任务 1 数据的基本处理
任务 1.1 根据附件 1“城市疫情”中的数据统计各城市自首次通报确诊病 例后至 6 月 30 日的每日累计确诊人数、累计治愈人数和累计死亡人数,将结果 保存为“task1_1.csv”,第一行为字段名,按城市、日期、累计确诊人数、累计 治愈人数、累计死亡人数的次序分别放在 A 列~E 列。在论文中给出实现方法的 相关描述,并列表给出武汉、深圳、保定每月 10、25 日的统计结果。
import numpy as np
import pandas as pdimport seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'SimHei' # 正常显示中文
plt.rcParams['axes.unicode_minus'] = Falseimport pyecharts
from pyecharts import *
from pyecharts.charts import Bar,Pie,Funnel,Scatter,Gauge,Page,WordCloud,Line
from pyecharts import options as opts# 任务1_1
data1 = pd.read_excel('附件1.xlsx',sheet_name='城市疫情')# 填充缺失的日期
date_range = pd.date_range(start=data1.日期.min(),end=data1.日期.max())
date = pd.DataFrame()
data1 = data1.set_index('日期')
for i in data1.城市.unique():a = data1[data1['城市']==i].reindex(index = date_range,)# 填充新增数据a.iloc[:,1:] = a.iloc[:,1:].fillna(0)# 填充城市数据a = a.fillna(i)a = a.reset_index()date = pd.concat((date,a))
date= date.rename(columns= {'index':'日期'})date[['累计确诊人数','累计治愈人数','累计死亡人数']] =date.groupby('城市').cumsum()
date.iloc[:,2:] = date.iloc[:,2:].astype(int)
date_ = date.loc[:,['城市','日期','累计确诊人数','累计治愈人数','累计死亡人数']].copy()
# 保存结果
date_.to_csv('task1_1.csv')data1:
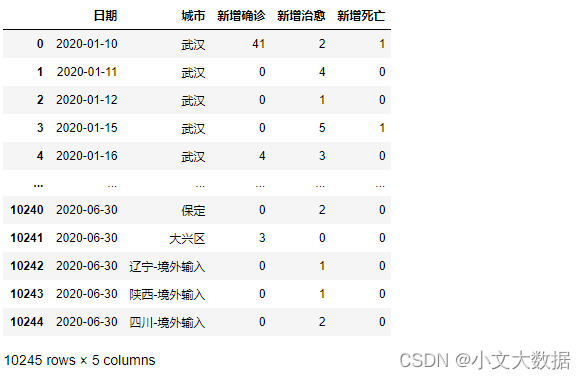
展示深圳、武汉、保定的每月10日、25日数据:
