博主介绍:黄菊华老师《Vue.js入门与商城开发实战》《微信小程序商城开发》图书作者,CSDN博客专家,在线教育专家,CSDN钻石讲师;专注大学生毕业设计教育、辅导。
所有项目都配有从入门到精通的基础知识视频课程,学习后应对毕业设计答辩,提供核心代码讲解,答辩指导。
项目配有对应开发文档、开题报告、任务书、PPT等,提供毕业设计论文辅导。项目都录了发布和功能操作演示视频;项目的界面和功能都可以定制,包安装运行!!!
如果需要联系我,可以在CSDN网站查询黄菊华老师的,在文章末尾可以获取联系方式
开发技术
开发操作系统:windows10 + 4G内存 + 500G硬盘
开发环境:Python3.8
开发语言:Python
开发框架:Django
开发工具:pycharm
数据库:mysql8
数据库管理工具:navicat
其他开发语言:html + css +javascript
功能清单

【后台管理员功能】
系统设置:设置网站名称,关键字,网站描述
关于我们设置:设置网站介绍、联系我们、加入我们、法律声明
广告管理:设置小程序首页轮播图广告和链接
留言列表:所有用户留言信息列表,支持删除
会员列表:查看所有注册会员信息,支持删除
录入资讯:录入资讯标题、内容等信息
