复杂事件处理(CEP)是一种对事件流进行分析的技术,它能够识别出数据流中的事件序列是否符合特定的模式,并允许用户对这些模式进行处理。Flink CEP 是 CEP 在 Apache Flink 中的具体实现,是 Apache Flink 的一个库,使用户可以在 Flink 的流处理引擎上进行复杂事件的处理。
该技术广泛应用于金融风控、网络安全、物流跟踪和电商推荐系统等领域。比如在风险用户识别中,CEP可以读取并分析客户行为日志,将 5 分钟内转账次数超过 10 次且金额大于 10000 的客户识别为异常用户。
而在袋鼠云实时开发平台上,有更加高效的功能支持,允许通过Flink SQL作业动态更新Flink CEP作业。本文将通过产品Demo演示,展示如何在实时开发平台中构建一个灵活加载最新规则的 Flink CEP 作业,处理来自上游 Kafka 的数据流,让大家更加直观地了解这一整套流程及其优势所在。
一、FLink CEP简介
1、CEP 的核心概念
模式(Pattern):这是定义复杂事件的规则,它由一系列简单的事件组成,这些事件之间通过一定的逻辑关系相连。
事件流(Event Stream):这是实时流入系统的数据流,CEP 会在这些流上寻找匹配的模式。
匹配(Match):当事件流中的事件序列符合定义的模式时,就会产生一个匹配。
2、Flink CEP 的使用流程
定义模式:使用 Flink CEP 的 API 定义感兴趣的事件模式。
应用模式:将定义的模式应用到事件流上,Flink CEP 会在流上寻找匹配该模式的事件序列。
处理匹配事件:对找到的匹配事件进行处理,执行相应的业务逻辑。
Flink CEP 的优势在于能够处理高吞吐量、低延迟的实时数据流,并且提供了丰富的 API 来定义复杂的事件模式。同时,Flink CEP 也支持基于事件时间的处理,允许用户处理乱序到达的数据。
3、动态FLink CEP 背景介绍
在风险控制或者模式匹配等场景下,用户经常会想要在模式仍然能够提供服务的情况下,改变事件需要匹配的模式。在目前的 Flink CEP 中,一个 CEP 算子有一个固定的 CEP 模式,不支持改变。因此,为了达到上述目的,用户必须重启 Flink 作业,并等待相对较长的更新时间。
另一种常见情况是,一个事件流需要与多个模式匹配。虽然当前的 Flink CEP 不支持在一个 CEP 运算符中匹配多个模式,但用户必须为每个模式设置一个 Flink 作业或一个运算符。这可能会浪费内存和计算资源。为此我们支持了动态加载规则,支持任务不重启Flink 作用动态的匹配规则。
4、FLink CEP 的应用场景
Flink CEP 的应用场景包括:
风险控制:例如,检测用户行为模式,如果发现异常行为(如短时间内多次登录失败),则可以触发相应的风险控制措施。
用户画像:通过分析用户的行为事件流,可以构建用户画像,进而实现精准营销。
运维监控:在企业服务的运维管理中,CEP 可以用来配置复杂的监控规则,以实现对服务状态的实时监控。
二、ELink 动态CEP方案
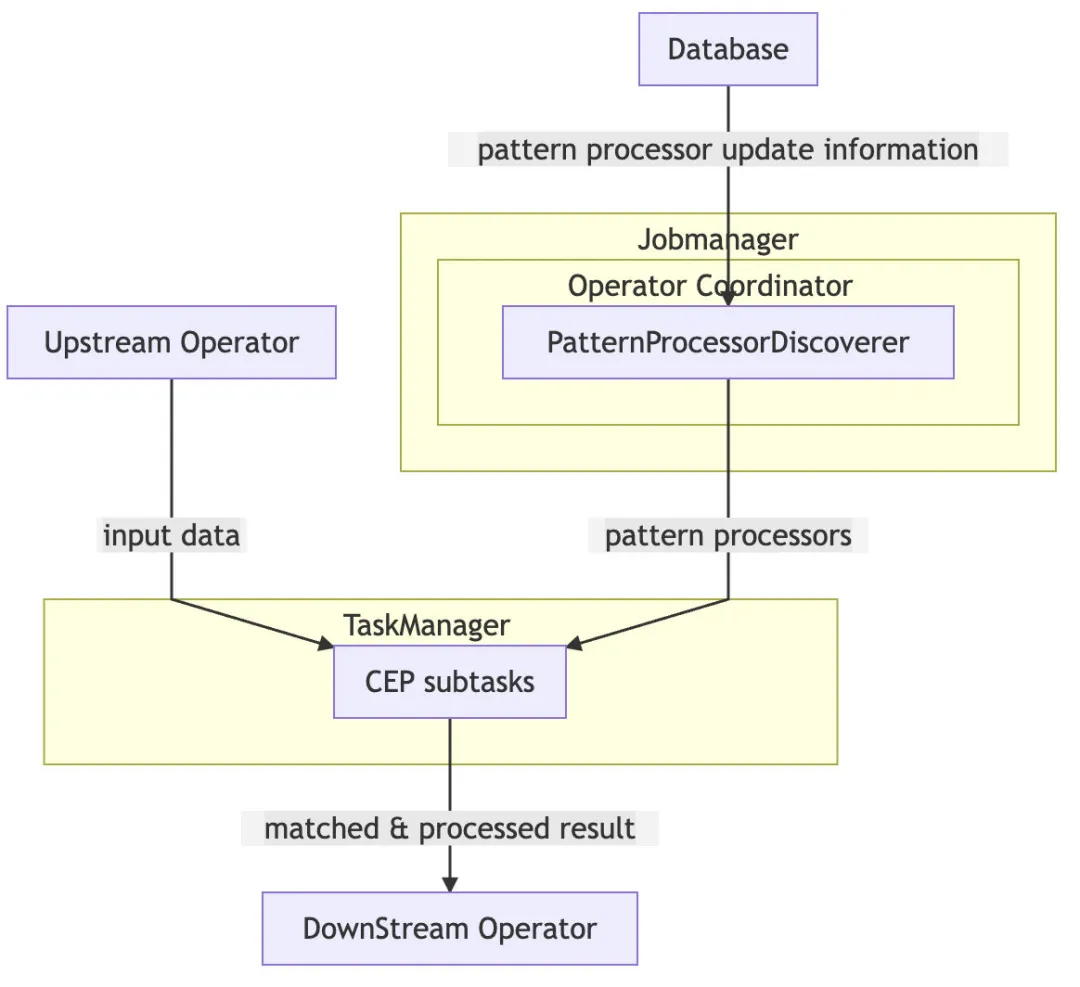
PatternProcessorDiscoverer 在 Jobmanager上定期抓取规则更新信息并将规则更新信息推送给 taskmanager 上的 CEP 算子。CEP 算子获取到更新的规则后更新 NFA(非确定有限自动机)。
1、PatternProcessorDiscoverer
PatternProcessorDiscoverer内部维护一个定时线程,通过定时线程定期轮询 database 获取规则信息。如果感知到规则变更则会将规则变更信息通知给 PatternProcessorManager。
2、DynamicCepOperatorCoordinator
DynamicCepOperatorCoordinator实现了 PatternProcessorManager和 OperatorCoordinator接口。 DynamicCepOperatorCoordinator接受到来自 PatternProcessorManager的变更信息后会将变更信息通过UpdatePatternProcessorEvent发送给每一个 DynamicCep 算子。
3、DynamicCepOperator
DynamicCepOperator实现了OperatorEventHandler接口,接收来自DynamicCepOperatorCoordinator 的UpdatePatternProcessorEvent。对于每个UpdatePatternProcessorEvent,DynamicCepOperator会利用规则处理器将 JSON 或者 SQL 表示的规则转为Pattern,再由Pattern获得 NFA。多个Pattern 的情况下会生成多个 NFA。NFA 会与PatternProcessFunction一起被保存到 Map 中。
当上游算子的数据发送到DynamicCepOperator时,同一条数据会被多个 NFA 处理,当某一个NFA match到数据之后,会将数据发送给对应的PatternProcessFunction处理,被PatternProcessFunction处理完的数据则会被发送给下游算子。这里需要注意的是:当有多个规则与PatternProcessFunction 时,不同的PatternProcessFunction处理完的数据结构需要保持一致,因为数据都会统一发送到下游算子,下游算子能接受的数据结构是固定的。
4、PatternProcessFunction
PatternProcessFunction的作用是处理匹配到的查询。PatternProcessFunction会在jobmanager中初始化,然后通过序列化后发送到taskmanager中,因此需要注意下jobmanager和中taskmanager加载到的PatternProcessFunction来自同一个依赖包,否则会有序列化问题。目前不支持对包含了PatternProcessFunction的jar进行热加载,所以如果需要更换新jar来增加PatternProcessFunction,只能通过重启任务实现。
对于使用 Flink Dynamic CEP on SQL 模式:还需要提供一种手段将包含了 PatternProcessFunction的 jar 提交到jm和tm上,数栈上可以通过ADD JAR语法实现。
三、FLink 动态CEP DEMO演示
1、规则说明
此规则定义了一个简单的流程,它有三个节点,每个节点都基于 action 的值来决定是否消费事件。如果 action 的值依次为 0、1、2,那么事件将依次通过 start、middle、end 节点。如果 action 的值不满足当前节点的条件,流程将跳至下一个节点。这个规则没有定义时间窗口,并且匹配到事件模式后不会跳过任何事件。
2、定义匹配规则
在Mysql 中进行SQL 编辑页面创建一张数据表,命名为 cep_demo,四个字段 id、version、pattern、function、type、is_deleted。id 和 version 用于标名唯一的版本和 id 信息,pattern 代表了序列化后的 Pattern Stream,function 用于指代规则 match 后执行的 function。规则 match 到数据后,数据会由该 function 处理然后发送到下游算子。type 用于代表规则表示类型。如果以 SQL 表示规则,则填 SQL;如果以 JSON 表示规则,则填写 JSON。然后编写 FlinkSQL 作业并提交到任务调度中运行。
{
"afterMatchStrategy": {
"type": "NO_SKIP"},
"edges": [
{"source": "middle","target": "end","type": "STRICT"},{"source": "start","target": "middle","type": "SKIP_TILL_NEXT"}],
"name": "end",
"nodes": [
{"condition": {"expression": "action == 2","type": "AVIATOR"},"name": "end","quantifier": {"consumingStrategy": "SKIP_TILL_NEXT","properties": ["SINGLE"]},"type": "ATOMIC"},{"condition": {"expression": "action == 1","type": "AVIATOR"},"name": "middle","quantifier": {"consumingStrategy": "SKIP_TILL_NEXT","properties": ["SINGLE"]},"type": "ATOMIC"},{"condition": {"expression": "action == 0","type": "AVIATOR"},"name": "start","quantifier": {"consumingStrategy": "SKIP_TILL_NEXT","properties": ["SINGLE"]},"type": "ATOMIC"}],
"quantifier": {
"consumingStrategy": "SKIP_TILL_NEXT","properties": ["SINGLE"]},
"type": "COMPOSITE",
"version": 1,
"window": null
}
3、数据开发编写FlinkSQL
FlinkSQL:
ADD JAR WITH /data/sftp/11_dynamic-cep-jar-1_dynamic-cep-jar-1.0-SNAPSHOT.jar AS functions.jar;
CREATE TABLE source (
id INT,name VARCHAR,productionId INT,action INT,eventTime BIGINT,procTime AS PROCTIME()) WITH (
'connector' = 'kafka-x','topic' = 'stream','properties.group.id' = 'stream','scan.startup.mode' = 'latest-offset','properties.bootstrap.servers' = 'localhost:9092','format' = 'json');
CREATE TABLE sink
(
id int) WITH (
'connector' = 'mysql-x', 'url' = 'jdbc:mysql://localhost:3306/stream', 'schema-name' = 'stream', 'table-name' = 'stream_cep_001', 'username' = 'drpeco', 'password' = '******', 'sink.buffer-flush.max-rows' = '1024', 'sink.buffer-flush.interval' = '10000', 'sink.all-replace' = 'true','sink.parallelism' = '1');INSERT INTO sink
SELECT id_total as id
FROM source
DYNAMIC MATCH_RECOGNIZE (PARTITION BY productionId ORDER BY procTime OUTPUT (id_total int) WITH_PATTERN ('tableName' = 'dynamic_cep', 'user' = 'drpeco', 'password' = '******', 'driver' = 'com.mysql.cj.jdbc.Driver', 'jdbcUrl' = 'jdbc:mysql://localhost:3306/cep','jdbcIntervalMillis' = '1000')) AS T;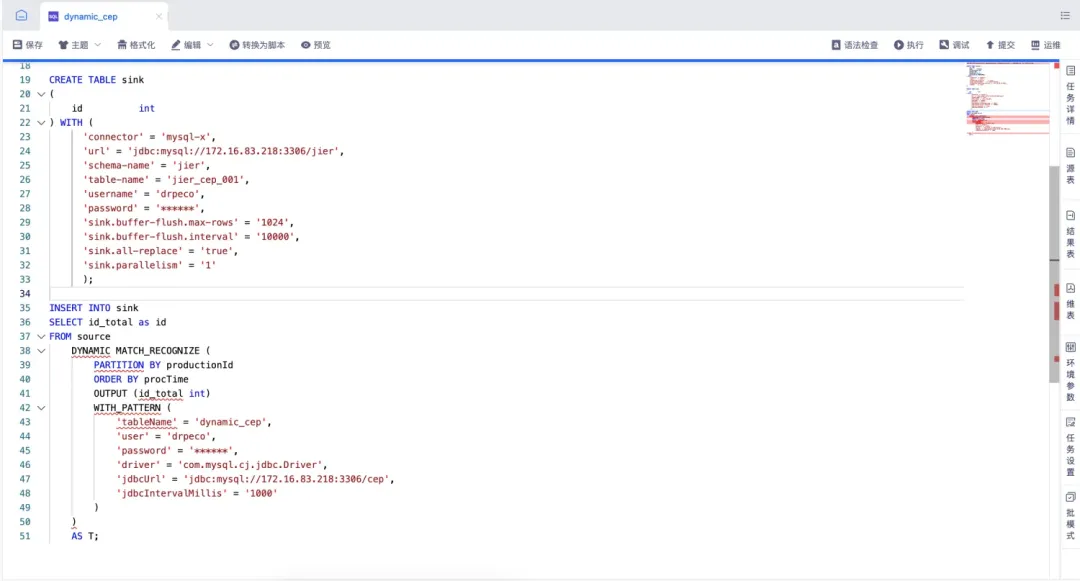
4、提交调度运行
FlinkSQL任务语法检查成功后,提交调度任务运行中状态时,kafka 源表Topic 中依次打入Demo数据。
{
"id": 1,"name" : "middle","productionId" : 11,"action" : 0,"eventTime" : 1};
{
"id": 2,"name" : "middle","productionId" : 11,"action" : 1,"eventTime" : 1};
{
"id": 3,"name" : "middle","productionId" : 11,"action" : 2,"eventTime" : 1}
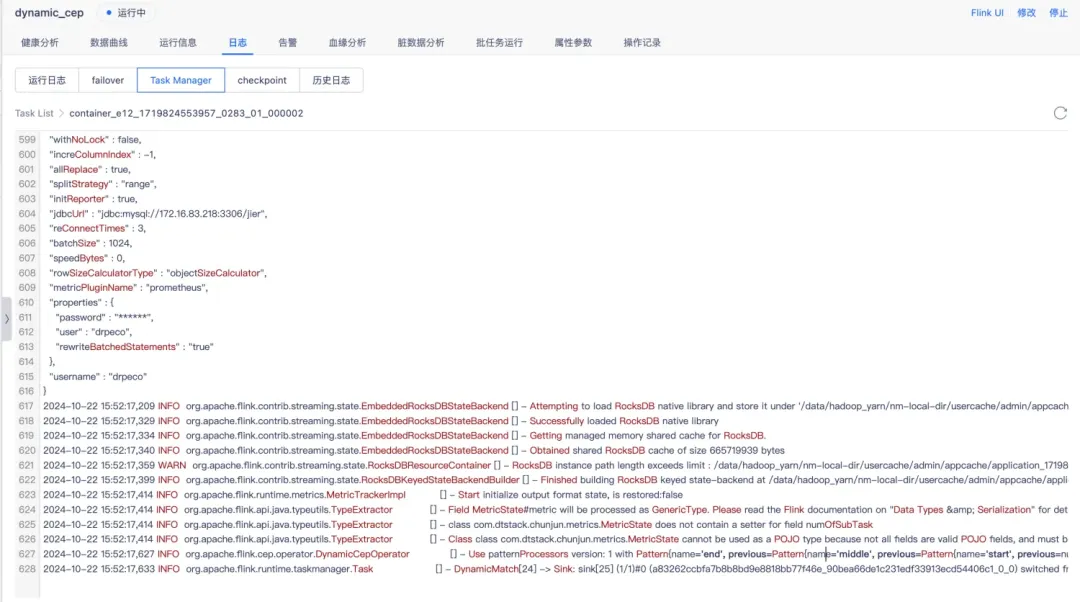
接下来我们检查匹配的结果,action 的值依次为 0、1、2。Jar包中的function为将匹配到的数据,id字段sum相加得出最后id_totle值作为输出条件。最后输出的结果 id_total 值为 6。

此时在任务不停止的状态下,直接操作Mysql数据库修改CEP Json 将规则匹配条件改为 action 的值依次为 0、1、3 为匹配条件。再次打入与上次同样的 kafka数据,此时匹配失败则不输出id_total值。
四、总结
本文和大家分享了什么是CEP,Flink CEP的原理与使用方法,并介绍了如何通过Flink SQL作业动态更新Flink CEP作业,可以说是干货满满。
《数据资产管理白皮书》下载地址:https://www.dtstack.com/resources/1073/?src=szsm
《行业指标体系白皮书》下载地址:https://www.dtstack.com/resources/1057/?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001/?src=szsm
《数栈V6.0产品白皮书》下载地址:https://www.dtstack.com/resources/1004/?src=szsm
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szsm
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术群」,交流最新开源技术信息,群号码:30537511,项目地址:https://github.com/DTStack