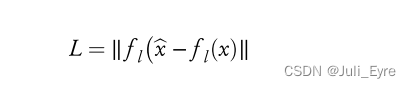一些专有名词缩写:automated border control (ABC) systems. 自动控制系统、面部识别(FR).面部识别、LBP(Local Binary Pattern,局部二值模式)
面部识别(FR)已成为身份认证的主要生物识别技术,并广泛用于各类领域,如金融,军事,公共安全和日常生活。 典型的FR系统的最终目标是识别或验证来自数字图像或来自视频源的视频帧的人。 通常将FR描述为基于智能的人工生物测量应用,通过分析人的面部特征的模式,可以唯一地识别人。
本文件的主要贡献是:
1.对FR系统的对抗生成方法的研究进行了审查,提出了符合其取向的对应方法的说明性分类,并比较了这些关于取向和属性的方法。
2.回顾了针对FR系统的新对抗示例检测方法,对所提出的算法进行了分类,并展示了这种分类的描述性分类。
3.根据四个主要问题解决了针对对抗样本的FR模型的主要挑战和潜在解决方案:对抗样本的特殊性,FR模型的不稳定性,偏离人类视觉系统和图像不可知的扰动生成。
本文的其余部分按以下方式组织:第二节介绍了FR技术,架构和数据库的背景。 在第三节中,我们描述了在FR课程背景下与对抗攻击和防御相关的标准术语,描述了攻击属性,解释了实验标准,并讨论了生成攻击的先驱方法。 审查了旨在减少第四节中FR任务的对抗示例生成方法。 讨论了方法,并比较了基于方向和属性的方法。后几节为对应措施、当前挑战和潜在的未来研究方向的讨论。
1 白盒攻击(White Box Attack):攻击者掌握对方系统的所有信息,包括使用何种方法,算法输出结果,计算中的梯度等等。这种场景是指当攻击者完全攻入目标系统的时候;
2 黑盒攻击(Black Box Attack):攻击者只能查询到有限的攻击结果,对目标系统的机制完全不了解。这种攻击难度最大,对与防御方的危害也最大。
根据攻击的特殊性,将深FR系统中的威胁模型归类为两大类型:
1 Targeted attack 减少了错误预测对抗样本的特定标签的模型。 在FR或生物测量系统中,这是由非人格化的杰出人物实现的。
2 Non-targeted attack预测对抗的样本无关紧要,因为结果不是正确的标签。 在FR/生物测量系统中,通过面部填充使其复杂化。 非目标攻击更容易实施,因为它有更多的冲击和空间改变输出。
根据实施的范围,扰动可能被归类为以下几种类型:
1 Image-specific perturbations可以根据输入图像明确生成。普遍干扰
2 Universal perturbations能够以很高的概率在任意图像上欺骗给定模型。请注意,普遍性是指扰动的性质是“图像不可知论”,而不是具有良好的可转移性。
1 Box-constrained L-BFGS
Szegedy 等人首次证明了可以通过对图像添加小量的人类察觉不到的扰动误导神经网络做出误分类。他们首先尝试求解让神经网络做出误分类的最小扰动的方程。但由于问题的复杂度太高,他们转而求解简化后的问题,即寻找最小的损失函数添加项,使得神经网络做出误分类,这就将问题转化成了凸优化过程。
2 Fast Gradient Sign Method (FGSM)
Szegedy 等人发现可以通过对抗训练提高深度神经网络的鲁棒性,从而提升防御对抗样本攻击的能力。GoodFellow 等人开发了一种能有效计算对抗扰动的方法。而求解对抗扰动的方法在原文中就被称为 FGSM。
Kurakin 等人提出了 FGSM 的「one-step target class」的变体。通过用识别概率最小的类别(目标类别)代替对抗扰动中的类别变量,再将原始图像减去该扰动,原始图像就变成了对抗样本,并能输出目标类别。
3 Basic & Least-Likely-Class Iterative Methods
one-step 方法通过一大步运算增大分类器的损失函数而进行图像扰动,因而可以直接将其扩展为通过多个小步增大损失函数的变体,从而我们得到 Basic Iterative Methods(BIM)。而该方法的变体和前述方法类似,通过用识别概率最小的类别(目标类别)代替对抗扰动中的类别变量,而得到 Least-Likely-Class Iterative Methods。
4 Jacobian-based Saliency Map Attack (JSMA)
对抗攻击文献中通常使用的方法是限制扰动的 l_∞或 l_2 范数的值以使对抗样本中的扰动无法被人察觉。但 JSMA 提出了限制 l_0 范数的方法,即仅改变几个像素的值,而不是扰动整张图像。
5 One Pixel Attack
这是一种极端的对抗攻击方法,仅改变图像中的一个像素值就可以实现对抗攻击。Su等人使用了差分进化算法,对每个像素进行迭代地修改生成子图像,并与母图像对比,根据选择标准保留攻击效果最好的子图像,实现对抗攻击。这种对抗攻击不需要知道网络参数或梯度的任何信息。
6 DeepFool
Moosavi-Dezfooli 等人通过迭代计算的方法生成最小规范对抗扰动,将位于分类边界内的图像逐步推到边界外,直到出现错误分类。作者证明他们生成的扰动比 FGSM 更小,同时有相似的欺骗率。
7 Universal Adversarial Perturbations
诸如 FGSM、ILCM、DeepFool 等方法只能生成单张图像的对抗扰动,而 Universal Adversarial Perturbations 能生成对任何图像实现攻击的扰动,这些扰动同样对人类是几乎不可见的。该论文中使用的方法和 DeepFool 相似,都是用对抗扰动将图像推出分类边界,不过同一个扰动针对的是所有的图像。虽然文中只针对单个网络 ResNet 进行攻击,但已证明这种扰动可以泛化到其它网络上。
8 Carlini and Wagner Attacks (C&W)
Carlini 和 Wagner 提出了三种对抗攻击方法,通过限制 l_∞、l_2 和 l_0 范数使得扰动无法被察觉。实验证明 defensive distillation 完全无法防御这三种攻击。该算法生成的对抗扰动可以从 unsecured 的网络迁移到 secured 的网络上,从而实现黑箱攻击。
下图中描述了现有的对抗性实例生成技术对FR系统的一般分类。这些技术主要分为四类,即面向(1)CNN模型;面向(2) 物理攻击;面向 (3) 去标识化;和面向 (4)几何。