date_[date_['日期'].apply(lambda x: x.day==10 or x.day==25)].query("城市 == '深圳'")
date_[date_['日期'].apply(lambda x: x.day==10 or x.day==25)].query("城市 == '武汉'")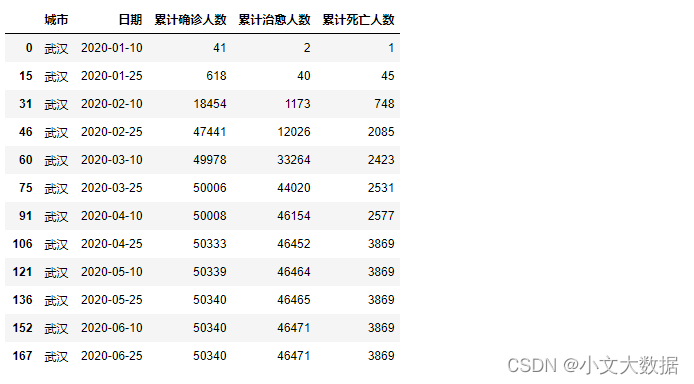
date_[date_['日期'].apply(lambda x: x.day==10 or x.day==25)].query("城市 == '保定'") 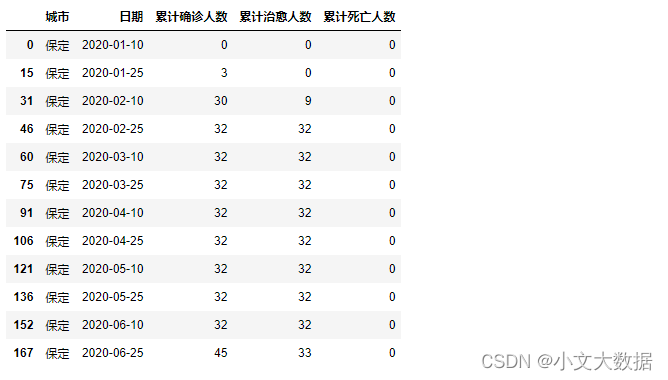
任务 1.2 根据任务 1.1 的结果,并结合附件 1“城市省份对照表”统计各省 级行政单位按日新增和累计数据,将结果保存为“task1_2.csv”,第一行为字段 名,按省份、日期、新增确诊人数、新增治愈人数、新增死亡人数、累计确诊人 数、累计治愈人数、累计死亡人数的次序分别放在 A 列~H 列。在论文中给出实 现方法的相关描述,并列表给出湖北、广东、河北每月 15 日的统计结果。
data1_sheng = pd.read_excel('附件1.xlsx',sheet_name='城市省份对照表')# 通过城市列进行联结
data1_2 = pd.merge(date, data1_sheng, on = '城市')
data1_2 = data1_2.reindex(columns = ['省份','日期','新增确诊','新增治愈','新增死亡','累计确诊人数','累计治愈人数','累计死亡人数'])
data1_2.columns = ['省份','日期','新增确诊人数','新增治愈人数','新增死亡人数','累计确诊人数','累计治愈人数','累计死亡人数']# 根据省份对该省份的城市数据进行汇总,得到该省份的每日新增确诊人数等。
data1_2 = data1_2.groupby(['省份','日期'],as_index =False).sum()
# 保存结果
data1_2.to_csv('task1_2.csv')data1_sheng:

展示广东、湖北、河北的每月15日数据:
data1_2[data1_2.日期.apply(lambda x:x.day == 15)].query("省份=='广东'")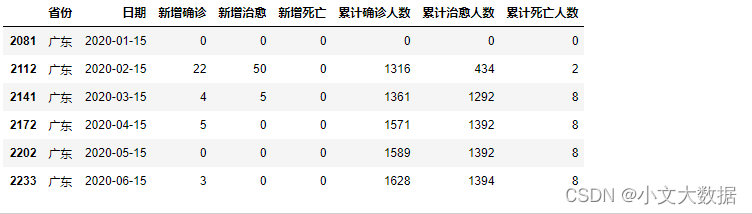
data1_2[data1_2.日期.apply(lambda x:x.day == 15)].query("省份=='湖北'")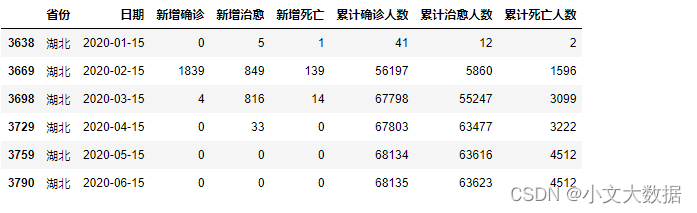