管理资讯:查看已录入资讯列表,支持删除和修改
商品分类设置:设置商品分类,支持修改和删除
录入商品:选择分类,录入商品名称,价格,属性,图片,介绍等
管理商品:查看已录入所有商品,支持修改和删除
热门关键字:设置热门商品关键字
订单列表:查看所有用户下单的订单列表信息
订单处理:针对已经下单的订单进行发货处理
评论列表:显示所有用户对商品的评论,默认不显示
评论处理:评论默认不显示,管理员审核处理后可见
【网站功能】
用户注册:填写手机账号和密码,注册新用户
登录功能:注册普通账号登录;登录后可以修改用户的基本信息,也可以退出。
关于我们:关于我们、联系我们、加入我们、法律声明
轮播广告:后台设置首页轮播广告图,可以连接到广告页面。
留言反馈:用户填写李哭咽的主题、联系人、电话、邮箱、留言内容;后台管理可以查看留言列表,可以删除留言。
资讯阅读:游客和用户都可以进行资讯的阅读。
商品库:后台录入商品的相关信息,可以在网站商品列表里面一个一个点击进去查看商品详细信息;支持通过查询来查找所需要的商品。
商品分类和列表:可以点击分类,按分类列出对应商品
商品信息:点击到商品详情页面,可以查看商品的介绍,查看商品简介、图片、详情、商品评论。
商品评论:在商品信息详情,可以填写评论,后台审核后可见。
收藏操作:在商品信息详情,下方点击“收藏”,进行收藏
加入购物车:在商品详情,点击“加购物车”,在我的购物车可以查看。
立即购买:在商品详情,点击“立即购买”,立即跳转到购物车。
我的购物车:显示所有加入购物车打算购买的产品列表。
商品选择:在购物车我们可以增加和减少商品的数量,可以勾选要去结算的物品。
购物车下单:点击“去结算”,选择或者填写收货地址、确认要下单的商品和数量;备注填写。点击“下单结算”,然后跳转到订单列表
订单列表:显示用户下单的记录列表
取消订单:在“我的订单”列表中,点击“取消申请”,删除订单
去付款::在“我的订单”列表中,点击“去付款”,模拟付款
我的收藏:用户收藏的商品列表。
地址录入:录入用户自己的收货地址
地址列表:用户输入的收货地址列表
地址管理:支持收货地址的管理和删除
用户信息:姓名、联系方式、邮箱、头像、简介、介绍等,支持随时修改;用户注册的信息后台管理员可见;后台管理员可以删除。
密码修改:修改注册的密码。
退出登录:清除登录的cookie,返回到首页。
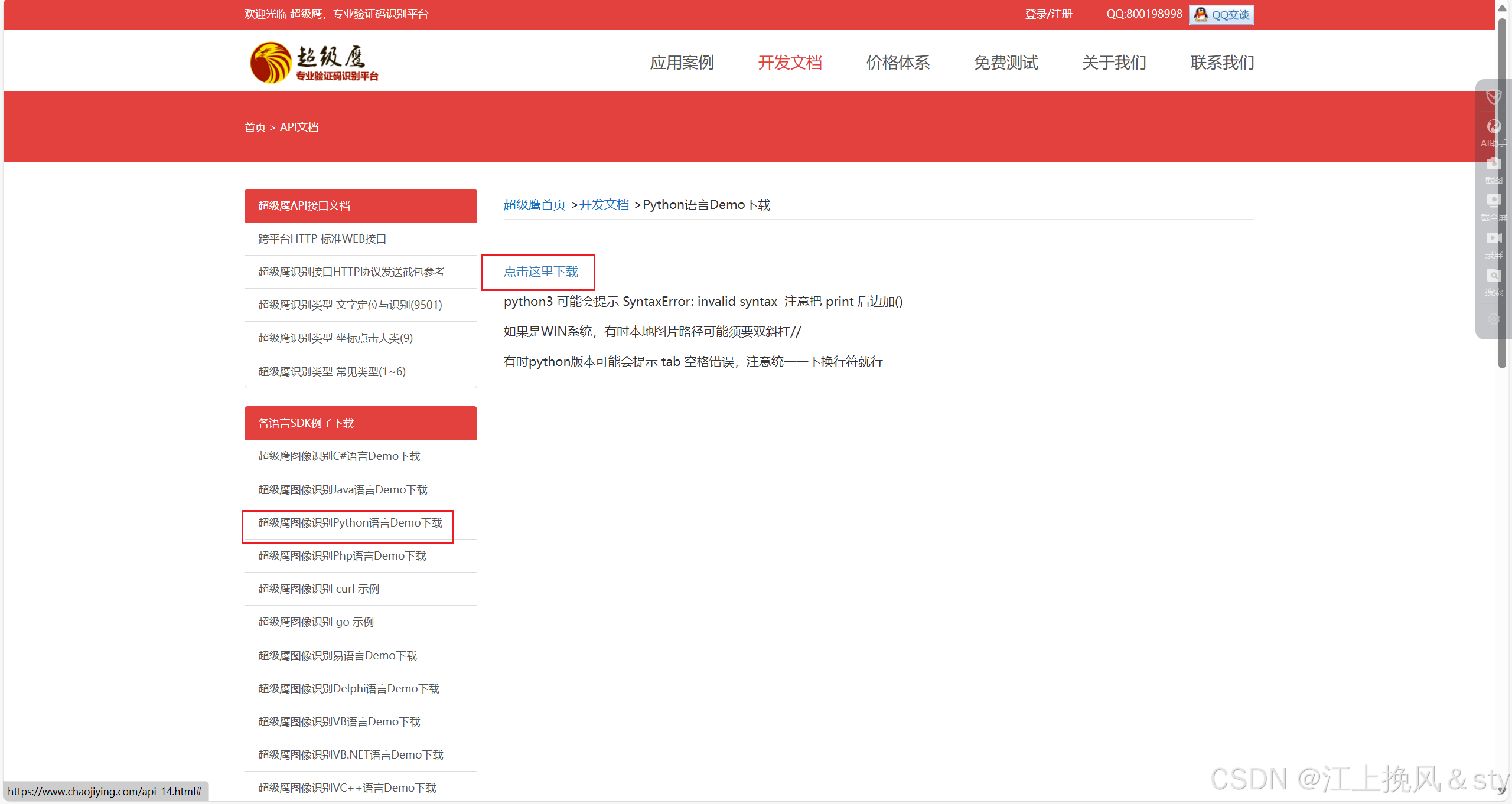
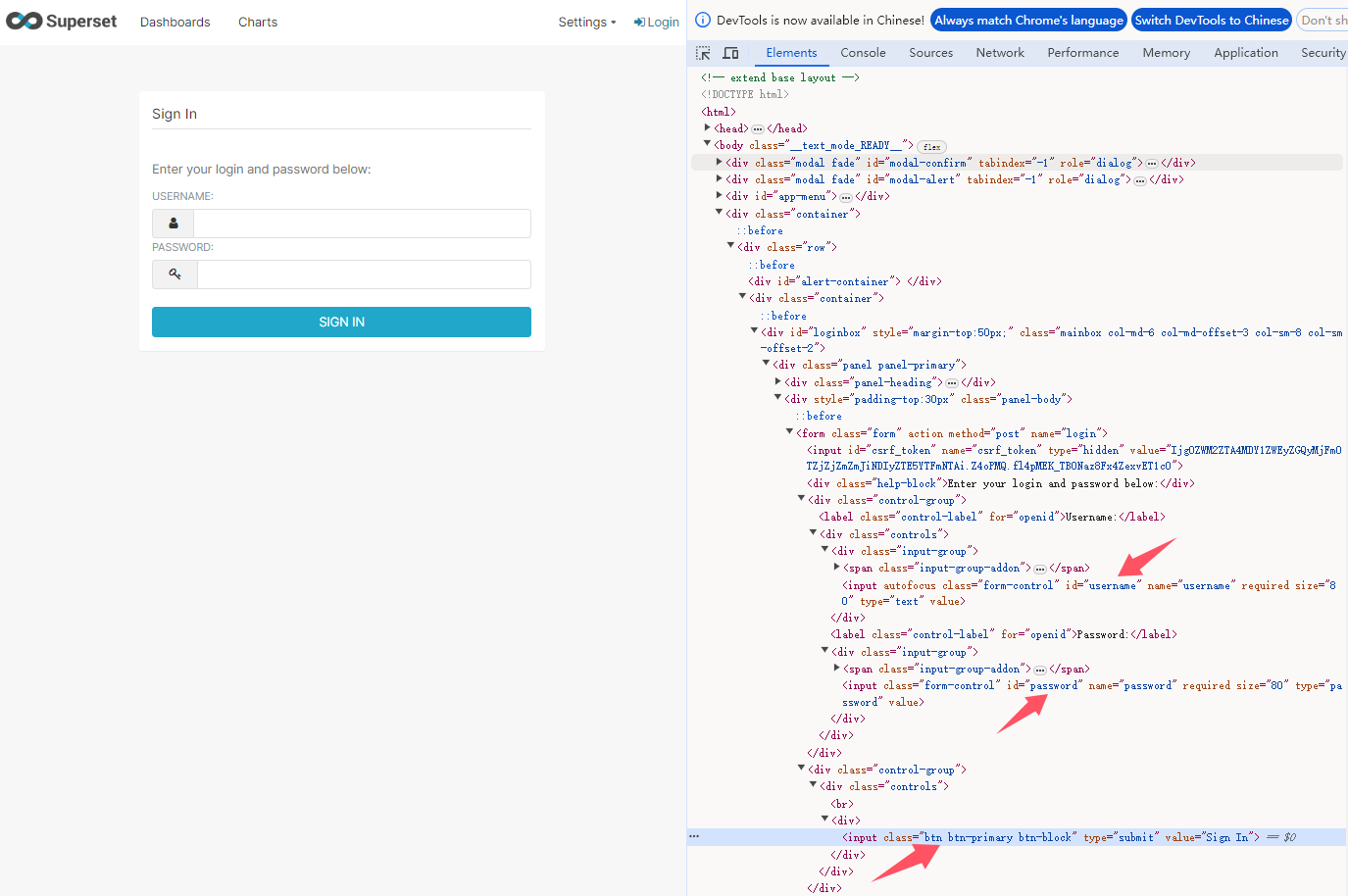
作品截图