对抗能力和特异性属性的不同对抗性攻击的比较如下表所示

考虑到对抗性示例生成技术的特异性,上表表示大多数攻击方法既是有针对性的,也是非有针对性的。因此,实际上考虑了关于这个属性的泛化。
随着制作对抗样本的新方法的提出,研究也针对对抗对手,以减轻对手对目标深度网络性能的影响。因此,已经定义了几种防御策略,以提高有风险的FR模型的安全性。
防御战略的目标一般可分为以下几个部分:
1 Model architecture preservation(模型架构保存):是构建任何对抗样本的防御技术时考虑的主要考虑因素。为了达到这个目标,应该对模型体系结构进行最小的改动。
2 Accuracy maintenance(精度维护):是考虑保持分类输出几乎不受影响的主要因素。
3 Model speed conservation(模型速度保持):是在大数据集上部署防御技术的测试过程中不应该受到影响的另一个因素。
防御策略:
一般来说,对抗攻击的防御策略可以分为三类:(1) 在学习过程中改变训练,例如,在训练数据中注入对抗性样本或在整个测试过程中加入改变的输入,(2) 改变网络,例如,通过改变层数、子网络、损失和激活函数,(3)通过外部网络补充主模型,以便关联以对未可见的样本进行分类。第一类方法中的方法与学习模型无关。然而,另外两类则直接处理NNs本身。“改变”网络和通过外部网络“补充”网络之间的区别在于,前者在训练过程中改变了原始的深度网络架构/参数。同时,后者保持了原始模型的完整,并在测试中将外部模型连接到一起。
针对防御FR系统抵御对抗性攻击的对抗性检测方法的一般分类:

对抗样本检测方法如下表所示:

挑战和讨论:
虽然在FR领域已经提出和开发了几种对抗样本生成方法和防御策略,但仍需要解决各种问题和挑战。大致分为四组:
1 对抗样本的具体化/规范:研究人员已经提出了几种图像、人脸和特征级的对抗样本生成方法来欺骗FR系统;然而,这些方法对于构建一个广义的对抗实例具有挑战性,只能在某些评估指标中取得良好的性能。这些评估指标主要分为三类:生成对抗样本的成功率,FR模型的鲁棒性,以及攻击的特定属性,如扰动量和可转移性的程度。简单地解释,一个攻击的成功率,被称为最直接和最有效的评估标准,与扰动的大小成反比。FR模型的鲁棒性与分类精度有关。FR模型的设计越好,它就越不容易受到对抗样本的影响。关于攻击的属性,对原始样本的太小的扰动很难构建对抗样本,而太大的扰动很容易被人类的眼睛区分出来。因此,应该实现在构建对抗样本和人类视觉系统之间的平衡。另一方面,在一定的扰动范围内,敌实例的转移率与敌扰动的大小成正比,即原样本的扰动越大,构造的敌样本的转移率越高。考虑到这些事实,在原始图像上需要考虑的扰动量,以及模型架构的设计变得至关重要。
2 FR模型的不稳定性:虽然深度学习FR系统的引入带来了好处,但它增加了这类系统的攻击面。例如,实施基于图像失真的对抗攻击,与应用基于非深度学习的商业现成匹配器相比,观察到的基于深度学习的系统的性能遭受了巨大的损失。因此,人们强烈主张只集成那些能够抵御逃避的架构。前一段已经表达了需要建立稳健的模型来增加对抗性例子的概括性,以及其他影响因素。然而,这一义务被单独强调,以强调它在采取步骤产生更多黑箱攻击时的重要性。在这种情况下,将对开发更稳健的FR模型提出安全担忧。
3 与人类视觉系统的偏差:对视觉系统的对抗攻击利用了这样一个事实,即系统对人类对图像的微小变化很敏感。开发算法,使图像更与人类相似,这将是一个好主意。特别是,那些根据图像的属性而不是根据其像素的强度对图像进行分类的方法可能会变得更加实用。这种方法可以训练分类器识别视觉外观的存在,如性别、种族、年龄和头发颜色,并提取和比较对姿势、光照、表达和其他成像条件不敏感的面部图像的高级视觉特征或特征。
4 图像不可知性的扰动产生:现有的对抗样本生成方法被显著地证明是图像不可知的,并且强烈注意到缺乏针对FR模型的普遍扰动生成。FR模型同时攻击不同目标面的能力将是产生普遍扰动的副产品,这是在这方面进行的许多研究中所关注的一个基本问题。