data1_2[data1_2.日期.apply(lambda x:x.day == 15)].query("省份=='河北'")
分析:
新增疫情数据分析:
plt.figure(figsize=(13,5))plt.subplot(131)
data1_2.groupby('日期').sum()['新增确诊人数'].plot(c = 'r')
plt.title('新增确诊')plt.subplot(132)
data1_2.groupby('日期').sum()['新增治愈人数'].plot(c = 'g')
plt.title('新增治愈')plt.subplot(133)
data1_2.groupby('日期').sum()['新增死亡人数'].plot(c = 'k')
plt.title('新增死亡')plt.show() 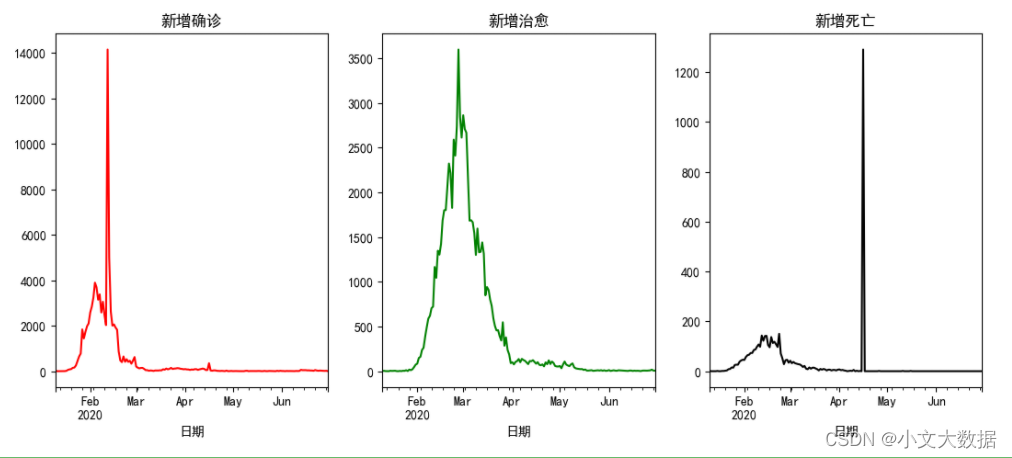
累计疫情数据分析:
plt.figure(figsize=(13,5))plt.subplot(131)
data1_2.groupby('日期').sum()['累计确诊人数'].plot(c = 'r')
plt.title('累计确诊')plt.subplot(132)
data1_2.groupby('日期').sum()['累计治愈人数'].plot(c = 'g')
plt.title('累计治愈')plt.subplot(133)
data1_2.groupby('日期').sum()['累计死亡人数'].plot(c = 'k')
plt.title('累计死亡')plt.show()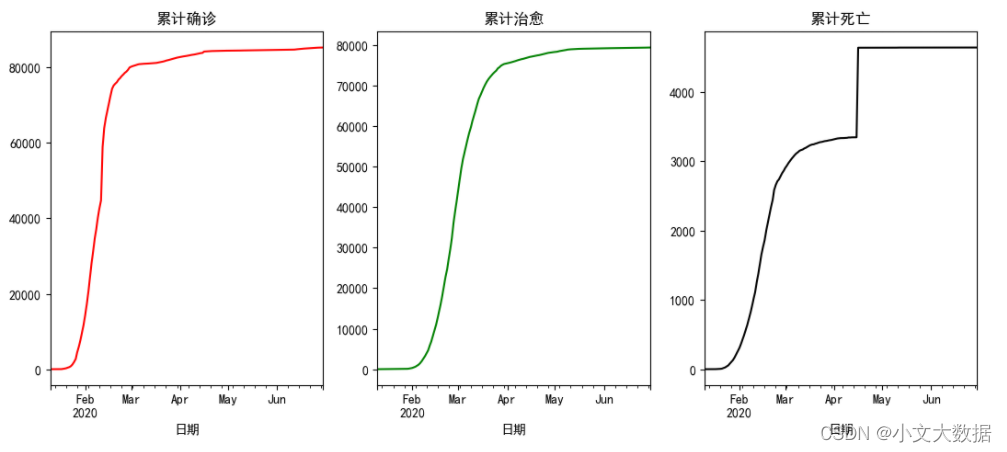
pyecharts绘图:
def plot_(data_name, color):d = data1_2.groupby('日期').sum()[data_name]d.index = d.index.map(lambda x:x.strftime('%Y/%m/%d'))line =Line()line.add_xaxis(xaxis_data=d.index.to_list())line.add_yaxis(series_name = f'{data_name}'[:-2],y_axis =d.to_list(),is_smooth =False,symbol_size = 10,linestyle_opts=opts.LineStyleOpts(color= color, width=4, type_="solid"),)line.set_series_opts(markpoint_opts = opts.MarkPointOpts(data = [opts.MarkPointItem(type_= ['max'], symbol_size = 