文章目录
- 一、基于统计的方法
- 1.1、标准差
- 1.2、箱线图
- 1.3、Z-Score法
- 二、基于机器学习算法的方法
- 2.1、K-NN
- 2.2、孤立森林
- 三、基于密度的方法
- 3.1、LOF
- 3.2、DBSCAN密度聚类
时间序列相关参考文章:
时间序列预测算法—ARIMA
时间序列预测算法—Prophet
时间序列分类任务—tsfresh
python时间序列处理
有季节效应的非平稳序列分析
时间序列异常值检测方法
时间序列异常值处理方法
一、基于统计的方法
1.1、标准差
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 负号正常显示data = pd.read_excel('data.xlsx')
mean = data['电量'].mean()
std_dev = data['电量'].std()
num_std_dev = 2
outliers = data[np.abs(data['电量'] - mean) > num_std_dev * std_dev]plt.figure(figsize=(10, 6))
plt.plot(data.date,data['电量'], label='Forecast Data', color='blue', alpha=0.7)
plt.scatter(outliers.date, outliers['电量'], color='red', label='Outliers')
plt.axhline(mean, color='green', linestyle='--', label='Mean')
plt.axhline(mean + num_std_dev * std_dev, color='orange', linestyle='--', label='Upper Bound')
plt.axhline(mean - num_std_dev * std_dev, color='orange', linestyle='--', label='Lower Bound')plt.title('用电量异常值检测', fontsize=15)
plt.xlabel('日期', fontsize=12)
plt.ylabel('电量', fontsize=12)
plt.legend()
plt.grid(True)
plt.show()

1.2、箱线图
计算步骤:
Q1(上四分位数):数据集中所有数值由小到大排列后,位于25%位置的数值。
Q3(下四分位数):数据集中所有数值由小到大排列后,位于75%位置的数值。
计算四分位距(IQR):IQR = Q3 - Q1
确定异常值范围:
- 上界= Q3 + 1.5 * IQR
- 下界= Q1 - 1.5 * IQR
判断异常值:低于下界或高于上界的数值。
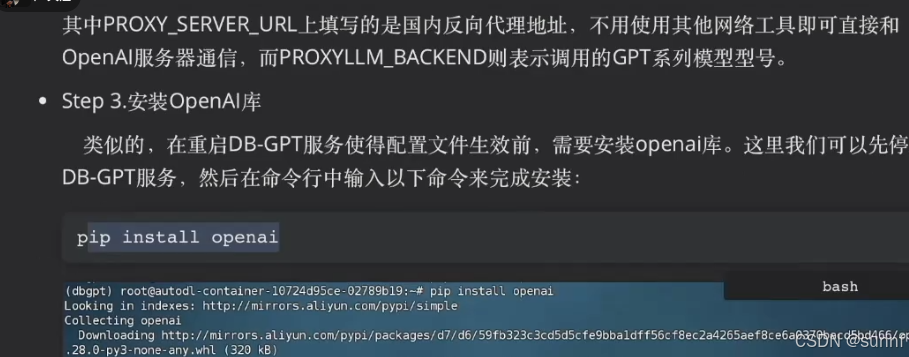
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 负号正常显示data = pd.read_excel('data.xlsx')# 计算异常值
Q1 = data['电量'].quantile(0.25)
Q3 = data['电量'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR #下四分位数
upper_bound = Q3 + 1.5 * IQR #上四分位数# 标识异常值
data['Outlier'] = ((data['电量'] < lower_bound) | (data['电量'] > upper_bound))
outliers = data[data['Outlier']] # 标注异常值#可视化
plt.figure(figsize=(12, 6))
sns.lineplot(data=data, x=data.date, y='电量', label='电量', color='blue')
plt.scatter(outliers.date, outliers['电量'], color='red', label='outlier')plt.title('箱体图异常值检测', fontsize=15)
plt.xlabel('date', fontsize=12)
plt.ylabel('电量', fontsize=12)
plt.legend()
plt.show()

1.3、Z-Score法
Z-Score(标准分数)是一种衡量数据点相对于其总体或样本平均值的偏离程度的统计方法。它表示数据点与均值之间的差异,并以标准差为单位来衡量。Z-Score的计算公式如下:

import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import statsdata = pd.read_excel('data.xlsx')
# 如果Z-Score大于3或小于-3,通常被认为是异常值
data['Z_Score'] = stats.zscore(data['电量'])# 定义离群点
