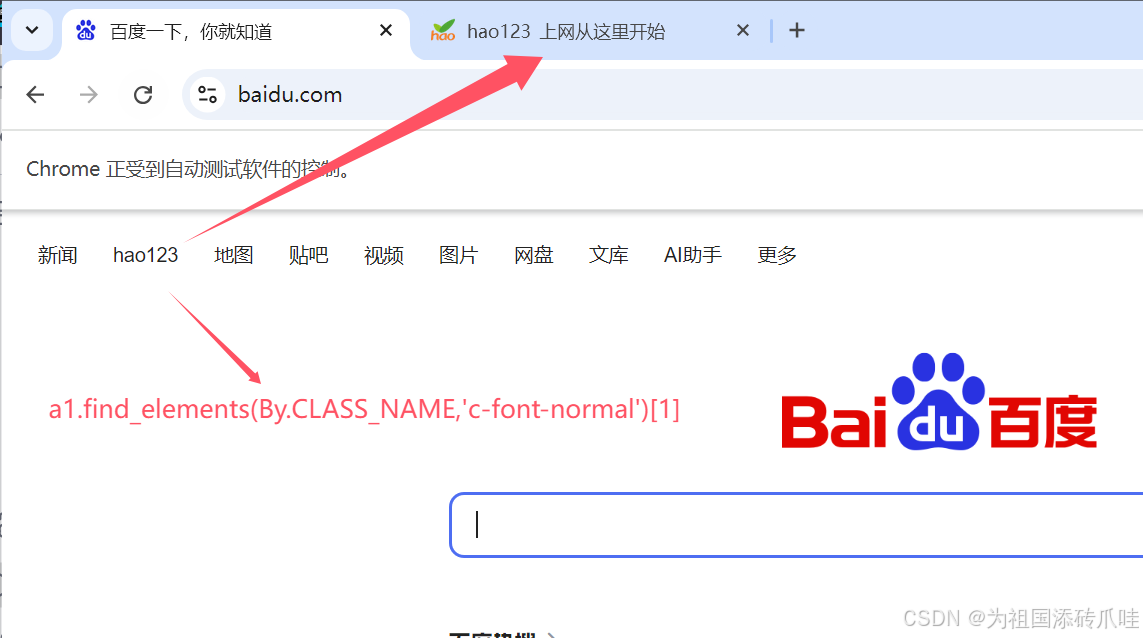
(4)TAG_NAME定位
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time
#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
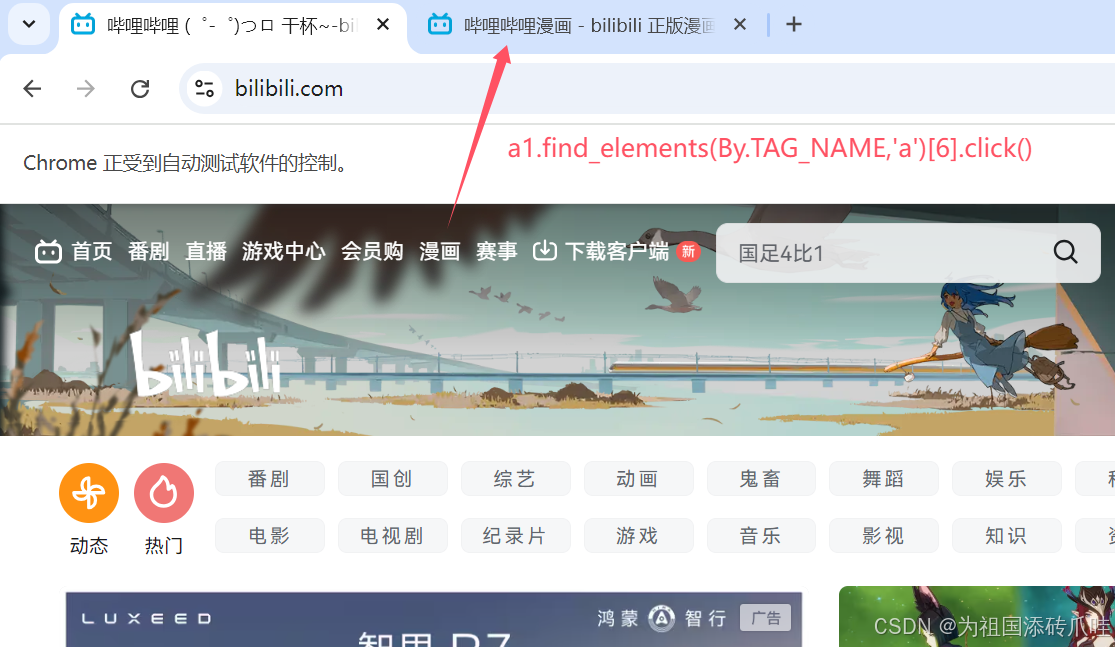
a1.get('http:/bilibili.com/')
time.sleep(2)#元素定位——TAG_NAME
#找出<开头便签名字>
a1.find_elements(By.TAG_NAME,'a')[6].click()
(5)LINK_TEXT定位
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time
#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)#元素定位——LINK_TEXT
#通过精准链接文本找到标签a的元素[精准文本]
#有重复的文本,需要切片
a1.find_element(By.LINK_TEXT,'新闻').click()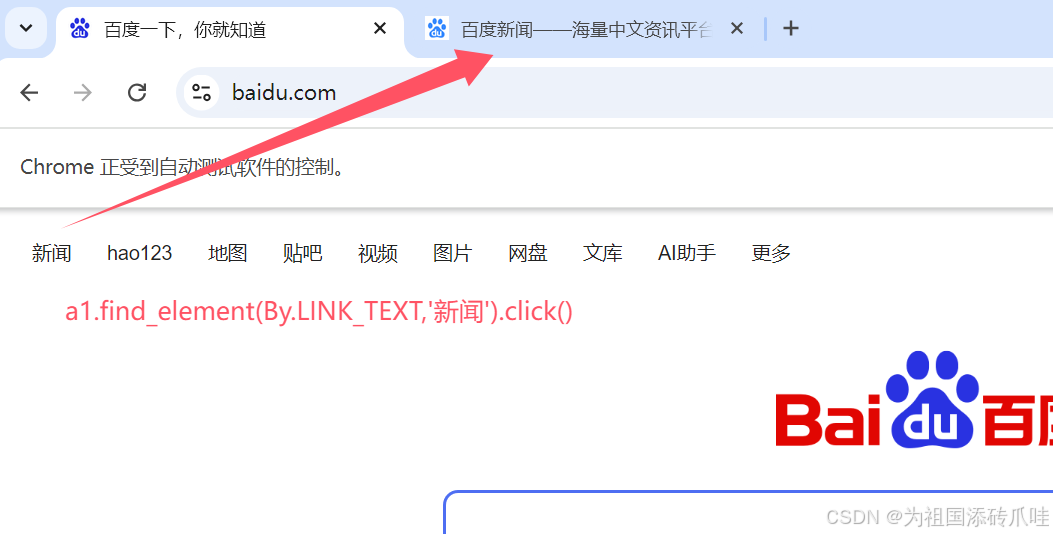
(6)PARTIAL_LINK_TEXT定位
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time
#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
a1.get('http:/bilibili.com/')
time.sleep(2)#元素定位——PARTIAL_LINK_TEXT
#通过模糊链接文本找到标签a的元素[模糊文本]
#有重复的文本,需要切片
a1.find_element(By.PARTIAL_LINK_TEXT,'音').click()(7)CSS_SELECTOR定位

from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time
#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)#元素定位——CSS_SELECTOR
#1、通过id定位——#id