70),opts.MarkPointItem(type_= ['min'])],),itemstyle_opts=opts.ItemStyleOpts(border_width=1, color=color))line.set_global_opts(title_opts=opts.TitleOpts(title = f'{data_name}随时间变化图'),xaxis_opts=opts.AxisOpts(name= '日期',type_='category', name_location='center',name_gap=25,),yaxis_opts=opts.AxisOpts(name= '人数',type_='value', name_location='end',name_gap=15,splitline_opts=opts.SplitLineOpts(is_show=True,linestyle_opts=opts.LineStyleOpts(opacity=1)),),tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),)return line.render_notebook()plot_('新增确诊人数', 'red')
# plot_('新增治愈人数', 'blue')
# plot_('新增死亡人数', 'blake')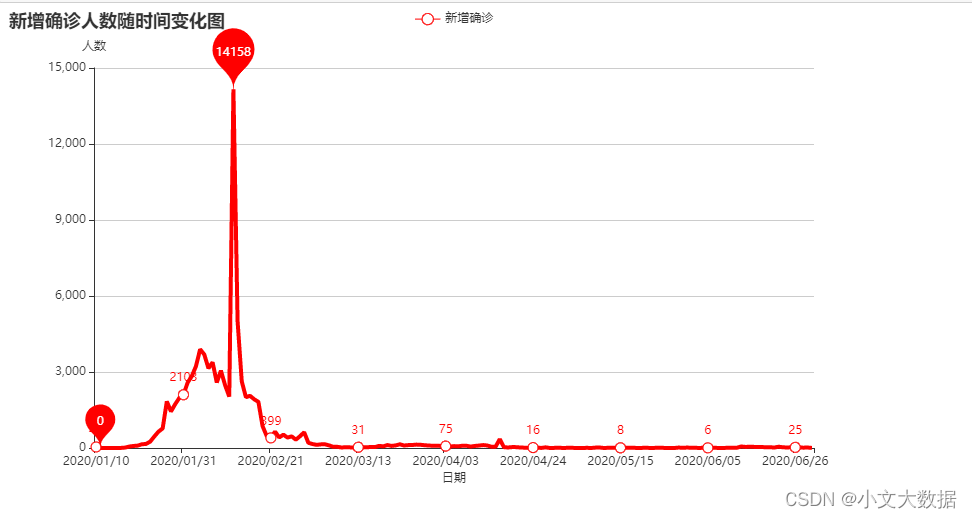





任务 1.3 根据任务 1.2 的结果,统计各省级行政单位每天新冠病人的住院 人数,将结果保存为“task1_3.csv”,第一行为字段名,按省份、日期、住院人 数的次序分别放在 A 列~C 列。在论文中给出实现方法的相关描述,并列表给出 湖北、广东、上海每月 20 日的统计结果。
假设确诊后迅速住院,定义住院人数为当天累计确诊人数减去累计治愈与累计死亡人数
data1_3= pd.DataFrame()
data1_3[['省份','日期']] = data1_2.iloc[:,:2]data1_3['住院人数'] = data1_2['累计确诊人数']-data1_2['累计治愈人数']-data1_2['累计死亡人数']
data1_3.to_csv('task1_3.csv',index=False)展示湖北、广东、上海每月 20 日的统计结果:
data1_3[data1_3.日期.apply(lambda x:x.day == 20)].query("省份=='湖北'")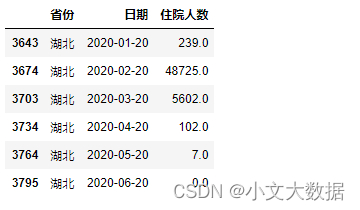
data1_3[data1_3.日期.apply(lambda x:x.day == 20)].query("省份=='广东'")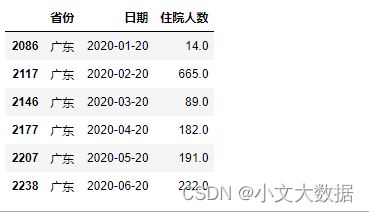
