文章目录
- 前言
- 1.ModelArts是什么
- 一、语音识别技术概述
- 1.语音识别概述
- 2.语音识别的一般原理
- 3.信号处理与特征提取方法
- 3.1 MFCC
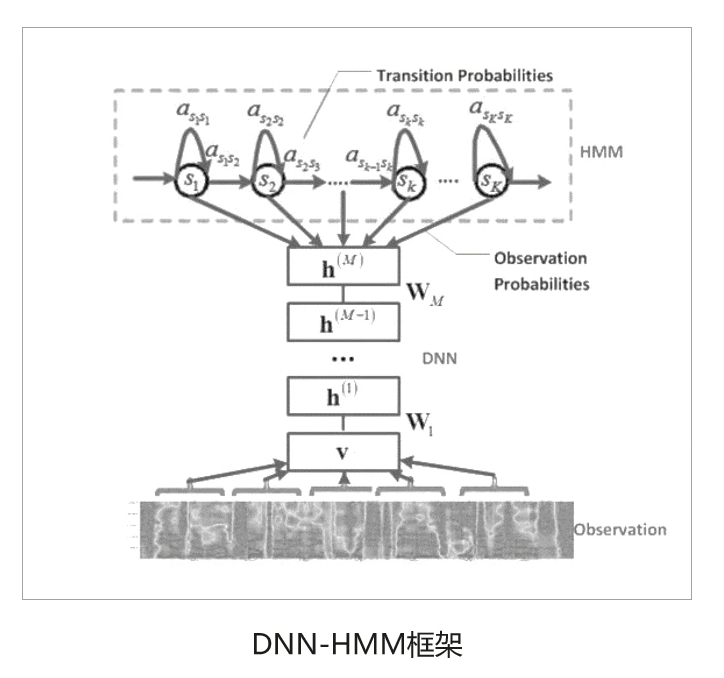
- 4.基于深度学习的声学模型DNN-HMM
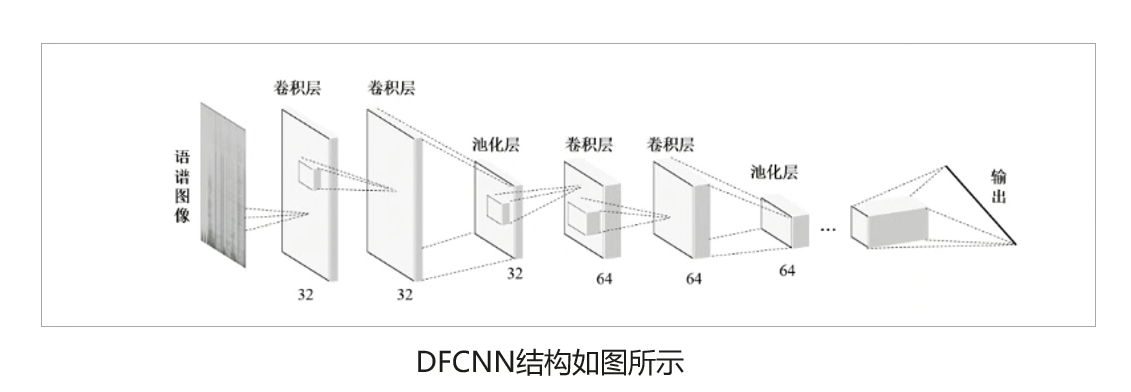
- 二、DFCNN全序列卷积神经网络介绍
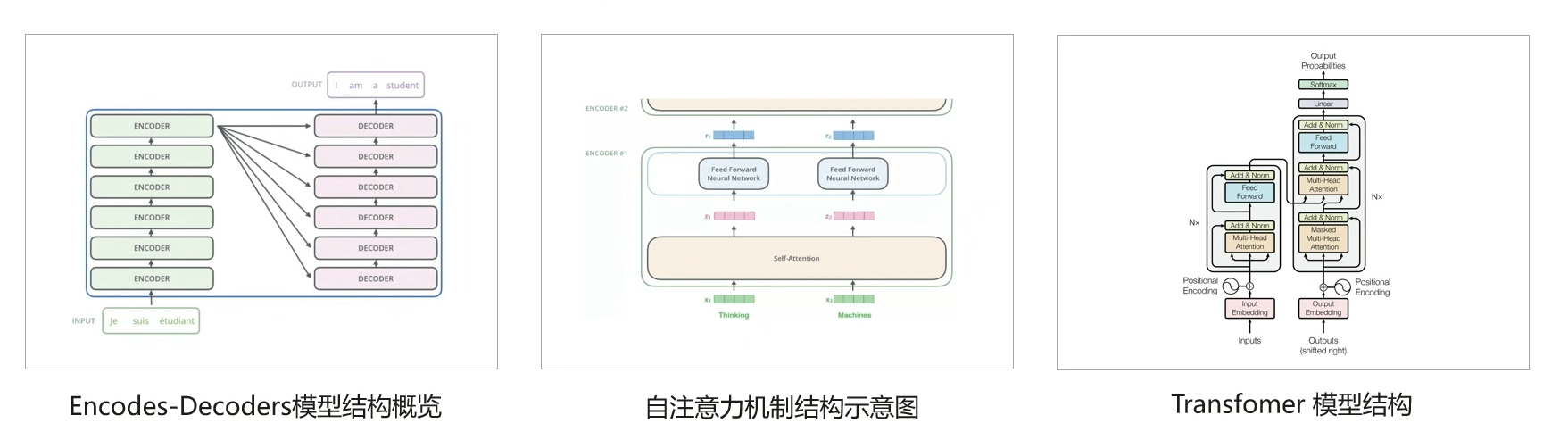
- 三、Transformer原理
- 四、使用ModelArts快速上手训练DFCNN+Transformer模型完成中文语音识别系统的搭建
- 1.ModelArts,致力打造行业AI落地首选平台
- 2.算法开发:面向四类开发人员提供AI开发工具
- 3.DFCNN+Transformer模型完成中文语音识别系统的搭建
- 3.1 系统环境搭建
- 3.2 DFCNN+Transformer模型完成中文语音识别系统的搭建的步骤
- 3.2.1 提取源码数据
- 3.2.2 提取数据集
- 3.2.3 加载需要的python库
- 3.2.4 建立DFCNN声学模型
- 3.2.5 获取数据类
- 3.2.6 声学模型训练
- 3.2.7 语言模型建模
- 3.2.8 多头注意力层
- 3.2.9 语言模型训练
- 3.2.10 模型测试
- 总结
前言
1.ModelArts是什么
ModelArts是面向AI开发者的一站式开发平台,提供海量数据预处理及半自动化标注、大规模分布式训练、自动化模型生成及端-边-云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期AI工作流。
“一站式”是指AI开发的各个环节,包括数据处理、算法开发、模型训练、模型部署都可以在ModelArts上完成。从技术上看,ModelArts底层支持各种异构计算资源,开发者可以根据需要灵活选择使用,而不需要关心底层的技术。同时,ModelArts支持Tensorflow、PyTorch、MindSpore等主流开源的AI开发框架,也支持开发者使用自研的算法框架,匹配您的使用习惯。
ModelArts的理念就是让AI开发变得更简单、更方便。
面向不同经验的AI开发者,提供便捷易用的使用流程。例如,面向业务开发者,不需关注模型或编码,可使用自动学习流程快速构建AI应用;面向AI初学者,不需关注模型开发,使用预置算法构建AI应用;面向AI工程师,提供多种开发环境,多种操作流程和模式,方便开发者编码扩展,快速构建模型及应用。
本文介绍的内容主要分为如下几个部分:
- 语音识别技术概述
DFCNN全序列卷积神经网络介绍Transformer原理- 使用ModelArts快速上手训练
DFCNN+Transformer模型完成中文语音识别系统的搭建
一、语音识别技术概述
1.语音识别概述
- 语音识别
(SpeechRecognition)是以语音为研究对象,通过语音信号处理和模式识别让机器自动识别和理解人类的语音。除了传统语音识别技术之外,基于深度学习的语音识别技术也逐渐发展起来。 - 自动语音识别
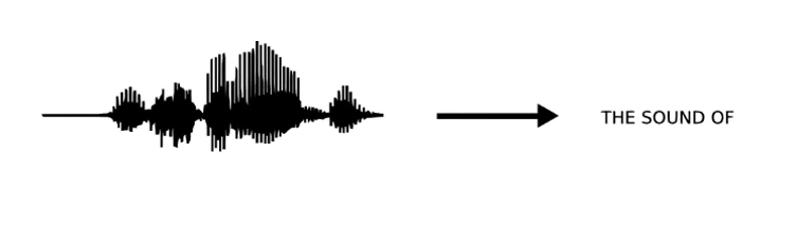
(Automatic Speech Recognition,ASR),也可以简称为语音识别。主要是将人类语音中的词汇内容转换为计算机可读的输入,一般都是可以理解的文本内容,也有可能是二进制编码或者字符序列。但是,我们一般理解的语音识别其实都是狭义的语音转文字的过程,简称语音转文本识别(SpeechToText,STT)更合适,这样就能与语音合成(TextToSpeech,TTS)对应起来。 - 为了能够更加清晰的定义语音识别的任务,先来看一下语音识别的输入和输出都是什么。大家都知道,声音从本质是一种波,也就是声波,这种波可以作为一种信号来进行处理,所以语音识别的输入实际上就是一段随时间播放的信号序列,而输出则是一段文本序列。语音识别的输入与输出如图所示。
2.语音识别的一般原理
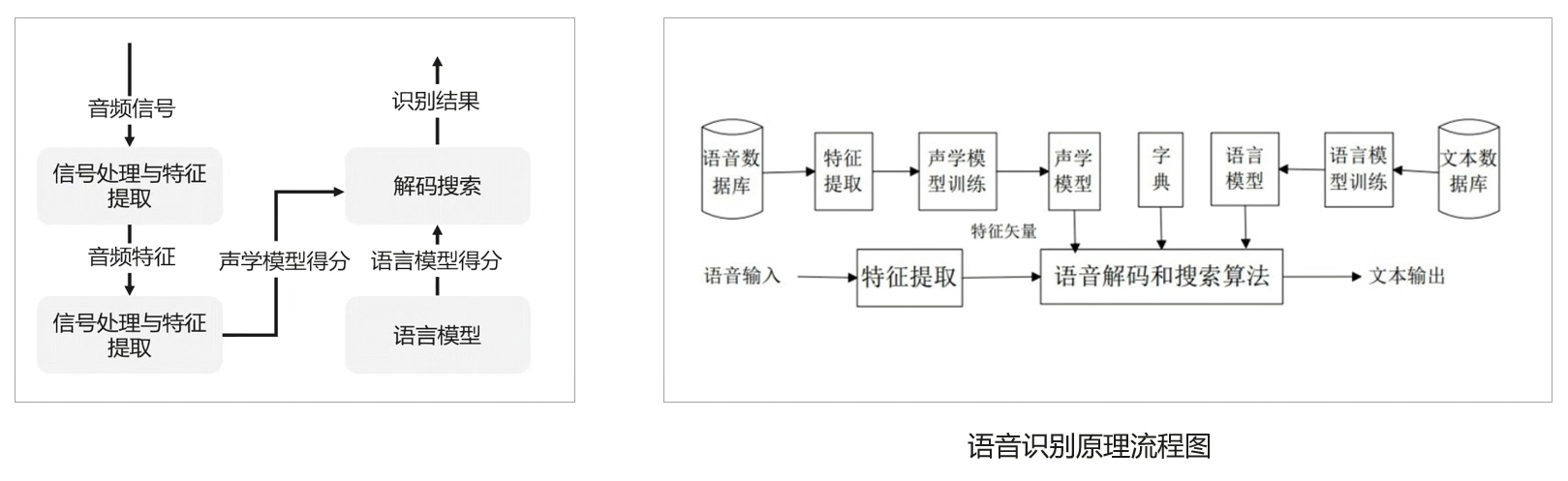
语音识别的一般原理是将语音信号转换为数字信号,然后使用机器学习算法对数字信号进行分析和处理,最终将语音转换为文本或命令。常用的语音识别算法包括隐马尔可夫模型、深度神经网络等。
语音识别的原理流程是:
- 首先,语音信号被采集并转换成数字信号。
- 然后,数字信号被分析和处理,包括预处理、特征提取和模式匹配等步骤。
- 最后,识别结果被输出。整个过程涉及到信号处理、机器学习、自然语言处理等多个领域的知识。
原理流程图如下:
3.信号处理与特征提取方法
特征提取方法主要有:
-
线性预测系数
(LPC):线性预测系数是一种用于时间序列分析的方法,用于预测未来的数值。它是通过对历史数据进行线性回归分析,得出一组系数,然后利用这些系数来预测未来的数值。具体的计算方法可以参考统计学中的相关知识。 -
LPC倒谱系数
(LPCC):LPC倒谱系数是一种用于语音信号处理的技术,它可以通过对语音信号进行分析,提取出信号的特征参数,从而实现语音信号的压缩和识别等功能。具体来说,LPC倒谱系数是一组用于描述语音信号的线性预测模型参数,它可以通过对语音信号进行自相关分析和线性预测分析得到。在语音信号处理中,LPC倒谱系数被广泛应用于语音编码、语音合成、语音识别等领域。 -
线谱对参数
(LSP):线谱对分析法是一种用于分析复杂系统的方法,它可以将系统分解成多个子系统,并通过对子系统之间的相互作用进行分析,来揭示系统的行为和性质。该方法在系统工程、控制理论、信号处理等领域得到了广泛应用。 -
共振峰率:共振峰率是指声音信号中的共振峰频率与声音信号的基频之比。在语音识别和语音合成中,共振峰率是一个重要的参数,可以用来识别和合成不同的语音音素。
-
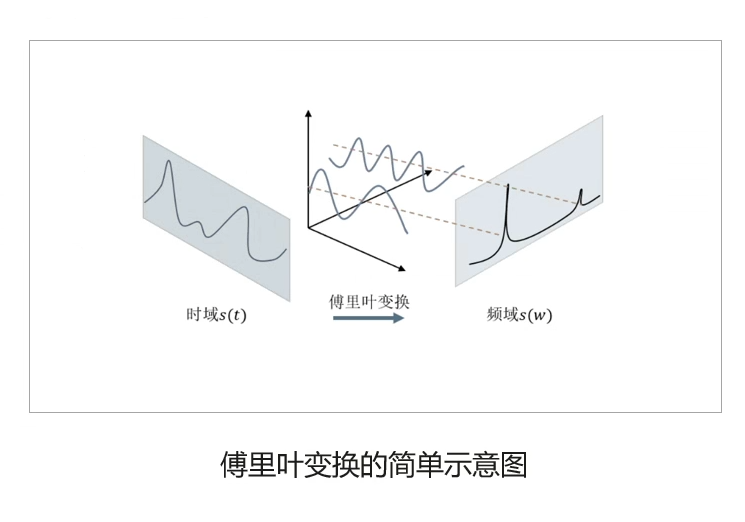
短时谱:短时谱分析法是一种信号处理技术,用于将信号分解成频率和时间的成分。它通过将信号分成短时间段,对每个时间段进行傅里叶变换,得到该时间段内信号的频率成分,从而得到整个信号的频率和时间成分。
-
感知线性预测
(PLP):感知线性预测是一种基于线性模型的机器学习算法,它可以用于分类和回归问题。它的基本思想是通过对输入数据进行线性组合,得到一个预测输出值,然后将这个预测输出值与真实输出值进行比较,从而不断调整线性组合的参数,使得预测输出值与真实输出值的误差最小化。 -
Mel频率倒谱系数
(MFCC):频率倒谱系数是一种信号处理中的特征参数,用于描述信号的频率变化情况。它可以通过对信号进行傅里叶变换和倒谱变换得到。
3.1 MFCC
MFCC提取过程如下:
-
预加重:MFCC提取过程的预加重是指在语音信号的前端加入一个高通滤波器,以增强高频信号的能量,从而提高MFCC特征的稳定性和可靠性。预加重的滤波器通常是一个一阶高通滤波器,其传递函数为H(z)=1-αz^-1,其中α是预加重系数,通常取值为0.95。
-
分帧:MFCC提取过程的分帧是将音频信号分成若干个固定长度的帧,通常每帧的长度为20-30毫秒,帧与帧之间有一定的重叠。然后对每一帧进行加窗处理,以减少频谱泄漏的影响。最后对每一帧进行傅里叶变换,得到其频谱信息,再通过Mel滤波器组将频谱信息转换为Mel频率下的能量分布,最后再进行离散余弦变换,得到MFCC系数。
-
加窗:MFCC提取过程中的加窗是为了减少频谱泄漏的影响,常用的加窗函数有汉明窗、海宁窗等。加窗后,信号在频域上的能量分布更加集中,可以更准确地提取出MFCC特征。
-
快速傅里叶变换
(FFT):MFCC提取过程中的快速傅里叶变换是用来将语音信号转换为频域特征的一种方法。它可以通过将语音信号分成短时窗口,并对每个窗口进行傅里叶变换来实现。这个过程可以使用快速傅里叶变换算法来加速计算。 -
通过三角带通滤器得到Mel频谱:MFCC提取过程中的三角带通滤器是一种用于将音频信号转换为频谱图的滤波器。它可以将音频信号分成不同的频带,并且对每个频带进行加权,以便更好地反映人类听觉系统的特性。三角带通滤波器通常使用Mel刻度来划分频带,以便更好地模拟人类听觉系统的响应。
-
倒谱分析
(取对数,做逆变换):MFCC提取过程中的倒谱分析是将音频信号转换为倒谱系数的过程。它首先将音频信号分帧,然后对每一帧进行加窗处理,接着进行傅里叶变换,得到频谱图。然后对频谱图进行对数化处理,再进行离散余弦变换,得到倒谱系数。倒谱系数是MFCC特征的一部分,用于表示音频信号的频率特征。
