# coding: utf-8
import osos.environ['KMP_DUPLICATE_LIB_OK'] = 'True'# 导入torch工具
import jsonimport torch
# 导入nn准备构建模型
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 导入torch的数据源 数据迭代器工具包
from torch.utils.data import Dataset, DataLoader
# 用于获得常见字母及字符规范化
import string
# 导入时间工具包
import time
# 引入制图工具包
import matplotlib.pyplot as plt
# 从io中导入文件打开方法
from io import open# 1 获取常用的字符 标点,把每个char字符作为一个token,用onehot编码表示token
# 因此我们的词表就是 char表 (字符表) 57个char
all_letters = string.ascii_letters + " ,.;'"
print(all_letters)n_letter = len(all_letters) # 词表的大小
print('字符表的长度:', n_letter)# 2 获取国家的类别种数
# 国家名 种类数
categorys = ['Italian', 'English', 'Arabic', 'Spanish', 'Scottish', 'Irish', 'Chinese', 'Vietnamese', 'Japanese','French', 'Greek', 'Dutch', 'Korean', 'Polish', 'Portuguese', 'Russian', 'Czech', 'German']
# 国家名 个数,就是模型的 (linear输出维度) 分类数
categorynum = len(categorys)
print('categorys--->', categorys)# 3 读取数据
def read_data(filename):# 3.1 初始化空列表两个my_list_x, my_list_y = [], []# 3.2 读取文件内容with open(filename, 'r', encoding='utf-8') as fr:for line in fr.readlines():# 异常点判断:改行长度<=5,说明这是异常样本,直接跳到下一行if len(line) <= 5:continuex, y = line.strip().split('\t')my_list_x.append(x)my_list_y.append(y)# 3.3 返回两个列表return my_list_x, my_list_y# 4 构建数据集
class NameClsDataset(Dataset):def __init__(self, mylist_x, mylist_y):self.mylist_x = mylist_xself.mylist_y = mylist_ydef __len__(self):return len(self.mylist_x)def __getitem__(self, item):# 01 item 异常值出处理index = min(max(item, 0), len(self.mylist_x) - 1)# 02 根据idx拿到人名 国家名x = self.mylist_x[index]y = self.mylist_y[index]# 03 完成onehottensor_x = torch.zeros(len(x), n_letter)for idx, letter in enumerate(x):tensor_x[idx][all_letters.find(letter)] = 1# 04 获得标签tensor_y = torch.tensor(categorys.index(y), dtype=torch.long)return tensor_x, tensor_y# 5 构建dataloader
def get_dataloader():filename = './data/name_classfication.txt'my_list_x, my_list_y = read_data(filename)mydataset = NameClsDataset(my_list_x, my_list_y)my_dataloader = DataLoader(mydataset,batch_size=1,shuffle=True, # 打乱顺序# drop_last=True, # 是否丢弃最后那个不足一个batch_size的数据组# collate_fn=collate_fn, # 处理一个batch的数据为整齐的维度)x, y = next(iter(my_dataloader))# print(x)# print(x.shape)# print(y)return my_dataloader# 6 创建rnn模型
class MyRNN(nn.Module):def __init__(self, input_size, hidden_size, output_size, num_layers=1):super().__init__()self.input_size = input_sizeself.hidden_size = hidden_sizeself.output_size = output_sizeself.num_layers = num_layersself.rnn = nn.RNN(self.input_size, self.hidden_size,self.num_layers, batch_first=True)# self.linear = nn.Linear(self.hidden_size, self.hidden_size)self.linear = nn.Linear(self.hidden_size, self.output_size)self.softmax = nn.LogSoftmax(dim=-1)def forward(self, input):# input.shape = (1, 9, 57)# hidden.shape = (1, 1, 128)# rnn_output.shape = (1, 9, 128)# rnn_hn.shape = (1, 1, 128)# rnn_output, _ = self.rnn(input)rnn_output, rnn_hn = self.rnn(input)# temp.shape = (1, 128)# temp = rnn_output[0][-1].unsqueeze(0)temp = rnn_hn[0]# output.shape=(1,18)# self.softmax(output) (2, 18)output = self.linear(temp) # 可以接受三维数据return self.softmax(output), rnn_hn# 7 测试RNN
def ceshiRNN():# 1 拿到数据my_dataloader = get_dataloader()# 2 实例化模型input_size = n_letter # 字符表的大小 (词表的大小)hidden_size = 128 # 超参数 768,rnn输出维度output_size = len(categorys) # 18,分类总数my_rnn = MyRNN(input_size, hidden_size, output_size)# 3 将数据送入到模型x, y = next(iter(my_dataloader))output, hn = my_rnn(x) # output.shape = (1, 18)print(output.shape)print(hn.shape)# 8 训练RNN