data1_3[data1_3.日期.apply(lambda x:x.day == 20)].query("省份=='上海'")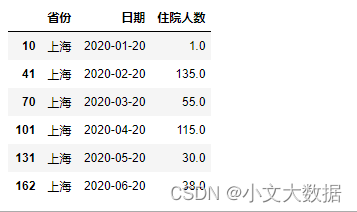
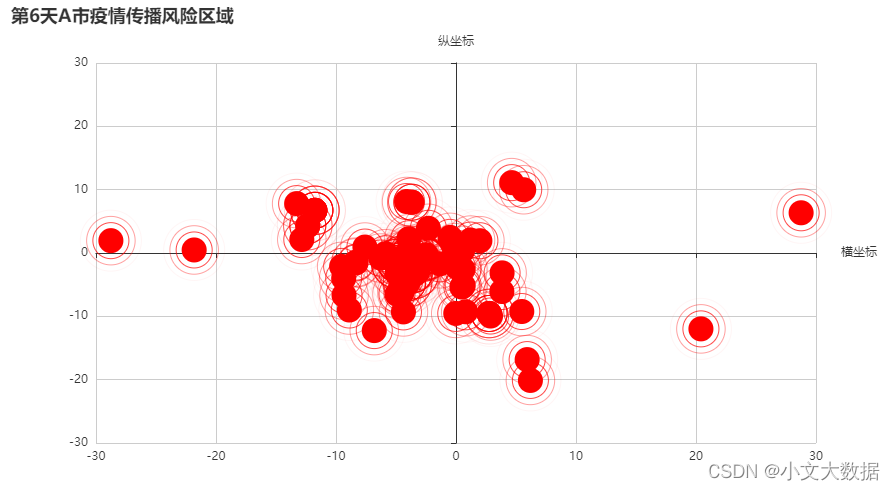
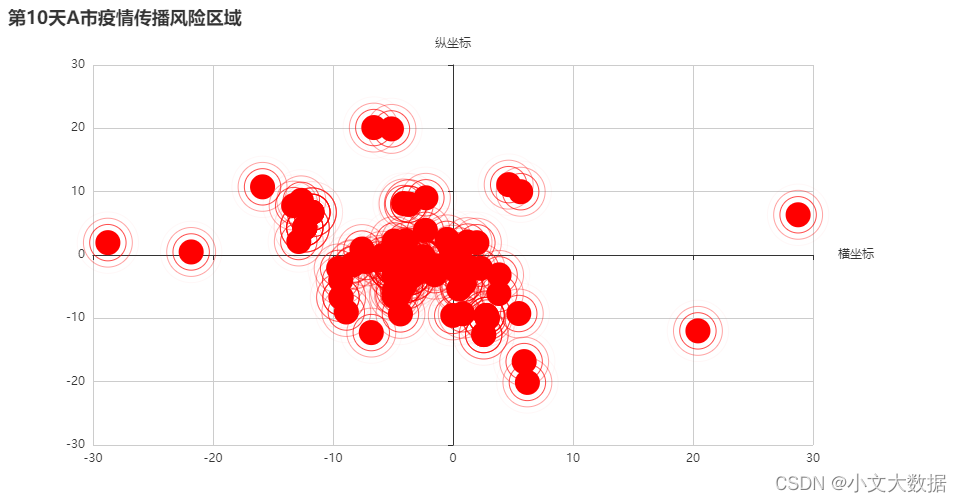
任务 1.4 假设新冠病人的传播半径为 1 km,根据附件 1“A 市涉疫场所” 在平面图中分别绘制该市第 6 天和第 10 天的疫情传播风险区域,并在论文中给 出分析和实现过程。
data3 = pd.read_excel('附件1.xlsx',sheet_name='A市涉疫场所分布')# 结合题意第6天的传播区域因为第8天时的总确诊
a1 = data3[data3['通报日期']<= 8]
# 第10天的传播区域因为第12天时的总确诊
a2 = data3[data3['通报日期']<= 12]# 常用全局参数配置封装
def global_opts(line,x_name = '',y_name = '',title = '',bottom = None,left = None,split_line = True):line.set_global_opts(title_opts=opts.TitleOpts(title = title),xaxis_opts=opts.AxisOpts(name= x_name,type_='value', name_location='end',name_gap=25,max_= 30,splitline_opts=opts.SplitLineOpts(is_show=split_line,linestyle_opts=opts.LineStyleOpts(opacity=1)),axistick_opts=opts.AxisTickOpts()),yaxis_opts=opts.AxisOpts(name= y_name,type_='value', name_location='end',name_gap=15,max_= 30,splitline_opts=opts.SplitLineOpts(is_show=split_line,linestyle_opts=opts.LineStyleOpts(opacity=1)),),legend_opts =opts.LegendOpts(type_ = 'scroll',pos_bottom=bottom, pos_left = left,orient = 'horizontal',align ='left',item_gap = 10,item_width = 25,item_height = 15,inactive_color = 'break'),tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),)data3:
from pyecharts.charts import EffectScatterscatter =EffectScatter()
scatter.add_xaxis(a1.iloc[:,2].tolist())
scatter.add_yaxis('',a1.iloc[:,3],itemstyle_opts=opts.ItemStyleOpts(color='red'),symbol_size = 25,label_opts=opts.LabelOpts(is_show=False),)
global_opts(scatter,'横坐标',y_name = '纵坐标',title = '第6天A市疫情传播风险区域')
scatter.render_notebook()
scatter =EffectScatter()
scatter.add_xaxis(a2.iloc[:,2].tolist())
scatter.add_yaxis('',a2.iloc[:,3],symbol_size = 25,itemstyle_opts=opts.ItemStyleOpts(color='red'),label_opts=opts.LabelOpts(is_show=False))
global_opts(scatter,'横坐标',y_name = '纵坐标',title = '第10天A市疫情传播风险区域')scatter.render_notebook()
任务 2 数字大屏设计
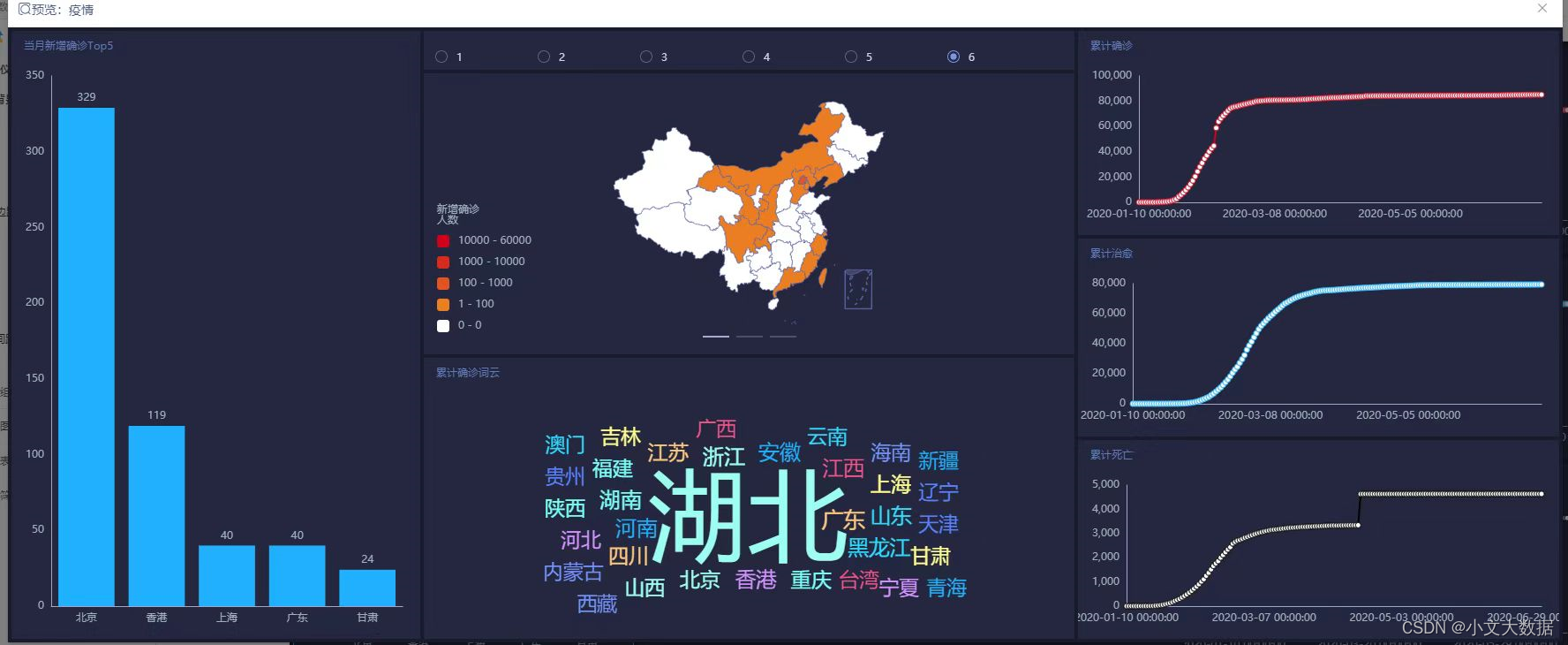
任务 2.1 设计数字大屏,展示国内新冠疫情汇总概要信息、时空变化情况、 重点关注区域等。在论文中附上截图,并给出相关的设计思路。
使用任务1_2结果数据data1_2进行绘制
任务 2.2 设计数字大屏,展现并分析国际疫情态势和发展变化。在论文中 附上截图,并给出相关的分析和设计思路。
处理前数据:
填补期间的缺失日期(分析结果可以发现其实没有,可以直接跳过)
data = pd.read_excel('附件1.xlsx',sheet_name='国际疫情'# 对国际疫情表参照任务一的方式进行日期填充
date = pd.DataFrame()
data = data.set_index('日期')
print(data)
