学习心得
(1)机器学习、深度学习、强化学习blabla很多内容都是面试的重点,本文结合菜鸡自身学习过程持续更新。
(2)如有不正确之处,恳请指正,共同学习,非常谢谢~
(3)可以参考面筋,如我是如何拿到字节跳动AI Lab算法Offer的?(NLP)等。
初学者学习Pytorch的建议:
(1)理论,看花书《深度学习》
(2 )通读一遍PyTorch官方文档
(3)复现经典工作(读代码和写代码交叉进行),注意去github下别人论文代码跑通没啥用,要自己复现,不会的再去看别人的代码
(4)扩充视野。基于上面前三个能力,因为复现是一开始很花时间的,现在看别人论文应该脑海有直觉代码大概咋写,看到不会的模块再去看别人代码,吸取精华,把小模块吸收为自己的内容。
在Andrew W.Track的《深度学习图解》这本书里说:深度学习的框架就是autograd加上一组预先定义好的神经元层和优化器。学习框架一般流程是先找到尽可能简单的example,微调代码并了解其中autograd系统的API,一段段修改样例直到写出所需的实验。
文章目录
- 学习心得
- 一。机器学习
- 0.学习路线与方法
- 1.学深度学习是不是需要先学机器学习?
- 2.深度学习难学吗?
- 1.问题
- 2.方法
- 3.流程
- 3.深度学习该怎么学
- 4.推荐课程
- 二。机器学习and深度学习面试题
- 第一部分:监督学习
- 一、线性回归
- 1.什么是回归?哪些模型可用于解决回归问题?👶
- 2.什么是线性回归?什么时候使用它?👶
- 3.什么是正态分布?为什么要重视它?👶
- 4.如何检查变量是否遵循正态分布?⭐️
- 5.如何建立价格预测模型?价格是否正态分布?需要对价格进行预处理吗?⭐️
- 6.解决线性回归的模型有哪些?⭐️
- 7.什么是梯度下降?它是如何工作的?⭐️
- 8.什么是正规方程?⭐️
- 9.什么是SGD-随机梯度下降?与通常的梯度下降有何不同?⭐️
- 10.有哪些评估回归模型的指标?👶
- 二、验证方式
- 1.什么是过拟合?👶
- 2.如何验证模型?👶
- 3.为什么需要将数据分为三个部分:训练,验证和测试?👶
- 4.解释交叉验证的工作原理?👶
- 5.什么是K折交叉验证?👶
- 6.如何在K折交叉验证中选择K?你最喜欢的K是什么?👶
- 三、分类
- 1.什么是分类?哪些模型可以解决分类问题?👶
- 2.什么是逻辑回归?什么时候需要使用它?👶
- 3.Logistic回归是线性模型吗?为什么?👶
- 4.什么是Sigmoid?它有什么作用?👶
- 5.如何评估分类模型?👶
- 6.什么是准确率?👶
- 7.准确率始终是一个好的指标吗?👶
- 8.什么是混淆表?表中的单元格表示什么?👶
- 9.什么是精度,召回率和F1分数?👶
- (1)精确率(precision,P值)
- (2)召回率(Recall,R值)
- (3)栗子
- 10.准确率和召回率的权衡⭐️
- 11.什么是ROC曲线?什么时候使用?⭐️
- 12.什么是AUC(AU ROC)?什么时候使用?⭐️
- 13.如何解释AU ROC分数?⭐️
- 14.在哪种情况下AU PR比AU ROC好?⭐️
- 15.如何处理分类变量?⭐️
- 16.为什么需要one-hot编码?⭐️
- 四、正则化
- 4.1 如果的数据中包含三列:x,y,z,其中z是x、y的和,那么线性回归模型会怎样?⭐️
- 4.2 如果数据中的z列是x和y列之和加上一些随机噪声,那么的线性回归模型会怎样?⭐️
- 4.3 什么是正则化?为什么需要它?👶
- 4.4 有哪些正则化技术?⭐️
- 4.5 什么样的正则化技术适用于线性模型?⭐️
- 4.6 L2正则化在线性模型中是什么样的?⭐️
- 4.7 如何选择正确的正则化参数?👶
- 4.8 L2正则化对线性模型的权重有什么影响?⭐️
- 4.9 L1正则化在线性模型中是什么样的?⭐️
- 4.10 L2和L1正则化有什么区别?⭐️
- 4.11 可以在线性模型中同时具有L1和L2正则化吗?⭐️
- 4.12 如何解释线性模型中的常数项?⭐️
- 4.13 如何解释线性模型中的权重?⭐️
- 4.14 如果一个变量的权重高于另一个变量的权重,那么可以说这个变量更重要吗?⭐️
- 4.1 什么时候需要对线性模型进行特征归一化?什么情况下可以不做归一化?⭐️
- 五、特征选择
- 1. 什么是特征选择?有啥用?👶
- 2. 特征选择对线性模型重要吗?⭐️
- 3. 有哪些特征选择技术?⭐️
- 4. 可以使用L1正则化进行特征选择吗?⭐️
- 5. 可以使用L2正则化进行特征选择吗?⭐️
- 六、决策树
- 6.1 什么是决策树?👶
- 6.2 如何训练决策树?⭐️
- 6.3 决策树模型的主要参数是什么?👶
- 6.4 如何处理决策树中的分类变量?⭐️
- 6.5 与更复杂的模型相比,单个决策树有什么好处?⭐️
- 6.6 如何知道哪些特征对决策树模型更重要?⭐️
- 七、随机森林
- 1.什么是随机森林?👶
- 2.为什么需要在随机森林中进行随机化?⭐️
- 3.随机森林模型的主要参数是什么?⭐️
- (1)RF框架的参数
- (2)RF决策树的参数
- 4.如何选择随机森林中树的深度?⭐️
- 5.如何知道随机森林需要多少棵树?⭐️
- 6.随机森林的训练并行化容易?该怎么做?⭐️
- 7.随机森林中过多的树有什么潜在问题?⭐️
- 八、梯度提升
- 1. 什么是梯度增强树?⭐️
- 2. 随机森林和梯度提升之间有什么区别?⭐️
- 3. 是否可以并行化梯度提升模型的训练?怎么做?⭐️
- 4. 梯度增强树中的特征重要性-有哪些可能的选择?⭐️
- 5. 梯度提升模型的特征重要性,连续变量和离散变量之间是否有区别?🚀
- 6. 梯度提升模型中的主要参数是什么?⭐️
- 7.如何在XGBoost或LightGBM中调整参数?🚀
- 8. 如何在梯度提升模型中选择树的数量?⭐️
- 9. XGBoost和GBDT树有何异同?🚀
- 九、参数调整
- 1. 大致了解哪些参数调整策略?⭐️
- 2. 网格搜索参数调整策略和随机搜索的区别?如何选择?⭐️
- 第二部分:深度学习基础
- 一、神经网络基础
- 1.神经网络可以解决哪些问题?👶
- 2.通常的全连接前馈神经网络如何工作?⭐️
- 3.为什么需要激活功能?👶
- 4.sigmoid 为激活函数有什么问题?⭐️
- 5.什么是ReLU?它比sigmoid 或tanh好吗?⭐️
- 6.如何初始化神经网络的权重?⭐️
- 7.如果将神经网络的所有权重都设置为0会怎样?⭐️
- 8.神经网络中有哪些正则化技术?⭐️
- 9.什么是1.1Dropout?为什么有用?它是如何工作的?⭐️
- 二、神经网络的优化
- 1.什么是反向传播?它是如何工作的?为什么需要它?⭐️
- 2.你知道哪些训练神经网络的优化技术?⭐️
- 3.如何使用SGD(随机梯度下降)训练神经网络?⭐️
- 4.学习率是多少?👶
- 5.学习率太大时会发生什么?太小?👶
- 6.如何设置学习率?⭐️
- 7.什么是Adam?Adam和SGD之间的主要区别是什么?⭐️
- 8.什么时候使用Adam和SGD?⭐️
- 9.要保持学习率不变还是在训练过程中改变它?⭐️
- 10.如何确定何时停止训练神经网络?👶
- 11.什么是ModelCheckpoint?⭐️
- 12.讲一下你是如何进行模型训练的?⭐️
- 第三部分:计算机视觉
- 1.如何使用神经网络进行计算机视觉?⭐️
- (1)传统神经网络结构存在的缺点:
- (2)计算机视觉的四个基本任务
- 2.什么是卷积层?⭐️
- 3.为什么需要卷积?不能使用全连接层吗?⭐️
- 4.CNN中的pooling是什么?为什么需要它?⭐️
- 5.Max pooling如何工作?还有其他池化技术吗?⭐️
- 6.CNN是否抗旋转?如果旋转图像,CNN的预测会怎样?🚀
- 7.什么是数据增强?为什么需要它们?你知道哪种增强?👶
- 8.如何选择要使用的增强?⭐️
- 9.你知道什么样的CNN分类体系?🚀
- 10.什么是迁移学习?它是如何工作的?⭐️
- 11.什么是目标检测?你知道有哪些框架吗?🚀
- 12.什么是对象分割?你知道有哪些框架吗?🚀
- 第四部分:自然语言处理
- 一、学习方法and入门须知:
- 二、文本分类
- 1.如何使用机器学习进行文本分类?⭐️
- 2.什么是词袋模型?如何将其用于文本分类?⭐️
- 3.词袋模型的优缺点是什么?⭐️
- 4.什么是N-gram?如何使用它们?⭐️
- 5.使用N-gram时,词袋模型中N应该是多少?⭐️
- 6.什么是TF-IDF?它对文本分类有什么用?⭐️
- 7.你用过哪种模型对带有词袋特征的文本进行分类?⭐️
- 8.使用词袋进行文本分类时,你希望使用梯度提升树模型还是逻辑回归?⭐️
- 9.什么是词嵌入?为什么有用?你知道Word2Vec吗?⭐️
- 10.还知道其他词嵌入的方法吗?🚀
- 11. 如果你的句子包含多个单词,则可能需要将多个单词嵌入组合为一个。你会怎么做?⭐️
- 12.在进行带有嵌入的文本分类时,使用梯度提升树模型还是逻辑回归?⭐️
- 13.如何使用神经网络进行文本分类,用CNN呢?🚀
- 14.bpe是什么,word piece是什么,sub word是什么👶
- 三、循环神经网络
- 1.RNN和CNN各自特点?⭐️
- 2.RNN能否使用ReLU作为激活函数?⭐️
- 3.Seq2Seq在解码时的常用方法?⭐️
- 4.长程依赖问题是什么👶
- 四、Transformer机制
- 0.Seq2Seq模型引入注意力机制是为了解决啥问题?👶
- 1.为什么Transformer中加入了positional embedding?⭐️
- 2.Transformer中的残差网络结构(residual connecttion)作用是什么?⭐️
- 3.Transformer中的softmax计算为什么需要除以 d k d_k dk?⭐️
- 4.==为什么 `num_heads` 的值需要能够被 `embed_dim` 整除==?⭐️
- 5.Transformer中attention score计算时候如何mask掉padding位置?🚀
- 6.为什么GPT要比transformer在对话系统上表现好🚀
- 五、Bert预训练模型
- 1.word2vec到BERT改进了什么?👶
- 2.BERT预训练是如何做mask的?BERT预训练时mask的比例,可以mask更大的比例(大于80%)吗🚀
- 3.BERT如何进行tokenize操作?有什么好处?⭐️
- 4.BERT模型特别大,单张GPU训练仅仅只能放入1个batch的时候,怎么训练?🚀
- 5.为什么会先提起Bert?⭐️
- 6.GPT如何进行tokenize操作?和BERT的区别是什么?⭐️
- 六、预训练代码实践
- 1. B E R T BERT BERT 训练时候的学习率 l e a r n i n g learning learning r a t e rate rate如何设置? B E R T BERT BERT 中的`warmup`作用是什么?
- 2.如何理解BERT模型输入的`type ids`?
- 3.BERT模型使用哪种分词方式?WordPiece分词的好处是什么?
- 4.Hugginface代码中的BasicTokenizer作用是?⭐️
- 第五部分:无监督学习
- 一、聚类
- 二、降维
- 1. 维度灾难是什么?为什么要关心它?⭐️
- 2. 知道降维技巧吗?⭐️
- 3. 什么是奇异值分解?它通常如何用于机器学习?⭐️
- 三、排序和搜索
- 如何使用梯度提升树GBDT进行排序?🚀
- 如何在线评估新的排序算法?⭐️
- 第六部分:推荐系统
- 1. 什么是推荐系统?👶
- 2. 建立推荐系统时有什么好的 baseline?⭐️
- 3. 什么是协同过滤?⭐️
- 4. 如何将隐式反馈(点击等)纳入推荐系统?⭐️
- 5. 什么是冷启动问题?⭐️
- 6. 解决冷启动问题的可能方法?🚀
- 7.常见的推荐算法有哪些?
- 8.介绍 FM 和 DeepFM
- 9.介绍一下协同过滤的冷启动和原因
- 10.基于内容的推荐算法优缺点
- 11.你了解的 CTR 预估模型有哪些?
- 12.推荐里面的低秩矩阵分解具体是怎么做的?
- 13.常见的推荐算法面试问题
- 第七部分:时间序列
- 1.什么是时间序列?👶
- 2.时间序列与通常的回归问题有何不同?👶
- 3.用于解决时间序列问题的有哪些模型?⭐️
- 4.如果序列中有趋势,如何消除它?为什么要这么做?⭐️
- 5.在时间t处测得只有一个变量“y”的序列。如何在时间t + 1预测“y”?使用哪种方法?⭐️
- 6.有一个带有变量“y”和一系列特征的序列。如何预测t + 1时的“y”?使用哪种方法?⭐️
- 7.使用树来解决时间序列问题有什么问题?⭐️
- 第八部分:强化学习
- 1.学习资料
- 2.代码层面:
- 3.理论层面
- 4.成果验收
- 5.附录
- 第九部分:其他
- 1.分布式机器学习框架
- reference
一开始先丢个AI类电子书pdf的链接: https://github.com/Kensuke-Hinata/statistic/tree/master/AI/books