4.基于深度学习的声学模型DNN-HMM
- DNN-HMM主要是用DNN模型代替原来的GMM模型,对每一个状态进行建模,DNN带来的好处是不再需要对语音数据分布进行假设,将相邻的语音帧拼接又包含了语音的时序结构信息,使得对于状态的分类概率有了明显提升,同时DNN还具有强大环境学习能力,可以提升对噪声和口音的鲁棒性。
- HMM用来描述语音信号的动态变化,DNN则是用来估计观察特征的概率。在给定声学观察特征的条件下,我们可以用DNN的每个输出节点来估计HMM某个状态的后验概率。由于DNN-HMM训练成本不高而且相对较高的识别概率,所以即使是到现在在语音识别领域仍然是较为常用的声学模型。
二、DFCNN全序列卷积神经网络介绍
- DFCNN的全称叫作全序列卷积神经网络
(Deep Fully Convolutional Neural Network),是由国内语音识别领域领头羊科大讯飞于2016年提出的一种语音识别框架。 - DFCNN先对时域的语音信号进行傅里叶变换得到语音的语谱图,DFCNN直接将一句语音转化成一张图像作为输入,输出单元则直接与最终的识别结果
(例如,音节或者汉字)相对应。DFCNN的结构中把时间和频率作为图像的两个维度,通过较多的卷积层和池化(pooling)层的组合,实现对整句语音的建模。
三、Transformer原理
Transformer的本质上是一个Encoder-Decoder的结构,Transformer是一个利用注意力机制来提高模型训练速度的模型,用于处理序列到序列的任务,如机器翻译、文本摘要、语音识别等。它由编码器和解码器两部分组成,每个部分都由多个层级的自注意力和前馈神经网络组成。编码器将输入序列映射到一组隐藏表示,解码器则使用这些表示来生成输出序列。Transformer 的自注意力机制可以同时考虑输入序列中的所有位置,从而更好地捕捉序列中的长距离依赖关系。
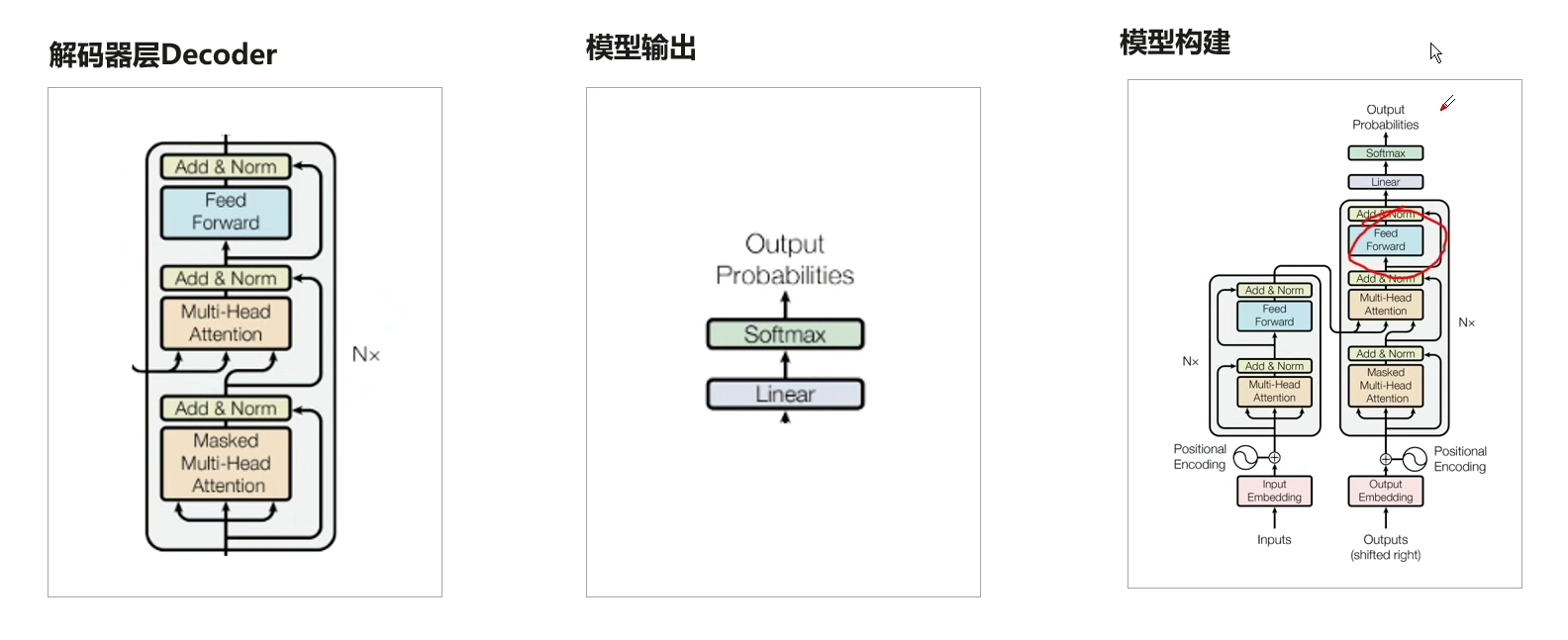
四、使用ModelArts快速上手训练DFCNN+Transformer模型完成中文语音识别系统的搭建
1.ModelArts,致力打造行业AI落地首选平台
ModelArts是华为云推出的一款人工智能开发平台,旨在为企业和开发者提供全面的AI解决方案和服务,包括数据管理、模型训练、模型部署等。它支持多种框架和算法,如TensorFlow、PyTorch、Caffe等,可以帮助用户快速构建和部署AI应用。
ModelArts的流程主要有:数据处理、算法开发、模型训练、模型管理、模型部署。

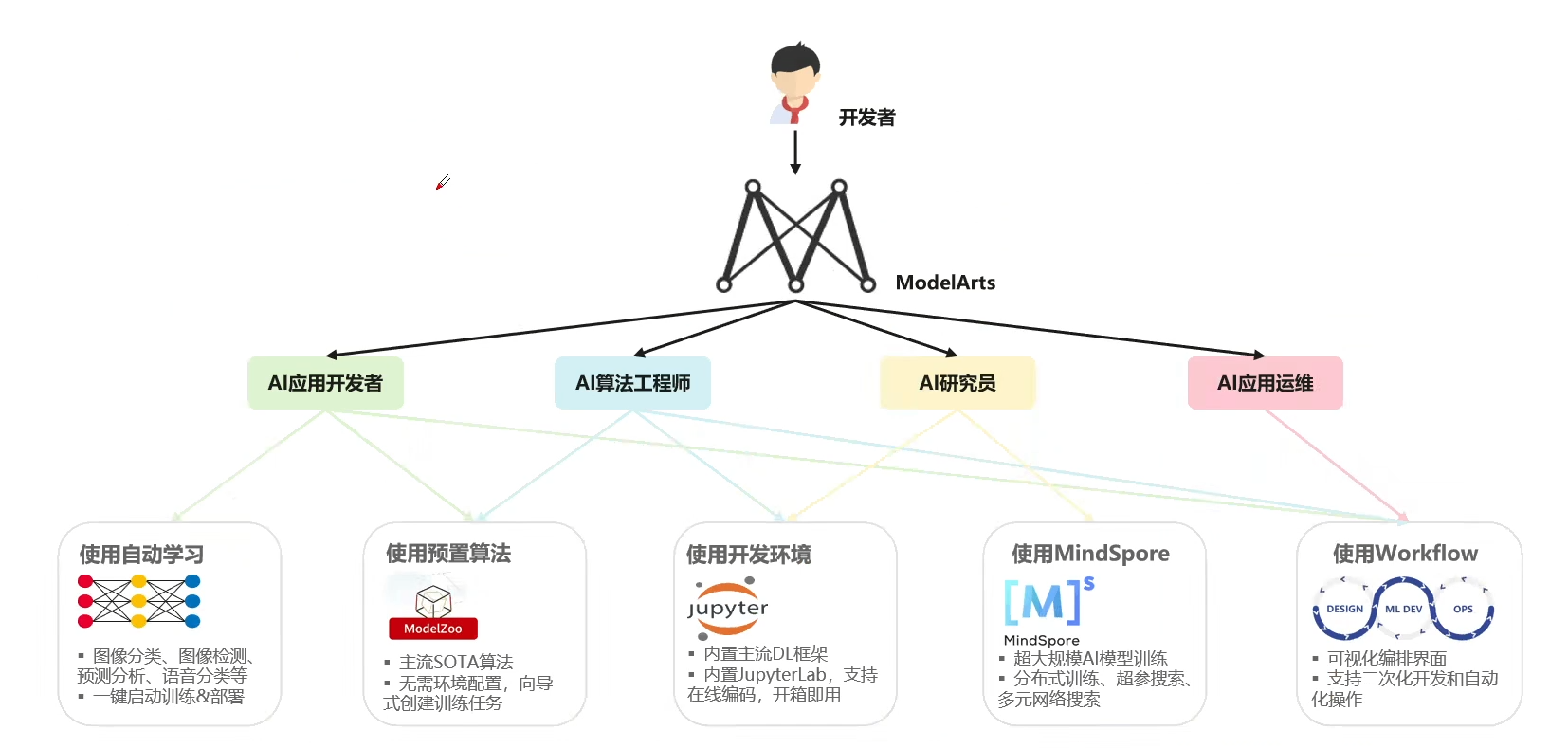
2.算法开发:面向四类开发人员提供AI开发工具
ModelArts提供了面向四类开发人员的AI开发工具,包括AI应用开发者、AI算法工程师、AI研究员和AI应用运维。
3.DFCNN+Transformer模型完成中文语音识别系统的搭建
DFCNN+Transformer模型完成中文语音识别系统的搭建的步骤主要有:
- 准备源代码和数据,从obs链接下载解压
- 下载数据集THCHS-30,数据预处理
- 加载需要的python库
- 声学模型DFCNN介绍
- 建立DFCNN声学模型
- 获取数据类
- 声学模型训练
- 语言模型Transformer的介绍
- 多头注意力的实现
- 语言模型训练
- 模型测试
3.1 系统环境搭建
1、打开基于ModelArts搭建中文语音识别系统的源码并点击运行Run in ModelArts:https://developer.huaweicloud.com/develop/aigallery/notebook/detail?id=945ed975-eac8-4c99-8403-a8f0f3095ee5

2、点击切换资源
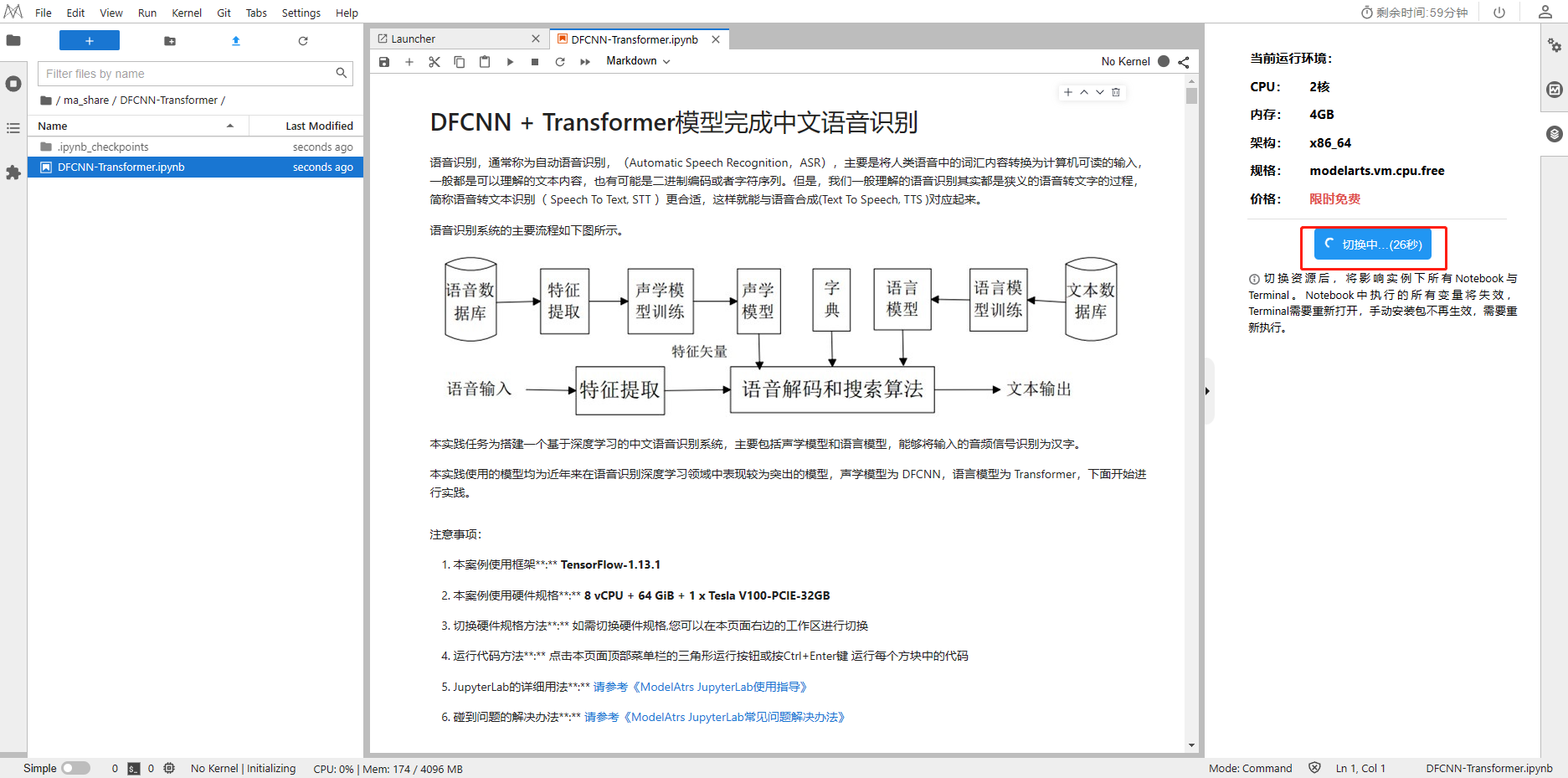
至此环境都准备完成
3.2 DFCNN+Transformer模型完成中文语音识别系统的搭建的步骤
3.2.1 提取源码数据
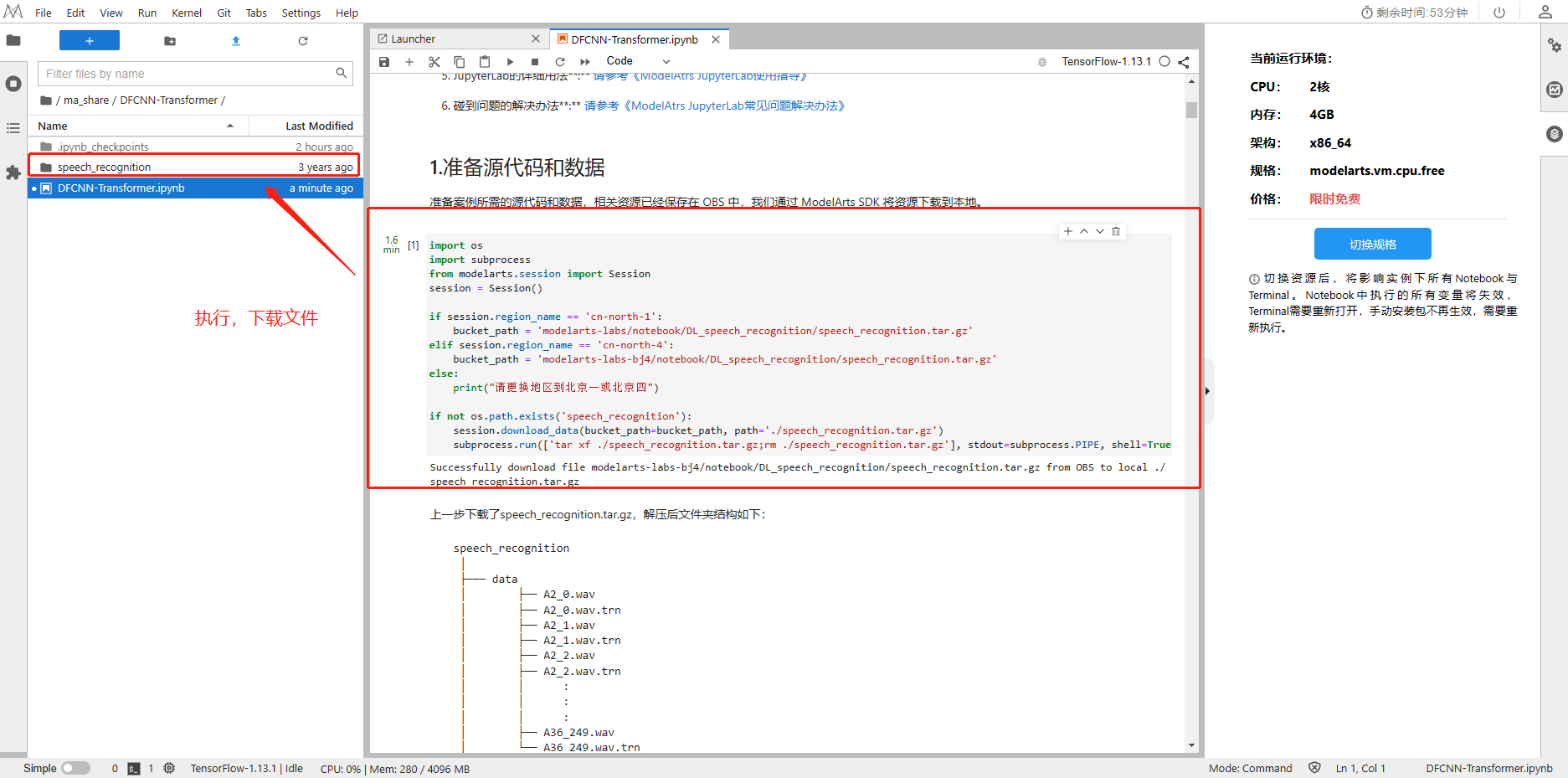
准备案例所需的源代码和数据,相关资源已经保存在 OBS 中,我们通过 ModelArts SDK 将资源下载到本地。
import os
import subprocess
from modelarts.session import Session
session = Session()if session.region_name == 'cn-north-1':bucket_path = 'modelarts-labs/notebook/DL_speech_recognition/speech_recognition.tar.gz'
elif session.region_name == 'cn-north-4':bucket_path = 'modelarts-labs-bj4/notebook/DL_speech_recognition/speech_recognition.tar.gz'
else:print("请更换地区到北京一或北京四")if not os.path.exists('speech_recognition'):session.download_data(bucket_path=bucket_path, path='./speech_recognition.tar.gz')subprocess.run(['tar xf ./speech_recognition.tar.gz;rm ./speech_recognition.tar.gz'], stdout=subprocess.PIPE, shell=True, check=True)
3.2.2 提取数据集
THCHS30是一个经典的中文语音数据集,包含了1万余条语音文件,大约40小时的中文语音数据,内容以新闻文章诗句为主,全部为女声。THCHS-30是在安静的办公室环境下,通过单个碳粒麦克风录取的,采样频率16kHz,采样大小16bits,录制对象为普通话流利的女性大学生。
with open('./speech_recognition/data.txt',"r", encoding='UTF-8') as f: #设置文件对象f_ = f.readlines()for i in range(10):for j in range(3):print(f_[i].split('\t')[j])print('语音总数量:',len(f_),'\n')
3.2.3 加载需要的python库
import os
import numpy as np
import scipy.io.wavfile as wav
import matplotlib.pyplot as plt
import tensorflow as tf
3.2.4 建立DFCNN声学模型
本实践采用的 DFCNN 与连接时序分类模型(CTC,connectionist temporal classification)方案结合,以实现整个模型的端到端声学模型训练,且其包含的池化层等特殊结构可以使得以上端到端训练变得更加稳定。与传统的声学模型训练相比,采用CTC作为损失函数的声学模型训练,是一种完全端到端的声学模型训练,不需要预先对数据做对齐,只需要一个输入序列和一个输出序列即可以训练。这样就不需要对数据对齐和一一标注,并且CTC直接输出序列预测的概率,不需要外部的后处理。
import keras
from keras.layers import Input, Conv2D, BatchNormalization, MaxPooling2D
from keras.layers import Reshape, Dense, Dropout, Lambda
from keras.optimizers import Adam
from keras import backend as K
from keras.models import Model
from tensorflow.contrib.training import HParams#定义卷积层
def conv2d(size):return Conv2D(size, (3,3), use_bias=True, activation='relu',padding='same', kernel_initializer='he_normal')#定义BN层
def norm(x):return BatchNormalization(axis=-1)(x)#定义最大池化层
