数据增强方法
数据增强是自然语言处理(NLP)中常用的一种技术,通过生成新的训练样本来扩充数据集,从而提高模型的泛化能力和性能。回译数据增强法是一种常见的数据增强方法,特别适用于文本数据。
回译数据增强法
定义
- 通过将一种语言翻译成不同的语言,再转换回来的一种方式。例如,将中文文本翻译成英文,然后再将英文翻译回中文。
优势
- 操作简便:只需要使用现有的翻译工具即可实现。
- 获得新语料质量高:翻译后的文本通常能够保持较高的语义一致性,且语法结构合理。
目的
- 增加数据集:通过生成新的训练样本来扩展数据集,从而提高模型的泛化能力。
存在的问题
- 高重复率:在短文本回译过程中,新语料与原语料可能存在很高的重复率,这并不能有效增大样本的特征空间。
高重复率解决办法
- 进行连续的多语言翻译:例如,中文→韩文→日语→英文→中文。最多只采用3次连续翻译,更多的翻译次数将产生效率低下、语义失真等问题。
使用工具
- ChatGPT:可以利用 ChatGPT 进行多语言翻译。
- 有道翻译接口:基于有道翻译接口进行多语言翻译。
具体步骤
-
准备原始数据
- 收集并准备好需要增强的原始文本数据。
-
选择翻译工具
- 可以选择 ChatGPT 或者有道翻译接口等工具进行翻译。
-
进行多语言翻译
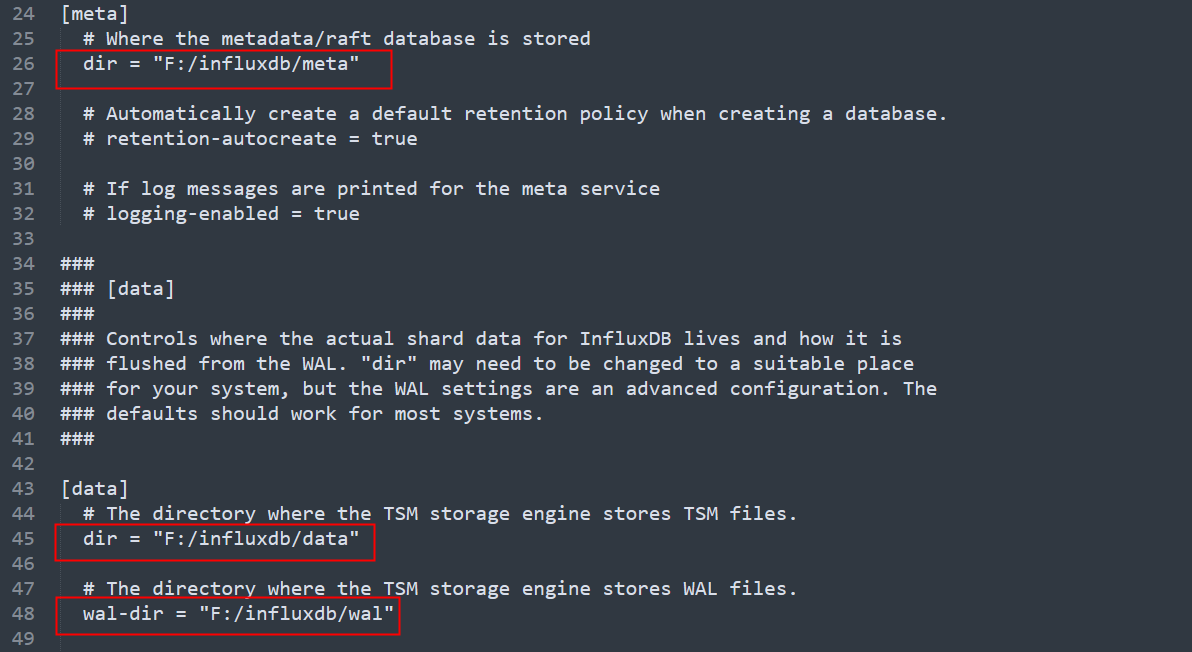
- 将原始文本翻译成另一种语言,再从该语言翻译回原始语言。
- 为了减少重复率,可以进行多次连续翻译,但不超过3次。
-
合并新旧数据
- 将生成的新文本与原始文本合并,形成扩增后的数据集。
示例代码
以下是使用有道翻译接口进行回译数据增强的示例代码:
import requests
import time# 有道翻译API
def translate(text, from_lang, to_lang):url = "http://fanyi.youdao.com/translate"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}data = {'doctype': 'json','type': f'{from_lang}-{to_lang}','i': text}response = requests.post(url, headers=headers, data=data)result = response.json()return result['translateResult'][0][0]['tgt']# 回译数据增强
def back_translation(text, lang_sequence):for i in range(len(lang_sequence) - 1):text = translate(text, lang_sequence[i], lang_sequence[i + 1])time.sleep(1) # 防止请求过于频繁return text# 示例
original_text = "我喜欢编程。"
lang_sequence = ['zh', 'en', 'ko', 'ja', 'zh']
augmented_text = back_translation(original_text, lang_sequence)
print("Original Text:", original_text)
print("Augmented Text:", augmented_text)
使用 ChatGPT 进行回译
如果你使用的是 ChatGPT API,可以通过以下方式实现回译:
import openai# 设置 OpenAI API 密钥
openai.api_key = 'your_openai_api_key'# 使用 ChatGPT 进行翻译
def translate_with_chatgpt(text, from_lang, to_lang):prompt = f"Translate the following {from_lang} text to {to_lang}: {text}"response = openai.Completion.create(engine="text-davinci-003",prompt=prompt,max_tokens=100)return response.choices[0].text.strip()# 回译数据增强
def back_translation_with_chatgpt(text, lang_sequence):for i in range(len(lang_sequence) - 1):text = translate_with_chatgpt(text, lang_sequence[i], lang_sequence[i + 1])time.sleep(1) # 防止请求过于频繁return text# 示例
original_text = "我喜欢编程。"
lang_sequence = ['Chinese', 'English', 'Korean', 'Japanese', 'Chinese']
augmented_text = back_translation_with_chatgpt(original_text, lang_sequence)
print("Original Text:", original_text)
print("Augmented Text:", augmented_text)
总结
回译数据增强法是一种简单且有效的方法,通过多语言翻译来生成新的训练样本。虽然存在一定的重复率问题,但通过连续多语言翻译可以有效缓解这一问题。