一。机器学习
一个大佬写的强化学习文章https://arxiv.org/pdf/1810.06339.pdf,其中有这么一幅图:

ML的基础理论(理解霍夫丁不等式)
使用ML模型(sklearn可调包)
某大佬说真正难的是在实践中采用相应的策略,吴恩达在《Machine Learning Yearning》中写道:
(1)建完模型后效果不好咋办——用正交策略(每次只改变模型的某一个性能的策略)
(2)在项目前如何设定有效目标——选单值指标
(3)如何有效识别模型误差来源——看偏差和方差
啥时候使用深度学习:
(1)简单的模型(如逻辑回归)无法达到用例所需要的准确度
(2)在图像、NLP或者音频处理中有复杂的模式匹配
(3)有高维数据
(4)在向量中有时间维度(序列)
啥时候坚持传统的机器学习
(1)有高质量、低维度的数据,如从数据库导出的列式数据
(2)无须在图像数据中找到复杂的模式
当数据不完整或者质量差时,深度学习和传统机器学习得到的结果都很差。
0.学习路线与方法
(1)梯度下降总结
(2)计算图的基础——Olah的博客:http://colah.github.io/posts/2015-08-Backprop/
(3)学习路线:
阿里云-天池挺多free资源和课程:https://tianchi.aliyun.com/course?spm=5176.12281920.J_3941670930.4.5cff3f74oaWqWM
到底如何学深度学习 | 学深度学习是不是需要先学机器学习?(下文引自知乎)
1.学深度学习是不是需要先学机器学习?

人工智能>机器学习>深度学习。
这样容易让人误认为人工智能的核心是机器学习,而机器学习的核心则是深度学习。
深度学习出道前叫【神经网络】,2012年的ImageNet赛场图像识别,神经网络出大招——AlexNet模型。CNN,深度卷积网络
CNN作为一种框架,不止AlexNet模型,但可以认为CNN是靠AlexNet模型一夜成名。
AlexNet模型效果很好只是起点。它开创了一个伟大的新时代,开挂技术——GPU。
AlexNet模型像是一个伟大的先知,它的成功引领机器学习走上了一条未曾设想的道路:更深的神经网络,更多的GPU,就有更好的效果——这就是深度学习。深度学习的快速崛起,和硬件技术的发展是息息相关的。不是前人太蠢,在这么长的时间里都没有想到通过加深神经网络来取得更好的效果,而是深度一旦上去了,算力就立马跪下去了——这是时代的局限性。
而随着GPU的加入,算力不再是瓶颈,深度学习也就真的成了那句话所说的:“你们有幸,遇见这样的时代,但时代更有幸,遇见这样的你们”。从此,机器学习也就从烧脑的玩意,变成了烧钱的玩意。
2.深度学习难学吗?
学深度学习,该不该先学机器学习呢?
本文不是专讲机器学习的文章,这里简要分析一下机器学习到底要学什么。
三样东西,问题,方法和流程。
1.问题
机器学习要解决的问题,主要分为有监督学习和无监督学习两个大类,目前有监督学习是研究和应用的热门方向,但无监督学习也一直在“怒刷”存在感,最近搞了个混血的半监督学习,说这才是未来的发展方向。
而这两个大类下面又有子问题,比如有监督学习下面有“回归问题”和“分类问题”,都是十分贴近工业应用需要的问题。在这一点上,机器学习也好,深度学习也好,研究的问题都是相通的,深度学习并没有为了证明自己已经到了叛逆期非要另搞一套问题。正因如此,机器学习模型和深度学习模型才能同台竞技。
2.方法
对于同样的分类问题,神经网络、决策树和支持向量机就给出了三种不同的解题思路,如果你只打算了解深度学习,那在方法这一步,可以选择重点了解神经网络的解题思路。
3.流程
机器学习不只有各种理论和模型,要在实际工作中使用,还需要学习工作流程:包括数据收集、数据清洗、特征工程、模型选择、参数调优等等……这和软件开发有一套长长的生命周期,而不是只有敲代码是一样的。
在机器学习的这套流程里面,特征工程一般公认是十分重要的一环,特征选取的好坏,能不能提取得到重要特征,可能会对模型最终的效果产生显著影响。但在这一点上,深度学习不太一样。
深度学习经常有一种提法,叫端到端学习。什么意思呢?
就是把原始的数据不经过特征工程处理,直接就喂给模型,然后就能吐出想要的结果。让模型自己提取特征,没有了特征工程作为中间商赚差价,叫端到端学习。这是深度学习很重要的一个卖点。
3.深度学习该怎么学
深度学习相对好学
最好的办法,首先建立对深度学习的基本概念,然后再重头读
深度学习也是有一个主角的,这个主角是谁呢?是权重(weight)。
整个深度学习的知识体系,都是围绕着权重从方方面面做文章。
譬如说BP,神经网络和深度学习有一个灵魂级的重要知识点,叫后向传播机制,简称BP。
BP是干什么的呢,就是更新权重。
- 怎么更新呢——梯度下降。
- 收敛太慢了怎办呢——随机梯度下降。
- 梯度弥散了怎办呢——更换激活函数,或者残差连接。
- 过拟合了呢——要么L1-norm要么L2-norm,要么干脆dropout,一了百了。
总之,玩法很多,但对象只有一个,那就是权重。
看到这里,是不是已经跃跃欲试,想知道应该找哪本深度学习的教材上手呢?不过,前面说深度学习现在还在全力飙车,这就会给深度学习的教材带来一些坑。
譬如说花书。花书很经典,全明星阵容,可惜是2016年出的,在2017年掀起风潮的各种GAN、在2018年掀起风潮的Self-Attention,在2019年掀起风潮的GNN,花书都不可能找得到相关内容。花书出得实在太早,就算是GAN之父亲自写的花书,GAN在书里面也只有很小的篇幅,很多在GAN的发展历程上起了里程碑作用的模块也没来得及收录,哪怕你只是想全面地了解GAN,花书也有心无力。
复旦大学邱锡鹏老师新出的《神经网络与深度学习》(b站有个学生有讲的,不知道咋样)
本课程主要介绍神经网络与深度学习中的基础知识、主要模型(卷积神经网络、递归神经网络等)以及在计算机视觉、自然语言处理等领域的应用。
要获取更新提醒,请关注https://github.com/nndl/nndl.github.io
示例代码,见https://github.com/nndl/nndl-codes
课程练习,见https://github.com/nndl/exercise
4.推荐课程
(1)Stat212b:Topics Course on Deep Learning
http://joanbruna.github.io/stat212b/
加州大学伯克利分校统计系Joan Bruna(Yann LeCun博士后) 以统计的角度讲解DL。
(2)CS224d: Deep Learning for Natural Language Processing
http://cs224d.stanford.edu/
斯坦福大学 Richard Socher 主要讲解自然语言处理领域的各种深度学习模型
(3)CS231n:Convolutional Neural Networks for Visual Recognition
http://cs231n.stanford.edu/
斯坦福大学 Fei-Fei Li Andrej Karpathy 主要讲解CNN、RNN在图像领域的应用
二。机器学习and深度学习面试题
数据科学职位的典型面试过程会有很多轮,其中通常会涉及理论概念,目的是确定应聘者是否了解机器学习的基础知识。
其中包括以下主题:
- 线性回归
- 模型验证
- 分类和逻辑回归
- 正则化
- 决策树
- 随机森林
- GBDT
- 神经网络
- 文本分类
- 聚类
- 排序:搜索和推荐
- 时间序列
这篇文章中的问题数量似乎远远不够,面试流程是根据公司的需求和你的工作经历而定的。因此,如果你的工作中没有用过时间序列模型或计算机视觉模型,就不会收到类似的问题。
根据难度将问题分为三类:
👶容易;⭐️中号;🚀专家
PS:机器学习的很多场景中,将建模对象向量化是建模过程中最核心的一步,比如对于图像处理,用spectral embedding来表示图片中的像素点能较好地表示像素点的图像特征;又如NLP中以前用的潜在语义分解来处理文本能较好地用向量表达文字的意思。
第一部分:监督学习
(1)什么是有监督学习?👶
答:监督学习是利用一组带标签的护具,学习从输入到输出的映射,然后将这种映射关系应用到未知数据上,达到分类或者回归的目的。

顺便来看下李宏毅机器学习第一节课的截图:

- 机器学习含有回归和分类,也包括structured learning(这里面有很多问题还在探究)
- 没有data做监督学习时我们才用reinforcement learning。ex:阿法狗就是用棋谱做监督学习(有label),然后用强化学习(需要一个对手,也是机器)。
PS:增强学习是做完给个分数(判断好坏) - 蓝色是学习的情景,红色是task(有分类、回归、structured),绿色为方法。
- 迁移学习是数据中有的有label是有用的,有的是不相关的label,那有不相关label的数据的作用是迁移学习要讲的。
- 半监督学习指很多情况没有label(output难获得,需要人工标注)的数据很多,减少label需要的量是半监督学习研究的。
一、线性回归
1.什么是回归?哪些模型可用于解决回归问题?👶
回归是19世纪80年代英国统计学家高尔顿为了研究父子身高关系提出的,最初的统计学含义如子代的身高有向族群平均身高“平均”的趋势。
回归分析:用于研究因变量(目标)和自变量(特征)之间的关系,即预测分析,时间序列模型以及发现变量之间的因果关系。
回归的原理:通常用曲线拟合数据点,目标是使数据点的距离差距最小。
可用于解决回归问题的模型:
- 线性回归的推广:
多项式回归(字面意思);
广义可加模型GAM:将线性模型推广至非线性模型的一个框架——每个变量都用一个非线性函数来代替,但是模型本身保持整体可加性。 - 回归树:根据分层和分割的方式将特征空间划分为一系列简单的区域(划分特征空间的分裂规则可以用树的形式进行概括)。
- 支持向量机回归SVR:
2.什么是线性回归?什么时候使用它?👶
- 线性回归模型:线性回归假设目标值与特征之间线性相关,即满足一个多元一次方程,构建损失函数后,求解损失函数最小时的参数w。
3.什么是正态分布?为什么要重视它?👶
4.如何检查变量是否遵循正态分布?⭐️
5.如何建立价格预测模型?价格是否正态分布?需要对价格进行预处理吗?⭐️
6.解决线性回归的模型有哪些?⭐️
7.什么是梯度下降?它是如何工作的?⭐️
8.什么是正规方程?⭐️
9.什么是SGD-随机梯度下降?与通常的梯度下降有何不同?⭐️
10.有哪些评估回归模型的指标?👶
- MSE均方误差: MSE ( y , y ^ ) = 1 n samples ∑ i = 0 n samples − 1 ( y i − y ^ i ) 2 . \text{MSE}(y, \hat{y}) = \dfrac{1}{n_\text{samples}} \sum_{i=0}^{n_\text{samples} - 1} (y_i - \hat{y}_i)^2. MSE(y,y^)=nsamples1∑i=0nsamples−1(yi−y^i)2.,还有RMSE就是在MSE基础上加个根号(Root)
- MAE平均绝对误差: MAE ( y , y ^ ) = 1 n samples ∑ i = 0 n samples − 1 ∣ y i − y ^ i ∣ \text{MAE}(y, \hat{y}) = \dfrac{1}{n_{\text{samples}}} \sum_{i=0}^{n_{\text{samples}}-1} \left| y_i - \hat{y}_i \right| MAE(y,y^)=nsamples1∑i=0nsamples−1∣yi−y^i∣
- R 2 R^2 R2决定系数: R 2 ( y , y ^ ) = 1 − ∑ i = 1 n ( y i − y ^ i ) 2 ∑ i = 1 n ( y i − y ˉ ) 2 R^2(y, \hat{y}) = 1 - \dfrac{\sum_{i=1}^{n} (y_i - \hat{y}_i)^2}{\sum_{i=1}^{n} (y_i - \bar{y})^2} R2(y,y^)=1−∑i=1n(yi−yˉ)2∑i=1n(yi−y^i)2
- 解释方差得分: e x p l a i n e d _ v a r i a n c e ( y , y ^ ) = 1 − V a r { y − y ^ } V a r { y } explained\_{}variance(y, \hat{y}) = 1 - \dfrac{Var\{ y - \hat{y}\}}{Var\{y\}} explained_variance(y,y^)=1−Var{y}Var{y−y^}
https://scikit-learn.org/stable/modules/model_evaluation.html#regression-metrics