def train_my_rnn():epochs = 1my_lr = 1e-3# 1 读取数据my_list_x, my_list_y = read_data('./data/name_classfication.txt')# 2 定义datasetmyDataset = NameClsDataset(my_list_x, my_list_y)# 3 实例化dataloadermy_dataloader = DataLoader(myDataset, batch_size=1, shuffle=True)# 4 实例化RNN模型input_size = 57hidden_size = 128output_size = 18my_rnn = MyRNN(input_size, hidden_size, output_size)# 5 损失函数my_crossentropy = nn.NLLLoss()# 6 优化器my_optimizer = optim.Adam(my_rnn.parameters(), lr=my_lr)# 7 日志start_time = time.time()total_iter_num = 0 # 已经训练好的样本数total_loss = 0 # 总的losstotal_loss_list = [] # 每隔多少步存储loss-avgtotal_acc_num = 0total_acc_list = [] # 存储间隔准确率acc-avg# 8 开始训练# 8.1 外部循环for epoch_idx in range(epochs):# 8.2 batch循环for i, (x, y) in enumerate(my_dataloader):# 8.3 将x送入到模型 一轮模型训练output, hn = my_rnn(x)my_loss = my_crossentropy(output, y)my_optimizer.zero_grad()my_loss.backward()my_optimizer.step()total_iter_num += 1total_loss += my_loss.item()item1 = 1 if torch.argmax(output, dim=-1).item() == y.item() else 0total_acc_num += item1# 每隔 100 步存储avg-loss acc-avgif total_iter_num % 100 == 0:# 保存一下平均损失loss_avg = total_loss / total_iter_numtotal_loss_list.append(loss_avg)# acc-avgacc_avg = total_acc_num / total_iter_numtotal_acc_list.append(acc_avg)if total_iter_num % 1000 == 0:loss_avg = total_loss / total_iter_numacc_avg = total_acc_num / total_iter_numend_time = time.time()use_time = end_time - start_timeprint('当前的训练批次:%d, 平均损失:%.5f, 训练时间:%.3f, 准确率:%.2f' % (epoch_idx + 1,loss_avg,use_time,acc_avg))# 9 保存模型torch.save(my_rnn.state_dict(), './model/my_rnn.bin')# 10 结束all_time = time.time() - start_timeprint('总耗时:', all_time)return total_loss_list, total_acc_list, all_time# 9 将模型结果进行保存,方便进行读取
def save_rnn_res():# 1 训练模型,得到需要的结果total_loss_list, total_acc_list, all_time = train_my_rnn()# 2 定义一个字典dict1 = {'loss': total_loss_list,'time': all_time,'acc': total_acc_list}# 3 保存成jsonwith open('./data/rnn_result.json', 'w') as fw:fw.write(json.dumps(dict1))# 10 读取模型结果json
def read_json(json_path):with open(json_path, 'r') as fr:# '{a:1, b:2,,,}' --> json.loads()# json.load() 加载json文件res = json.load(fr)return res# 11 绘图
def plt_RNN():# 1 拿到数据rnn_results = read_json('./data/rnn_result-epoch3.json')total_loss_list_rnn, all_time_rnn, total_acc_list_rnn = rnn_results['loss'], rnn_results['time'], rnn_results['acc']lstm_results = read_json('./data/lstm_result-epoch3.json')total_loss_list_lstm, all_time_lstm, total_acc_list_lstm = lstm_results['loss'], lstm_results['time'], lstm_results['acc']gru_results = read_json('./data/gru_result-epoch3.json')total_loss_list_gru, all_time_gru, total_acc_list_gru = gru_results['loss'], gru_results['time'], gru_results['acc']# 2 绘制loss对比曲线图plt.figure(0)plt.plot(total_loss_list_rnn, label='RNN')plt.plot(total_loss_list_lstm, label='LSTM', color='red')plt.plot(total_loss_list_gru, label='GRU', color='orange')plt.legend(loc='upper right')plt.savefig('./picture/loss.png')plt.show()# 3 绘制耗时柱状图plt.figure(1)x_data = ['RNN', 'LSTM', 'GRU']y_data = [all_time_rnn, all_time_lstm, all_time_gru]plt.bar(range(len(x_data)), y_data, tick_label=x_data)plt.savefig('./picture/use_time.png')plt.show()# 4 绘制acc曲线图plt.figure(2)plt.plot(total_acc_list_rnn, label='RNN')plt.plot(total_acc_list_lstm, label='LSTM', color='red')plt.plot(total_acc_list_gru, label='GRU', color='orange')plt.legend(loc='upper right')plt.savefig('./picture/acc.png')plt.show()# 12 定义预测输入的x --》 tensor_x
def line2tensor(x):tensor_x = torch.zeros(len(x), n_letter)for li, letter in enumerate(x):tensor_x[li][all_letters.find(letter)] = 1return tensor_x# 13 预测主函数
def rnn_predict(x):# 1 x --》 tensor_xtensor_x = line2tensor(x)# 2 实力化模型my_rnn = MyRNN(input_size=57, hidden_size=128, output_size=18)my_rnn.load_state_dict(torch.load('./model/my_rnn.bin'))# 3 预测with torch.no_grad(): # 预测时不去计算梯度input0 = tensor_x.unsqueeze(0) # input0 是三维的,rnn需要output, hn = my_rnn(input0)topv, topi = output.topk(3, 1, True)print('人名是', x)# 4 打印topk个for i in range(3):value = topv[0][i]index = topi[0][i]cate = categorys[index]print('国家名是:', cate)if __name__ == '__main__':# filename = './data/name_classfication.txt'# x, y = read_data(filename)# print(x)# print(y)# get_dataloader()# ceshiRNN()# train_my_rnn()# plt_RNN()rnn_predict('zhang')
人名分类器(nlp)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/479255.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

