检索增强生成(Retrieval-Augmented Generation, RAG)已经成为提升大型语言模型(LLMs)能力的重要方法之一,通过整合外部知识,显著改善了生成内容的质量和相关性。
RAG 的局限性
传统的 RAG 系统虽然表现优异,但其局限性也不容忽视:
- 数据结构扁平化
传统 RAG 系统往往依赖扁平化的数据结构,难以捕捉信息之间的复杂关系。这种缺陷导致生成的答案片段化,缺乏上下文的一致性。 - 有限的上下文意识
系统在处理需要综合多个数据点的复杂问题时表现不佳,生成的答案缺乏对数据间相互关联的全面理解。
GraphRAG的局限性
GraphRAG 通过使用** 知识图谱** 对文本中的实体和关系进行结构化建模,从而能够捕捉信息间的复杂关联。GraphRAG 首先在整个私有数据集上创建实体和关系的引用,随后采用自底向上的聚类方法,将数据层次化地组织为语义簇。
然而,当数据集中加入新的知识时,GraphRAG 必须重新执行整个图构建流程。这种方式对于动态更新的数据集来说效率低下且成本高昂。
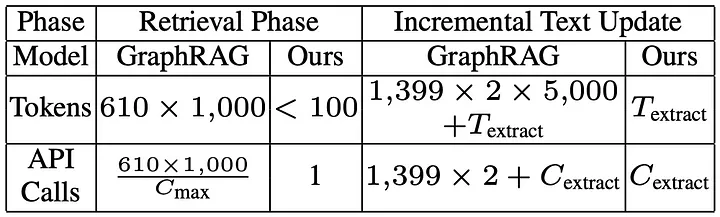
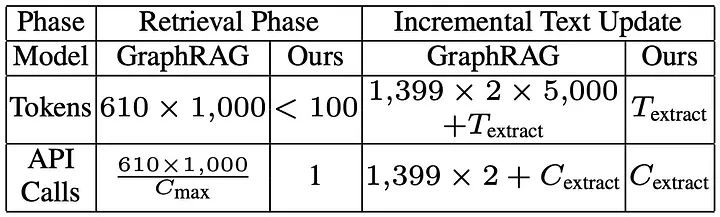
- 资源需求高:需要大量 API 调用(通常依赖昂贵的模型如 GPT-4o)。
- 数据更新昂贵:每次更新数据时,必须重建整个图谱。
LightRAG的创新点
相比之下,LightRAG 的增量更新机制大大简化了流程。它通过简单的 联合操作(union operation),将新的图节点和边直接添加到现有图谱中。这种方式避免了重复构建图谱的高昂开销,同时确保知识库实时更新,适应动态数据需求。
LightRAG
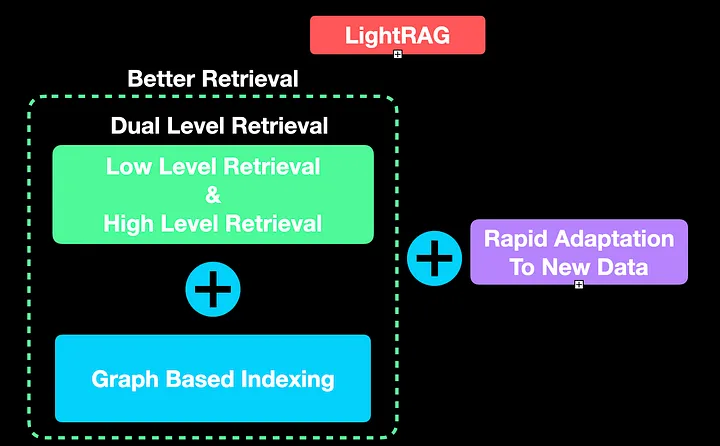
LightRAG 的核心卖点在于 基于图的索引 和 双层检索框架。以下是对这两个关键功能的深入解析:
Graph-based Indexing
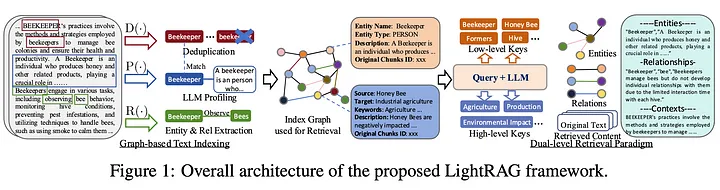
以下是 LightRAG 进行基于图索引的步骤:
-
实体与关系(ER)提取
实体与关系提取由图中的 R(.) 表示。此步骤确保从给定文档中首先提取简单的实体。例如,在上图的示例中,“蜜蜂”(bees)和“养蜂人”(beekeeper)是两个实体,它们通过“观察”(observe)关系相关联,即养蜂人观察蜜蜂。 -
使用 LLM 生成键值(KV)对
使用简单的 LLM 生成键值对。LLM 的分析步骤为实体或关系提供了简要的说明或解释。例如,在所选示例中,LLM 解释了“养蜂人”是谁。此步骤在图中由 P(.) 表示。需要注意的是,此 LLM 不同于主 RAG 流程中使用的通用 LLM。 -