data['Outlier_Z'] = data['Z_Score'].abs() > 3
plt.figure(figsize=(12, 6))# 绘制forecast值的折线图
sns.lineplot(data=data, x=data.date, y='电量', label='电量', color='blue')# 标注离群点
outliers = data[data['Outlier_Z']]
plt.scatter(outliers.date, outliers['电量'], color='red', label='Outliers (Z > 3)')plt.title('Z-Score 异常值检测', fontsize=15)
plt.xlabel('date', fontsize=12)
plt.ylabel('电量', fontsize=12)
plt.legend()
plt.show()

二、基于机器学习算法的方法
2.1、K-NN
k近邻算法的思想可参考之前的文章:K近邻算法
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.neighbors import NearestNeighbors
import seaborn as snsdata = pd.read_excel('data.xlsx')# data['date'] = pd.to_datetime(data['date'])
data = data.sort_values(by='date')n_neighbors = 5 # 设置 K 值
knn_smaller = NearestNeighbors(n_neighbors=n_neighbors)
knn_smaller.fit(data[['电量']])distances_smaller, _ = knn_smaller.kneighbors(data[['电量']]) # 计算每个点到其邻居的距离
mean_distance_smaller = np.mean(distances_smaller, axis=1) # 计算每个点到其邻居的平均距离# 计算距离的平均值和标准差
mean_distance_mean = np.mean(mean_distance_smaller)
mean_distance_std = np.std(mean_distance_smaller)# 离群点检测:使用均值和标准差,判断大于某个阈值的数据为离群点
outlier_threshold = mean_distance_mean + 2 * mean_distance_std # 使用2倍标准差作为阈值
outlier_indices_smaller = np.where(mean_distance_smaller > outlier_threshold)[0]# 在数据框中标记离群点
data['Outlier_KNN'] = False
data.loc[outlier_indices_smaller, 'Outlier_KNN'] = True# 绘制图表
plt.figure(figsize=(12, 6))
sns.lineplot(data=data, x='date', y='电量', label='电量', color='blue') # 绘制电量的折线图# 标注离群点
outliers_knn_smaller = data[data['Outlier_KNN']]
plt.scatter(outliers_knn_smaller['date'], outliers_knn_smaller['电量'], color='red', label='Outliers (KNN, Smaller K)')# 设置标题和标签
plt.title('K近邻异常检测', fontsize=15, fontweight='bold')
plt.xlabel('date', fontsize=12)
plt.ylabel('电量', fontsize=12)
plt.legend()
plt.show()
2.2、孤立森林
孤立森林算法的核心思想是通过随机分割数据将异常值孤立开来。
具体来说,孤立森林通过以下几步来识别异常值:
1、构建树结构:我们将数据看作一个“树”,而树的每一层都是通过随机选择一个特征(比如电压、功率等)并随机选择一个分割点来将数据分成两部分。这样,我们可以从根节点开始,逐层对数据进行分割,直到最终每个数据点都被“孤立”在一片区域中。
2、树的“深度”:每个数据点在被孤立时,所经历的分割次数(树的深度)是非常关键的。如果一个数据点在很多分割后才被孤立,那么这个数据点通常是“正常”的;相反,如果数据点很容易被孤立,即分割层数很少,那么它很可能是一个“异常值”。
3、构建多个树:为了提高算法的鲁棒性(即处理不同类型数据的能力),孤立森林并不是只构建一棵树,而是会构建多棵树(森林)。每棵树都是随机选择不同的特征和分割点来训练的。
4、异常值的判定:对于每个数据点,算法会计算它在森林中每棵树的“孤立深度”,然后将这些孤立深度综合起来,得出一个最终的“异常评分”。分数越低,说明这个点越容易被孤立,越有可能是异常值。