ubuntu设置程序开机自启动
文章目录 1、概述2、图形界面设置3、设置为Systemd服务 1、概述 测试环境:ubuntu22.04 带图形界面 实现方式1:通过图形界面的【启动应用程序】设置开机自启动; 实现方式2:通过配置为服务实现开机自启动。 2、图形界面设置 优点&am…

4.STM32之通信接口《精讲》之IIC通信---软件实现IIC《深入浅出》面试必备!
接下正式,进入软件编写IIC时序了,并实现对MPU6050的控制,既然是软件实现,那么硬件方面,我仅需两根控制线即可,即:数据控制线SDA,时钟控制线SCL。(人为软件层面定义的&…
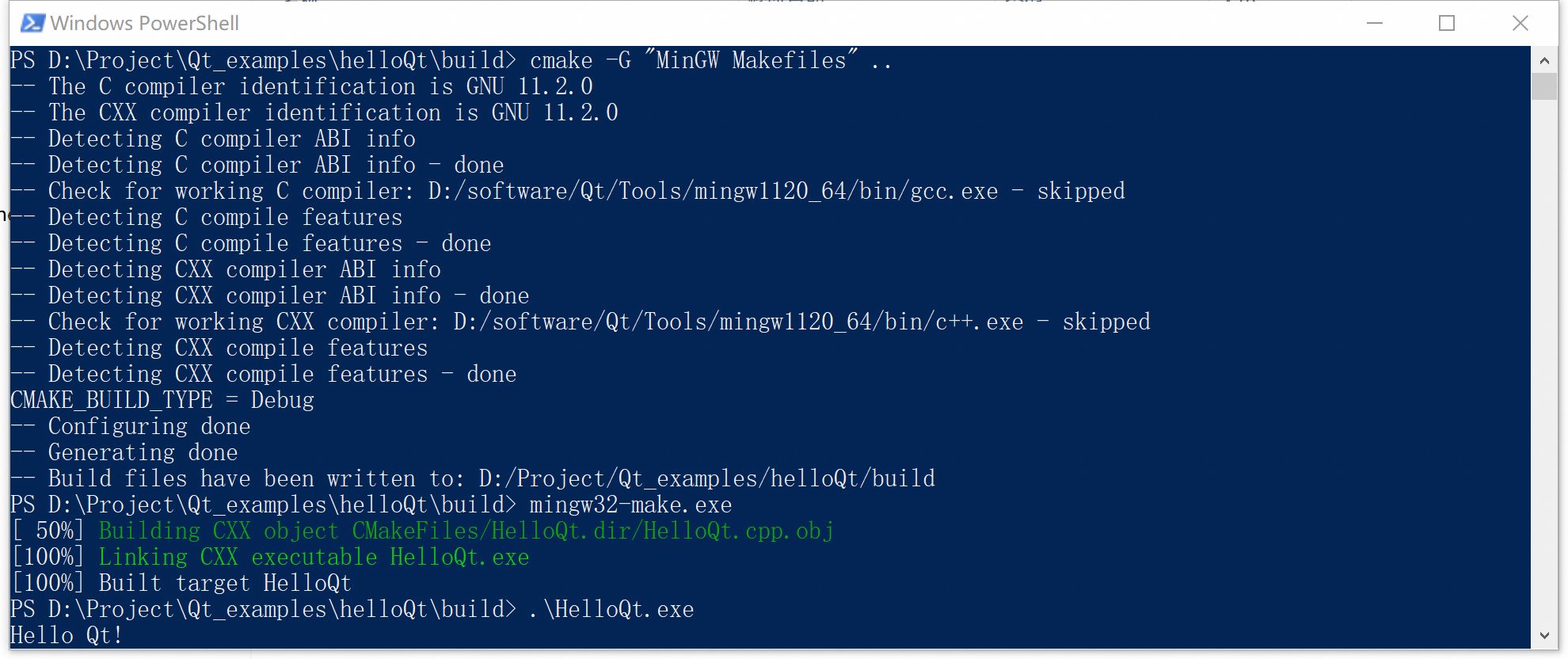
使用mingw+CMake在Windows平台编译OpenCV
1. 安装mingw和cmake cmake的安装比较简单,百度一下完成相关操作即可,笔者安装的是3.24.3版本。 Mingw的安装也有很多相关文章,不过我使用的是安装QT时附带安装的mingw,其路径为D:\software\Qt\Tools\mingw1120_64。其中的bin文件…

