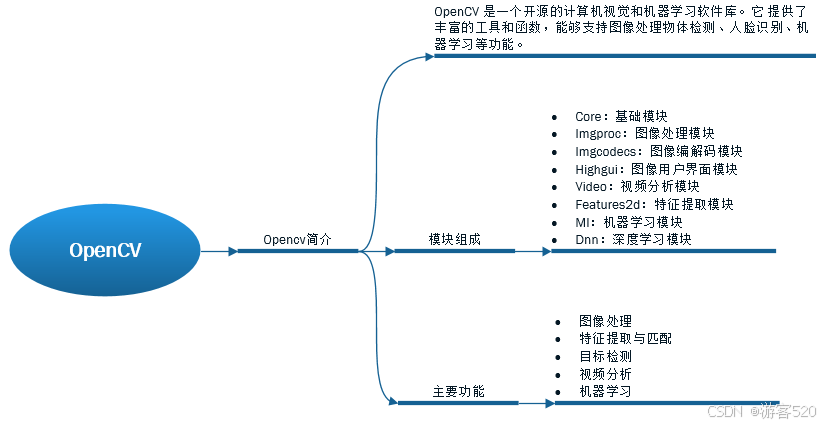
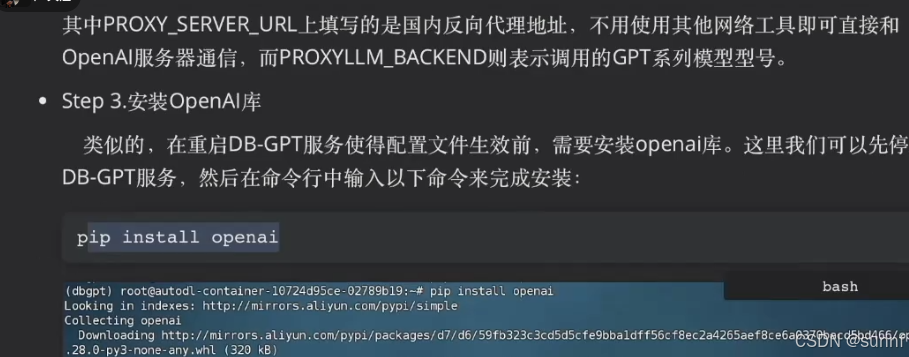
SparkSQL案例
**案例描述:**某系统存储有用户的基本信息,包括用户的姓名、身份证号、手机号码。
数据集: 有用得着的评论或私信即可
需求分析:
- 将表中的数据进行过滤,只保留 80 后、90 后、00 后的用户信息,并存入新的 Hive 分区表中,以年代为分区字段。
- 查询过滤后的表中,90 后的占比。
- 查询过滤后的表中,各个省份的人数及占比。
- 查询 00 后中性别的占比。
Hive建表语句
# 用户基础信息表 create table if not exists users(username string,idcard string,phone string ) row format delimited fields terminated by ',' lines terminated by '\n';# 身份证地址信息对照表 create table if not exists idcard_info(idcard string,province string,city string,country string ) row format delimited fields terminated by ',' lines terminated by '\n';# 新的分区表准备 create table if not exists filtered_users(username string,idcard string,phone string,birthday string,age int,gender string,province string,city string,country string ) partitioned by (era string) row format delimited fields terminated by ',' lines terminated by '\n';
"""
案例描述: 在某项目中有用户信息表、身份证地址对照表用户信息表 users:- 用户名 username- 身份证号 idcard- 手机号 phone身份证地址对照表 idcard_info:- 身份证号 idcard- 省份 province- 市 city- 区县 country- 将表中的数据进行过滤,只保留 80 后、90 后、00 后的用户信息,并存入新的 Hive 分区表中,以年代为分区字段。
- 查询过滤后的表中,每个年龄段的占比。
- 查询过滤后的表中,各个省份的人数及占比。
- 查询 00 后中女性的占比。
"""import os
import re
import datetime
from pyspark.sql import SparkSession
from pyspark.sql.types import IntegerType, StringType, BooleanTypeos.environ.setdefault("HADOOP_USER_NAME", "root")def idcard_checker(idcard: str) -> bool:"""检查一个身份证号是否合法:param idcard: 身份证号:return: 检验结果"""check_res = re.fullmatch(r'(\d{6})'r'(?P<year>(19|20)\d{2})(?P<month>0[1-9]|1[0-2])(?P<day>[012][0-9]|10|20|30|31)\d{2}'r'(?P<gender>\d)[0-9xX]',idcard)return check_res is not Nonedef get_year(idcard: str) -> int:"""从一个身份证中查询年:param idcard: 身份证号:return: 年"""return int(idcard[6:10])def get_month(idcard: str) -> int:"""从一个身份证中查询月:param idcard: 身份证号:return: 月"""return int(idcard[10:12])def get_day(idcard: str) -> int:"""从一个身份证中查询日:param idcard: 身份证号:return: 日"""return int(idcard[12:14])def get_birthday(idcard: str) -> str:"""从一个身份证中查询生日:param idcard: 身份证号:return: 生日"""return "-".join([idcard[6:10], idcard[10:12], idcard[12:14]])def get_gender(idcard: str) -> str:"""从一个身份证中查询性别:param idcard: 身份证号:return: 性别"""return '男' if int(idcard[-2]) % 2 != 0 else '女'def get_era(idcard: str) -> str:"""从一个身份证中查询年代:param idcard: 身份证号:return: 年代"""return f"{idcard[8]}0"def get_age(idcard: str) -> int:"""从一个身份证中查询年龄:param idcard: 身份证号:return: 年龄"""year = get_year(idcard)month = get_month(idcard)day = get_month(idcard)now = datetime.datetime.now()age = now.year - yearif now.month < month:age -= 1elif now.month == month and now.day < day:age -= 1return agedef get_addr(idcard: str) -> str:"""从一个身份证中查询地址信息:param idcard: 身份证号:return: 地址信息"""return idcard[0:6]with SparkSession\.builder.master("local[*]")\.appName("exercise")\.enableHiveSupport()\.config("hive.exec.dynamic.partition.mode", "nonstrict")\.getOrCreate() as spark:# 注册 UDF 函数spark.udf.register("get_year", get_year, IntegerType())spark.udf.register("get_month", get_month, IntegerType())spark.udf.register("get_day", get_day, IntegerType())spark.udf.register("get_gender", get_gender, StringType())spark.udf.register("get_age", get_age, IntegerType())spark.udf.register("get_era", get_era, StringType())spark.udf.register("get_birthday", get_birthday, StringType())spark.udf.register("idcard_checker", idcard_checker, BooleanType())spark.udf.register("get_addr", get_addr, StringType())# 将身份证中的信息都提取出来spark.sql("""select username,idcard,phone,get_birthday(idcard) birthday,get_age(idcard) age,get_gender(idcard) gender,get_era(idcard) erafrom mydb.userswhereidcard_checker(idcard) == true""").createTempView("tmp_user")# 连接上地址信息进行查询,并将结果写出到表中# spark.sql("""# insert into mydb.filtered_users partition(era)# select# username,# tmp_user.idcard,# phone,# birthday,# age,# gender,# province,# city,# country,# era# from# tmp_user# join# mydb.idcard_info# on# mydb.idcard_info.idcard == get_addr(tmp_user.idcard)# where# tmp_user.era == 10 or tmp_user.era == 80 or tmp_user.era == 90 or tmp_user.era == 00# """)# - 查询过滤后的表中,每个年龄段的占比。# spark.sql("""# select distinct# era,# count(*) over(partition by era) / count(*) over() rate# from# mydb.filtered_users# """).show()# - 查询过滤后的表中,各个省份的人数及占比。# spark.sql("""# select distinct# province,# count(*) over(partition by province) / count(*) over() rate# from# mydb.filtered_users# order by# rate desc# """).show(50)# - 查询00后中男女的占比。spark.sql("""select distinctgender,count(*) over(partition by gender) / count(*) over() ratefrommydb.filtered_userswhere era = '00';""").show()