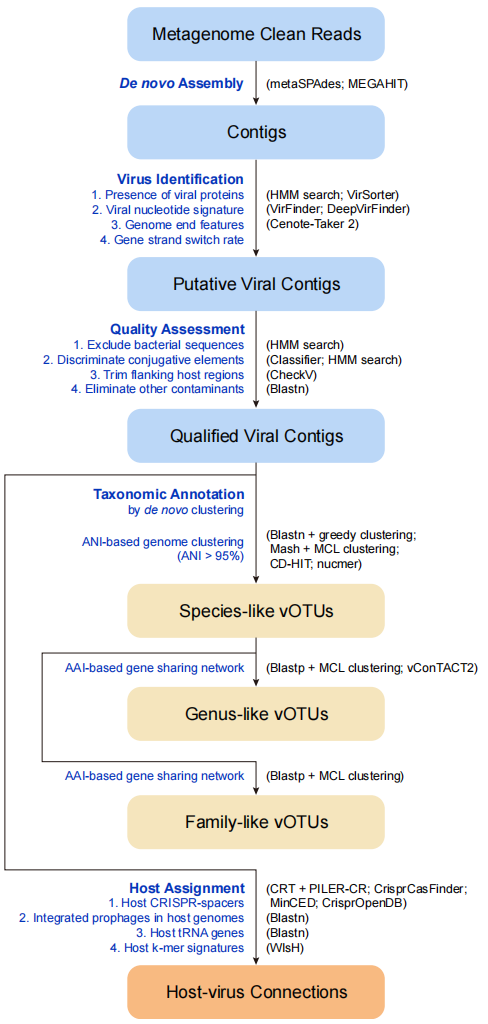
目录
- 药物重定位概述
- 药物重定位数据库
- 表示学习
- 基于序列的表示学习
- 基于图的表示学习
- 药物重定位深度学习
- 以靶点为中心
- 以疾病为中心
- 药物重定位的应用
药物重定位概述
新药物的研发投资巨大,周期漫长。从获批准的临床药物中有效识别新的适应药物在药物发现中起到重要作用,可以绕过开发一个治疗性药物所需的多项批准前测试,这个过程被称为药物重定位。
药物重定位数据库
现有的数据库存储了来自不同系列化合物的潜在细胞靶点。例如,KEGG数据库,包含了来自基因,蛋白质,生物途径和人类疾病的大规模分子数据集。DrugBank将详细的药物信息和相应的靶点结合,共计13791个药物条目。药物重定位涉及化学,药物-靶点相互作用数据。
表示学习
深度学习的性能很大程度上体现在有效的数据表示上。这意味着可以让一个系统使用一套技术自动从原始数据中提取特征或发现分类所需的表示,这被称为表示学习。目前,用于药物重定位的表示学习分为基于序列的方法和基于图的方法。
基于序列的表示学习
基于序列的表示方法可以克服部分现有的蛋白质结构数据的局限性和昂贵的分子对接模拟需求。现有的蛋白质和化合物序列可以推进药物重定位。

- 图1:药物的表示。
对于分子化合物,常用1D序列SMILES表示(图1a)。受到NLP中预训练语言模型的启发,Mol2vec被提出并被认为是最具有代表性的方法,它将化合物分子的子结构视为单词,化合物视为句子,使用Word2vec生成化合物的embedding(向量组成的矩阵)。
此外,分子指纹,比如圆形指纹,可以表示为二进制向量(图1b),以此高维稀疏向量作为输入,可以得到化合物的embedding(一个低维向量)。

- 图2:蛋白质的表示。
对于蛋白质,蛋白质序列一般由20种标准氨基酸构成,每个氨基酸都可以通过one-hot进行编码(图2a)。该矩阵同样可以被word2vec表示。
此外,蛋白质可以用2D距离图表示(图2b),它计算3D蛋白质结构中所有可能的氨基酸残基对之间的距离。
基于序列的表示方法没有考虑蛋白质的3D结构信息。DeepMind开发的AlphaFold系统发布了基于序列的蛋白质3D结构预测结果。
基于图的表示学习
对于化合物,SMILES可以通过RDKit转换为分子图(graph结构),并将分子图中的原子和键分别表示为图中的顶点和边。对于蛋白质,可以将蛋白质的各种非氢原子表示为蛋白质图的顶点。然后用GNN提取节点的特征表示。
药物重定位深度学习
药物重定位模型分为:以靶点为中心(预测药物-靶点相互作用)和以疾病为中心(预测药物-疾病相互作用)。
以靶点为中心
卷积运算可用于处理不同长度的氨基酸序列,并捕获在药物-靶点相互作用(DTI)预测中起到关键作用的局部残基的模式。DTI预测可以利用化合物-蛋白质相互作用(CPI)数据。DTI预测可以使用之前描述的CPI预测模型。
以疾病为中心
识别药物-疾病对之间的相互作用是以疾病为中心的药物重定位关键步骤。现有方法大致分为基于相似性和基于网络。
- 已有很多方法被用于计算药物和疾病之间的相似性。这些方法通过将药物-疾病特征与已知的药物-疾病关联结合。
- 基于网络的方法结合生物网络的图信息进行重定位。该方法以知识图谱嵌入研究为主。
药物重定位的应用
以COVID-19为例,说明药物重定位在对抗COVID-19中起到的加速治疗作用。
从SARS-CoV-2病毒→宿主蛋白→蛋白相互作用的角度来看,经批准的针对特定人类蛋白或靶点的药物可能为COVID-19提供潜在的宿主靶向治疗。
尽管现有可用的疫苗,但目前尚无有效的COVID-19治疗方法。针对COVID-19大流行,Belyaeva等人提出一个基于自编码器的平台,该平台集成了可用的转录组学,蛋白质组学和结构数据。作者强调将丝氨酸和酪氨酸激酶作为潜在靶点,并确定了三种候选药物(多沙普蓝,达沙替尼,利巴韦林)。
除了针对COVID-19的宿主靶向疗法,专门针对SARS-CoV-2病毒蛋白的抗病毒药物重定位也是一种疗法。例如,SARS-CoV-2的主蛋白酶(Mpro)是最有利的药物靶点之一。现有研究已经确定了71个候选的SARS-CoV-2 Mpro共价键抑制剂。
这些研究表明,深度学习在识别用于COVID-19的可重新利用药物(包括靶向宿主疗法和抗病毒疗法)具有潜力。