2024APMCM亚太杯数学建模C题【宠物行业】原创论文分享
大家好呀,从发布赛题一直到现在,总算完成了2024 年APMCM亚太地区大学生数学建模竞赛C题的成品论文。 给大家看一下目录吧:
目录
摘 要: 10
一、问题重述 14
二.问题分析 15
2.1问题一 15
2.2问题二 15
2.3问题三…

win10中使用ffmpeg和MediaMTX 推流rtsp视频
在win10上测试下ffmpeg推流rtsp视频,需要同时用到流媒体服务器MediaMTX 。ffmpeg推流到流媒体服务器MediaMTX ,其他客户端从流媒体服务器拉流。
步骤如下:
1 下载MediaMTX
github: Release v1.9.3 bluenviron/mediamtx GitHub…
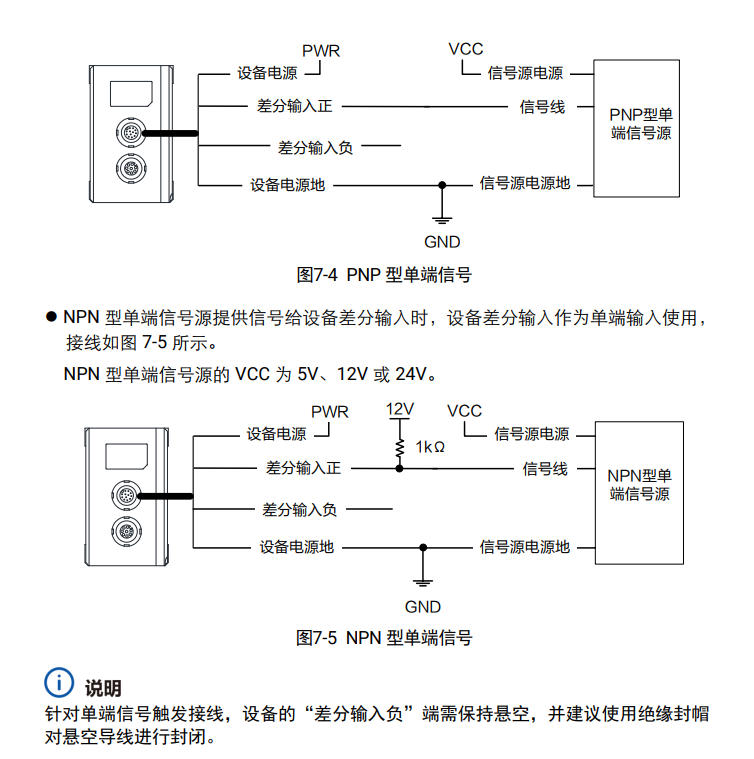
海康面阵、线阵、读码器及3D相机接线说明
为帮助用户快速了解和配置海康系列设备的接线方式,本文将针对海康面阵相机、线阵相机、读码器和3D相机的主要接口及接线方法进行全面整理和说明。 一、海康面阵相机接线说明
海康面阵相机使用6-pin P7接口,其功能设计包括电源输入、光耦隔离信号输入输出…

vue3(十七)-基础入门之vue-nuxt路由
一、路由 Nuxt.js 依据 pages 目录结构自动生成 vue-router 模块的路由配置。 要在页面之间使用路由,建议使用 < nuxt-link> 标签。
<template><nuxt-link to"/">首页</nuxt-link>
</template>1、基础路由
pages 的目录结…

C++设计模式-中介者模式
动机(Motivation)
多个对象相互关联的情况,对象之间常常会维持一种复杂的引用关系,如果遇到一些需求的更改,这种直接的引用关系将面临不断的变化。在这种情况下,可以使用一种”中介对象“来管理对象间的关联关系,避免…
IntelliJ+SpringBoot项目实战(十四)--在SpringBoot中整合SpringSecurity和JWT(上)
SpringSecurity是大名鼎鼎的认证授权框架,在SSH时代就已经大放异彩。在JAVA项目中,权限框架的解决方案主要是以SpringSecurity和Shiro为主。JWT是目前主流的基于access-token的的认证框架,在项目中一般时SpringSecurity和JWT结合使用…

【AI系统】Tensor Core 架构演进
自 Volta 架构时代起,英伟达的 GPU 架构已经明显地转向深度学习领域的优化和创新。2017 年,Volta 架构横空出世,其中引入的张量核心(Tensor Core)设计可谓划时代之作,这一设计专门针对深度学习计算进行了优…

问题记录-Java后端
问题记录 目录 问题记录1.多数据源使用事务注意事项?2.mybatis执行MySQL的存储过程?3.springBoot加载不到nacos配置中心的配置问题4.服务器产生大量close_wait情况 1.多数据源使用事务注意事项? 问题:在springBoot项目中多表处理数…
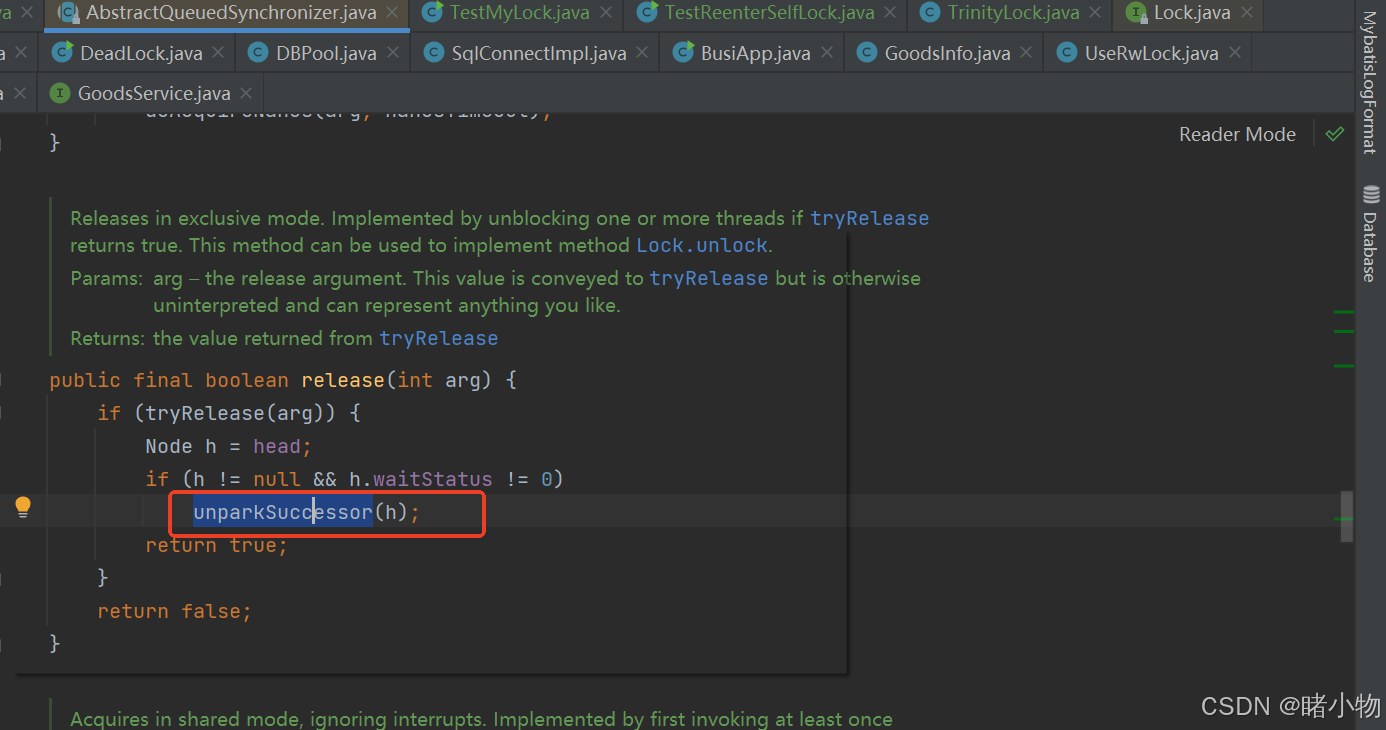
java:aqs实现自定义锁
aqs采用模板方式设计模式,需要重写方法 package com.company.aqs;import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;…

