模型主要分为了两个部分
第一个部分是HD_PM 主要是做预测的
第二个部分是SAbHD_RM 主要是做推荐的。
我们主要是对心脏病进行一个疾病预测(四选一),然后进行建议的匹配,这个建议来源于专家建立的知识库。
模型大概分为以下几个部分:
数据划分为训练集和测试集->数据预处理->选择重要的特征->用一些基础的分类器进行分类->预测结果。
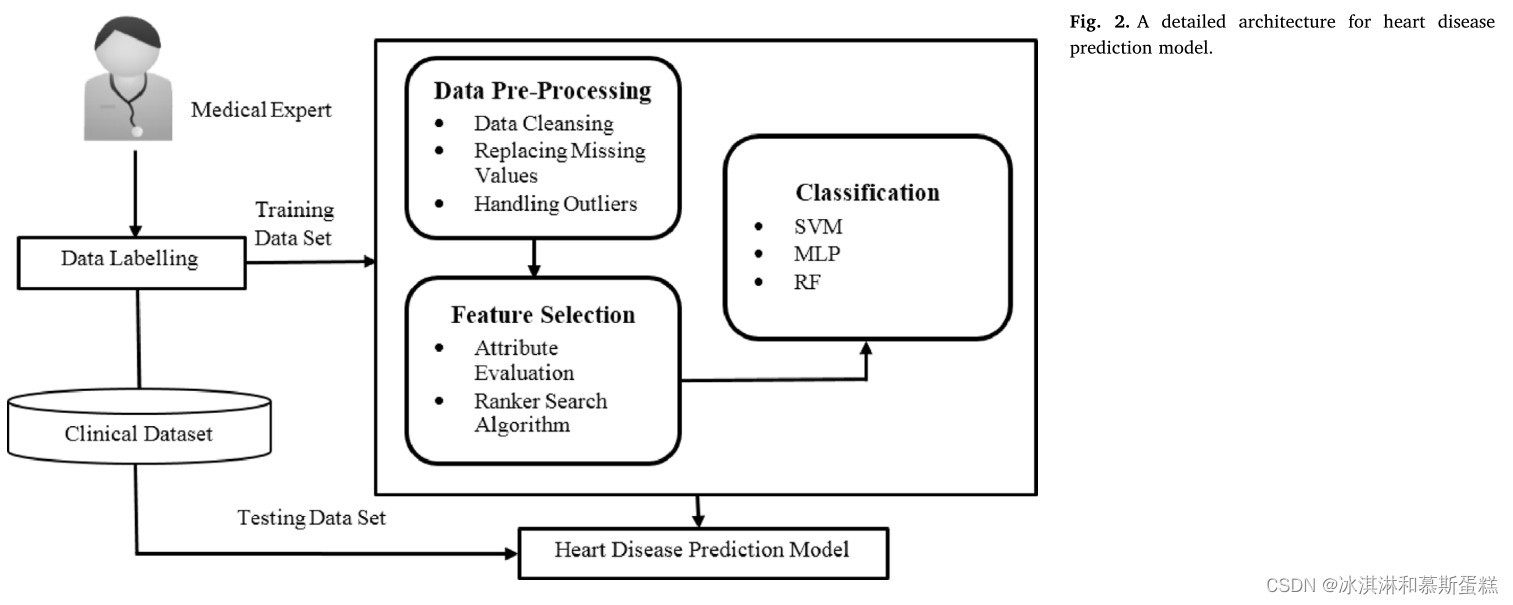
特征选择过程分为两个阶段。
第一阶段实现一种属性计算器技术,该技术针对输出类计算数据集的特征。
第二阶段应用搜索方法,使用不同的特征组合为分类问题选择最优集合。该模型采用了一种基于信息增益的特征选择方法。在这种技术中,计算信息增益,即给定类的每个特征的熵。
使用了阈值对信息增益进行了一个下线的划分,以得到最重要的属性。
第一个模型就是简单的使用了分类器进行预测,好像没啥内容,接着看第二个模型。
算法如下。
这里主要是把建议也给分类了,分成了5类。
F代表critical属性集合(f1:氧饱和度,f2:血压,f3:胆固醇,f4:血糖)
V代表严重程度(红、黄、绿)
W代表F的权重。
知识基础K=F,W,V
对于每种疾病,我们先计算疾病的可能性,然后计算疾病的存在风险R(存在疾病/缺失疾病),如果风险大于1且疾病存在概率大于一定的阈值,我们就计算一个严重分数S和一个最终分数,最终分数就是用S*W,我们按照最终分数的大小进行推荐(最终分数小推荐‘运动’、最终分数大推荐‘吃药’)
这个流程也比较简单似乎,