def maxpool(x):return MaxPooling2D(pool_size=(2,2), strides=None, padding="valid")(x)#定义dense层
def dense(units, activation="relu"):return Dense(units, activation=activation, use_bias=True,kernel_initializer='he_normal')#两个卷积层加一个最大池化层的组合
def cnn_cell(size, x, pool=True):x = norm(conv2d(size)(x))x = norm(conv2d(size)(x))if pool:x = maxpool(x)return x#CTC损失函数
def ctc_lambda(args):labels, y_pred, input_length, label_length = argsy_pred = y_pred[:, :, :]return K.ctc_batch_cost(labels, y_pred, input_length, label_length)#组合声学模型
class acoustic_model():def __init__(self, args):self.vocab_size = args.vocab_sizeself.learning_rate = args.learning_rateself.is_training = args.is_trainingself._model_init()if self.is_training:self._ctc_init()self.opt_init()def _model_init(self):self.inputs = Input(name='the_inputs', shape=(None, 200, 1))self.h1 = cnn_cell(32, self.inputs)self.h2 = cnn_cell(64, self.h1)self.h3 = cnn_cell(128, self.h2)self.h4 = cnn_cell(128, self.h3, pool=False)self.h5 = cnn_cell(128, self.h4, pool=False)# 200 / 8 * 128 = 3200self.h6 = Reshape((-1, 3200))(self.h5)self.h6 = Dropout(0.2)(self.h6)self.h7 = dense(256)(self.h6)self.h7 = Dropout(0.2)(self.h7)self.outputs = dense(self.vocab_size, activation='softmax')(self.h7)self.model = Model(inputs=self.inputs, outputs=self.outputs)def _ctc_init(self):self.labels = Input(name='the_labels', shape=[None], dtype='float32')self.input_length = Input(name='input_length', shape=[1], dtype='int64')self.label_length = Input(name='label_length', shape=[1], dtype='int64')self.loss_out = Lambda(ctc_lambda, output_shape=(1,), name='ctc')\([self.labels, self.outputs, self.input_length, self.label_length])self.ctc_model = Model(inputs=[self.labels, self.inputs,self.input_length, self.label_length], outputs=self.loss_out)def opt_init(self):opt = Adam(lr = self.learning_rate, beta_1 = 0.9, beta_2 = 0.999, decay = 0.01, epsilon = 10e-8)self.ctc_model.compile(loss={'ctc': lambda y_true, output: output}, optimizer=opt)def acoustic_model_hparams():params = HParams(vocab_size = 50,learning_rate = 0.0008,is_training = True)return paramsprint("打印声学模型结构")
acoustic_model_args = acoustic_model_hparams()
acoustic = acoustic_model(acoustic_model_args)
acoustic.ctc_model.summary()
3.2.5 获取数据类
from scipy.fftpack import fft# 获取信号的时频图
def compute_fbank(file):x=np.linspace(0, 400 - 1, 400, dtype = np.int64)w = 0.54 - 0.46 * np.cos(2 * np.pi * (x) / (400 - 1) ) fs, wavsignal = wav.read(file)time_window = 25 window_length = fs / 1000 * time_window wav_arr = np.array(wavsignal)wav_length = len(wavsignal)range0_end = int(len(wavsignal)/fs*1000 - time_window) // 10 data_input = np.zeros((range0_end, 200), dtype = np.float) data_line = np.zeros((1, 400), dtype = np.float)for i in range(0, range0_end):p_start = i * 160p_end = p_start + 400data_line = wav_arr[p_start:p_end] data_line = data_line * w data_line = np.abs(fft(data_line))data_input[i]=data_line[0:200] data_input = np.log(data_input + 1)return data_inputclass get_data():def __init__(self, args):self.data_path = args.data_path self.data_length = args.data_lengthself.batch_size = args.batch_sizeself.source_init()def source_init(self):self.wav_lst = []self.pin_lst = []self.han_lst = []with open('speech_recognition/data.txt', 'r', encoding='utf8') as f:data = f.readlines()for line in data:wav_file, pin, han = line.split('\t')self.wav_lst.append(wav_file)self.pin_lst.append(pin.split(' '))self.han_lst.append(han.strip('\n'))if self.data_length:self.wav_lst = self.wav_lst[:self.data_length]self.pin_lst = self.pin_lst[:self.data_length]self.han_lst = self.han_lst[:self.data_length]self.acoustic_vocab = self.acoustic_model_vocab(self.pin_lst)self.pin_vocab = self.language_model_pin_vocab(self.pin_lst)self.han_vocab = self.language_model_han_vocab(self.han_lst)def get_acoustic_model_batch(self):_list = [i for i in range(len(self.wav_lst))]while 1:for i in range(len(self.wav_lst) // self.batch_size):wav_data_lst = []label_data_lst = []begin = i * self.batch_sizeend = begin + self.batch_sizesub_list = _list[begin:end]for index in sub_list:fbank = compute_fbank(self.data_path + self.wav_lst[index])pad_fbank = np.zeros((fbank.shape[0] // 8 * 8 + 8, fbank.shape[1]))pad_fbank[:fbank.shape[0], :] = fbanklabel = self.pin2id(self.pin_lst[index], self.acoustic_vocab)label_ctc_len = self.ctc_len(label)if pad_fbank.shape[0] // 8 >= label_ctc_len:wav_data_lst.append(pad_fbank)label_data_lst.append(label)pad_wav_data, input_length = self.wav_padding(wav_data_lst)pad_label_data, label_length = self.label_padding(label_data_lst)inputs = {'the_inputs': pad_wav_data,'the_labels': pad_label_data,'input_length': input_length,'label_length': label_length,}outputs = {'ctc': np.zeros(pad_wav_data.shape[0], )}yield inputs, outputsdef get_language_model_batch(self):batch_num = len(self.pin_lst) // self.batch_sizefor k in range(batch_num):begin = k * self.batch_sizeend = begin + self.batch_sizeinput_batch = self.pin_lst[begin:end]label_batch = self.han_lst[begin:end]max_len = max([len(line) for line in input_batch])input_batch = np.array([self.pin2id(line, self.pin_vocab) + [0] * (max_len - len(line)) for line in input_batch])label_batch = np.array([self.han2id(line, self.han_vocab) + [0] * (max_len - len(line)) for line in label_batch])yield input_batch, label_batchdef pin2id(self, line, vocab):return [vocab.index(pin) for pin in line]def han2id(self, line, vocab):return [vocab.index(han) for han in line]def wav_padding(self, wav_data_lst):wav_lens = [len(data) for data in wav_data_lst]wav_max_len = max(wav_lens)wav_lens = np.array([leng // 8 for leng in wav_lens])new_wav_data_lst = np.zeros((len(wav_data_lst), wav_max_len, 200, 1))for i in range(len(wav_data_lst)):new_wav_data_lst[i, :wav_data_lst[i].shape[0], :, 0] = wav_data_lst[i]return new_wav_data_lst, wav_lensdef label_padding(self, label_data_lst):label_lens = np.array([len(label) for label in label_data_lst])max_label_len = max(label_lens)new_label_data_lst = np.zeros((len(label_data_lst), max_label_len))for i in range(len(label_data_lst)):new_label_data_lst[i][:len(label_data_lst[i])] = label_data_lst[i]return new_label_data_lst, label_lensdef acoustic_model_vocab(self, data):vocab = []for line in data:line = linefor pin in line:if pin not in vocab:vocab.append(pin)vocab.append('_')return vocabdef language_model_pin_vocab(self, data):vocab = ['<PAD>']for line in data:for pin in line:if pin not in vocab:vocab.append(pin)return vocabdef language_model_han_vocab(self, data):vocab = ['<PAD>']for line in data:line = ''.join(line.split(' '))for han in line:if han not in vocab:vocab.append(han)return vocabdef ctc_len(self, label):add_len = 0label_len = len(label)for i in range(label_len - 1):if label[i] == label[i + 1]:add_len += 1return label_len + add_len
3.2.6 声学模型训练
为了本示例演示效果,参数batch_size在此仅设置为1,参数data_length在此仅设置为20
若进行完整训练,则应注释data_args.data_length = 20,并调高batch_size
def data_hparams():params = HParams(data_path = './speech_recognition/data/', #d数据路径batch_size = 1, #批尺寸data_length = None, #长度)return paramsdata_args = data_hparams()
data_args.data_length = 20 # 重新训练需要注释该行
train_data = get_data(data_args)acoustic_model_args = acoustic_model_hparams()
acoustic_model_args.vocab_size = len(train_data.acoustic_vocab)
acoustic = acoustic_model(acoustic_model_args)print('声学模型参数:')