#2、通过class值定位——.class
#3、通过标签头定位——标签头
#4、通过任意类型定位:"[类型='精准值']"
#5、通过任意类型定位:"[类型*='模糊值']"
#6、通过任意类型定位:"[类型^='开头值']"
#7、通过任意类型定位:"[类型$'结尾值']"
a1.find_element(By.CSS_SELECTOR,'#kw').send_keys('hello')(8)XPATH定位
Copy XPath:通过属性+路径定位,属性如果是随机的就定位不到
Copy full XPath:完整路径(缺点是定位值比较长,优点是基本100%正确)

from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time
#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)#元素定位——XPath
a1.find_element(By.XPATH,'//*[@id="kw"]').send_keys('hello')
from selenium import webdriver #用于操作浏览器
from selenium.webdriver.chrome.options import Options #用于设置谷歌浏览器
from selenium.webdriver.chrome.service import Service #用于管理驱动
from selenium.webdriver.common.by import By
import time
#设置浏览器、启动浏览器
def func():q1=Options()q1.add_argument('--no-sandbox')q1.add_experimental_option('detach',True)a1=webdriver.Chrome(service=Service('chromedriver.exe'),options=q1)return a1
a1=func()
#打开指定网址
a1.get('http:/baidu.com/')
time.sleep(2)#元素定位——XPath
a1.find_element(By.XPATH,'/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input').send_keys('hello')