举个例子:假设我们有一组学生的身高数据,正常的身高大多在150-180厘米之间,但有一个学生的身高是220厘米。孤立森林算法通过随机选择身高的某些范围来分割数据,发现大部分学生的身高在某个区域内分布很密集,而这个220厘米的学生会在很早的分割阶段就被孤立出来。于是,它就会被认为是一个异常值。
- 高效:孤立森林只需要少量的数据即可进行训练,不像一些其他算法需要复杂的计算。
- 适用于大数据:由于它基于树结构,处理大规模数据时表现很优秀。
- 无需标签:孤立森林是无监督算法,不需要事先标注哪些是正常值,哪些是异常值。
from sklearn.ensemble import IsolationForest
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsnew_data = pd.read_excel('data.xlsx')
# 设置孤立森林参数
iso_forest = IsolationForest(n_estimators=100, contamination='auto', random_state=42) # 可调整参数
#n_estimators=100 是 Isolation Forest 算法中的一个超参数,它表示 森林中树的数量
#如果对数据的异常值比例有所了解,可以调整 contamination 参数。如:知道数据中大约有5%的异常值,可以设置 contamination=0.05,而不是使用 'auto'。
iso_labels = iso_forest.fit_predict(new_data[['电量']]) # 使用孤立森林模型
new_data['Outlier_IsolationForest'] = (iso_labels == -1) # 标记离群点(在孤立森林中,-1标签表示离群点)plt.figure(figsize=(12, 6))
sns.lineplot(data=new_data, x=new_data.date, y='电量', label='电量', color='blue') # 绘制forecast值的折线图# 标注离群点
outliers_iso_forest = new_data[new_data['Outlier_IsolationForest']]
plt.scatter(outliers_iso_forest.date, outliers_iso_forest['电量'], color='red', label='Outliers (Isolation Forest)')# 设置标题和标签
plt.title('孤立森林异常值检测', fontsize=15, fontweight='bold')
plt.xlabel('date', fontsize=12)
plt.ylabel('电量', fontsize=12)
plt.legend()
plt.show()
总结:孤立森林算法通过随机分割数据,尽可能早地将异常点孤立出来,最后根据这些点被孤立的深度来判断它们是否异常。它是一种简单、高效且适用于大数据的异常值检测方法。
三、基于密度的方法
3.1、LOF
LOF(局部离群因子,Local Outlier Factor)是一种用于异常检测的算法,它的主要作用是帮助我们找到那些在数据中表现得很“不同”或“离群”的数据点。简单来说,LOF可以帮助我们识别出哪些数据点可能是错误的、特殊的或不常见的。
LOF算法的思路:LOF算法通过局部密度来判断数据点是否异常。它的基本想法是:一个数据点如果和周围点比较“远”,而且密度较低,那么它就有可能是一个异常点。
LOF算法的工作过程可以分为以下几个步骤:
1、定义“密度”
首先,LOF需要计算每个数据点的“局部密度”。局部密度表示该点的邻近区域内的点的分布情况。如果某个数据点周围的点很密集(例如很多点都聚集在一起),我们就说这个点的局部密度较高;反之,如果周围点很稀疏,局部密度就较低。
2、计算“可达距离”
为了衡量一个数据点与它的邻居之间的距离,LOF引入了一个叫做“可达距离”的概念。可达距离不仅仅看两个点之间的直线距离,还考虑到该点周围邻居的密度。如果一个数据点的邻居非常密集,那么这个点到邻居的可达距离就比较短。这样,LOF算法就能在更“稠密”的区域找到异常点。
3、计算“局部离群因子”
LOF的核心是计算每个点的“局部离群因子”(Local Outlier Factor)。LOF的值通过比较数据点的局部密度与其邻居的局部密度来得到。如果一个数据点的局部密度显著低于它的邻居的局部密度,那么它的LOF值就较高,说明它是一个异常点。反之,如果一个数据点的局部密度与邻居差不多,它的LOF值就接近1,说明它是正常的。
from sklearn.neighbors import LocalOutlierFactor
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 负号正常显示new_data = pd.read_excel('data.xlsx')
lof = LocalOutlierFactor(n_neighbors=10) # 可以调整n_neighbors的值,来调整对数据的敏感度lof_labels = lof.fit_predict(new_data[['电量']]) # 使用LoF模型
lof_scores = -lof.negative_outlier_factor_ # LoF分数(负数,越小越异常)new_data['Outlier_LoF'] = (lof_labels == -1) # 标记离群点plt.figure(figsize=(12, 6))
sns.lineplot(data=new_data, x=new_data.date, y='电量', label='电量', color='blue')outliers_lof = new_data[new_data['Outlier_LoF']] # 标注离群点
plt.scatter(outliers_lof.date, outliers_lof['电量'], color='red', label='Outliers (LoF)')# 设置标题和标签
plt.title('LoF异常值检测', fontsize=15, fontweight='bold')
plt.xlabel('date', fontsize=12)
plt.ylabel('电量', fontsize=12)
plt.legend()
plt.show()

LOF算法的优缺点:
优点:
- 不依赖全局密度:LOF算法考虑的是局部密度,因此它能发现一些在全局层面上看不出来的异常点。
- 适用于复杂数据:它特别适用于那些数据分布复杂、密度不均匀的场景。
缺点:
- 计算复杂度高:LOF需要计算每个点与其他点的距离,尤其是数据量较大时,计算开销较高。
- 参数选择敏感:LOF算法需要设置邻居数量(通常是K),如果K选择不合适,可能影响异常点检测的准确性。
3.2、DBSCAN密度聚类
DBSCAN算法的思想可参考之前的文章:聚类算法
eps(邻域半径)值决定了每个点的邻域范围。eps值过小,很多点无法找到足够的邻居,导致它们被判定为离群点。
方法:可以通过可视化k-distance图来选择一个合理的eps值。k-distance图会显示每个点到其k个邻居的距离,通常选择k为min_samples值。例如,你可以计算每个点与其最近min_samples个点的距离,并绘制出图像,寻找距离急剧上升的点,这个点的距离对应的eps值是较好的选择。
观察k-distance图的“拐点”,通常拐点处的距离值是eps的一个合适选取。
from sklearn.neighbors import NearestNeighbors
import numpy as np# 计算k个邻居的距离
neighbors = NearestNeighbors(n_neighbors=20).fit(data[['电量']])
distances, indices = neighbors.kneighbors(data[['电量']])# 排序并绘制k-distance图
distances = np.sort(distances[:, -1], axis=0)
plt.plot(distances)
plt.title('k-distance plot')
plt.xlabel('Data Points')
plt.ylabel('Distance')
plt.show()

import pandas as pd
from sklearn.cluster import DBSCAN
import matplotlib.pyplot as plt
import seaborn as sns# 读取数据
data = pd.read_excel('data.xlsx')
data = data.sort_values(by='date')# 设置 DBSCAN 参数,eps 和 min_samples 根据实际数据可能需要调整
dbscan = DBSCAN(eps=500, min_samples=5)
dbscan_labels = dbscan.fit_predict(data[['电量']]) # 使用 DBSCAN 模型进行拟合和预测# 标记离群点(DBSCAN 中,-1 标签表示离群点)
data['Outlier_DBSCAN'] = (dbscan_labels == -1)plt.figure(figsize=(12, 6))
sns.lineplot(data=data, x='date', y='电量', label='电量', color='blue')outliers_dbscan = data[data['Outlier_DBSCAN']] # 标注离群点
plt.scatter(outliers_dbscan['date'], outliers_dbscan['电量'], color='red', label='Outliers (DBSCAN)', zorder=5)# 设置标题和标签
plt.title('DBSCAN算法异常检测', fontsize=15, fontweight='bold')
plt.xlabel('时间', fontsize=12)
plt.ylabel('电量', fontsize=12)
plt.legend()
plt.show()