————————————————————————————————
二、验证方式
1.什么是过拟合?👶
模型在训练数据集中表现好,而在测试数据集中表现差。
2.如何验证模型?👶
3.为什么需要将数据分为三个部分:训练,验证和测试?👶
4.解释交叉验证的工作原理?👶
如果要对测试误差进行估计,有训练误差修正和交叉验证两种方式。前者是通过训练误差的桥梁的一种间接方式;而交叉验证是对测试误差的直接估计。
5.什么是K折交叉验证?👶
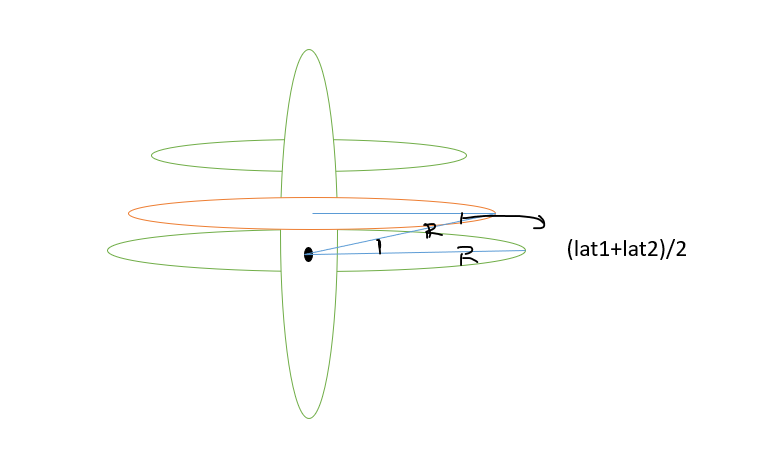
K折交叉验证:我们把训练样本分成K等分,然后用K-1个样本集当做训练集,剩下的一份样本集为验证集去估计由K-1个样本集得到的模型的精度,这个过程重复K次取平均值得到测试误差的一个估计 C V ( K ) = 1 K ∑ i = 1 K M S E i CV_{(K)} = \frac{1}{K}\sum\limits_{i=1}^{K}MSE_i CV(K)=K1i=1∑KMSEi。5折交叉验证如下图:(蓝色的是训练集,黄色的是验证集)

6.如何在K折交叉验证中选择K?你最喜欢的K是什么?👶
——————————————————————————————
三、分类
1.什么是分类?哪些模型可以解决分类问题?👶
-
回归问题与分类问题需要预测的因变量不一样。在回归问题中,因变量是连续性变量,我们需要预测 E ( Y ∣ X ) E(Y|X) E(Y∣X)是一个连续的实数,但是在分类问题中,我们往往是通过已知X的信息预测Y的类别,往往是一个离散集合中的某个元素。如:是否患癌症,图片是猫还是狗等。
-
分类模型:如逻辑回归、基于概率的分类模型(分为线性判别分析和朴素贝叶斯)、决策树和SVM等算法。首先逻辑回归是在线性回归基础上加多logistic函数后将结果转为概率值; 为了解决多分类问题,我们又提出了线性判别分析和朴素贝叶斯,其中前者可以从贝叶斯或者降维分类的角度理解;
2.什么是逻辑回归?什么时候需要使用它?👶
回归的因变量是连续性变量,分类的因变量是离散集合中的某个元素,自然想到用线性回归去处理分类问题,但是会有问题:
(1)因变量可能出现负数(不现实)
(2)处理多分类问题
3.Logistic回归是线性模型吗?为什么?👶
是线性模型。
线性分类模型一般是一个广义线性函数,即一个或多个【线性判别函数】加上一个【非线性激活函数】,所谓“线性”是指决策边界由一个多个超平面组成。
4.什么是Sigmoid?它有什么作用?👶
通过引入S型的对数几率函数 y = 1 1 + e − z y=\dfrac{1}{1+e^{-z}} y=1+e−z1该激活函数作用是因此引入非线性,则有多种选择。

Sigmoid优点:输出范围有限,所以数据在传递过程中不易发散;还有容易求导。
Sigmoid缺点:梯度下降非常明显,且两头过于平坦,容易出现梯度消失的情况,输出的至于不对称(并非像tanh函数那样是-1~1)
5.如何评估分类模型?👶
可以先从推荐算法的角度直观看图说话:Precision@K和Recall@K的分子都相同(推荐了且用户有交互的item数),但是Precision@K的分母是所有推荐的item数。

度量分类模型的指标和回归的指标有很大的差异:
(1)因为分类问题本身的因变量是离散变量,因此像定义回归的指标那样,单单衡量预测值和因变量的相似度可能行不通。
(2)在分类任务中,对于每个类别犯错的代价不尽相同,例如:我们将癌症患者错误预测为无癌症和无癌症患者错误预测为癌症患者,在医院和个人的代价都是不同的,前者会使得患者无法得到及时的救治而耽搁了最佳治疗时间甚至付出生命的代价,而后者只需要在后续的治疗过程中继续取证就好了,因此我们很不希望出现前者,当发生了前者错误则认为建立的模型是很差的。
为了解决这些问题,我们必须将各种情况分开讨论,然后给出评价指标。
PS:下面涉及英文缩写,第一个字母T和F代表True和False;第二个字母P和N代表阴性(Positive)和阳性(Negative),即预测结果。
- 真阳性TP:预测值和真实值都为正例;
- 真阴性TN:预测值与真实值都为正例;
- 假阳性FP:实际值为负,但预测值为正;
- 假阴性FN:实际值为正,但预测值为负;

TP反应预测为真的样本也是正样本的样本数。
| 真实类别-> | 正样本 | 负样本 |
|---|---|---|
| 预测为真 | 真阳性TP | 假阳性FP |
| 预测为假 | 假阴性FN | 真阴性TN |
| 分类模型(二分类)的指标: |
- 准确率:分类正确的样本数占总样本的比例,即: A C C = T P + T N F P + F N + T P + T N ACC = \dfrac{TP+TN}{FP+FN+TP+TN} ACC=FP+FN+TP+TNTP+TN.
- 精度:预测为正且分类正确的样本占预测值为正的比例,即: P R E = T P T P + F P PRE = \dfrac{TP}{TP+FP} PRE=TP+FPTP.
- 召回率:预测为正且分类正确的样本占类别为正的比例,即: R E C = T P T P + F N REC = \dfrac{TP}{TP+FN} REC=TP+FNTP.
- F1值:综合衡量精度和召回率,即: F 1 = 2 P R E × R E C P R E + R E C F1 = 2\dfrac{PRE\times REC}{PRE + REC} F1=2PRE+RECPRE×REC.
- ROC曲线:以假阳率为横轴,真阳率为纵轴画出来的曲线,曲线下方面积越大越好。
sklearn相关工具包:

6.什么是准确率?👶
准确率:分类正确的样本数占总样本的比例,即: A C C = T P + T N F P + F N + T P + T N ACC = \frac{TP+TN}{FP+FN+TP+TN} ACC=FP+FN+TP+TNTP+TN
7.准确率始终是一个好的指标吗?👶
8.什么是混淆表?表中的单元格表示什么?👶
参考第五点的矩阵。
9.什么是精度,召回率和F1分数?👶
精确率:你认为的该类样本,有多少猜对了(猜对的概率)
召回率:该类样本有多少被找了回来
(1)精确率(precision,P值)
是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP),也就是
P = T P T P + F P P=\frac{T P}{T P+F P} P=TP+FPTP
(2)召回率(Recall,R值)
是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN):
R = T P T P + F N R=\frac{T P}{T P+F N} R=TP+FNTP
(3)栗子
有60个正样本,40个负样本,我们要找出所有的正样本,系统查找出50个,其中只有40个是真正的正样本,计算上述各指标。
- TP: 将正类预测为正类数 40
- FN: 将正类预测为负类数 20
- FP: 将负类预测为正类数 10
- TN: 将负类预测为负类数 30
准确率(accuracy) = 预测对的/所有 = (TP+TN)/(TP+FN+FP+TN) = 70%
精确率(precision) = TP/(TP+FP) = 80%
召回率(recall) = TP/(TP+FN) = 2/3
10.准确率和召回率的权衡⭐️
F1值:P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure,通过计算F值来评价一个指标!
F1-score 的值越高,就证明模型在精确率和召回率的整体表现上越好。
F 1 = 2 ⋅ precision ⋅ recall precision + recall \mathrm{F} 1=\frac{2 \cdot \text { precision } \cdot \text { recall }}{\text { precision }+\text { recall }} F1= precision + recall 2⋅ precision ⋅ recall
11.什么是ROC曲线?什么时候使用?⭐️
https://www.zhihu.com/question/39840928/answer/241440370
12.什么是AUC(AU ROC)?什么时候使用?⭐️
P-R 曲线,这里的 P 就是精确率 Precision,R 就是召回率 Recall。为了综合评价一个推荐模型的好坏,不仅要看模型在一个 Top n 值下的精确率和召回率,还要看到模型在不同 N 取值下的表现,甚至最好能绘制出一条 n 从 1 到 N,准确率和召回率变化的曲线。这条曲线就是 P-R 曲线。
P-R 曲线的横轴是召回率,纵轴是精确率。
对于一个推荐模型来说,它的 P-R 曲线上的一个点代表“在某一阈值下,模型将大于该阈值的结果判定为正样本,将小于该阈值的结果判定为负样本时,整体结果对应的召回率和精确率”。整条 P-R 曲线是通过从高到低移动正样本阈值生成的。如图 1 所示,它画了两个测试模型,模型 A 和模型 B 的对比曲线。其中,实线代表模型 A 的 P-R 曲线,虚线代表模型 B 的 P-R 曲线。