day11_JS初识_语法
day11_JS初识_语法
今日学习目标 : 入门HarmonyOS生态中 , ArkTS最基础的语法 JavaScript , 今天最主要的学习内容了解和掌握JavaScript的基础语法 , 并灵活的再后面开发过程进行使用
今日学习目标 什么是JavaScript JavaScript组成 JavaScript执行环境 JavaScript代码的书…
![[C++]:IO流](https://img-blog.csdnimg.cn/img_convert/0af94504654871c3f774566834af19d6.png)

基于Kubernetes编排部署EFK日志收集系统
基于K8S编排部署EFK日志收集系统
案例分析
1. 规划节点
节点规划,见表1。
表1 节点规划
IP主机名k8s版本信息192.168.100.3masterv1.25.2192.168.100.4nodev1.25.2 2. 基础准备
Kubernete环境已安装完成,将提供的软件包efk-img.tar.gz上传至master…

Kubernetes 还是 SpringCloud?
前些年,随着微服务的概念提出以及落地,不断有很多的公司都加入到了这场技术革新中,现在可谓是人人都在做和说微服务。 提到微服务,Java栈内,就不得不提SpringBoot、SpringCloud、Dubbo。 近几年,随着Cloud …

ChatGPT如何辅助academic writing?
今天想和大家分享一篇来自《Nature》杂志的文章《Three ways ChatGPT helps me in my academic writing》,如果您的日常涉及到学术论文的写作(writing)、编辑(editing)或者审稿( peer review)&a…

101.【C语言】数据结构之二叉树的堆实现(顺序结构) 2
目录
1.堆删除函数HeapPop
一个常见的错误想法:挪动删除
正确方法
设计堆顶删除函数HeapPop
解析向下调整函数AdjustDown
核心思想
向下调整最多次数
向下调整的前提
代码实现
提问
细节分析
2.测试堆删除函数
运行结果
3.引申问题
运行结果
4.练习
分析
代码…
【机器学习chp8】统计学习理论
前言
本文遗留问题:无
目录
前言
一、结构风险最小化
1、最小化风险决策
2、分类与回归中的最小化风险决策
3、统计学习的基本目标
4、无免费午餐定理
5、Hoeffding不等式
(1)背景及定义
(2)Hoeffding不等式…

Springboot启动报错’javax.management.MBeanServer’ that could not be found.
报错信息如下图: 解决办法: 1.在你的.yml文件或者.properties文件里加上如下配置: properties:
management.endpoints.jmx.enabledfalseyml:
management:endpoints:jmx:enabled: false2.如果以上方法行不通,在springboot启动类…