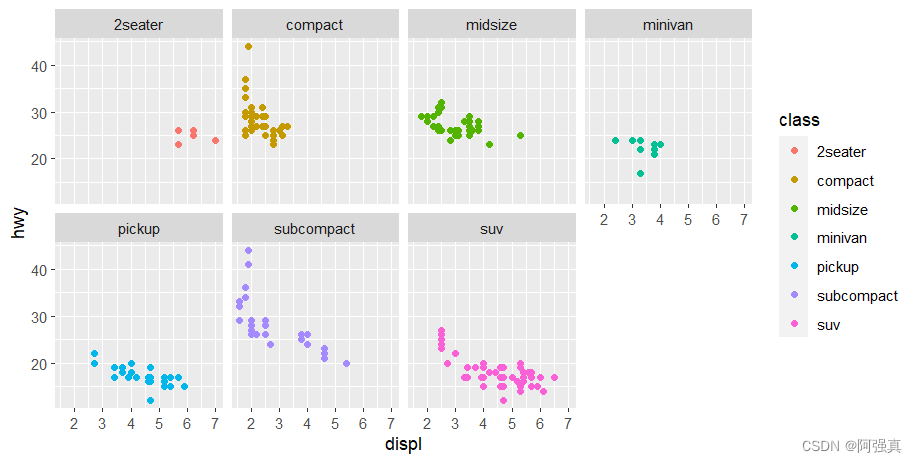
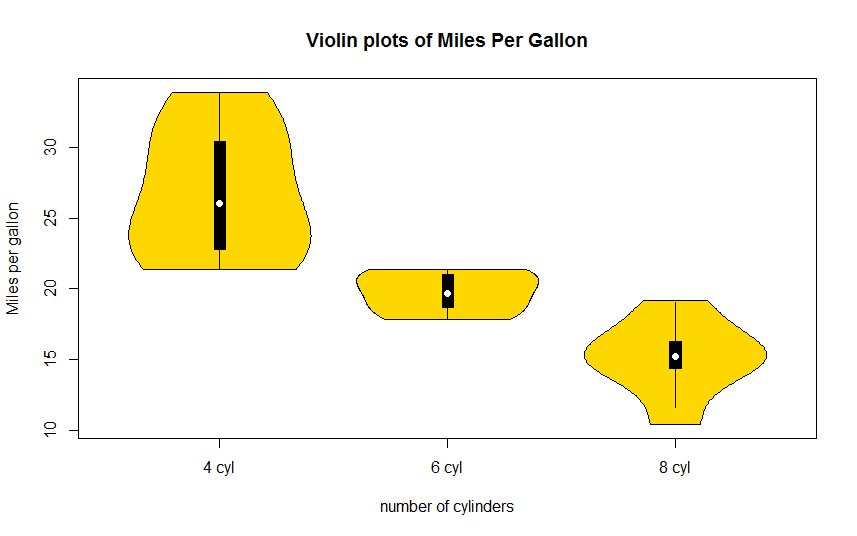
最近直播答题很火,凑了一段时间热门,最好用的还是百度的语音搜索,速度很快。可惜有时候题目太长,没时间去念题,所以琢磨了一下写了这个小小的软件来辅助搜索答案。
基本的思路很简单,要利用安卓的模拟器,题目出来后,把题目截图,然后用OCR识别,最后用百度搜索。
中间绕了很多弯路,想过用tesseract,也用过onenote,识别效果都不好,最后还是不得不用了百度的OCR,虽然是收费的,效果还是刚刚的,识别率基本100%,基本2-3秒出搜索结果。
最终的效果图如下:

看一下视频效果
演示视频一
演示视频二
软件使用很简单,点击“选择识别区域”按钮后,先在屏幕上画个框,题目一出来马上按“识别按钮”,百度搜索结果就出来了。
窗口的代码就不帖了,把python提交的代码贴一下。
# -*- coding: utf-8 -*-
import sys, urllib, urllib2, json
import base64
import StringIO
reload(sys)
sys.setdefaultencoding('utf8')APPKEY=你的APPKey
SecretKey=你的SecretKEY#token
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id='+APPKEY+'&client_secret='+SecretKey
request = urllib2.Request(host)
request.add_header('Content-Type', 'application/json; charset=UTF-8')
response = urllib2.urlopen(request)
content = response.read()
result=json.loads(content)
if (content):token=result.get("access_token")url = 'https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic?access_token='+token
data = {} #
data['languagetype'] = "CHN_ENG"
#data['imagetype'] = "1"# read picture
file = open('question.jpg', 'rb')
image = file.read()
file.close()
data['image'] = base64.b64encode(image)
decoded_data = urllib.urlencode(data)
req2 = urllib2.Request(url, data=decoded_data)
req2.add_header("Content-Type", "application/x-www-form-urlencoded")resp = urllib2.urlopen(req2)
content = resp.read()
result=json.loads(content)linenum=result["words_result_num"]
words=""
for i in range(0,linenum):words = words+ result["words_result"][i]["words"]
f=open(sys.path[0] + '/result.txt', 'wb+')
f.write(words)
f.close()








![[R语言绘图]plot函数的使用](https://img-blog.csdn.net/20150608113055259)