从图中我们可以看到,在召回率接近 0 时,模型 A 的精确率是 0.9,模型 B 的精确率是 1。这说明模型 B 预测的得分前几位的样本全部是真正的正样本,而模型 A 即使是得分最高的几个样本也存在预测错误的情况。
曲线分析:
随着召回率的增加,两个模型的精确率整体上都有所下降。特别是当召回率在 0.6 附近时,模型 A 的精确率反而超过了模型 B。这就充分说明了,只用一个点的精确率和召回率是不能全面衡量模型性能的,只有通过 P-R 曲线的整体表现,才能对模型进行更全面的评估。
AUC (Area Under Curve):AUC用于衡量P-R曲线的优劣。指的是 P-R 曲线下的面积大小,因此计算 AUC 值只需要沿着 P-R 曲线横轴做积分。AUC 越大,就证明推荐模型的性能越好。
13.如何解释AU ROC分数?⭐️
14.在哪种情况下AU PR比AU ROC好?⭐️
15.如何处理分类变量?⭐️
16.为什么需要one-hot编码?⭐️
————————————————————————————
四、正则化
4.1 如果的数据中包含三列:x,y,z,其中z是x、y的和,那么线性回归模型会怎样?⭐️
4.2 如果数据中的z列是x和y列之和加上一些随机噪声,那么的线性回归模型会怎样?⭐️
4.3 什么是正则化?为什么需要它?👶
4.4 有哪些正则化技术?⭐️
正则化regularization
- Lasso回归:加入L惩罚项(|a|+|b|+|c|)即参数(a,b,c)的L1-norm(L1范数)
- ridge回归(即岭回归):加入惩罚项(a^2 + b^2 +c^2)即参数(a,b,c)的L2-norm(L2范数)。ridge约束更强(所以不容易过拟合)。直观上看,系数尽量小(即每个特征对输出的影响应尽可能小)
4.5 什么样的正则化技术适用于线性模型?⭐️
4.6 L2正则化在线性模型中是什么样的?⭐️
4.7 如何选择正确的正则化参数?👶
4.8 L2正则化对线性模型的权重有什么影响?⭐️
4.9 L1正则化在线性模型中是什么样的?⭐️
4.10 L2和L1正则化有什么区别?⭐️
4.11 可以在线性模型中同时具有L1和L2正则化吗?⭐️
4.12 如何解释线性模型中的常数项?⭐️
4.13 如何解释线性模型中的权重?⭐️
4.14 如果一个变量的权重高于另一个变量的权重,那么可以说这个变量更重要吗?⭐️
4.1 什么时候需要对线性模型进行特征归一化?什么情况下可以不做归一化?⭐️
五、特征选择
1. 什么是特征选择?有啥用?👶
2. 特征选择对线性模型重要吗?⭐️
3. 有哪些特征选择技术?⭐️
为了选择一个测试误差达到最小的模型,我们可以通过训练误差修正或者交叉验证对测试误差进行估计,之后我们做特征选择的目标是:从p个特征中选择m个特征,使得对应的模型的测试误差的估计最小。
特征选择的方法有:
(1)最优子集选择;
(2)向前逐步选择。
4. 可以使用L1正则化进行特征选择吗?⭐️
5. 可以使用L2正则化进行特征选择吗?⭐️
六、决策树
6.1 什么是决策树?👶
目标:从一组样本数据中,根据不同的特征和属性,建立一棵树形的分类结构。既希望该树能够拟合训练数据(达到良好的分类效果),也希望控制其复杂度(具有一定泛化能力)。
决策树的生成的三个过程:
(1)特征选择;(2)树的构造;(3)树的剪枝。
决策树常用于分类,目标就是将具有 P P P 维特征的 n n n 个样本分到 C C C 个类别中,相当于做一个映射 C = f ( n ) C = f(n) C=f(n) ,将样本经过一种变换赋予一个 l a b e l label label。可以把分类的过程表示成一棵树,每次通过选择一个特征 p i pi pi 来进行进一步分叉。而根据每次分叉选择哪个特征对样本进行划分,能够又快又准地对样本进行分类,即根据不同的特征选择方案,我们分为了:ID3、C4.5、CART等算法。
| ID3树 | C4.5树 | CART算法 | |
|---|---|---|---|
| 评价标准 | 信息增益 | 信息增益比 | 基尼指数 |
| 样本类型 | 离散型变量 | 连续型变量 | 连续型变量 |
| 任务 | 分类 | 分类 | 分类and回归(回归树使用最小平方误差) |
6.2 如何训练决策树?⭐️
6.3 决策树模型的主要参数是什么?👶
(1)sklearn的sklearn.tree.DecisionTreeClassifier的参数min_impurity_decrease用来描述父节点的不纯度 - 子节点的不纯度:

(2)在sklearn中提供了两种生长模式,它们分别被称为深度优先生长和最佳增益生长,当参数max_leaf_nodes使用默认值None时使用前者,当它被赋予某个数值时使用后者。如果使用max_left_nodes则一定会使用最佳优先生长,但当参数max_leaf_nodes使用默认值None时为深度优先生长。
(3)预剪枝中:
在sklearn的CART实现中,一共有6个控制预剪枝策略的参数,它们分别:
(1)最大树深度max_depth
(2)节点分裂的最小样本数min_samples_split
(3)叶节点最小样本数min_samples_leaf
(4)节点样本权重和与所有样本权重和之比的最小比例min_weight_fraction_leaf(公式繁琐,此处不讲)
(5)最大叶节点总数max_leaf_nodes
(6)分裂阈值min_impurity_decrease。
PS:更多参数可以参考官网。
6.4 如何处理决策树中的分类变量?⭐️
6.5 与更复杂的模型相比,单个决策树有什么好处?⭐️
优点:
(1)速度快: 计算量相对较小, 且容易转化成分类规则. 只要沿着树根向下一直走到叶, 沿途的分裂条件就能够唯一确定一条分类的谓词.
(2)准确性高: 挖掘出来的分类规则准确性高, 便于理解, 决策树可以清晰的显示哪些字段比较重要, 即可以生成可以理解的规则.
(3)可以处理连续和种类字段
(4)不需要任何领域知识和参数假设
(5)适合高维数据
缺点:
(1)对于各类别样本数量不一致的数据, 信息增益偏向于那些更多数值的特征
(2)容易过拟合
(3)忽略属性之间的相关性
6.6 如何知道哪些特征对决策树模型更重要?⭐️
决策树学习的算法通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得各个子数据集有一个最好的分类的过程。
以下是不同决策树算法的属性选择的度量(评价标准):
| ID3树 | C4.5树 | CART算法 | |
|---|---|---|---|
| 评价标准 | 信息增益 | 信息增益比 | 基尼指数 |
| 样本类型 | 离散型变量 | 连续型变量 | 连续型变量 |
| 任务 | 分类 | 分类 | 分类and回归(回归树使用最小平方误差) |
七、随机森林
1.什么是随机森林?👶
Bagging是一种并行集成方法(各基分类器之间无强依赖,可以并行训练),其全称是 b o o t s t r a p ag g r e g a t ing \rm{\textbf{b}ootstrap\,\textbf{ag}gregat\textbf{ing}} bootstrapaggregating,即基于bootstrap抽样的聚合算法。随机森林算法就是一种基于bagging的模型,在最终决策时,每个个体单独做出判断后再进行投票作集体决策。
bagging的好处是集成后的分类器的方差,比基分类器的方差小。Bagging所采用的的基分类器,最好是本身对样本分布较为敏感(即不稳定),所以用决策树作为基分类器,而不使用线性分类器或者K-近邻(它们是较为稳定的分类器,以它们作为基分类器使用Bagging甚至可能因为Bagging的采样,导致在训练中更难收敛,从而增大了集成分类器的偏差)。
2.为什么需要在随机森林中进行随机化?⭐️
随机森林在样本空间、参数空间以及模型空间增加了随机扰动,从而降低了"个例"的影响,提高了泛化能力。
随机森林中的随机主要来自三个方面:
- 其一为bootstrap抽样导致的训练集随机性,
- 其二为每个节点随机选取特征子集进行不纯度计算的随机性,
- 其三为当使用随机分割点选取时产生的随机性(此时的随机森林又被称为Extremely Randomized Trees)。
3.随机森林模型的主要参数是什么?⭐️
(1)RF框架的参数
RF框架的参数:RandomForestClassifier和RandomForestRegressor参数绝大部分相同。
(1)n_estimators(重点): 也就是最大的弱学习器的个数。一般来说n_estimators太小,容易欠拟合,n_estimators太大,计算量会太大,并且n_estimators到一定的数量后,再增大n_estimators获得的模型提升会很小,所以一般选择一个适中的数值。默认是100。
(2)oob_score :即是否采用袋外样本来评估模型的好坏。默认识False。个人推荐设置为True,因为袋外分数反应了一个模型拟合后的泛化能力。
(3)criterion: 即CART树做划分时对特征的评价标准。分类模型和回归模型的损失函数是不一样的。分类RF对应的CART分类树默认是基尼系数gini,另一个可选择的标准是信息增益。回归RF对应的CART回归树默认是均方差mse,另一个可以选择的标准是绝对值差mae。一般来说选择默认的标准就已经很好的。
(2)RF决策树的参数
(1)RF划分时考虑的最大特征数max_features: 可以使用很多种类型的值,默认是"auto",意味着划分时最多考虑 N \sqrt{N} N个特征;一般我们用默认的"auto"就可以了,如果特征数非常多,我们可以灵活使用下面描述的其他取值来控制划分时考虑的最大特征数,以控制决策树的生成时间。
如果是"log2"意味着划分时最多考虑 log 2 N \log _{2} N log2N个特征;
如果是"sqrt"或者"auto"意味着划分时最多考虑 N \sqrt{N} N个特征。
如果是整数,代表考虑的特征绝对数。
如果是浮点数,代表考虑特征百分比,即考虑(百分比xN)取整后的特征数。其中N为样本总特征数。
(2)决策树最大深度max_depth: 默认可以不输入。如果不输入的话,决策树在建立子树的时候不会限制子树的深度。一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间。
(3)内部节点再划分所需最小样本数min_samples_split: 这个值限制了子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分。 默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
(4)叶子节点最少样本数min_samples_leaf: 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
4.如何选择随机森林中树的深度?⭐️
sklearn中RF框架中的决策树最大深度max_depth: 默认可以不输入。如果不输入的话,决策树在建立子树的时候不会限制子树的深度。
一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间。
5.如何知道随机森林需要多少棵树?⭐️
sklearn中的RF框架中的n_estimators参数:也就是最大的弱学习器的个数。一般来说n_estimators太小,容易欠拟合,n_estimators太大,计算量会太大,并且n_estimators到一定的数量后,再增大n_estimators获得的模型提升会很小,所以一般选择一个适中的数值。默认是100。
6.随机森林的训练并行化容易?该怎么做?⭐️
可以使用随机森林或者孤立森林:
(1)随机森林中的随机主要来自三个方面:
- 其一为bootstrap抽样导致的训练集随机性,
- 其二为每个节点随机选取特征子集进行不纯度计算的随机性,
- 其三为当使用随机分割点选取时产生的随机性(此时的随机森林又被称为Extremely Randomized Trees)。
(2)孤立森林算法类比在切蛋糕,点密度稠密的一块需要切很多刀才能分割完,而那些很早能分割完的应该是异常点(我们要把每个点都单独存在一个子空间中)。
孤立森林通过随机选择特征,然后随机选择特征的分割值,递归地生成数据集的分区。和数据集中「正常」的点相比,要隔离的异常值所需的随机分区更少,因此异常值是树中路径更短的点,路径长度是从根节点经过的边数。
7.随机森林中过多的树有什么潜在问题?⭐️
是否可以不找到最佳分割,而是随机选择几个分割,然后从中选择最佳分割?可行吗 🚀
数据中存在相关特征时会怎样?⭐️
八、梯度提升
Andy同学介绍自己实习时候用过XGBoost预测股票涨跌,那面试官可能会由浅入深依次考察下列问题:
- GBDT的原理(知识)
- 决策树节点分裂时是如何选择特征的?(知识)
- 写出Gini Index和Information Gain的公式并举例说明(知识)
- 分类树和回归树的区别是什么?(知识)
- 与Random Forest作比较,并以此介绍什么是模型的Bias和Variance(知识)
- XGBoost的参数调优有哪些经验(工具)
- XGBoost的正则化是如何实现的(工具)
- XGBoost的并行化部分是如何实现的(工具)
- 为什么预测股票涨跌一般都会出现严重的过拟合现象(业务)
- 如果选用一种其他的模型替代XGBoost或者改进XGBoost你会怎么做,为什么?(业务+逻辑+知识)
这是一条由简历出发,由“知识”为切入点,不仅考察了“知识”的深度,而且还考察了“工具”、“业务”、“逻辑”深度的面试路径。
1. 什么是梯度增强树?⭐️
2. 随机森林和梯度提升之间有什么区别?⭐️
- 随机森林RF也是多棵树,但从效果上有实践证明不如GBDT。
- GBDT前面的树,特征分裂主要体现对多数样本有区分度的特征;后面的树,主要体现的是经过前N颗树,残差仍然较大的少数样本。优先选用在整体上有区分度的特征,再选用针对少数样本有区分度的特征,思路更加合理,这应该也是用GBDT的原因。
3. 是否可以并行化梯度提升模型的训练?怎么做?⭐️
4. 梯度增强树中的特征重要性-有哪些可能的选择?⭐️
5. 梯度提升模型的特征重要性,连续变量和离散变量之间是否有区别?🚀
6. 梯度提升模型中的主要参数是什么?⭐️
7.如何在XGBoost或LightGBM中调整参数?🚀
8. 如何在梯度提升模型中选择树的数量?⭐️
9. XGBoost和GBDT树有何异同?🚀
(可从目标损失、近似方法、分裂依据等方面考虑)
(1)GBDT是机器学习算法,XGBoost是该算法的工程实现。
(2)在使用CART作为基分类器时,XGBoost显式地加入了正则项来控制模型的复杂度,有利于防止过拟合,从而提高模型的泛化能力。
(3)GBDT在模型训练时只使用了损失函数的一阶导数信息,XGBoost对损失函数进行二阶泰勒展开,可以同时使用一阶和二阶导数。
(4)传统的GBDT采用CART作为基分类器,XGBoost支持多种类型的基分类器,比如线性分类器。
(5)传统的GBDT在每轮迭代时使用全部的数据,XGBoost则采用与随机森林类似的策略,支持对数据进行采样。
(6)传统的GBDT没有对缺失值进行处理,XGBoost能够自动学习出缺失值的处理策略。
九、参数调整
超参数:无法使用最小二乘法或者梯度下降法等最优化算法优化出来的数;反之即参数(通常不由编程者手动设置,而是被保存为学习模型的一部分)。
1. 大致了解哪些参数调整策略?⭐️
网格搜索;随机搜索。
2. 网格搜索参数调整策略和随机搜索的区别?如何选择?⭐️
- 网格搜索相当于暴力地从参数空间中每个都尝试一遍,然后选择最优的那组参数,这样的方法显然是不够高效的,因为随着参数类别个数的增加,需要尝试的次数呈指数级增长。
- 更加高效的调优方式:随机搜索的方式。实验证明,随机搜索法结果比稀疏化网格法稍好(有时候也会极差,需要权衡)。参数的随机搜索中的每个参数都是从可能的参数值的分布中采样的。与网格搜索相比,这有两个主要优点:
可以独立于参数数量和可能的值来选择计算成本;添加不影响性能的参数不会降低效率。
————————————————————————————
第二部分:深度学习基础
深度学习其实也是监督学习的一部分,但是由于内容过于庞大和发展迅猛,一般单独拿出来讲,下图源自复旦邱锡鹏的nndl:

一、神经网络基础
1.神经网络可以解决哪些问题?👶
- DNN:deep neural network,深度神经网络。单层感知机不能解决的问题,那么使用更多层就可以解决了。
- CNN:convolutional neural network,卷积神经网络,主要用在图像、计算机视觉领域,如图像识别,目标检测,视频检测等等。CNN也有许多变种,能够解决不同的问题。
- RNN:主要用于序列数据的处理,比如语音领域:语音识别、语音分离;自然语言处理领域(文本检测,机器翻译);图像视频领域。
- GAN:生成式对抗网络,也属于神经网络的一种。有源源不断的新种类正在诞生。解决问题的涉及面相当广,不局限于语音、图像、视频、文字。
- 增强学习(强化学习):这只要是应用在游戏领域。比如Alpha-go
2.通常的全连接前馈神经网络如何工作?⭐️

3.为什么需要激活功能?👶
- 使用非线性激活函数的原因是线性模型的表达能力不够,通过对输出结果应用激活函数而引入非线性变换。
- 如果不用激活函数,每一层输出都是上一层输入的线性函数,那么每一层的输出都是输入的线性组合,与只有一个隐藏层的效果是一样的。
引入非线性函数后才使得深层神经网络有意义(可以逼近任意函数)。
有个大佬的视频真的娓娓道来(链接在下方),讲解了“信息量”、“比特”、“熵”、“KL散度”等概念和联系,极大似然估计和交叉熵的关系,更更加深入理解交叉熵作为损失函数的含义。
https://www.bilibili.com/video/BV15V411W7VB?p=1&share_medium=android&share_plat=android&share_session_id=11be65af-5446-4760-a2d1-088f2616470f&share_source=WEIXIN&share_tag=s_i×tamp=1628701950&unique_k=wVk4Jd
激活函数特点:
(1)非线性、
(2)可微性:因为在反向传播更新梯度时,需要计算损失函数对权重的偏导数,传统的激活函数sigmoid满足出处可微,而ReLU函数仅在有限个点处不可微。对于随机梯度下降(Stochastic Gradient Descent,SGD)算法,几乎不可能收敛到梯度接近0的位置,所以优先的不可微点对于优化结果影响不大。
(3)单调性:保证单层网络为凸函数;单调性说明其导数符号不变,使得梯度方向不会经常改变(从而让训练更容易收敛)
(4)f(x)≈x:f的福祉不会随着深度的增加而发生显著的增大(使得网络训练更为稳定,梯度也更容易回传),与(1)的非线性有点矛盾(所以说激活函数知识部分满足这个条件)
(5)输出值范围:
——对激活函数的输出结果进行范围限定(有助于梯度平稳下降,如Sigmoid、tanh),但对——输出值范围限定会导致梯度消失问题;
强行让每一层的输出结果控制在固定范围会限制神经网络的表达能力,而输出值范围为无限的激活函数(如ReLU函数),对应模型的训练过程更加高效,此时一般需要使用更小的学习率。
(6)计算简单、归一化
4.sigmoid 为激活函数有什么问题?⭐️
缺点:梯度下降非常明显,且两头过于平坦,容易出现梯度消失的情况,输出的至于不对称(并非像tanh函数那样是-1~1)
5.什么是ReLU?它比sigmoid 或tanh好吗?⭐️
(1)ReLU函数的线性特点使得其收敛速度比Sigmoid、tanh更快,而且没有梯度饱和的情况出现。
(2)计算更加高效,相比于sigmoid、tanh函数,ReLU只需要一个阈值就可以得到激活值,不需要对输入归一化来防止达到饱和。
6.如何初始化神经网络的权重?⭐️
在torch中可以使用torch.nn.init.xavier_normal_()进行正态分布的权重初始化,也可以使用何凯明初始化torch.nn.init.kaiming_normal_,效果会比其他好点。
7.如果将神经网络的所有权重都设置为0会怎样?⭐️
8.神经网络中有哪些正则化技术?⭐️
9.什么是1.1Dropout?为什么有用?它是如何工作的?⭐️
——————————————————————
二、神经网络的优化

上图源自复旦邱锡鹏的nndl第七章-网络优化与正则化的(7.2)优化算法。
1.什么是反向传播?它是如何工作的?为什么需要它?⭐️
首先回顾一个简单栗子

在Chris Olah的博客(http://colah.github.io/posts/2015-08-Backprop/)中,高数我们学过链式求导法则,现在下面的e当做误差函数,而把a、b、c和d当做权重,利用梯度下降求解这权重的最优值时,需要求误差函数对它们的偏导数——计算偏导数的好方法就是反向微分(就是下图中的从上往下的这个过程);反向微分的术语就是反向传播( B a c k w a r d Backward Backward P r o p a g a t i o n Propagation Propagation, B a c k p r o g a p a t i o n Backprogapation Backprogapation)。

正向微分( F o r w a r d − m o d e Forward -mode Forward−mode D i f f e r e n t i a t i o n Differentiation Differentiation):下图从下到上,从b开始正向往上计算所有节点上变量对b的导数
正向传播:在已知所有权重和转换函数的情况下,输入一个数组,一层层地向前(正方向)推进,最后输出一个数组。

反向微分( B a c k w a r d − m o d e Backward-mode Backward−mode D i f f e r e n t i a t i o n Differentiation Differentiation):下图从上到下,从e开始反向往下计算e对所有节点上变量的导数(计算的过程即紫色的部分)
反向传播即把权重当做未知量,从尾推导头得到偏导数。

ps:神经网络中的箭头承载着权重,从上一层的输出开始,权重乘以输出就是下一层的得分。
2.你知道哪些训练神经网络的优化技术?⭐️
【李宏毅深度学习】(task5)网络设计技巧1—Local Minimum和鞍点
【李宏毅深度学习】(task5)网络设计技巧2—Batch and Momentum
【李宏毅深度学习】(task5)网络设计技巧3—Adaptive Learning Rate
【李宏毅深度学习】(task5)网络设计技巧4—Batch Normalization批量归一化
3.如何使用SGD(随机梯度下降)训练神经网络?⭐️
4.学习率是多少?👶
5.学习率太大时会发生什么?太小?👶
学习率:确定权重连接调整成都的系数。
随机梯度下降法中的计算结果乘以学习率,可以得到权重调整值。
如果学习率过大,则有可能修正过头,导致无法收敛,神经网络训练效果不佳;反之,如果学习率过小,则收敛速度会很慢,导致训练时间过长。
6.如何设置学习率?⭐️
(1)多数时候我们会根据经验确定学习率,首先设定一个较大的值,再慢慢地把这个值变小,这是比较有效的方法。
(2)可以自适应调整学习率,如使用AdaGrad方法——用学习率除以截止当前时刻t的梯度 ∇ E \nabla E ∇E的累积值,得到神经网络的连接权重w:
w ( t + 1 ) = w − η ∑ i = 1 t ( ∇ E ( i ) ) 2 + ε ∇ E ( t ) w^{(t+1)}=w-\frac{\eta}{\sqrt{\sum_{i=1}^{t}\left(\nabla E^{(i)}\right)^{2}}+\varepsilon} \nabla E^{(t)} w(t+1)=w−∑i=1t(∇E(i))2+εη∇E(t) (3)AdaGrad方法会对网络参数逐个进行梯度累积,能够为每个参数分配不同的学习率——虽然该方法能够快速收敛,但是存在参数学习率不断衰减的问题。
(4)AdaDelta方法:在求梯度累积值时指使用距离当前时刻比较近的梯度
(5)动量 m o m e n t u m momentum momentum方法是以指数级衰减的形式累积之前参数的梯度。
7.什么是Adam?Adam和SGD之间的主要区别是什么?⭐️
A d a m Adam Adam算法在 R M S P r o p RMSProp RMSProp 算法的基础上对小批量随机梯度也做了指数加权移动平均,并且使用了偏差修正。

看adam论文中的伪代码(上图):
从while循环往下看,第一行是更新step,
第二行是计算梯度,
第三行计算一阶矩的估计,即mean均值
第四行计算二阶距的估计,即variance,和方差类似,都是二阶距的一种。
第五、六行则是对mean和var进行校正,因为mean和var的初始值为0,所以它们会向0偏置,这样处理后会减少这种偏置影响。
第七行是梯度下降。注意alpha后的梯度是用一阶距和二阶距估计的。
8.什么时候使用Adam和SGD?⭐️
9.要保持学习率不变还是在训练过程中改变它?⭐️
10.如何确定何时停止训练神经网络?👶
可以设置早停策略。
11.什么是ModelCheckpoint?⭐️
回调函数ModelCheckpoint将在每个epoch后保存模型到filepath。更多可以参考keras官方文档的详解。
keras.callbacks.ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', period=1)
12.讲一下你是如何进行模型训练的?⭐️

linux和win系统的多进程库是不同的:在win中是用spawn替代linux的fork(创建一个新进程)。所以要将把loader进行迭代的代码进行封装起来(如if语句或者函数里面,即不能直接写在外面), 也可以直接外面加上if __name__ == '__main__':。
# batch处理
if __name__ == '__main__':for epoch in range(50):# 内层循环执行一个mini-batchfor i, data in enumerate(train_loader, 0):# 也可以写成for i, (input, labels) in enumerate(train_loader, 0):# 1.准备数据inputs, labels = data # 2.向前传递y_predict = model(inputs)loss = criterion(y_predict, labels)losslst.append(loss.item())print(epoch, i, loss.item())# 3.反向传播optimizer.zero_grad()loss.backward()# 4.更新参数optimizer.step()
——————————————————————
第三部分:计算机视觉
1.如何使用神经网络进行计算机视觉?⭐️
(1)传统神经网络结构存在的缺点:
(1)输入层的维度过大,如一张尺寸较大的1000×1000×3的三通道图片,输入层的维度将达到三百万,使神经网络权重参数W的数量过于庞大。这样会造成2个后果:
容易出现过拟合——因为神经网络结构复杂,样本训练集不够时
训练模型较为困难——所需的内存和计算量非常庞大
(2)传统的前馈神经网络(将二维或三维/RGB三通道图片拉伸成一维特征,作为输入层)不符合图像特征提取的机制,忽略了各个像素点之间的区域性联系
所以CNN出现了。
(2)计算机视觉的四个基本任务
(关于这个任务,说法不一,比如有些地方说到对象检测detection、对象追踪tracking、对象分割segmentation,不用拘泥),即图像分类,对象定位及检测,语义分割,实例分割。图示如下:
- 1)图像分类:一张图像中是否包含某种物体
- 2)物体检测识别:若细分该任务可得到两个子任务,即目标检测,与目标识别,首先检测是视觉感知得第一步,它尽可能搜索出图像中某一块存在目标(形状、位置)。而目标识别类似于图像分类,用于判决当前找到得图像块得目标具体是什么类别。
- 3)语义分割:按对象得内容进行图像得分割,分割的依据是内容,即对象类别。
- 4)实例分割:按对象个体进行分割,分割的依据是单个目标。

2.什么是卷积层?⭐️
卷积层可通过重复使用卷积核有效地表征局部空间,卷积核(过滤器filter)通过卷积的计算结果(相似度)表示该卷积核和扫描过的图像块的灰色格子部分(此处举例的是黑白的手写体数字识别)相吻合的个数——该值越大则说明越符合卷积核的偏好程度(相似程度)。
——卷积的结果矩阵(这个矩阵上的每个元素即上面体积的每一个偏好程度)为特征映射( f e a t u r e feature feature m a p map map)
3.为什么需要卷积?不能使用全连接层吗?⭐️
4.CNN中的pooling是什么?为什么需要它?⭐️
pooling池化层:进行信息压缩。通常在 2 × 2 2×2 2×2的区域中进行(也不一定这样)。常用的信息压缩方法为最大池化( m a x max max p o o l i n g pooling pooling),即提取出划分好的各区域的最大值。
5.Max pooling如何工作?还有其他池化技术吗?⭐️
m a x max max p o o l i n g pooling pooling提取出划分好的各区域的最大值。
池化方法的种类:最大池化;平均池化;Lp池化。
6.CNN是否抗旋转?如果旋转图像,CNN的预测会怎样?🚀
(1)知乎大佬王峰说:CNN是没有旋转不变性的,只能靠数据增强。
有个spatial transformer network,用了之后可以旋转不变。
(2)卷积运算本身是不抗仿射变换的(想想卷积的性质)
(3)设计一个有旋转不变性/同变性的cnn:https://arxiv.org/pdf/1602.02660.pdf
7.什么是数据增强?为什么需要它们?你知道哪种增强?👶
(1)数据增强也叫数据扩增,即不实质性的增加数据的情况下,让有限的数据产生等价于更多数据的价值。
(2)作一些随机的裁剪、旋转操作得来。每张图对于网络来说都是不同的输入,加上原图就将数据扩充到原来的10倍。假如我们输入网络的图片的分辨率大小是256×256,若采用随机裁剪成224×224的方式,那么一张图最多可以产生32×32张不同的图,数据量扩充将近1000倍。虽然许多的图相似度太高,实际的效果并不等价,但仅仅是这样简单的一个操作,效果已经非凡了。
(3)如果再辅助其他的数据增强方法,将获得更好的多样性,这就是数据增强的本质。
(4)数据增强可以分为,有监督的数据增强和无监督的数据增强方法。其中有监督的数据增强又可以分为单样本数据增强和多样本数据增强方法,无监督的数据增强分为生成新的数据和学习增强策略两个方向。
8.如何选择要使用的增强?⭐️
9.你知道什么样的CNN分类体系?🚀
10.什么是迁移学习?它是如何工作的?⭐️
迁移学习是将从源数据集学到的知识迁移到目标数据集上。
11.什么是目标检测?你知道有哪些框架吗?🚀
资源推荐:提供轮子https://manaai.cn/
识别图像的目标主体的类别,在图像中的具体位置等
主流的框架:Faster R-CNN,SSD,YOLO三个检测框架,更多参考之前转载的一篇总结(CV之目标检测22年发展历程(CVHub))
目标检测的基本思路:同时解决定位(localization) + 检测(detection)。
多任务学习,带有两个输出分支。一个分支用于做图像分类,即全连接+softmax判断目标类别,和单纯图像分类区别在于这里还另外需要一个“背景”类。另一个分支用于判断目标位置,即完成回归任务输出四个数字标记包围盒位置(例如中心点横纵坐标和包围盒长宽),该分支输出结果只有在分类分支判断不为“背景”时才使用。
12.什么是对象分割?你知道有哪些框架吗?🚀
————————————————————————————
第四部分:自然语言处理
一、学习方法and入门须知:
-
文睿大佬建议:斯坦福的cs224n,宗成庆老师的《统计自然语言处理》,建议搭配李航老师的《统计学习方法》。例如nlp的话,至少要知道nlp都有哪些经典任务?每个经典任务的传统经典模型和现在主流用的模型都是哪些?懂原理吗?会用相应的库吗?
-
某NLP博士:入门是看知乎:从seq2seq到bert,把知乎提及的论文都看一遍就入门了
-
三类NLP任务:语言模型、基础任务、应用任务:
- 基础任务:中文分词、词性标注、句法分析、语义分析等
- 应用任务:信息抽取、情感分析、问答系统、机器翻译、对话系统等
-
NLP任务的评价方法:主要包括针对答案的准确率和F值,针对非确定答案的BLEU值,以及针对开放答案的人工评价等。
-
2018年以来,以BERT、GPT为代表的超大规模预训练语言模型七号弥补了NLP标注数据不足的缺点;模型预训练( P r e − t r a i n Pre-train Pre−train)即首先在一个原任务上预先训练一个初始模型,然后在下游任务(即目标任务)上继续对该迷行进行精调( F i n e − t u n e Fine-tune Fine−tune)——从而达到提高下游任务准确率的目的。
二、文本分类
1.如何使用机器学习进行文本分类?⭐️
2.什么是词袋模型?如何将其用于文本分类?⭐️
为了通过词的表示构成更长文本的表示——词袋(Bag-Of-Words,BOW)表示:假设文本中的词语是没有顺序的集合,将文本中的全部词所对应的向量表示(既可以是独热表示,也可以是分布式表示或词向量)相加,即构成了文本的向量表示。
ex:如在使用独热表示时,文本向量表示的每一维恰好是相应的词在文本中出现的次数。
3.词袋模型的优缺点是什么?⭐️
词袋表示非常简单、直观;但缺点:
(1)没有考虑词的顺序信息
(2)无法融入上下文信息,比如要表示“不 喜欢”,只能将两个词的向量相加,无法进行更细致的语义操作。
4.什么是N-gram?如何使用它们?⭐️
5.使用N-gram时,词袋模型中N应该是多少?⭐️
6.什么是TF-IDF?它对文本分类有什么用?⭐️
TF-IDF帮你建立:答案:B
A. 文档中出现频率最高的词 B. 文档中最重要的词
TF-IDF有助于确定特定词在文档语料库中的重要性。TF-IDF考虑了该词在文档中出现的次数,并被出现在语料库中的文档数所抵消。
7.你用过哪种模型对带有词袋特征的文本进行分类?⭐️
8.使用词袋进行文本分类时,你希望使用梯度提升树模型还是逻辑回归?⭐️
9.什么是词嵌入?为什么有用?你知道Word2Vec吗?⭐️
- 词的独热表示(One-hot Encoding):用一个词表大小的向量表示一个词——在该向量上中,词表中第i个词在第i维上被设置为1,其余维均为0。
——缺点:独热模型会导致数据稀疏问题,导致训练数据规模有限时,很多语言现象没有背充分的学习到。如“美丽”和“漂亮”两个语义相似的词语,但是通过余弦函数来度量它们之间的相似度时值可能为0。
——解决方法:提取更多和词相关的泛化特征,如词性特征、语义特征和词聚类特征等。 - 词的分布式表示:向量值是通过对语料库进行统计得到的,然后再经过点互信息、奇异值分解等变换,一旦确定则无法修改。
- 词嵌入表示(Word Embedding):使用一个连续、低维、稠密的向量(词向量)来表示词,词向量的向量值是随着目标任务的优化过程自动调整的,即可以将词向量中的向量值看做模型的参数。
- 文本的词袋表示(见第2、3点)。
10.还知道其他词嵌入的方法吗?🚀
glove词向量等。
11. 如果你的句子包含多个单词,则可能需要将多个单词嵌入组合为一个。你会怎么做?⭐️
12.在进行带有嵌入的文本分类时,使用梯度提升树模型还是逻辑回归?⭐️
13.如何使用神经网络进行文本分类,用CNN呢?🚀
14.bpe是什么,word piece是什么,sub word是什么👶
子词切分:将一个单词切分为若干连续的片段。很多子词切分算法基本原理都是——使用尽量长且频次高的子词对单词进行,如BPE(字节对编码,Byte Pair Encoding):
(1)首先构造好子词词表
(2)将一个单词切分为子词序列:
1)可以用贪心思想将子词词表按照子词的长度由大到小进行排序
2)从前往后遍历子词词表,依次判断一个子词是否为单词的子串,如果是的话,则将该单词切分,然后继续往后遍历子词词表
3)如果子词词表全部遍历完,单词中仍然有子串没有被切分,那么这些子串一定为低频串——则使用统一的标记,如<UNK>进行替换。
WordPiece也是子词切分算法,与BPE类似(每次从子词词表中选出两个子词进行合并),与BPE最大区别是——选择两个子词进行合并的策略不同:BPE选择频次最高的相邻子词合并,而WordPiece选择能够提升语言模型概率最大的相邻子词进行合并。
ps:提升语言模型概率最大的相邻子词具有最大的互信息值,即两子词在语言模型上具有较强的关联性(它们经常在语料中以相邻方式同时出现)。
三、循环神经网络
1.RNN和CNN各自特点?⭐️
传统文本处理任务中一般将TF-IDF向量作为特征输入,这种表示实际丢失了输入的文本序列中每个单词的顺序。如CNN时input变长的字符串或者单词串,然后通过滑动窗口(卷积)和池化的方式将input转换为一个固定长度的像狼表示——虽然可以捕捉到原文本中一些局部特征,但是两个单词之间的长距离依赖问题很难被学习到,而RNN则可以。

2.RNN能否使用ReLU作为激活函数?⭐️
可以。
【小trick】当采用ReLU作为RNN中隐藏层的激活函数时,只有当W的取值在单位矩阵附近时才能取到较好的效果(因此要将W初始化为单位矩阵),实验证明这样做后能在一些应用与LSTM取得相似的结果,且学习速度更快。
3.Seq2Seq在解码时的常用方法?⭐️
- 最基础的方法是贪心法,即选取一种度量标准后,每次都在当前状态下选择最佳的一个结果,知道结束。
- 改进的方法有集束搜索(是启发式算法),会保存beam size个当前的较佳选择,然后解码时每一步根据保存的选择进行下一步扩展和排序,然后又是选取前beam size个进行保存,循环迭代,直到结束时选择最佳的一个作为解码的结果。
- 其他改进方法:使用堆叠的RNN、增加Dropout机制、与编码器之间建立残差连接等。重要的改进有注意力机制,使得解码时每一步可以有针对性的关注与当前有关的编码结果,从而减小编码器输出表示的学习难度,更容易学习到长期的依赖关系。
4.长程依赖问题是什么👶
当输入序列比较长时,会存在梯度爆炸和消失问题,为了解决长程依赖问题(简单神经网络很难建模长距离依赖),大佬们对RNN进行改进,如引入门控机制(LSTM)。
四、Transformer机制
0.Seq2Seq模型引入注意力机制是为了解决啥问题?👶
以往Seq2Seq模型的输出序列常常因为在解码时,当前词及对应的源语言词的上下文信息和位置信息在编解码过程中丢失了,造成损失部分输入序列的信息。
在注意力机制中,仍然可以用普通的RNN对输入序列进行编码,得到隐状态h1,h2,…hT。但是在解码时,每一个输出词都依赖于前一个隐状态以及输入序列每一个对应的隐状态 s i = f ( s i − 1 , y i − 1 , c i ) s_{i}=f\left(s_{i-1}, y_{i-1}, c_{i}\right) si=f(si−1,yi−1,ci)
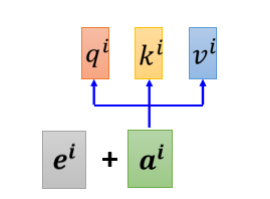
1.为什么Transformer中加入了positional embedding?⭐️
答:初始的self-attention的这个layer的每一个input,对于sequence中的最前还是最后的东东,缺少了重要的位置信息。如在做词性标记POS tagging时,动词很少出现在句首,所以某一个词汇如果放在句首的话,那么它是动词的可能性很低。所以在一开始paper《Attention Is All You Need》中将位置的信息塞进去(如下图所示),每一个位置设定一个 vector(positional vector,用 e i e^i ei 来表示),上标 i 代表是位置,每一个不同的位置。
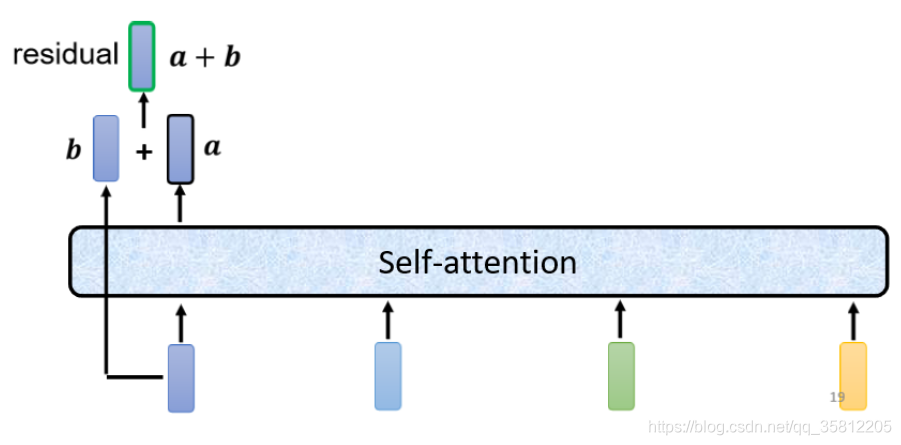
2.Transformer中的残差网络结构(residual connecttion)作用是什么?⭐️
答:在transformer里面加了了一个设计——不只是输出这个vector,还要把这个vector加上它的input得到新的ouput。BN其实已经解决了梯度消失问题,resnet残差链接更多解决的是深层网络训练时候退化的问题,更多参考https://zhuanlan.zhihu.com/p/268308900。
3.Transformer中的softmax计算为什么需要除以 d k d_k dk?⭐️
答:如果我们计算句子中第一个位置单词的 Attention Score(注意力分数),那么第一个分数就是 q1 和 k1 的内积,第二个分数就是 q1 和 k2 的点积。以此类推。而每个Attention Score(注意力分数)除以 ( d k e y ) \sqrt(d_{key}) (dkey) ( d k e y d_{key} dkey是 Key 向量的长度),当然也可以除以其他数,除以一个数是为了在反向传播时,求取梯度更加稳定( ps:在车万翔老师的书《自然语言处理》中说的是:避免因为向量维度d过大导致点积结果过大)。
4.为什么 num_heads 的值需要能够被 embed_dim 整除?⭐️
这是为了把词的隐向量长度平分到每一组,这样多组注意力也能够放到一个矩阵里,从而并行计算多头注意力。例如,8 组注意力可以得到 8 组 Z 矩阵,然后把这些矩阵拼接起来,得到最终的输出。如果最终输出的每个词的向量维度是 512,那么每组注意力的向量维度应该是512 ÷8=64。如果不能够整除,那么这些向量的长度就无法平均分配。
5.Transformer中attention score计算时候如何mask掉padding位置?🚀
如在Comirec-SA模型中,可以先减去一个负无穷大,然后使用softmax归一化将paddign的位置mask掉。
A = torch.einsum('bsd, dk -> bsk', H, self.W2) + -1.e9 * (1 - mask)
A = F.softmax(A, dim=1)
6.为什么GPT要比transformer在对话系统上表现好🚀
让我们拆解一个训练好的 GPT-2,看看它是如何工作的。

图:拆解GPT2
GPT-2 能够处理 1024 个 token。每个 token 沿着自己的路径经过所有的 Decoder 模块
运行一个训练好的 GPT-2 模型的最简单的方法是让它自己生成文本(这在技术上称为 生成无条件样本)。或者,我们可以给它一个提示,让它谈论某个主题(即生成交互式条件样本)。在漫无目的情况下,我们可以简单地给它输入初始 token,并让它开始生成单词(训练好的模型使用 <|endoftext|> 作为初始的 token。我们称之为 <s>)。

图:拆解GPT2初始token
模型只有一个输入的 token,因此只有一条活跃路径。token 在所有层中依次被处理,然后沿着该路径生成一个向量。这个向量可以根据模型的词汇表计算出一个分数(模型知道所有的 单词,在 GPT-2 中是 5000 个词)。在这个例子中,我们选择了概率最高的 the。但我们可以把事情搞混–你知道如果一直在键盘 app 中选择建议的单词,它有时候会陷入重复的循环中,唯一的出路就是点击第二个或者第三个建议的单词。同样的事情也会发生在这里,GPT-2 有一个 top-k 参数,我们可以使用这个参数,让模型考虑第一个词(top-k =1)之外的其他词。
下一步,我们把第一步的输出添加到我们的输入序列,然后让模型做下一个预测。

动态图:拆解GPT2
请注意,第二条路径是此计算中唯一活动的路径。GPT-2 的每一层都保留了它自己对第一个 token 的解释,而且会在处理第二个 token 时使用它(我们会在接下来关于 Self Attention 的章节中对此进行更详细的介绍)。GPT-2 不会根据第二个 token 重新计算第一个 token。
五、Bert预训练模型
1.word2vec到BERT改进了什么?👶
答:通过 Word2Vec,我们可以使用一个向量(一组数字)来恰当地表示单词,并捕捉单词的语义以及单词和单词之间的关系,其中包括CBOW(Continuous Bag-of-Words)模型和Skip-gram模型。CBOW所做的,与BERT一样也是做一个空白,并要求它预测空白处的内容。
CBOW是一个非常简单的模型,它使用两个变换,有人会问,“为什么它只使用两个变换?”,“它可以更复杂吗?”——CBOW的作者Thomas Mikolov说可以用深度学习,但是之所以选择线性模型,最大的担心其实是算力问题(16年训练一个非常大的模型还是比较困难的)。现在当你使用BERT的时候,就相当于一个深度版本的CBOW,你可以做更复杂的事情,而且BERT还可以根据不同的语境,从同一个词汇产生不同的embedding(Contextualized embedding)。
2.BERT预训练是如何做mask的?BERT预训练时mask的比例,可以mask更大的比例(大于80%)吗🚀
答:mask的具体实现主要有两种方法(都可以用):

- 第一种方法:用一个特殊的符号替换句子中的一个词,我们用 "MASK "标记来表示这个特殊符号,你可以把它看作一个新字,这个字完全是一个新词,它不在你的字典里,这意味着mask了原文。
- 第二种方法:随机把某一个字换成另一个字。中文的 "湾"字被放在这里,然后你可以选择另一个中文字来替换它,它可以变成 "一 "字,变成 "天 "字,变成 "大 "字,或者变成 "小 "字,我们只是用随机选择的某个字来替换它。
3.BERT如何进行tokenize操作?有什么好处?⭐️
答:BERT 基本上是一个训练好的 Transformer 的 Encoder 的栈。但是 Encoder 的 Self Attention 层,每个 token 会把大部分注意力集中到自己身上,那么这样将容易预测到每个 token,模型学不到有用的信息。BERT 提出使用 mask,把需要预测的词屏蔽掉。
BERT 预训练的第 2 个任务是两个句子的分类任务。在上图中,tokenization 这一步被简化了,因为 BERT 实际上使用了 WordPieces 作为 token,而不是使用单词本身。在 WordPiece 中,有些词会被拆分成更小的部分。
4.BERT模型特别大,单张GPU训练仅仅只能放入1个batch的时候,怎么训练?🚀
答:google 官方bert本身不支持分布式训练,因此有其他用户自己修改了一个版本分支,官方bert也接受了:
分支地址:https://github.com/google-research/bert/pull/568
代码地址:https://github.com/abditag2/bert
更多可以参考——bert多GPU训练
5.为什么会先提起Bert?⭐️
bert带火了transformer。
6.GPT如何进行tokenize操作?和BERT的区别是什么?⭐️
GPT2使用Transformer的Decoder模块构建
工作方式(自回归):产生每个token;将token添加到输入的序列中,形成一个新序列;将上述新序列作为模型下一个时间步的输入。
六、预训练代码实践
1. B E R T BERT BERT 训练时候的学习率 l e a r n i n g learning learning r a t e rate rate如何设置? B E R T BERT BERT 中的warmup作用是什么?
答: B E R T BERT BERT 的训练中另一个特点在于 W a r m u p Warmup Warmup,其含义为:在训练初期使用较小的学习率(从 0 开始),在一定步数(比如 1000 步)内逐渐提高到正常大小(比如上面的 2e-5),避免模型过早进入局部最优而过拟合;在训练后期再慢慢将学习率降低到 0,避免后期训练还出现较大的参数变化。
2.如何理解BERT模型输入的type ids?
答:
3.BERT模型使用哪种分词方式?WordPiece分词的好处是什么?
答:子词切分:将一个单词切分为若干连续的片段,各种算法的基本原理都是使用尽量长且频次高的子词对单词进行切分。如在本次代码中的WordPieceTokenizer在词的基础上,进一步将词分解为子词(subword)。例如,tokenizer 这个词就可以拆解为“token”和“##izer”两部分。
BPE和WordPiece区别:两者在选择两个子词进行合并的策略不同——BPE选择频次最高的相邻子词进行合并,WordPiece选择能够提升语言模型概率最大的相邻子词进行合并。
4.Hugginface代码中的BasicTokenizer作用是?⭐️
答:BasicTokenizer负责处理的第一步——按标点、空格等分割句子,并处理是否统一小写,以及清理非法字符。
- 对于中文字符,通过预处理(加空格)来按字分割;
- 同时可以通过
never_split指定对某些词不进行分割; - 这一步是可选的(默认执行)。
第五部分:无监督学习
什么是无监督学习?👶:
- 聚类(clustering)问题:没有标签的情况下,给数据分类,如给猫狗兔图片分类
- 主成分分析(principal component analysis)问题:我们能否找到少量的参数来准确地捕捉数据的线性相关属性?比如,一个球的运动轨迹可以用球的速度、直径和质量来描述。再比如,裁缝们已经开发出了一小部分参数,这些参数相当准确地描述了人体的形状,以适应衣服的需要。另一个例子:在欧几里得空间中是否存在一种(任意结构的)对象的表示,使其符号属性能够很好地匹配?这可以用来描述实体及其关系,例如“罗马” 、“意大利”、“法国” 、“巴黎”。
- 因果关系(causality)和概率图模型(probabilistic graphical models)问题:我们能否描述观察到的许多数据的根本原因?例如,如果我们有关于房价、污染、犯罪、地理位置、教育和工资的人口统计数据,我们能否简单地根据经验数据发现它们之间的关系?
- 生成对抗性网络(generative adversarial networks):为我们提供一种合成数据的方法,甚至像图像和音频这样复杂的非结构化数据。潜在的统计机制是检查真实和虚假数据是否相同的测试,它是无监督学习的另一个重要而令人兴奋的领域。
一、聚类
什么是聚类?什么时候需要它?👶
K-means是如何工作的吗?⭐️
如何为K均值选择K?⭐️
你还知道其他哪些聚类算法?⭐️
你知道DBScan如何工作吗?⭐️
何时选择K-means,何时选择DBScan?⭐️
二、降维
1. 维度灾难是什么?为什么要关心它?⭐️
维度过高,计算量大。
2. 知道降维技巧吗?⭐️
3. 什么是奇异值分解?它通常如何用于机器学习?⭐️
SVD矩阵分解。
三、排序和搜索
什么是排序问题?可以使用哪些模型来解决它们?⭐️
文本信息检索任务重,什么是好的无监督baselines?⭐️
如何评估排序算法?使用哪些离线指标?⭐️
k的精度和召回率是多少?⭐️
k的平均精度均值是多少?⭐️
如何使用机器学习进行搜索?⭐️
如何获得训练算法的排序数据?⭐️
可以将搜索问题表述为分类问题吗?⭐️
如何将点击数据用作训练数据以进行排序算法?🚀
如何使用梯度提升树GBDT进行排序?🚀
如何在线评估新的排序算法?⭐️
第六部分:推荐系统
这块也是和深度学习紧密联系的。
王喆大佬的提醒:如果你介绍的项目是实现了一种类似阿里DIN的CTR预估模型。那么问题路径可能是这样的。
- softmax函数的定义是什么?(知识)
- 深度神经网络为什么会产生梯度消失现象,如何解决它?(知识)
- 常见的激活函数有哪些?都有什么特点?(知识)
- 挑一种激活函数推导梯度下降的过程。(知识+逻辑)
- Attention机制什么?(知识)
- 阿里将attention机制引入推荐模型的动机是什么?(知识+业务)
- DIN中将用户和商品进行了embedding,请讲清楚两项你知道的embedding方法。(知识)
- 推荐系统中embedding技术都可以有哪些应用?(业务+知识)
- 你如何serving类似DIN这样的深度学习模型(工具+业务)
上面这条路径侧重于考查“知识”深度的路径。为了弥补其他方向考察的不足,面试官肯定还会问一个从工具或者业务出发的问题来确定你其他方面的深度。
1. 什么是推荐系统?👶
2. 建立推荐系统时有什么好的 baseline?⭐️
3. 什么是协同过滤?⭐️
- 协同: 使用多个用户的数据来训练模型,借助群体智慧的同时也避免了单个用户数据的信息不足。
- 过滤: 把十亿量级的商品降低到数百量级甚至更少,解决信息过载问题。
结合两种思想就是协同过滤,使用多个用户的数据来训练一个模型。模型输入可以有用户信息,物品信息,还可以有上下文信息等等,模型输出是各物品的预测评分,最后仅取分数top K的物品推荐给用户。
4. 如何将隐式反馈(点击等)纳入推荐系统?⭐️
5. 什么是冷启动问题?⭐️
(1)冷启动问题:在没有大量用户数据的情况下如何给用户进行个性化推荐。
(3)目的:最优化点击率、转化率或用户体验(用户停留时间、留存率等)。
(3)分类:
- 用户冷启动:对一个之前没有行为或者行为极少的新用户进行推荐
- 物品冷启动:为一个新上市的商品或电影(这时没有与之相关的评分或用户行为数据)寻找潜在兴趣用户
- 系统冷启动:为一个新开发的网站设计个性化推荐系统
6. 解决冷启动问题的可能方法?🚀
各种embedding技术、加入side information。
7.常见的推荐算法有哪些?
- 协同过滤推荐算法(Collaborative Filtering Recommendation)
- 内容推荐算法(Content-based Recommendation)
- 相似性推荐算法(Similarity Recommendation)
- 关联规则推荐算法(Association Rule Based Recommendaion)
8.介绍 FM 和 DeepFM
- [https://www.hrwhisper.me/machine-learning-fm-ffm-deepfm-deepffm/ ]
9.介绍一下协同过滤的冷启动和原因
10.基于内容的推荐算法优缺点
11.你了解的 CTR 预估模型有哪些?
deepFM、DIN、DIEN、wide&deep等。
12.推荐里面的低秩矩阵分解具体是怎么做的?
13.常见的推荐算法面试问题
(1)初级问题
- 这个项目的日活有多少?
- 你负责的这个模块, 输入输出的规模有多大?
- 模型使用了哪些特征?
- 模型使用了哪些结构? 画出模型的结构图。
- 训练模型使用的是什么优化算法?
- 优化的目标有哪些? 多个目标的损失函数是怎么融合的? 多个目标的打分是怎么融合的?如MMOE多目标融
- 离线评估时采用了哪些指标? 在线评估时主要看哪些指标?
- 模型多长时间更新一次?
(2)中级问题
- 当初为什么要做出这个选型决策? 原来的老模型是什么? 有哪些缺点促使你决定升级? 新模型是如何解 决老模型的那些缺点的?
- 对于实数特征是如何处理的? 分桶是什么做的? 对于观看次数这样的长尾分布的数据如何处理?
- ——可以取log或开平方
- 面对高维稀疏的特征空间, 如何处理特征维度爆炸的问题?
- ——PCA降维or使用nn.embedding
- 召回模型中的负样本为什么是靠随机采样得来的? 为什么不像精排那样用"曝光末点击"当负样本? 排序 与召回的样本策略为什么有如此不同:召回看样本,排序看特征
- 召回中负样本的采样是如何实现的? 离线采样还是在线采样? 采样时是均匀采样吗?
- ——随机采样速度很慢,无偏采样(按一定分布)即根据item的流行度、用户活跃度采样;负样本加权采样。
- 召回结果出现了热门内容霸屏的现象, 可能是什么原因造成的? 如何解决?
- ——冷启动、调整特征权重、已经被推荐的item加入惩罚因子、混合策略
- 对于一些经典模型,应该有深入理解。FM就是这样的 经典模型。
- 问FM相对LR的优点有哪些? ——FM特征交叉,学习非线性交互关系、泛化能力;deepfm的fm比传统fm训练更快(使用Mini-batch SGD);类别or数值特征都可以:二元特征click直接输入、连续特征age归一化后输入or通过nn.embedding低维emb后进入FM
- 对于Wide & Deep, 哪些特征应该进 Wide侧? 哪些特征应该进Deep侧? 为什么在训练中要采用两个不同的优化算法?
- ——wide处理低阶特征交叉(我的版本就直接lr了)、deep处理高阶特征交叉+非线性;高阶特征交叉:搜索词and行为、历史item序列cat;低阶:用户性别和年龄。
- 如果2个特征之间存在线性相关性,则交互就可能比较简单;如果存在非线性则交互复杂;w&d的联合训练和集成学习不同(wide部分是使用L1正则化的Follow-the-regularized-leader(FTRL)算法进行优化,deep部分使用的是AdaGrad完成优化。)wide部分使用FTRL在线学习算法。

- 阿里的Deep Interest Network(DIN)提出这个 模型主要解决什么问题? 它的时间复杂度和什么有关? 如果用户行为序列太短需要补齐, 对那些补齐的 位置,模型需要如何处理?——DIN和DIEN区别在于后者
- 如果要同时预测"点击率"与"购买率", 训练这两个目标的负样本应该如何选取?
- 在Wide&Deep模型中,一般会使用类别型特征的embedding向量和数值型特征的原始值拼接,得到最终的特征向量,例如:
v ∗ f i n a l = [ v ∗ e m b e d d i n g , v n u m ] \mathbf{v}*{final} = [\mathbf{v}*{embedding}, \mathbf{v}_{num}] v∗final=[v∗embedding,vnum]
其中, v ∗ e m b e d d i n g \mathbf{v}*{embedding} v∗embedding是类别型特征的embedding向量, v ∗ n u m \mathbf{v}*{num} v∗num是数值型特征的原始值。
(3)高级问题
- 哪些因素会导致线上线下的效果不一致? 如何解决?
- 推荐系统中经常出现的bias有哪些? 如何解决?
- 做 A / B A / B A/B 实验的时候, 有哪些需要注意的地方?
- 对新用户、新物料的冷启, 你有哪些好的解决方案?
- 工程问题:
- 如:特征平台,比如物品实时统计特征,可能是通过客户端上报实时计算点击数,点赞数,购买数,用户画像可能是离线计算,从hive或者hdfs每天更新,物品的一些基础属性也可能是通过mysql db 表生成。特征的生产和使用可能是由不同业务团队负责,因此相对隔离,同时计数口径也可能不一样,会给使用上带来一定的障碍。
第七部分:时间序列
1.什么是时间序列?👶
2.时间序列与通常的回归问题有何不同?👶
3.用于解决时间序列问题的有哪些模型?⭐️
4.如果序列中有趋势,如何消除它?为什么要这么做?⭐️
5.在时间t处测得只有一个变量“y”的序列。如何在时间t + 1预测“y”?使用哪种方法?⭐️
6.有一个带有变量“y”和一系列特征的序列。如何预测t + 1时的“y”?使用哪种方法?⭐️
7.使用树来解决时间序列问题有什么问题?⭐️
第八部分:强化学习
- 强化学习还可以解决许多监督学习无法解决的问题。 例如,在监督学习中,我们总是希望输入与正确的标签相关联。 但在强化学习中,我们并不假设环境告诉智能体每个观测的最优动作。 一般来说,智能体只是得到一些奖励。 此外,环境甚至可能不会告诉是哪些行为导致了奖励。
- 一般的强化学习问题是一个非常普遍的问题。 智能体的动作会影响后续的观察,而奖励只与所选的动作相对应。 环境可以是完整观察到的,也可以是部分观察到的,解释所有这些复杂性可能会对研究人员要求太高。 此外,并不是每个实际问题都表现出所有这些复杂性。 因此,学者们研究了一些特殊情况下的强化学习问题。
- 当环境可被完全观察到时,强化学习问题被称为马尔可夫决策过程(markov decision process)。 当状态不依赖于之前的操作时,我们称该问题为上下文赌博机(contextual bandit problem)。 当没有状态,只有一组最初未知回报的可用动作时,这个问题就是经典的多臂赌博机(multi-armed bandit problem)。
一个大佬写的强化学习文章https://arxiv.org/pdf/1810.06339.pdf,其中有这么一幅图:
原理学习:spinning up、David Silver的公开课和ppt
学习目标:
(1)基于价值函数的算法:Q-learning DQN Dueling DQN
(2)梯度算法:VPG TRPO PPO DDPG TD3 SAC
(3)动手实现PPO,并在PongNoFrameskip-v4环境达成平均回报20
参考:TensorFlow实现的各种算法代码——TensorFlow版本最好控制在2.0、2.1左右,太高或者太低则很多代码无法运行
学习分布式强化学习框架
SEED RL
工具:
编辑器:Pycharm vscode
包管理器:anaconda3
智能体框架:TensorFlow pytorch
环境框架:gym pygame
建议:
(1)最好安装Ubuntu系统(不过就目前算法的学习阶段,win也能顺利运行)
(2)模型训练时,注意版本的控制和存储,可安装matplotli等工具可视化学习成果
(3)学习过程可以使用开放云平台Colaboratory,可避开搭建平台或GPU不足的困境
(4)OpenAI Spinning Up的实现需要TensorFlow学习框架,最好将python的版本控制在3.7及以下,否则容易报错
1.学习资料
(1)SLM Lab学习资源——《深度强化学习基础》书的配套库,用于可重复强化学习RL研究的软件框架,非基于图像的环境可以在笔记本电脑上运行,对于台式机参考GTX 1080 GPU 4个3.0GHz以上的CPU 32GB内存。
(2)立竿见影:试试unity的ml-agents工具或spinning up中的gym玩具例子
强化学习的算法很多,推荐看PPO这类,即无模型的策略梯度类的方法(简单粗暴)
(3)伯克利CS294进阶课程,系统理论和前沿介绍
(4)《强化学习精要》和《强化学习导论》
刘:
李宏毅、 nndl(《神经网络与深度学习》)邱锡鹏 、花书(《深度学习》)、 博客 b站
2.代码层面:
完成强化学习算法(CPG PPO A3C Q-learning DQN)在贪吃蛇环境的应用(即作出控制贪吃蛇的智能体)
在github上找到对应算法的代码并跑通代码
阅读理解代码的实现逻辑,对代码中用到的重要函数查阅和理解
对算法的调试和优化,使贪吃蛇智能体取得更好的分数
3.理论层面
阅读并理解五大算法的论文(需配合贪吃蛇代码的完成顺序)
对分布式相关知识的学习:按顺序完成学习A3C DPPO IMPALA seed-rl的论文及其相关文章
4.成果验收
(1)考察智能体在贪吃蛇的得分
三个算法(A3C PPO DQN)在测试中平均分在30分以上
两个基础算法(CPG Q-learning)平均分在25分以上
最后的大作业(使用seed-rl框架)平均分在35分以上
(2)对神经网络构建代码,对强化学习各算代码逻辑(尤其是seed-rl的项目代码)的理解程度
(3)对神经网络基础,强化学习基础,强化学习主要算法及强化学习业界重大理论知识的理解程度
第(2)(3)点由每天日会后的交流和总结做学习成果的评估。
5.附录
(1)numpy,按照教程在python控制台敲一遍就可以了
(2)gym 常用的环境包装器
(3)简单的强化学习实验可以不使用GPU,一般可以先安装anaconda,再pip安装剩余的包解决。推荐Ubuntu
(4)机器学习的西瓜书,李航的统计学习方法,神经网络-吴恩达的深度学习教程
(5)TensorFlow和pytorch网上教程很多
第九部分:其他
1.分布式机器学习框架
MapReduce编程模型
下图来自google的一篇论文:《MapReduce: Simplified Data Processing on Large Clusters》

reference
(1)面试题:https://hackernoon.com/160-data-science-interview-questions-415s3y2a
(2)完备的 AI 学习路线,最详细的资源整理
(3)《深度学习中的数学》[日]涌井良幸——贼通俗易懂的讲解数学,连高数最基础的拉格朗日乘数法的都带有例题,能快速复习以前学过的知识;算法讲解把输入层为恶魔的手下,隐藏层为恶魔,而恶魔之间的“交情”为神经单元之间的权重,通俗讲解。
(4)《深度学习基础与实践》Adam Gibson
(5)知识图谱: http://www.openkg.cn/
(6)刘建平大佬的博客
(7)自然语言处理面试题,更至105题,持续更新…
(8)NLP面试宝典:38个最常见NLP问题答案一文get
(9)王喆大佬:https://zhuanlan.zhihu.com/p/76827460
(10)NLP百面百搭


![[漫画]120430 混血男孩](https://pic002.cnblogs.com/images/2012/361824/2012043012094364.jpg)