去重
鉴于文档内容与蜜蜂相关,实体“养蜂人”可能从多个文档或文本块中被多次提取。因此,需要一个去重步骤,仅保留一个具有相同含义的实体,丢弃其他重复项。此步骤在图中由 D(.) 表示。
Dual-level Retrieval
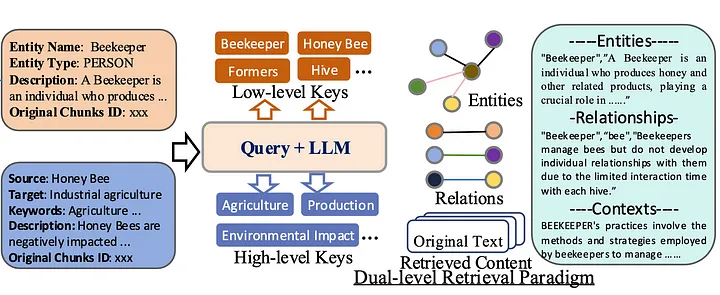
对 RAG 系统的查询可以分为两种类型——具体的或抽象的。在同样的蜜蜂示例中,具体查询可能是:“一个蜂巢中可以有多少只蜂王?” 抽象查询可能是:“气候变化对蜜蜂有哪些影响?” 为了应对这种多样性,LightRAG 采用了两种检索方式:
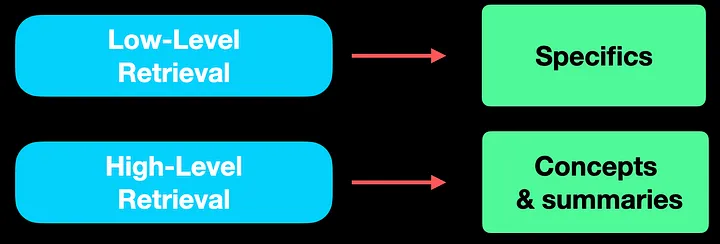
低层检索:简单地提取精确的实体及其关系,如蜜蜂(bees)、观察(observe)和养蜂人(beekeepers)。
高层检索:通过使用 LLM,LightRAG 聚合信息并总结多个信息来源。
架构意义
进行这些操作并切换到 LightRAG 的确能改进执行时间。在索引过程中,每个文本块只需调用一次 LLM 来提取实体及其关系。
同样,在用户查询时,仅使用与索引相同的 LLM 从文本块中检索实体和关系。这大大减少了检索的开销,从而降低了计算成本。因此,最终拥有了一个“轻量”的 RAG!
将新知识整合到现有图谱中看起来是一个无缝的操作。与其在有新信息时重新索引整个数据,可以简单地将新知识附加到现有图谱中。
评估
评估中,LightRAG 与 Naive RAG、RQ-RAG、HyDE 和 GraphRAG 进行了比较。为了保持比较的公平性,统一使用了 GPT-4o-mini 作为 LLM,并在所有数据集上采用固定的分块大小(1200)。答案的评估标准包括全面性、多样性以及回答用户问题的有效性。
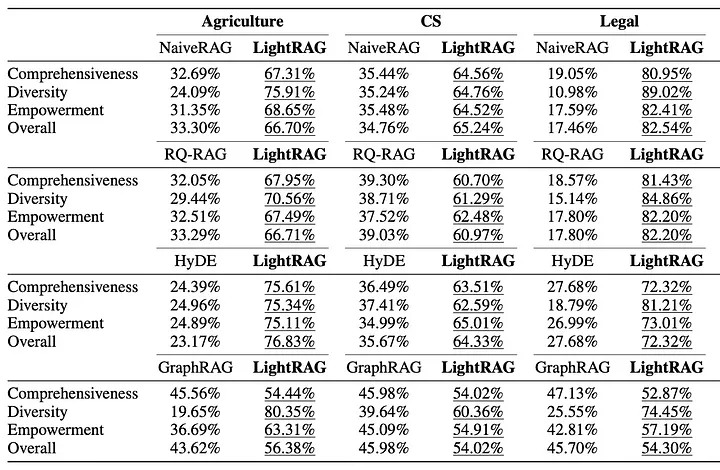
正如下划线结果所示,LightRAG 超越了当前所有最先进的方法。
总体而言,得出了以下结论:
• 使用基于图的方法(如 GraphRAG 或 LightRAG)相比基础的 Naive RAG 有显著改进。
• LightRAG 通过双层检索范式生成了相当多样化的答案。
• LightRAG 能够更好地处理复杂查询。
结论
尽管 RAG 是一种相对较新的技术,但这一领域正在快速发展。像 LightRAG 这样的技术可以将 RAG 流程引入廉价的通用硬件,这是非常受欢迎的。尽管硬件领域不断进步,但始终需要在计算受限的硬件上实时运行 LLM 和 RAG 流程。



