for i in data.国家.unique():a = data[data['国家']==i]date_range = pd.date_range(start=a.index.min(),end=a.index.max())a = a.reindex(index = date_range,)print(a,a.isna().sum())a = a.fillna(method = 'ffill')a = a.fillna(method = 'bfill')print(a,a.isna().sum(),'+++++')a = a.reset_index()date = pd.concat((date,a))
date= date.rename(columns= {'index':'日期'})处理后数据:
获取‘新增’数据:
# 初始化
data = pd.DataFrame()
for i in date.国家.unique():_ =date[date['国家']== i].copy()_[['新增确诊','新增治愈','新增死亡']] = pd.concat((_.iloc[0:1,2:],_.iloc[:,2:].diff().iloc[1:,:]))data = pd.concat((data,_))# 保存数据用于可视化大屏绘制
data.to_excel(r'data_guoji.xlsx')最终数据:

大屏未做,可参考国内城市大屏
任务 3 国际疫情的发展分析
任务 3.1 根据附件 1“国际疫情”中的数据,对印度、伊朗、意大利、加 拿大、秘鲁、南非在各个时间段中所处的疫情发展阶段进行划分,并在论文中给 出划分的依据和结果。
未做
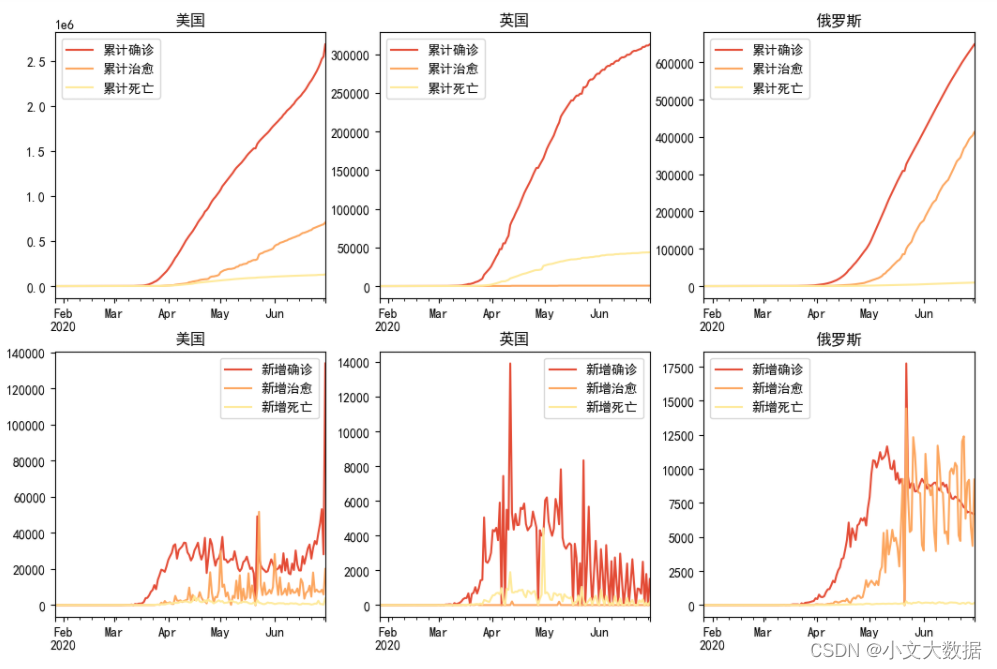
任务 3.2 根据附件 2 中的信息,分析美国、英国、俄罗斯 3 个国家推出的 疫情防控措施对本国疫情变化情况的影响。
data['日期'] = pd.to_datetime(data['日期'])
with sns.color_palette('RdYlGn'):fig, axes = plt.subplots(2, 3, figsize = (14,8))for num, country in enumerate(['美国', '英国', '俄罗斯']):d_ = data.query(f"国家 == '{country}'").set_index('日期')d_[['累计确诊', '累计治愈', '累计死亡']].plot(ax = axes[0][num])axes[0][num].set_title(country)axes[0][num].set_xlabel(None)d_[['新增确诊', '新增治愈', '新增死亡']].plot(ax = axes[1][num])axes[1][num].set_title(country)axes[1][num].set_xlabel(None)plt.subplots_adjust(0.2,0.1)博客里三个泰迪杯分析赛完整项目资料可加微信:gjwtxp 获取(20yuan)