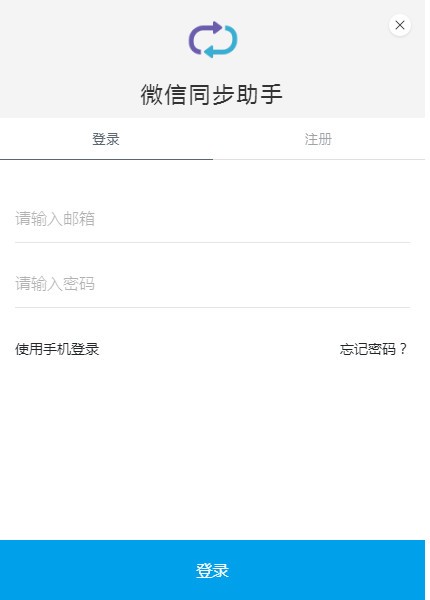
需求分析
- 我有一些资源网站,但是每次我需要资源的时候需要打开他们的网页,搜索再筛选我需要的网盘资源,这样的操作非常麻烦
- 使用python模拟这些搜索操作,然后爬取我需要的百度网盘信息
- 用python的Gui编程开发一个简单的界面
实现
界面开发
- 搜索框
- 搜索按键
- 结果展示框
#coding=utf-8from tkinter imprt *class movieFrame:def __init__(self, init_window_name):self.init_window_name = init_window_namedef setInitWindow(self):self.init_window_name.title("百度网盘_SEARCH by YoooKnight")self.init_window_name.getmetry('500x400')# 搜索框self.init_search_text = Text(self.init_window_name, width=30, height=2)self.init_search_text.grid(row=0, column=1, padx=20, pady=10)# 结果集self.init_result_data = Text(self.init_window_name, width=50, height=20)self.init_result_data.config(state=DISABLED)self.init_result_data.grid(row=1, column=1, columnspan=2, padx=20, pady=10, sticky=W)#滚动条scroll = Scrollbar(command=self.init_result_data.yview)self.init_result_data.config(yscrollcommand=scroll.set)scroll.grid(row=1,column=3, sticky=S + W + E + N)# 查询按钮self.searchButton = Button(self.init_window_name, text="查询", bg='lightblue', command=self.searchMovie)self.searchButton.grid(row=0, column=2)def searchMovie:pass
BDY资源爬虫开发
- 目前只做了一个资源网站的爬取,后期有时间会进行扩展
- 该网站做了爬虫封锁间隔时间,也就是如果连续爬取该页面会直接不给你访问,可能会等待一段时间才能继续访问,后期有时间会增加代理ip访问
from bs4 import BeautifulSoup
from urllib.request import quote
import urllib.request
import string
import reclass Spider:search = ''# 需要访问的网址indexUrl = 'http://****/'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}def __init__(self, search):self.search = searchdef getlinkList(self):# 搜索文件searchUrl = self.indexUrl + '?s=' + self.searchsearchUrl = quote(searchUrl, safe=string.printable)req = urllib.request.Request(searchUrl, headers=self.headers)res = urllib.request.urlopen(req)html = res.read().decode('utf8')# 读取详情页面soup = BeautifulSoup(html, 'html.parser')try:# 这里只找了第一个链接,所有相当于是查找到相似度最高的一个结果detailUrl = soup.find('div', class_='mainleft').find('div', class_='thumbnail').find('a').get('href')# 获取详情页面detailReq = urllib.request.Request(detailUrl, headers=self.headers)detailRes = urllib.request.urlopen(detailReq)detailHtml = detailRes.read().decode('utf-8')dic = []# 查找所有的a标签soup = BeautifulSoup(detailHtml, 'html.parser')aList = soup.findAll("a")linkUrlList = []for aTag in aList:tempHref = aTag.get("href")if tempHref and tempHref.find("pan.baidu.com")>=0:linkUrlList.append(tempHref)# 获取所有的提取码codeList = re.findall('((提取码|密码)[\:\:][ ]?.{4})', str(detailHtml))# 拼接我需要的数据index=0for link in linkUrlList:if (index<len(codeList)):tempDic = {"link": link,"code": codeList[index][0][-4:]}dic.append(tempDic)index += 1return dicexcept Exception as e:print(e)return []
整合界面和爬虫
- 点击搜索之后调用爬虫接口
- 获取网盘数据并且展示
from sourceSpider.pinghaoche import spider as pingSpiderclass movieFrame:def searchMovie(self):# 获取搜索框里面的内容search = self.init_search_Text.get(1.0, END)spiderObject = pingSpider.Spider(search)ret = spiderObject.getlinkList()index = 1self.init_result_data.config(state=NORMAL)self.init_result_data.delete(1.0, END)if ret:for temp in ret:tempIndex = format(index, '0.1f')self.init_result_data.insert(tempIndex, "链接地址:" + temp['link'] + "\n")index += 1tempIndex = format(index, '0.1f')self.init_result_data.insert(tempIndex, "提取码:" + temp['code'] + "\n\n")index += 2else:self.init_result_data.insert(1.0, "非常抱歉,没有找到你要的影片")self.init_result_data.config(state=DISABLED)
打包
- 安装pyInstaller
pip install pyInstaller
- 打包成exe文件
# F: 生成结果是一个exe文件,所有的第三方依赖、资源和代码均被打包进该exe内
# w: 不显示命令行窗口
pyInstaller -Fw xx.py
成果展示
总结
- 界面开发使用的是tkinter,后期看一下qt开发
- 在爬虫的过程中发现详情页面规则并不是确定的,发现每次爬取可能会出错,于是直接爬取所有的a标签并且对比百度网盘的地址,提取码直接用正则全文搜索出来,肯定还是有误差的,可能会出错,先把功能实现,后期修改就行
Tips:有兴趣的朋友可以+qq1592388194,这只是一个小工具,有很多问题,不介意的可以找我,大家一起学习进步,哈哈哈。
ps:
该文章已经同步发到简书,链接地址:https://www.jianshu.com/p/9a53322a6d0c