print(acoustic_model_args)if os.path.exists('/speech_recognition/acoustic_model/model.h5'):print('加载声学模型')acoustic.ctc_model.load_weights('./speech_recognition/acoustic_model/model.h5')
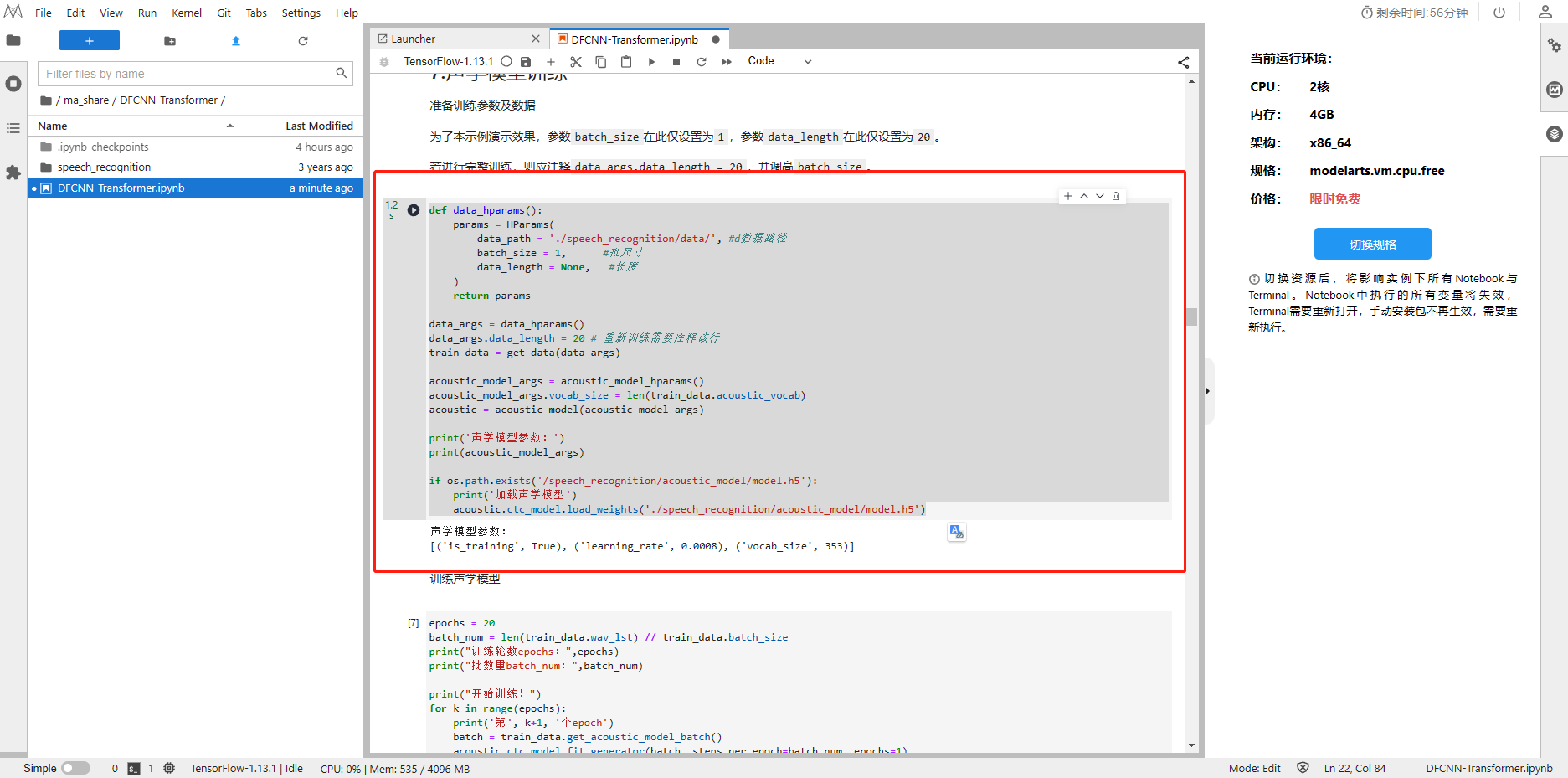
epochs = 20
batch_num = len(train_data.wav_lst) // train_data.batch_size
print("训练轮数epochs:",epochs)
print("批数量batch_num:",batch_num)print("开始训练!")
for k in range(epochs):print('第', k+1, '个epoch')batch = train_data.get_acoustic_model_batch()acoustic.ctc_model.fit_generator(batch, steps_per_epoch=batch_num, epochs=1)print("\n训练完成,保存模型")
acoustic.ctc_model.save_weights('./speech_recognition/acoustic_model/model.h5')
3.2.7 语言模型建模
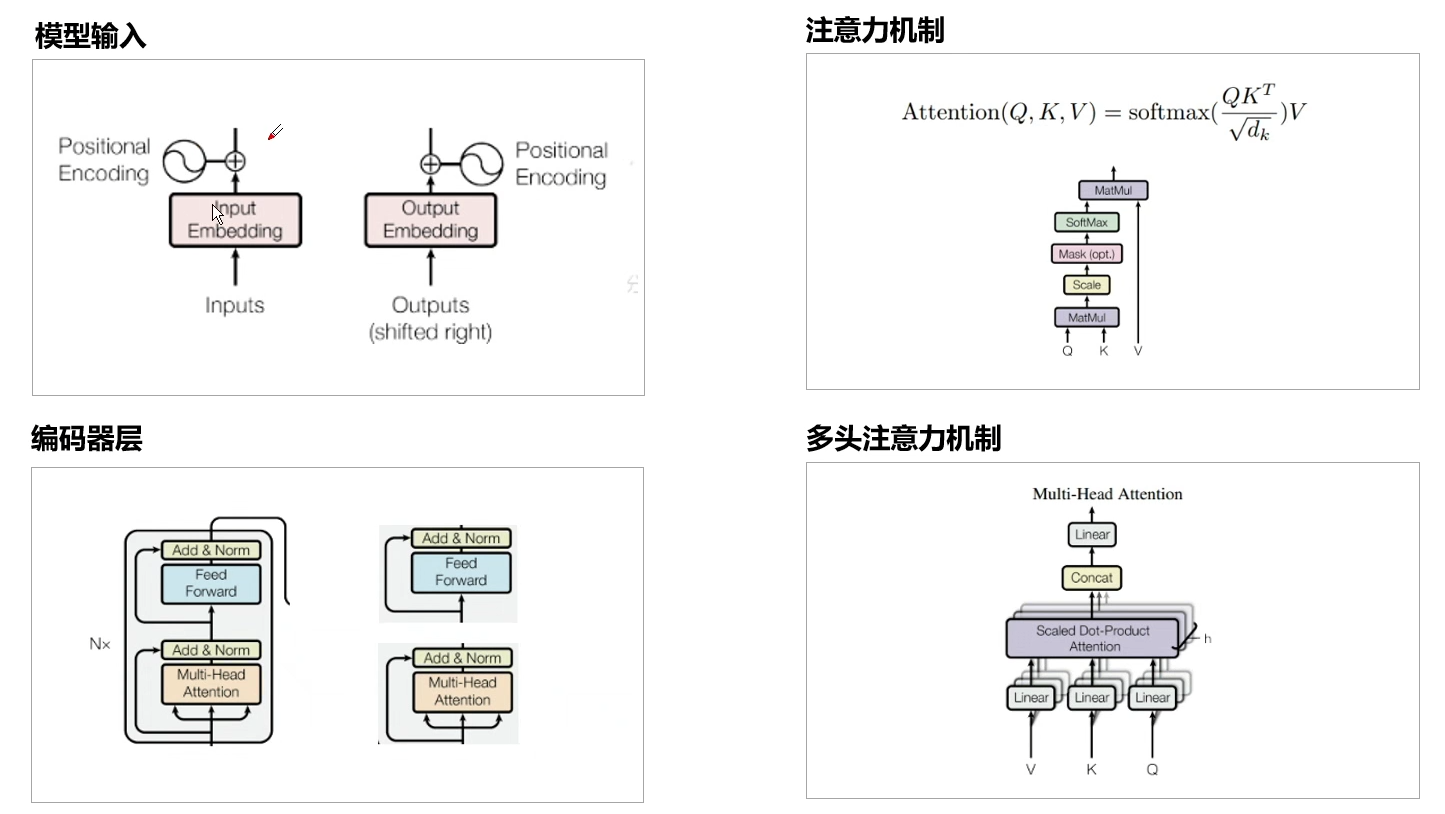
Transformer 是完全基于注意力机制(attention mechanism)的网络框架,attention 来自于论文《attention is all you need》。 一个序列每个字符对其上下文字符的影响作用都不同,每个字对序列的语义信息贡献也不同,可以通过一种机制将原输入序列中字符向量通过加权融合序列中所有字符的语义向量信息来产生新的向量,即增强了原语义信息。
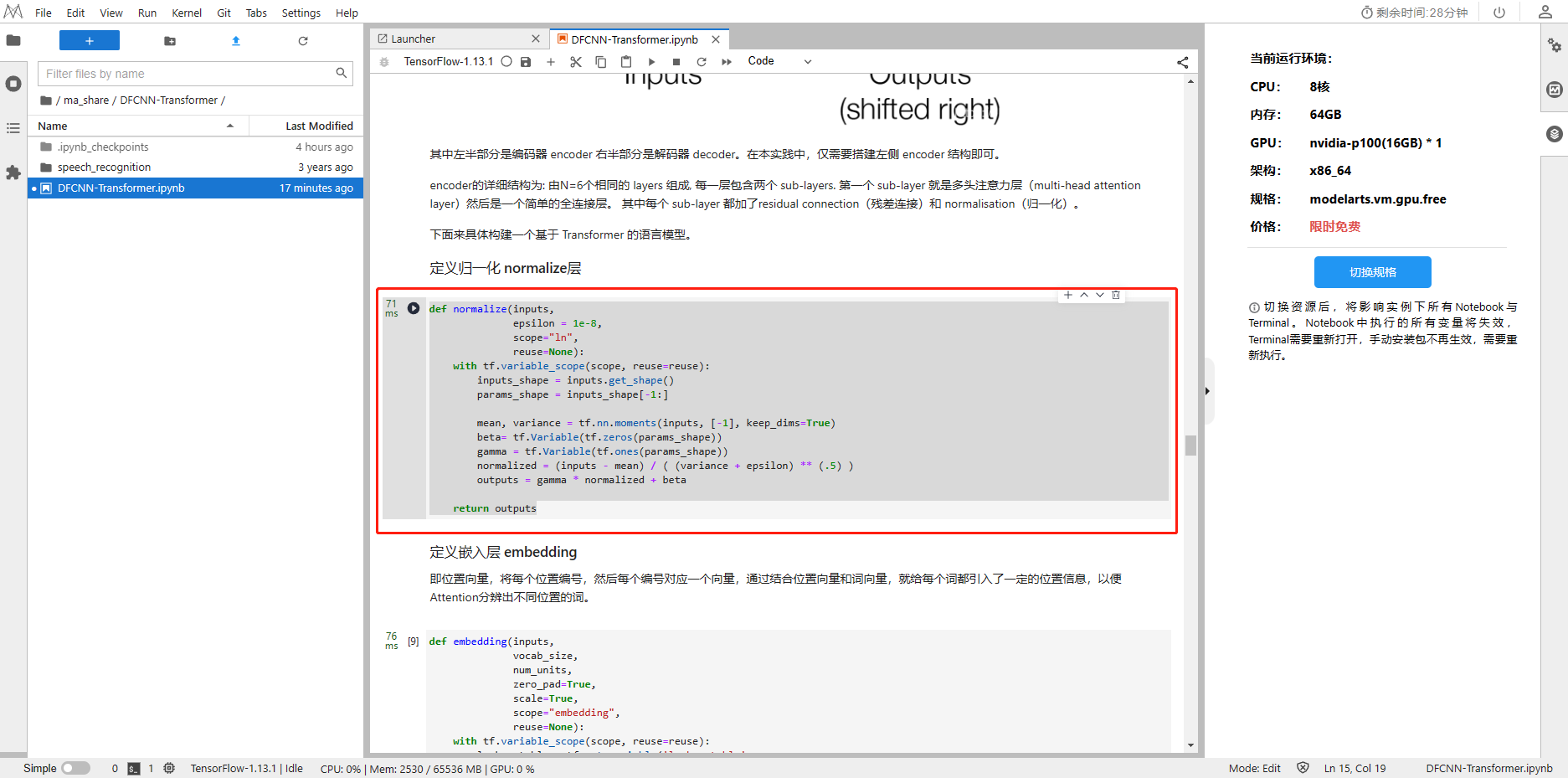
1、定义归一化 normalize层
def normalize(inputs, epsilon = 1e-8,scope="ln",reuse=None):with tf.variable_scope(scope, reuse=reuse):inputs_shape = inputs.get_shape()params_shape = inputs_shape[-1:]mean, variance = tf.nn.moments(inputs, [-1], keep_dims=True)beta= tf.Variable(tf.zeros(params_shape))gamma = tf.Variable(tf.ones(params_shape))normalized = (inputs - mean) / ( (variance + epsilon) ** (.5) )outputs = gamma * normalized + betareturn outputs
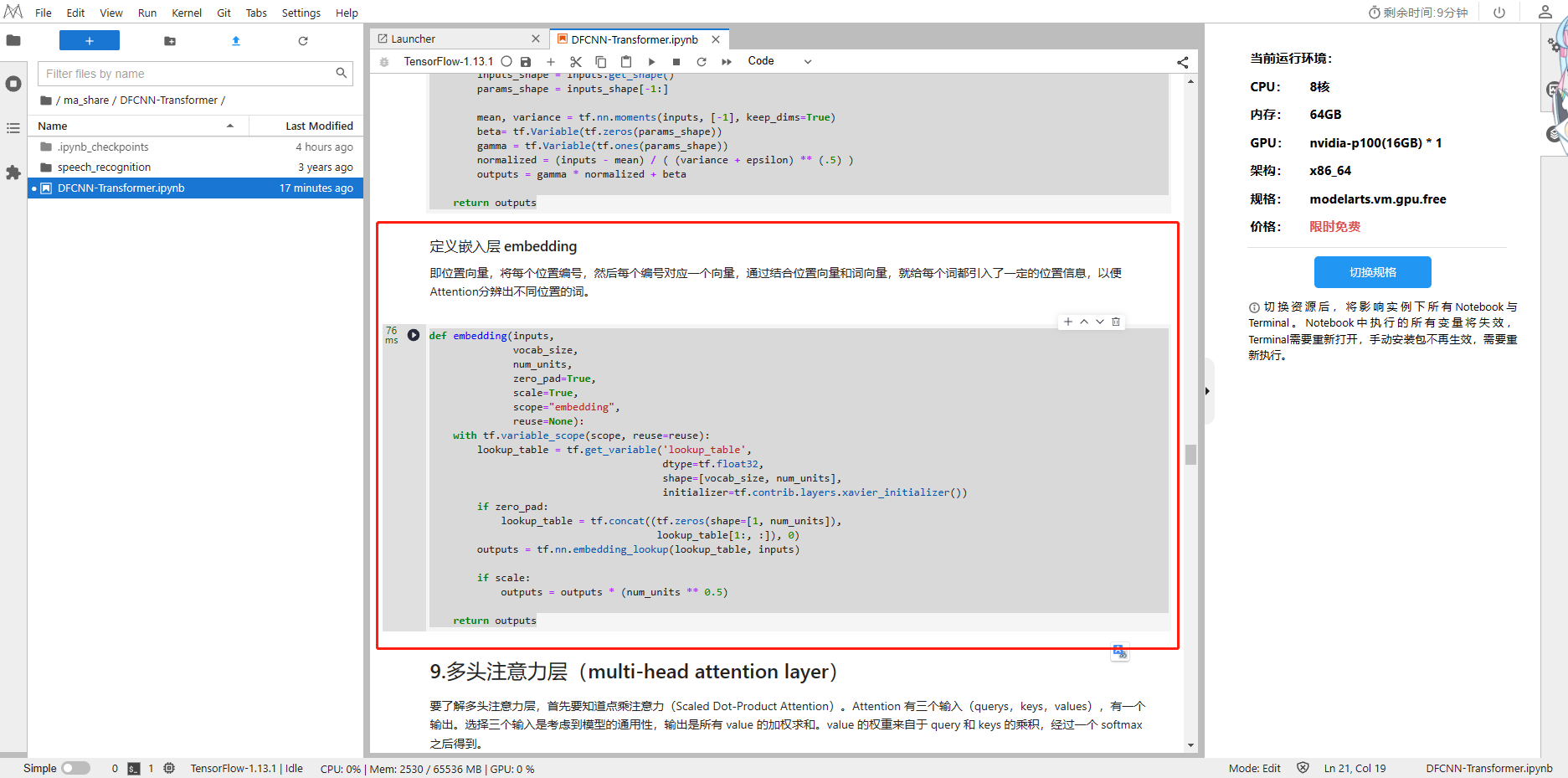
2、定义嵌入层 embedding
def embedding(inputs, vocab_size, num_units, zero_pad=True, scale=True,scope="embedding", reuse=None):with tf.variable_scope(scope, reuse=reuse):lookup_table = tf.get_variable('lookup_table',dtype=tf.float32,shape=[vocab_size, num_units],initializer=tf.contrib.layers.xavier_initializer())if zero_pad:lookup_table = tf.concat((tf.zeros(shape=[1, num_units]),lookup_table[1:, :]), 0)outputs = tf.nn.embedding_lookup(lookup_table, inputs)if scale:outputs = outputs * (num_units ** 0.5) return outputs
3.2.8 多头注意力层
要了解多头注意力层,首先要知道点乘注意力(Scaled Dot-Product Attention)。Attention 有三个输入(querys,keys,values),有一个输出。选择三个输入是考虑到模型的通用性,输出是所有 value 的加权求和。value 的权重来自于 query 和 keys 的乘积,经过一个 softmax 之后得到。
1、定义 multi-head attention层
def multihead_attention(emb,queries, keys, num_units=None, num_heads=8, dropout_rate=0,is_training=True,causality=False,scope="multihead_attention", reuse=None):with tf.variable_scope(scope, reuse=reuse):if num_units is None:num_units = queries.get_shape().as_list[-1]Q = tf.layers.dense(queries, num_units, activation=tf.nn.relu) # (N, T_q, C)K = tf.layers.dense(keys, num_units, activation=tf.nn.relu) # (N, T_k, C)V = tf.layers.dense(keys, num_units, activation=tf.nn.relu) # (N, T_k, C)Q_ = tf.concat(tf.split(Q, num_heads, axis=2), axis=0) # (h*N, T_q, C/h) K_ = tf.concat(tf.split(K, num_heads, axis=2), axis=0) # (h*N, T_k, C/h) V_ = tf.concat(tf.split(V, num_heads, axis=2), axis=0) # (h*N, T_k, C/h) outputs = tf.matmul(Q_, tf.transpose(K_, [0, 2, 1])) # (h*N, T_q, T_k)outputs = outputs / (K_.get_shape().as_list()[-1] ** 0.5)key_masks = tf.sign(tf.abs(tf.reduce_sum(emb, axis=-1))) # (N, T_k)key_masks = tf.tile(key_masks, [num_heads, 1]) # (h*N, T_k)key_masks = tf.tile(tf.expand_dims(key_masks, 1), [1, tf.shape(queries)[1], 1]) # (h*N, T_q, T_k)paddings = tf.ones_like(outputs)*(-2**32+1)outputs = tf.where(tf.equal(key_masks, 0), paddings, outputs) # (h*N, T_q, T_k)if causality:diag_vals = tf.ones_like(outputs[0, :, :]) # (T_q, T_k)tril = tf.contrib.linalg.LinearOperatorTriL(diag_vals).to_dense() # (T_q, T_k)masks = tf.tile(tf.expand_dims(tril, 0), [tf.shape(outputs)[0], 1, 1]) # (h*N, T_q, T_k)paddings = tf.ones_like(masks)*(-2**32+1)outputs = tf.where(tf.equal(masks, 0), paddings, outputs) # (h*N, T_q, T_k)outputs = tf.nn.softmax(outputs) # (h*N, T_q, T_k)query_masks = tf.sign(tf.abs(tf.reduce_sum(emb, axis=-1))) # (N, T_q)query_masks = tf.tile(query_masks, [num_heads, 1]) # (h*N, T_q)query_masks = tf.tile(tf.expand_dims(query_masks, -1), [1, 1, tf.shape(keys)[1]]) # (h*N, T_q, T_k)outputs *= query_masks # broadcasting. (N, T_q, C)outputs = tf.layers.dropout(outputs, rate=dropout_rate, training=tf.convert_to_tensor(is_training))outputs = tf.matmul(outputs, V_) # ( h*N, T_q, C/h)outputs = tf.concat(tf.split(outputs, num_heads, axis=0), axis=2 ) # (N, T_q, C)outputs += queriesoutputs = normalize(outputs) # (N, T_q, C)return outputs
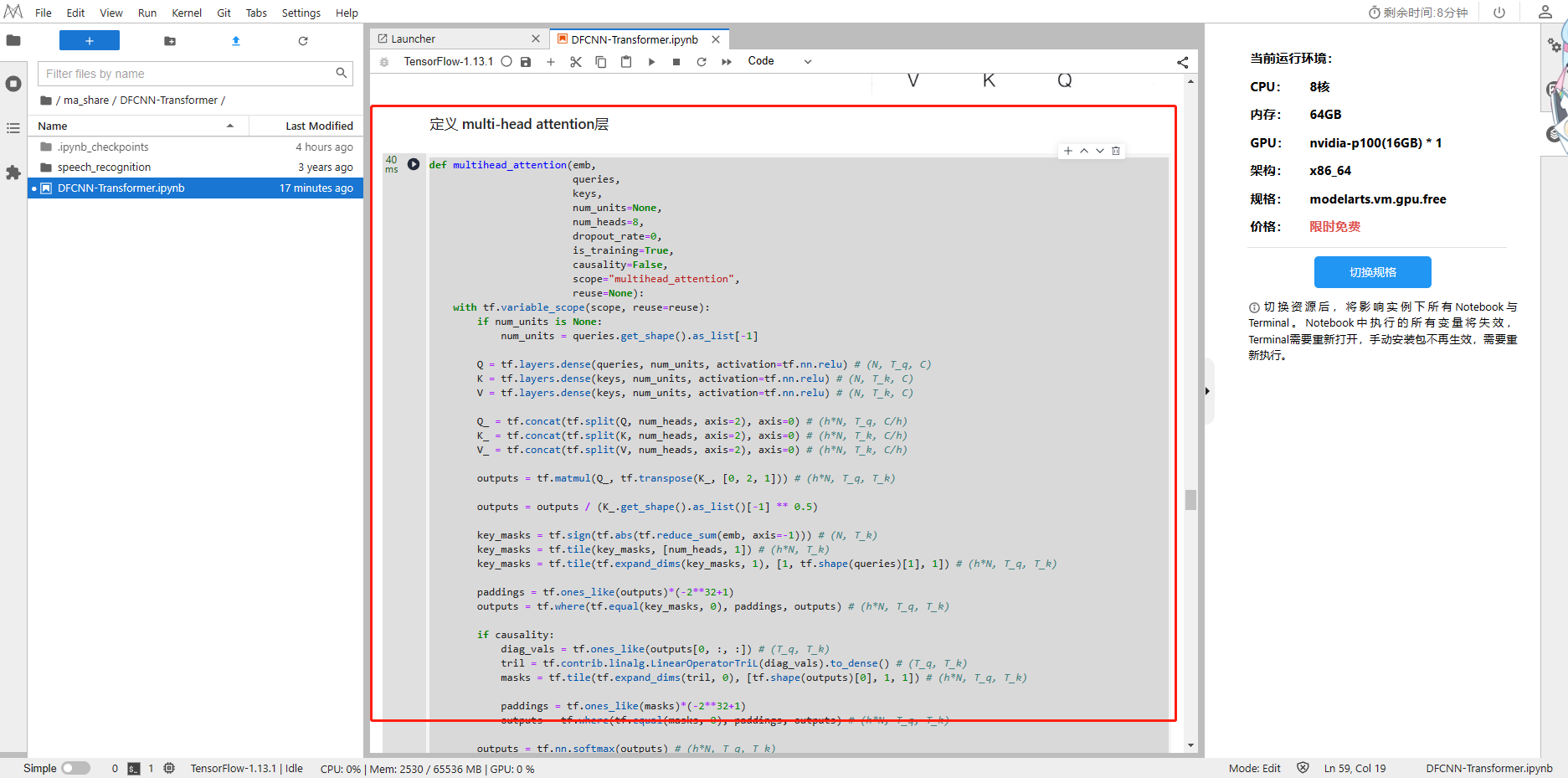
2、定义 feedforward层
def feedforward(inputs, num_units=[2048, 512],scope="multihead_attention", reuse=None):with tf.variable_scope(scope, reuse=reuse):params = {"inputs": inputs, "filters": num_units[0], "kernel_size": 1,"activation": tf.nn.relu, "use_bias": True}outputs = tf.layers.conv1d(**params)params = {"inputs": outputs, "filters": num_units[1], "kernel_size": 1,"activation": None, "use_bias": True}outputs = tf.layers.conv1d(**params)outputs += inputsoutputs = normalize(outputs)return outputs
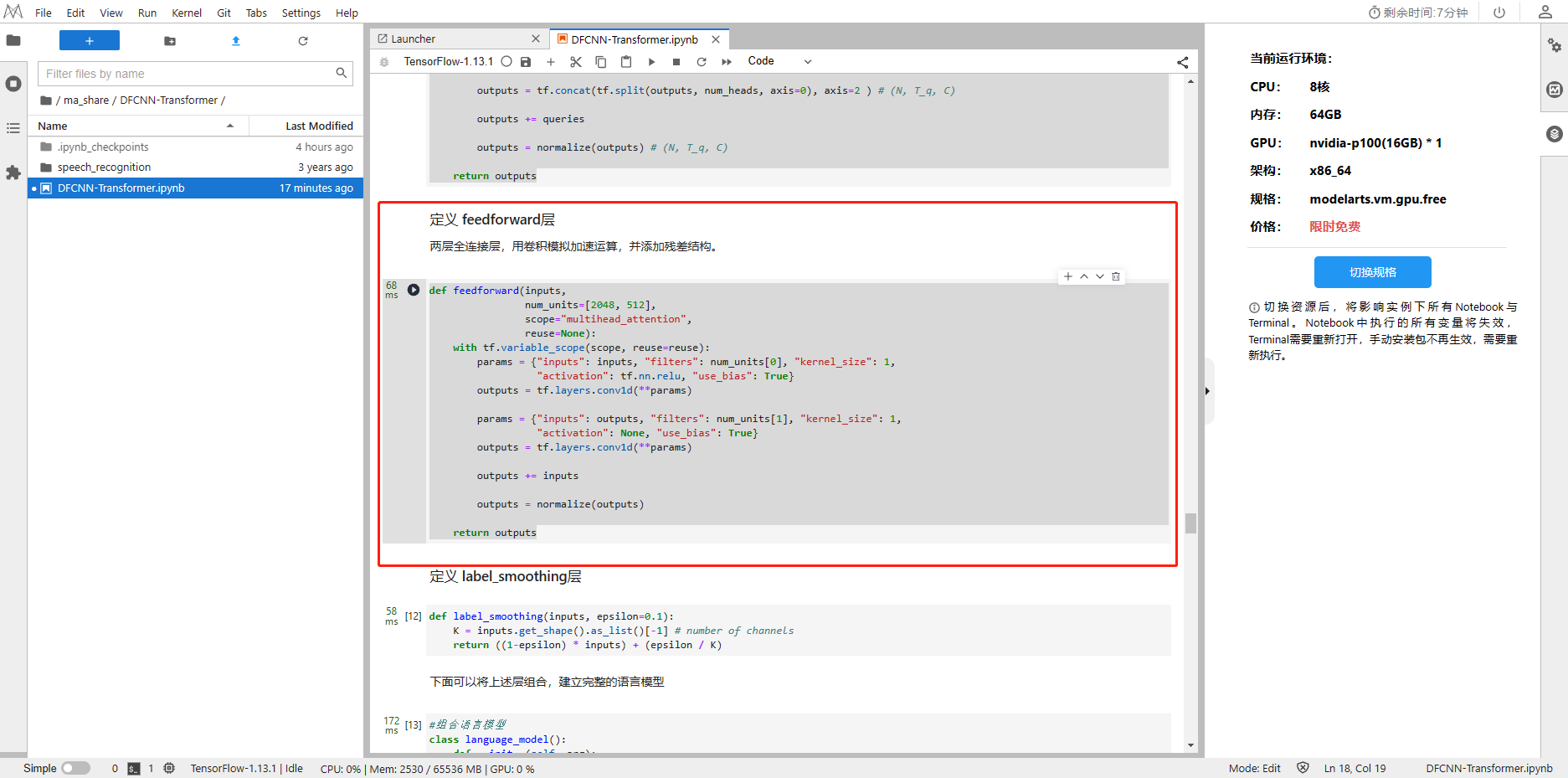
3、定义 label_smoothing层
def label_smoothing(inputs, epsilon=0.1):K = inputs.get_shape().as_list()[-1] # number of channelsreturn ((1-epsilon) * inputs) + (epsilon / K)
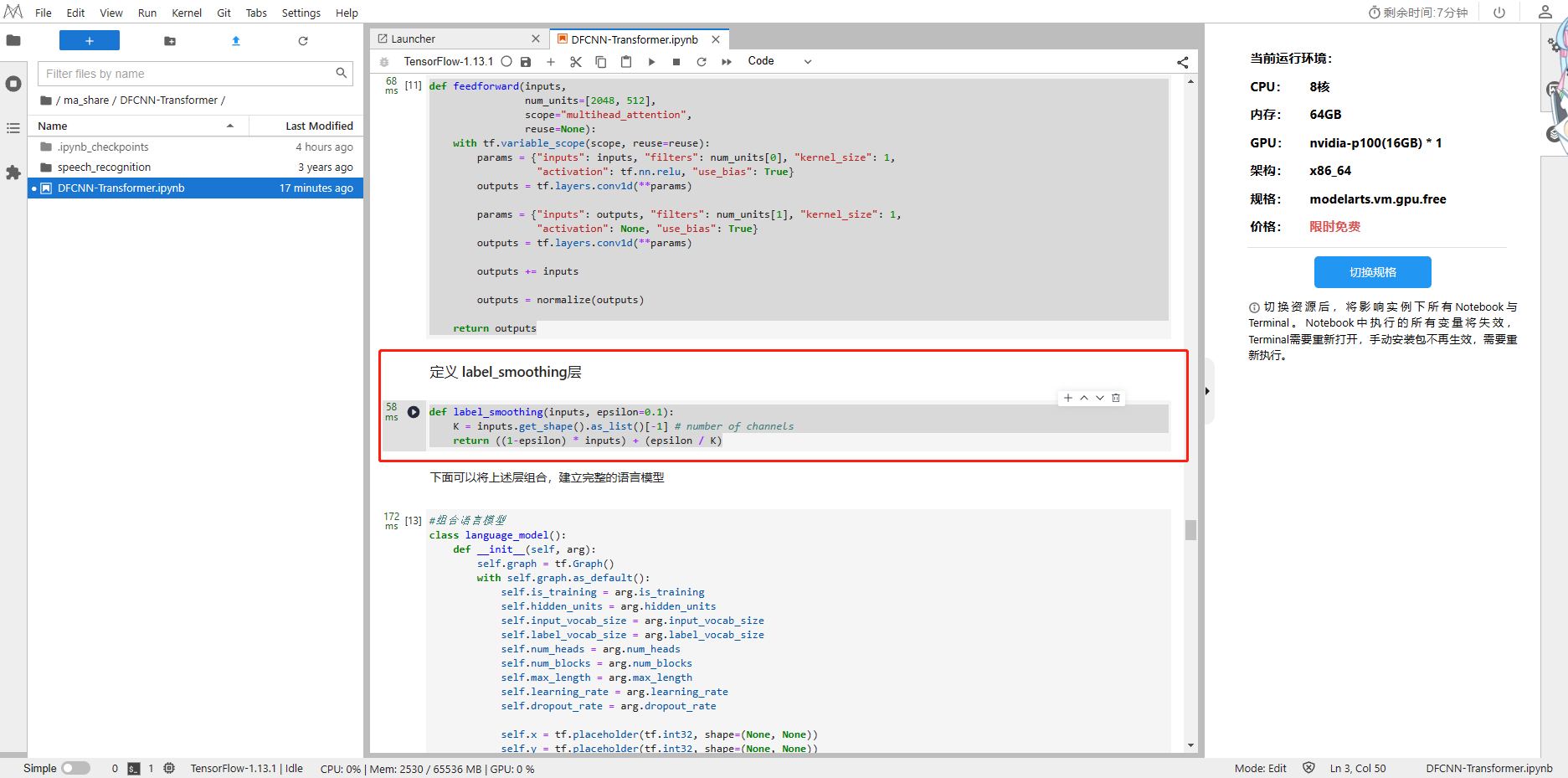
#组合语言模型
class language_model():def __init__(self, arg):self.graph = tf.Graph()with self.graph.as_default():self.is_training = arg.is_trainingself.hidden_units = arg.hidden_unitsself.input_vocab_size = arg.input_vocab_sizeself.label_vocab_size = arg.label_vocab_sizeself.num_heads = arg.num_headsself.num_blocks = arg.num_blocksself.max_length = arg.max_lengthself.learning_rate = arg.learning_rateself.dropout_rate = arg.dropout_rateself.x = tf.placeholder(tf.int32, shape=(None, None))self.y = tf.placeholder(tf.int32, shape=(None, None))self.emb = embedding(self.x, vocab_size=self.input_vocab_size, num_units=self.hidden_units, scale=True, scope="enc_embed")self.enc = self.emb + embedding(tf.tile(tf.expand_dims(tf.range(tf.shape(self.x)[1]), 0), [tf.shape(self.x)[0], 1]),vocab_size=self.max_length,num_units=self.hidden_units, zero_pad=False, scale=False,scope="enc_pe")self.enc = tf.layers.dropout(self.enc, rate=self.dropout_rate, training=tf.convert_to_tensor(self.is_training))for i in range(self.num_blocks):with tf.variable_scope("num_blocks_{}".format(i)):self.enc = multihead_attention(emb = self.emb,queries=self.enc, keys=self.enc, num_units=self.hidden_units, num_heads=self.num_heads, dropout_rate=self.dropout_rate,is_training=self.is_training,causality=False)self.outputs = feedforward(self.enc, num_units=[4*self.hidden_units, self.hidden_units])self.logits = tf.layers.dense(self.outputs, self.label_vocab_size)self.preds = tf.to_int32(tf.argmax(self.logits, axis=-1))self.istarget = tf.to_float(tf.not_equal(self.y, 0))self.acc = tf.reduce_sum(tf.to_float(tf.equal(self.preds, self.y))*self.istarget)/ (tf.reduce_sum(self.istarget))tf.summary.scalar('acc', self.acc)if self.is_training: self.y_smoothed = label_smoothing(tf.one_hot(self.y, depth=self.label_vocab_size))self.loss = tf.nn.softmax_cross_entropy_with_logits_v2(logits=self.logits, labels=self.y_smoothed)self.mean_loss = tf.reduce_sum(self.loss*self.istarget) / (tf.reduce_sum(self.istarget))self.global_step = tf.Variable(0, name='global_step', trainable=False)self.optimizer = tf.train.AdamOptimizer(learning_rate=self.learning_rate, beta1=0.9, beta2=0.98, epsilon=1e-8)self.train_op = self.optimizer.minimize(self.mean_loss, global_step=self.global_step)tf.summary.scalar('mean_loss', self.mean_loss)self.merged = tf.summary.merge_all()print('语音模型建立完成!')
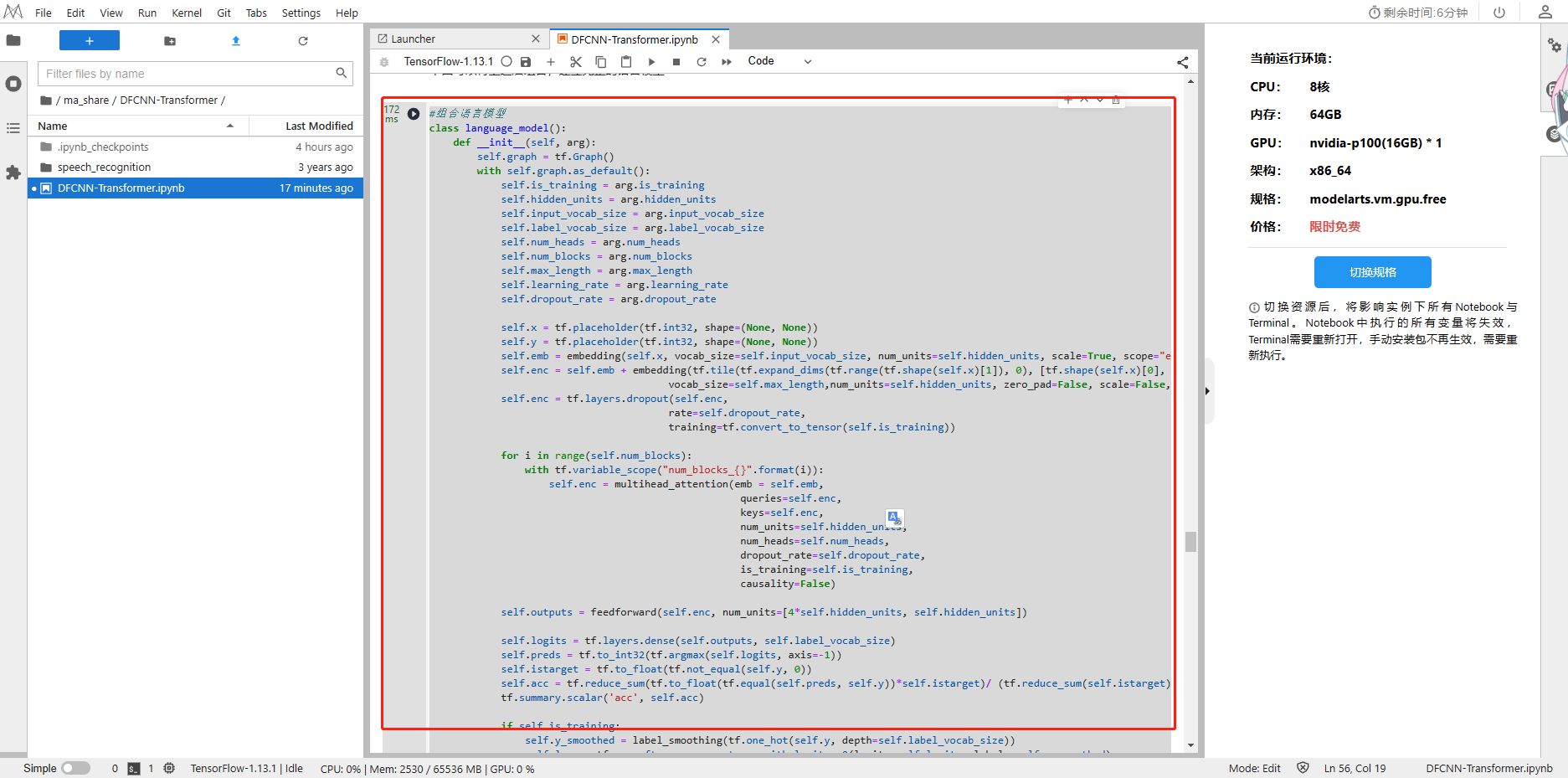
3.2.9 语言模型训练
1、准备训练参数及数据
def language_model_hparams():params = HParams(num_heads = 8,num_blocks = 6,input_vocab_size = 50,label_vocab_size = 50,max_length = 100,hidden_units = 512,dropout_rate = 0.2,learning_rate = 0.0003,is_training = True)return paramslanguage_model_args = language_model_hparams()
language_model_args.input_vocab_size = len(train_data.pin_vocab)
language_model_args.label_vocab_size = len(train_data.han_vocab)
language = language_model(language_model_args)print('语言模型参数:')
print(language_model_args)
2、训练语言模型
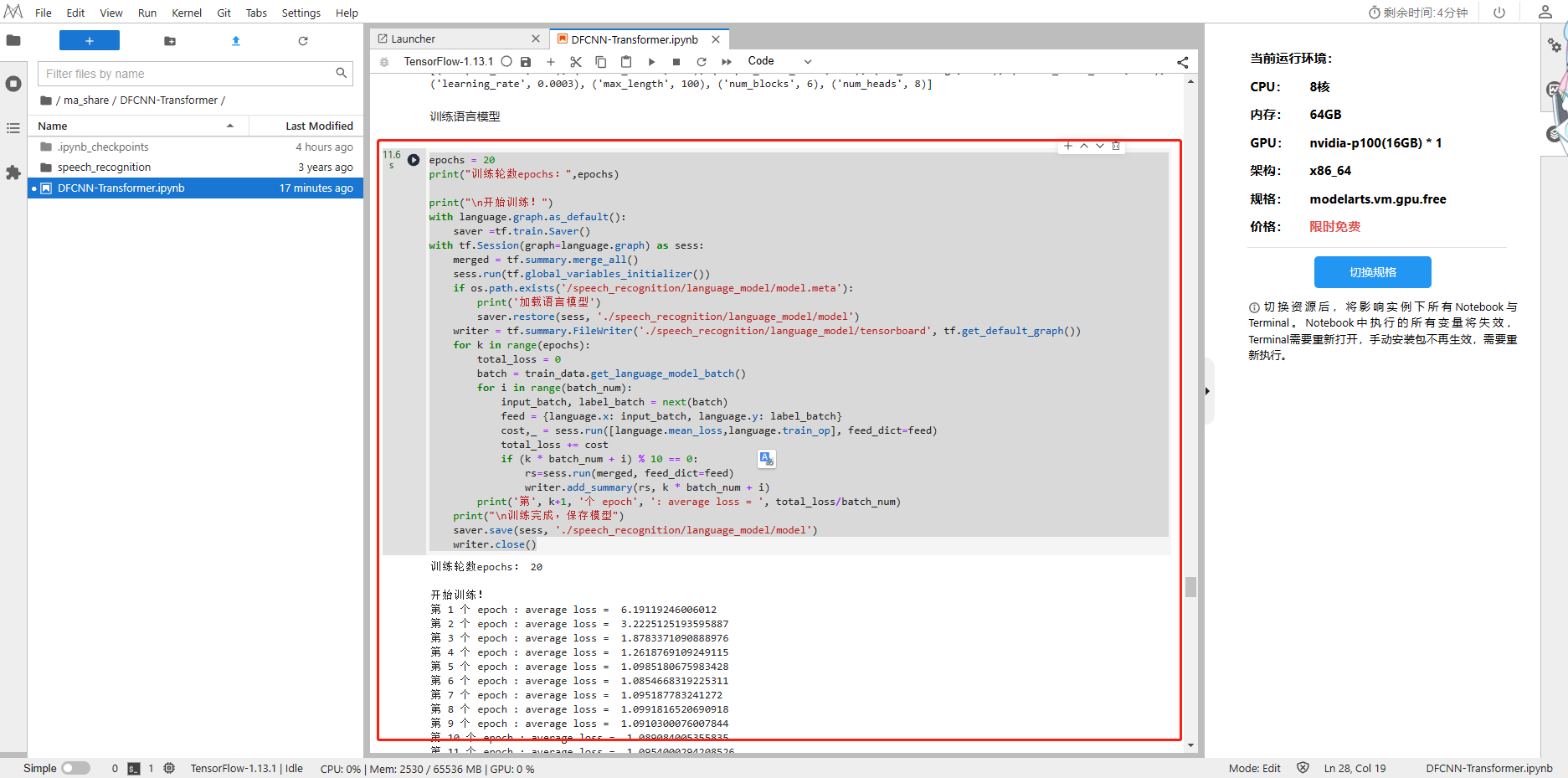
epochs = 20
print("训练轮数epochs:",epochs)print("\n开始训练!")
with language.graph.as_default():saver =tf.train.Saver()
with tf.Session(graph=language.graph) as sess:merged = tf.summary.merge_all()sess.run(tf.global_variables_initializer())if os.path.exists('/speech_recognition/language_model/model.meta'):print('加载语言模型')saver.restore(sess, './speech_recognition/language_model/model')writer = tf.summary.FileWriter('./speech_recognition/language_model/tensorboard', tf.get_default_graph())for k in range(epochs):total_loss = 0batch = train_data.get_language_model_batch()for i in range(batch_num):input_batch, label_batch = next(batch)feed = {language.x: input_batch, language.y: label_batch}cost,_ = sess.run([language.mean_loss,language.train_op], feed_dict=feed)total_loss += costif (k * batch_num + i) % 10 == 0:rs=sess.run(merged, feed_dict=feed)writer.add_summary(rs, k * batch_num + i)print('第', k+1, '个 epoch', ': average loss = ', total_loss/batch_num)print("\n训练完成,保存模型")saver.save(sess, './speech_recognition/language_model/model')writer.close()
3.2.10 模型测试
1、准备解码所需字典,需和训练一致,也可以将字典保存到本地,直接进行读取
data_args = data_hparams()
data_args.data_length = 20 # 重新训练需要注释该行
train_data = get_data(data_args)
2、准备测试所需数据, 不必和训练数据一致。
test_data = get_data(data_args)
acoustic_model_batch = test_data.get_acoustic_model_batch()
language_model_batch = test_data.get_language_model_batch()
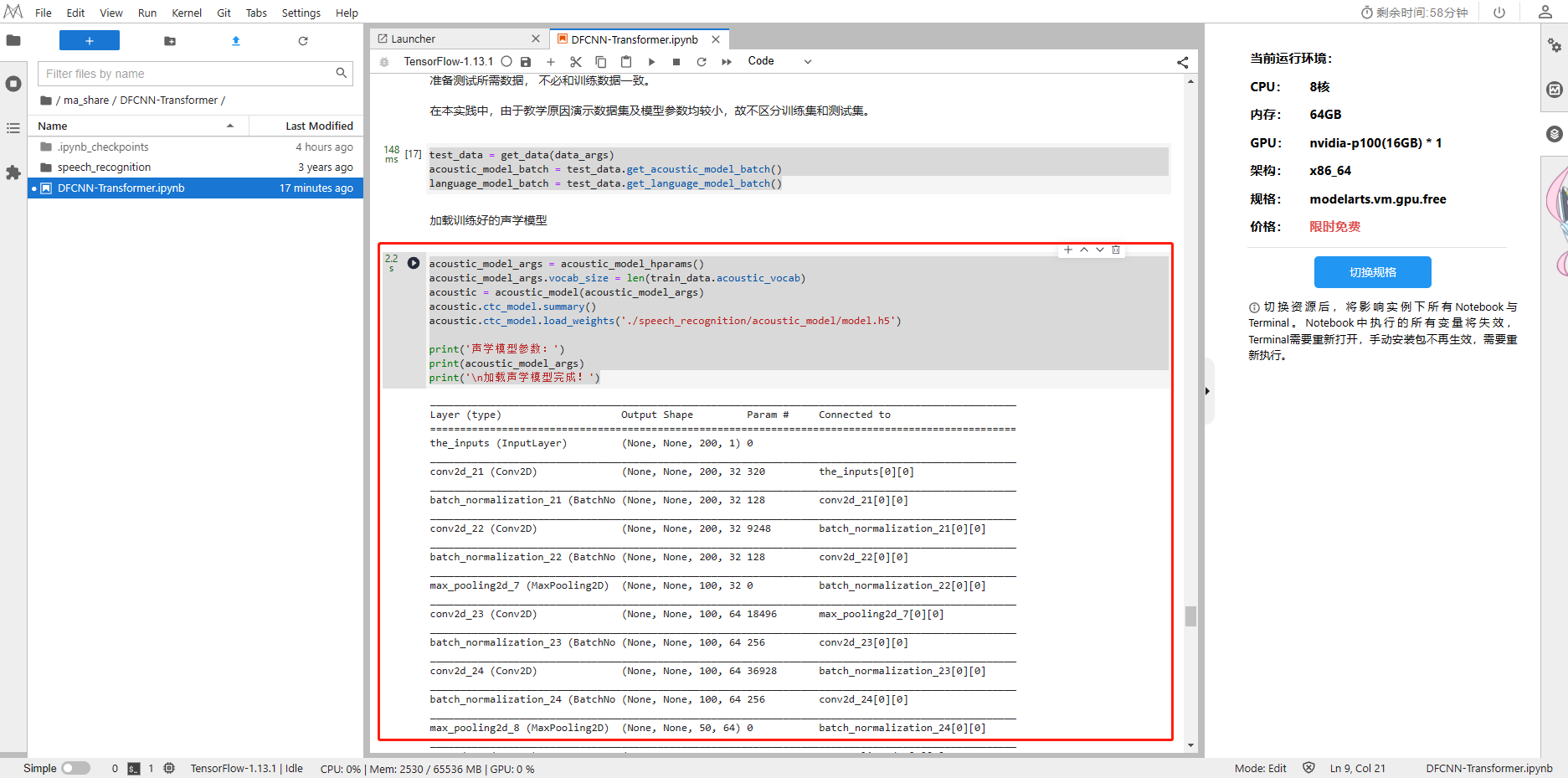
3、加载训练好的声学模型
acoustic_model_args = acoustic_model_hparams()
acoustic_model_args.vocab_size = len(train_data.acoustic_vocab)
acoustic = acoustic_model(acoustic_model_args)
acoustic.ctc_model.summary()
acoustic.ctc_model.load_weights('./speech_recognition/acoustic_model/model.h5')print('声学模型参数:')
print(acoustic_model_args)
print('\n加载声学模型完成!')
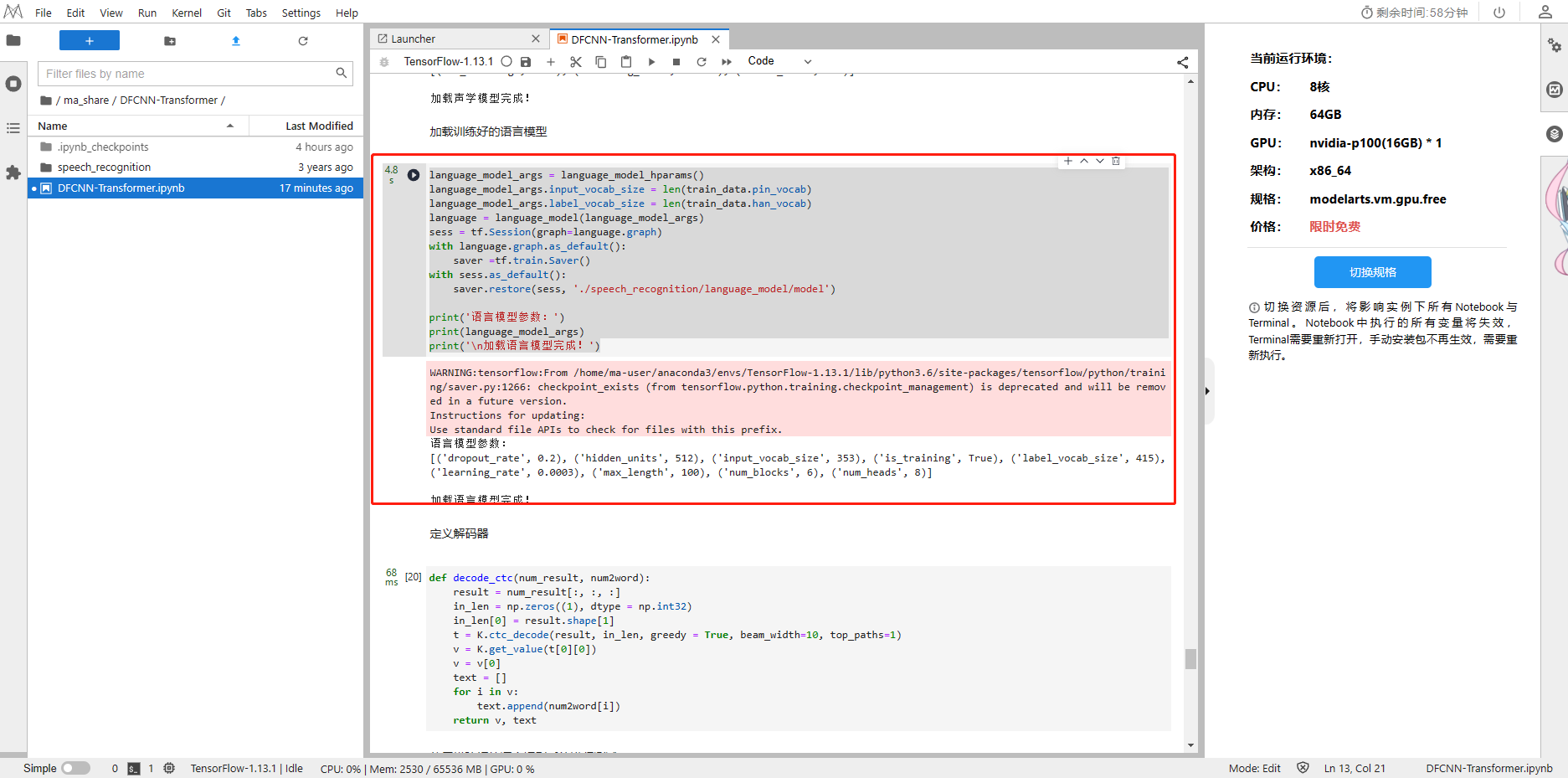
4、加载训练好的语言模型
language_model_args = language_model_hparams()
language_model_args.input_vocab_size = len(train_data.pin_vocab)
language_model_args.label_vocab_size = len(train_data.han_vocab)
language = language_model(language_model_args)
sess = tf.Session(graph=language.graph)
with language.graph.as_default():saver =tf.train.Saver()
with sess.as_default():saver.restore(sess, './speech_recognition/language_model/model')print('语言模型参数:')
print(language_model_args)
print('\n加载语言模型完成!')
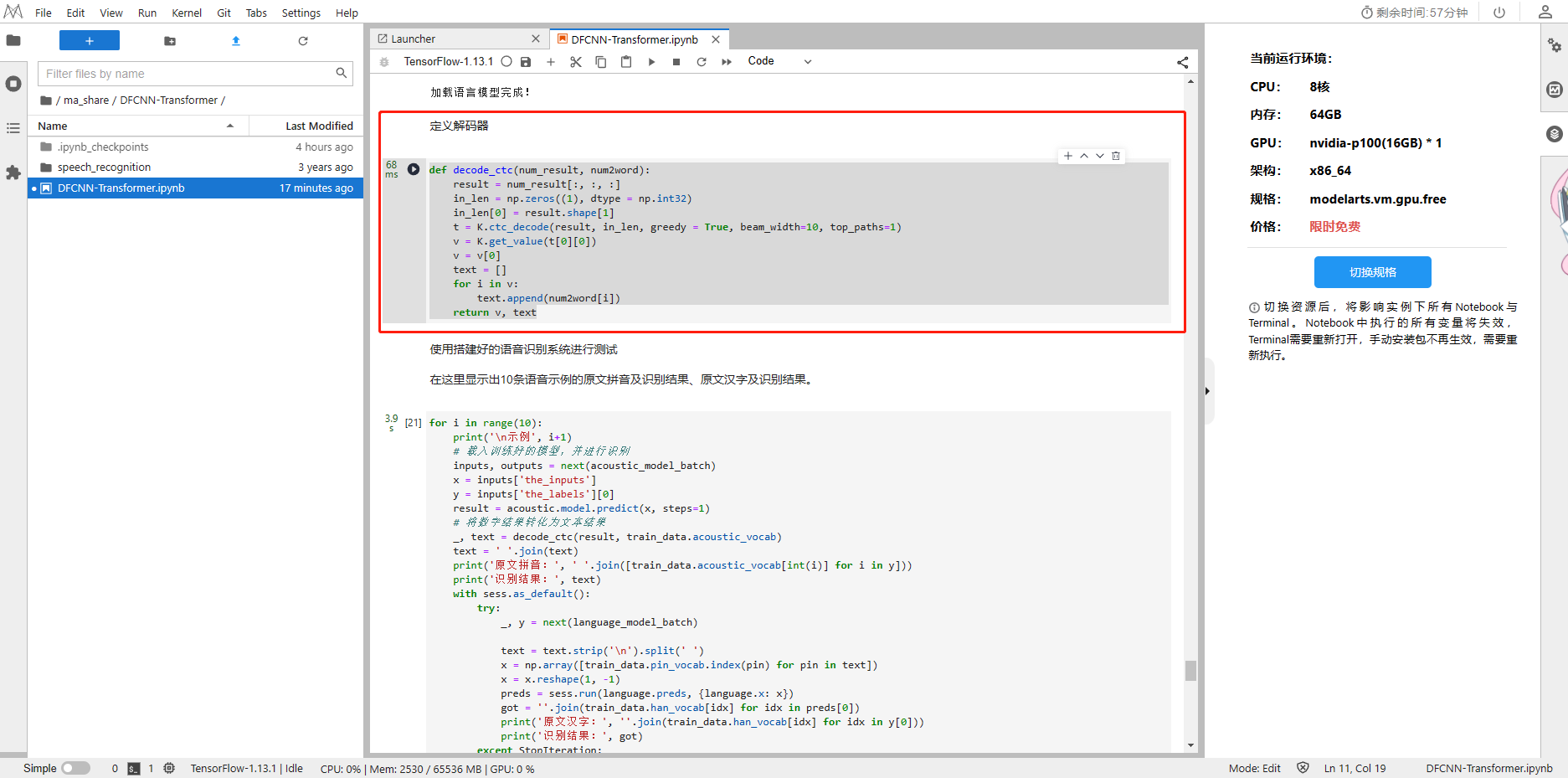
5、定义解码器
def decode_ctc(num_result, num2word):result = num_result[:, :, :]in_len = np.zeros((1), dtype = np.int32)in_len[0] = result.shape[1]t = K.ctc_decode(result, in_len, greedy = True, beam_width=10, top_paths=1)v = K.get_value(t[0][0])v = v[0]text = []for i in v:text.append(num2word[i])return v, text
6、测试语音识别
for i in range(10):print('\n示例', i+1)# 载入训练好的模型,并进行识别inputs, outputs = next(acoustic_model_batch)x = inputs['the_inputs']y = inputs['the_labels'][0]result = acoustic.model.predict(x, steps=1)# 将数字结果转化为文本结果_, text = decode_ctc(result, train_data.acoustic_vocab)text = ' '.join(text)print('原文拼音:', ' '.join([train_data.acoustic_vocab[int(i)] for i in y]))print('识别结果:', text)with sess.as_default():try:_, y = next(language_model_batch)text = text.strip('\n').split(' ')x = np.array([train_data.pin_vocab.index(pin) for pin in text])x = x.reshape(1, -1)preds = sess.run(language.preds, {language.x: x})got = ''.join(train_data.han_vocab[idx] for idx in preds[0])print('原文汉字:', ''.join(train_data.han_vocab[idx] for idx in y[0]))print('识别结果:', got)except StopIteration:break
sess.close()
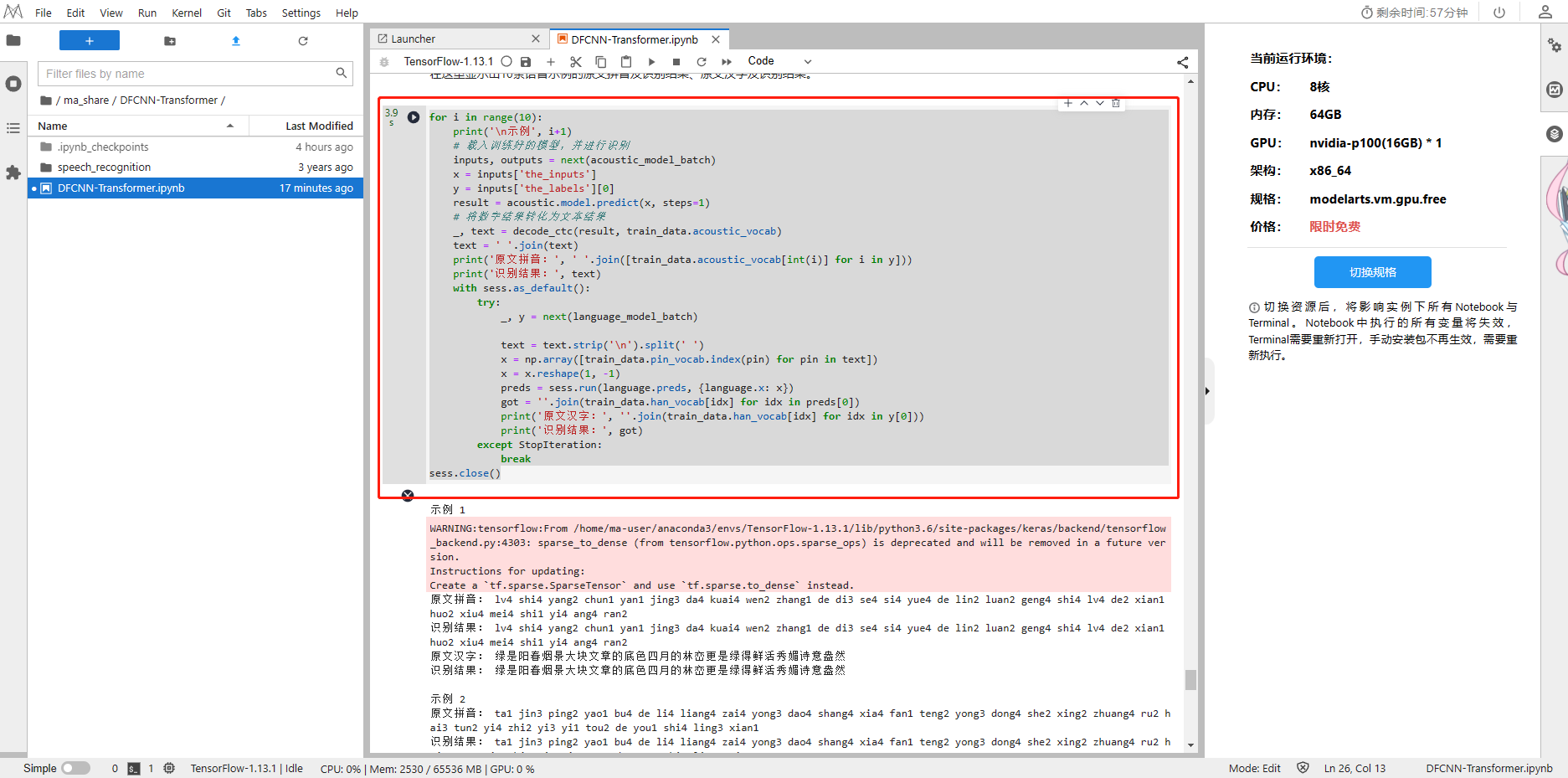
可以看到识别结果,准确率还是很高的

总结
语音识别系统是一种人工智能技术,它可以将人类语音转换为计算机可识别的文本或指令。这种技术可以应用于语音助手、智能家居、语音搜索、语音翻译等领域。语音识别系统通常包括语音信号采集、信号预处理、特征提取、模型训练和识别等步骤。其中,模型训练是关键的一步,它需要使用大量的语音数据进行训练,以提高识别准确率。目前,市面上已经有很多成熟的语音识别系统,例如百度语音、阿里云语音、微软小冰等。
ModelArts进行模型训练的优势包括:高效的分布式训练、自动化的超参数调优、灵活的模型管理、安全的数据隔离和多样的算法支持等。此外,ModelArts还提供了丰富的数据预处理和模型评估功能,帮助用户更快速、更准确地完成模型训练和部署。
基于ModelArts搭建中文语音识别系统的优势在于其高准确率和稳定性,同时支持多种语言和方言,具有较好的适应性和可扩展性。此外,该系统还具备较高的实时性和处理速度,能够满足各种语音识别场景的需求。