目录
评估模型的性能
保存模型
参数超参数调整
网格搜索
评估模型的性能
显然,我们现在想测试我们的模型表现得如何。PySpark 在包的 .evaluation 部分提供了一些分类和回归的评估方法:
import pyspark.ml.evaluation as ev我们将使用 BinaryClassficationEvaluator 来测试我们的模型表现如何:
evaluator = ev.BinaryClassificationEvaluator(rawPredictionCol='probability', labelCol='INFANT_ALIVE_AT_REPORT')rawPredictionCol 可以是估计器产生的 rawPrediction 列,也可以是概率。
让我们看看我们的模型表现如何:
print(evaluator.evaluate(test_model, {evaluator.metricName: 'areaUnderROC'}))
print(evaluator.evaluate(test_model, {evaluator.metricName: 'areaUnderPR'}))前面的代码产生了以下结果:

ROC 曲线下面积为 74%,PR 曲线下面积为 71%,显示出一个定义良好的模型,但并没有什么非凡之处;如果我们有其他特征,我们可以提高这个数值,但这不是本章(更不用说这本书)的目的。
保存模型
PySpark 允许你保存管道定义以供以后使用。它不仅保存管道结构,还保存所有转换器和估计器的定义:
pipelinePath = './infant_oneHotEncoder_Logistic_Pipeline'
pipeline.write().overwrite().save(pipelinePath)所以,你可以在以后加载它,并直接使用它来 .fit(...) 和预测:
loadedPipeline = Pipeline.load(pipelinePath)
loadedPipeline \.fit(births_train)\.transform(births_test)\.take(1)前面的代码产生了相同的结果(正如预期):
然而,如果你想保存估计出的模型,你也可以这样做;而不是保存管道,你需要保存 PipelineModel。
要保存你的模型,请看以下示例:
from pyspark.ml import PipelineModel
modelPath = './infant_oneHotEncoder_Logistic_PipelineModel'
model.write().overwrite().save(modelPath)
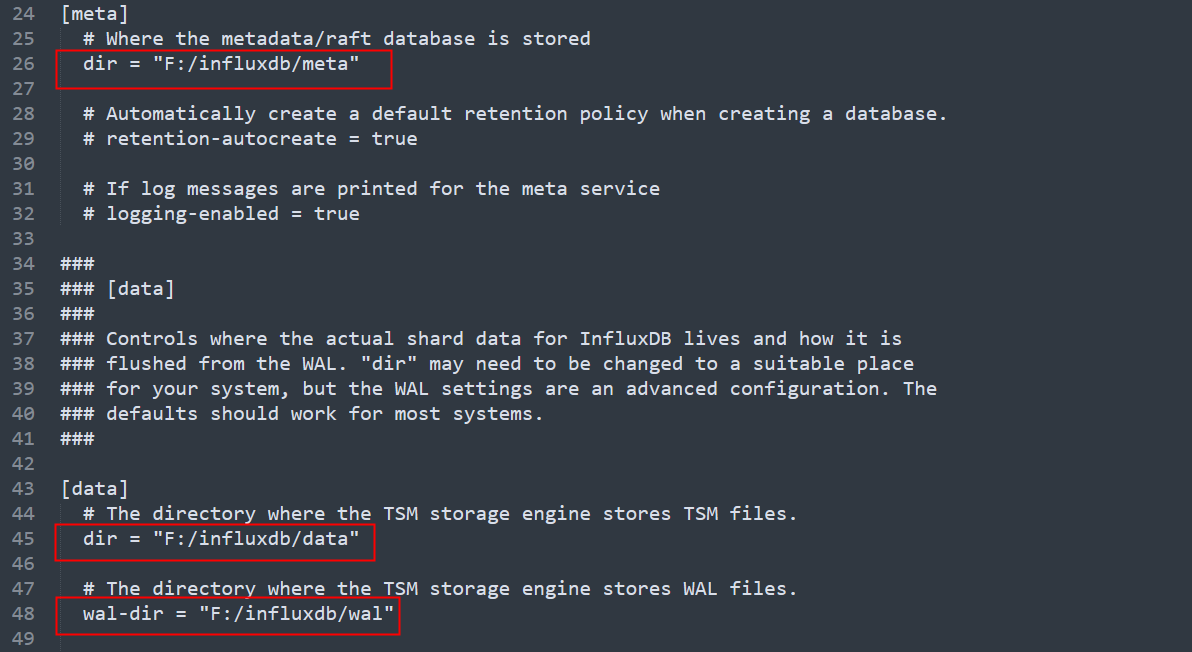
loadedPipelineModel = PipelineModel.load(modelPath)
test_reloadedModel = loadedPipelineModel.transform(births_test)前面的脚本使用 PipelineModel 类的类方法 .load(...) 来重新加载估计出的模型。你可以将 test_reloadedModel.take(1) 的结果与我们之前展示的 test_model.take(1) 的输出进行比较。
参数超参数调整
很少情况下,我们的第一个模型会是我们能做的最好的。仅仅通过观察我们的指标,并因为它通过了我们预先设定的性能阈值而接受模型,这很难说是一种科学的方法来找到最佳模型。
参数超参数调整的概念是找到模型的最佳参数:例如,正确估计逻辑回归模型所需的最大迭代次数或决策树的最大深度。
在这一部分,我们将探讨两种概念,它们允许我们为我们的模型找到最佳参数:网格搜索和训练-验证分割。
网格搜索
网格搜索是一种穷尽算法,它遍历定义的参数值列表,估计单独的模型,并根据某些评估指标选择最佳模型。
这里应该谨慎说明:如果你定义了太多的参数要优化,或者这些参数的值太多,选择最佳模型可能需要很长时间,因为随着参数数量和参数值数量的增加,需要估计的模型数量会迅速增长。
例如,如果你想微调两个参数,每个参数有两个参数值,你将不得不拟合四个模型。增加一个具有两个值的参数将需要估计八个模型,而为我们的两个参数增加一个额外的值(将其带到每个参数的三个值)将需要估计九个模型。正如你所看到的,如果你不小心,这个很快就会失控。请看以下图表进行直观检查:
在这次警示性故事之后,让我们开始微调我们的参数空间。首先,我们加载包的 .tuning 部分:
import pyspark.ml.tuning as tune接下来,让我们指定我们的模型和我们想要遍历的参数列表:
logistic = cl.LogisticRegression(labelCol='INFANT_ALIVE_AT_REPORT')
grid = tune.ParamGridBuilder() \.addGrid(logistic.maxIter, [2, 10, 50]) \.addGrid(logistic.regParam, [0.01, 0.05, 0.3]) \.build()首先,我们指定我们想要优化参数的模型。接下来,我们决定我们将优化哪些参数,以及要测试这些参数的哪些值。我们使用 .tuning 子包中的 ParamGridBuilder() 对象,并使用 .addGrid(...) 方法向网格中添加参数:第一个参数是我们要优化的模型的参数对象(在我们的例子中,这些是 logistic.maxIter 和 logistic.regParam),第二个参数是我们想要遍历的值列表。调用 .ParamGridBuilder 上的 .build() 方法构建网格。
接下来,我们需要一种比较模型的方法:
evaluator = ev.BinaryClassificationEvaluator(rawPredictionCol='probability', labelCol='INFANT_ALIVE_AT_REPORT')所以,再一次,我们将使用 BinaryClassificationEvaluator。现在轮到创建为我们执行验证工作的逻辑了:
cv = tune.CrossValidator(estimator=logistic, estimatorParamMaps=grid, evaluator=evaluator
)CrossValidator 需要估计器、估计器参数映射和评估器来完成其工作。模型遍历值的网格,估计模型,并使用评估器比较它们的性能。
我们不能直接使用数据(因为 births_train 和 births_test 仍然有未编码的 BIRTHS_PLACE 列),所以我们创建一个纯粹的转换管道:
pipeline = Pipeline(stages=[encoder ,featuresCreator])
data_transformer = pipeline.fit(births_train)完成这些后,我们准备好为我们的模型找到最优的参数组合了:
cvModel = cv.fit(data_transformer.transform(births_train))cvModel 将返回估计出的最佳模型。现在我们可以使用它来看看它是否比我们之前的模型表现得更好:
data_train = data_transformer \.transform(births_test)
results = cvModel.transform(data_train)
print(evaluator.evaluate(results, {evaluator.metricName: 'areaUnderROC'}))
print(evaluator.evaluate(results, {evaluator.metricName: 'areaUnderPR'}))前面的代码将产生以下结果:
正如你看到的,我们得到了一个稍微更好的结果。最佳模型有哪些参数?答案有点复杂,但以下是如何提取它的方法:
results = [([{key.name: paramValue} for key, paramValue in zip(params.keys(), params.values())], metric) for params, metric in zip(cvModel.getEstimatorParamMaps(), cvModel.avgMetrics)
]
sorted(results, key=lambda el: el[1], reverse=True)[0]前面的代码产生了以下输出: