点击上方“AI遇见机器学习”,选择“星标”公众号
第一时间获取价值内容

夕小瑶科技说 原创
作者 | 小戏、Python
从 OpenAI 的 ChatGPT、Meta 的 LLaMA、Anthropic 的 Claude 到复旦的 Moss、清华的 ChatGlm、MiniMax 的 Glow,国内的国外的大模型百花齐放层出不穷。那么,抛出一个相信大家都会关心的问题!在中文背景下,这些各门各派的大模型究竟谁更能打?谁具有更强的推理判断能力以及更加全面的世界知识?
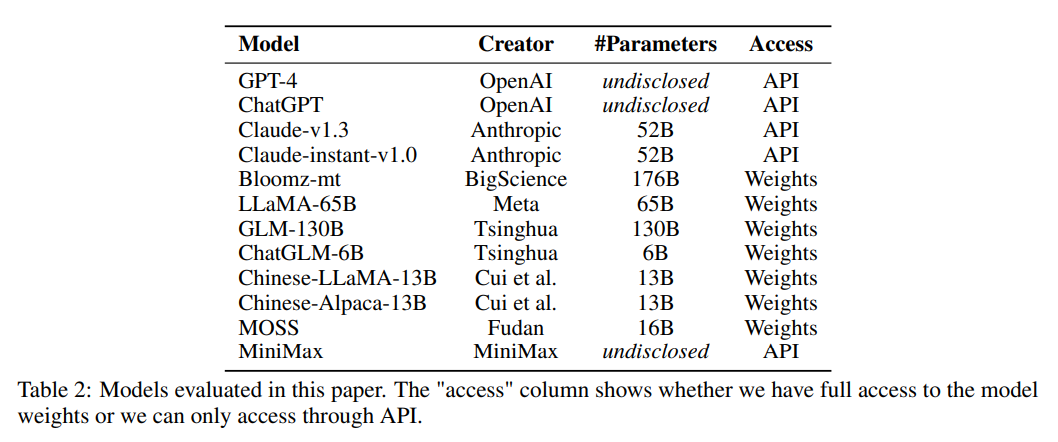
来自上交、清华以及爱丁堡大学的研究者们为这些模型举办了一场“天下第一武道大会”,首次提出了一个包含 52 个学科的全面的中国文化背景下的大模型高级知识和推理能力评估套件 C-EVAL,评估了包含 GPT-4、ChatGPT、Claude、LLaMA、Moss 在内的 9 个国内外大模型在中文学科问题上的性能!

如果跳过大模型们华山论剑决战紫禁之巅的过程,直接来看结果。出乎意料的是,这场比赛出现了一边倒的局面,在所有参与测评的大模型中,只有 GPT-4 的准确率超过了 60%,达到了 68.7%,对其余模型有代际上的差距,整体正确率前三甲 GPT-4、ChatGPT 以及 Claude-v 1.3 均来自国外,而国产模型中表现最好的 MiniMax 的准确率也只有 49%,相差排名第 1 的 GPT-4 接近 20 个点,相差 ChatGPT 也有 5 个点左右的差距,革命尚未成功,同志仍需努力。
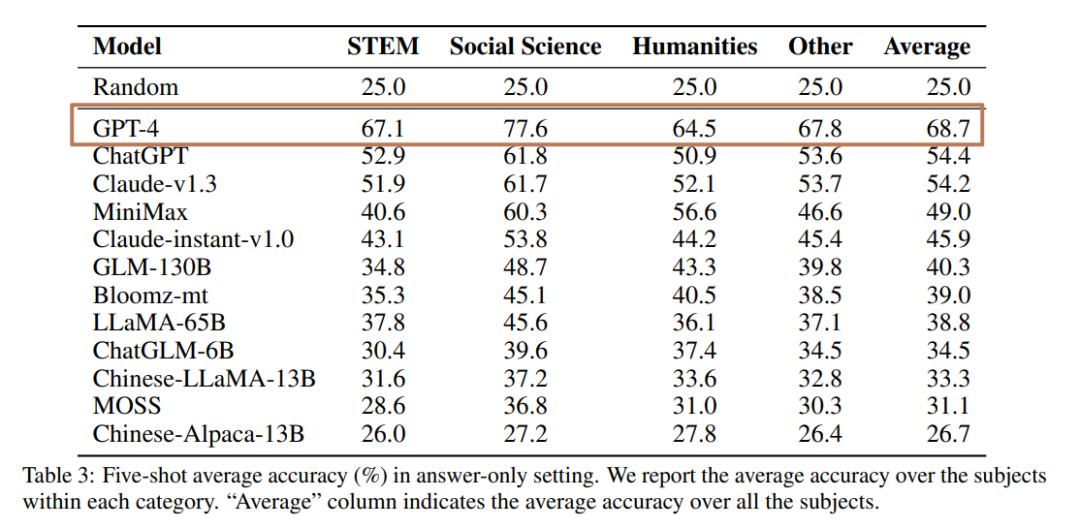
而细究国产或专门在中文数据上进行微调的大模型时,如果排除掉 bug GPT-4,可以看到有一些国产模型还是成功在一些中文语境下的问题中获得了超越国外模型的性能,如表现最好的 MiniMax 在毛泽东思想(73.5% vs.60.7%)、艺术研究(65.4% vs.49.7%)、中国语言文学(59.3% vs.50.2%)和中国近现代史(70.1% vs.62.8%)等领域中,MiniMax 显著优于 ChatGPT。
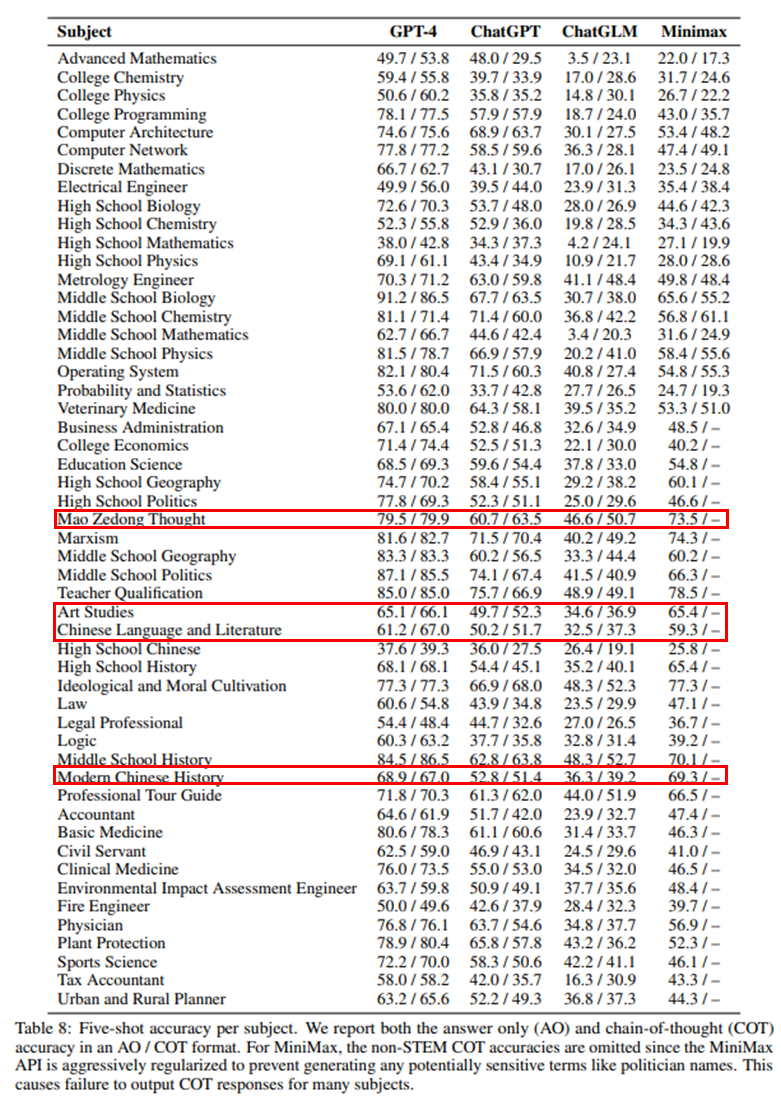
纵观所有的评测结果,其实一方面虽然 GPT-4 在所有模型中一枝独秀,但是从得分上来说正确率也只有百分之六十多,这其实是说当下任何一种大模型在单纯中文语料的推理上都仍然有很大的提升空间。而另一方面,国产模型虽然相较国外的模型表现不佳,但是很大程度上可能是源于参数量的不同而带来的推理能力的下降,很大程度上参数量与模型的准确率还是有很大的关系,几个排名垫底的模型参数量均没有那么巨大,并且 50B 参数以下的模型效果也只比随机基线(25%准确率)高不到 10 个点。
详解 C-EVAL
一个良好的模型评测评估标准对模型的研发十分重要,评估评测标准的核心点一个在于选择的指标能否优秀的代表“中文推理判断”这样一个模糊的外延丰富的名词,而另一个则在于评测的结果能否全面准确的反应模型的真实能力。在大模型出现之后,传统的评测指标确实已经不再能够适应并挖掘大模型蕴含的能力,而为了评估这些大模型相对高级的,如推理与世界知识的能力,论文作者团队从中国真实的、具有挑战性的人类的考试题中构建了 C-EVAL,这些考试可以被分为四大类共 52 种不同的学科,每个学科内两百到五百道不等的四个选项的单项选择题,其中四大类分别是 STEM(Science、Technology、Engineering、Mathematics),人文科学,社会科学与其他(包含医学、公务员考试、注册会计师考试、消防工程师考试等)
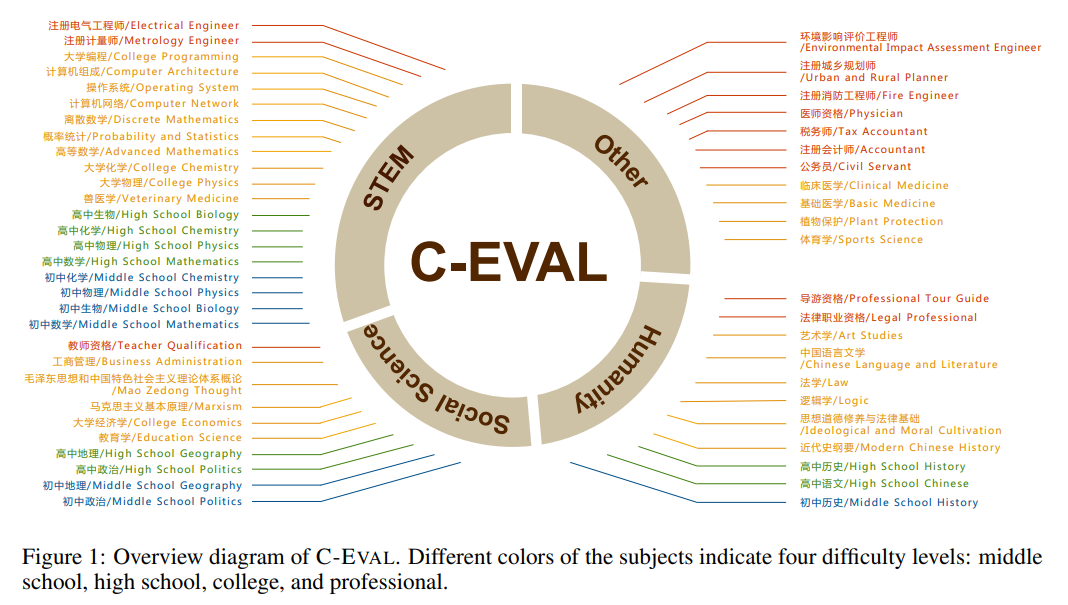
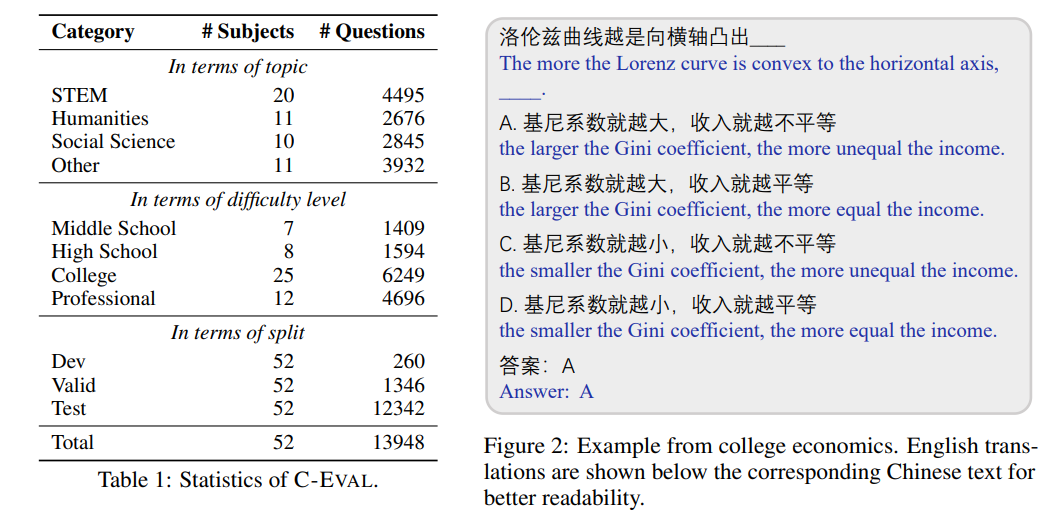
C-EVAL 涵盖四个难度级别,分别是初中、高中、大学与专业,数据主要来源于互联网中爬虫得到的试题与一部分作者收集的试题分享,由于爬虫得到的试题格式不统一,作者人工将试题数据做了统一,并将题目中涉及的公式都转化为了标准的 Latex 版本并纠正或删除了一部分错误试题。为了适应 Few-shot 的学习方式,在每个学科下作者还设置了 5 个带有答案的示例,一般的题目设计示例如下:
而为了利用大模型具有思维链(COT)提升解的质量的能力,作者还构建了一部分带有引导解释的数据如下图所示:

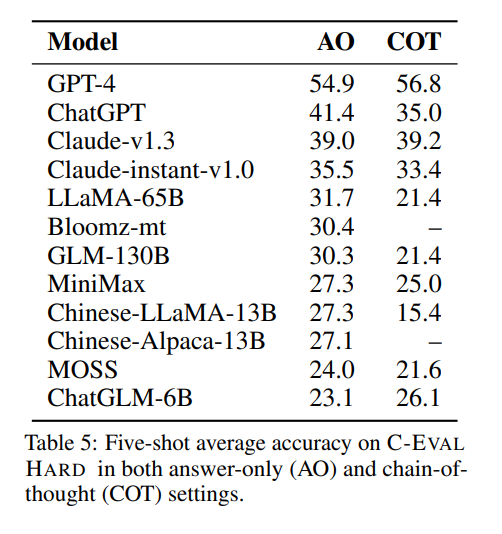
最后,为了给大模型“上点难度”,作者团队从 C-EVAL 中选择了具有挑战性的数学、物理和化学等 8 个学科的问题,组成了一个独立的 C-EVAL HARD 评测集,这些问题基本需要大学及以上的水平才能进行解决,并且思维与推理过程颇有难度,如下图所示:

而在 C-EVAL HARD 下,可以看到,所有模型的准确率都出现了显著下降,GPT-4 只能获得 54.9% 的准确率,而在一般问题下的国产模型榜首 MiniMax 在困难模式下准确率出现滑铁卢,暴跌 14 个点,几乎与随机选择持平,可以看到,当问题变得复杂与困难时,大模型的关键差别将被暴露出来,这事实上也在为国产模型敲响警钟——我们需要的不是一个随便瞎聊天的聊天机器人,大模型真正的潜力必然不在 Chat 上,而是在于它的判断推理理解能力,这才是智能真正的标准。
整个数据集的主页、大模型榜单等都被作者制作成网站方便其他用户评测与查看榜单:
论文题目:
C-EVAL: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models
论文链接:
https://arxiv.org/pdf/2305.08322.pdf
项目主页:
https://cevalbenchmark.com/index.html

欢迎大家加入我的这个”AIGC与GPT“知识星球,价格便宜,目前已有近130人
作为一个大厂算法工程师和机器学习技术博主,我希望这个星球可以:
【最全免费资源】免费chatgpt-API,最新AIGC和GPT相关pdf报告和手册。
【最专业算法知识】Transformer、RLHF方法、多模态解读及其论文分享。
【最新变现姿势】如何结合ChatGPT应用落地,各种可以作为副业的AIGC变现方式,打好这个信息差。
【最有趣AICG】ChatGPT+midjourney拍电影,制作壁纸,漫画等等有趣的AICG内 容分享。
一些截图: