0.前言
最近在做BEV视图下融合感知的项目,需要对相关工作进行学习。BEVFusion作为一项经典的工作,值得深入探索,论文地址,代码地址。然而由于配置环境比较麻烦,耽误了一些时间。经过几次成功配置之后,有了一些总结,在这里记录下来,供大家参考,也方便自己下次查阅。
首先,要知道这个工程对于电脑配置要求比较高。我目前在3090和3060上都成功了,但是再低一些可能就不太行了,batch_size为1的时候显存占用8-9G。当前我配环境的这台电脑配置是3060显卡,16G内存,12G显存。如果你的电脑配置很低,那还是别麻烦了,或者换更好的配置。
目录如下,如果显卡驱动话cuda都安装好了,直接进入第三步!
0.前言
1.显卡驱动安装
2.cuda安装
3.环境配置
4.数据准备
5.终端训练与测试
6.用pycharm 进行 debug
1.显卡驱动安装
如果你的电脑还没有安装显卡驱动,需要根据系统推荐的进行安装。查看是否有显卡驱动的指令是:
nvidia-smi如果显示了如下所示的详细信息:
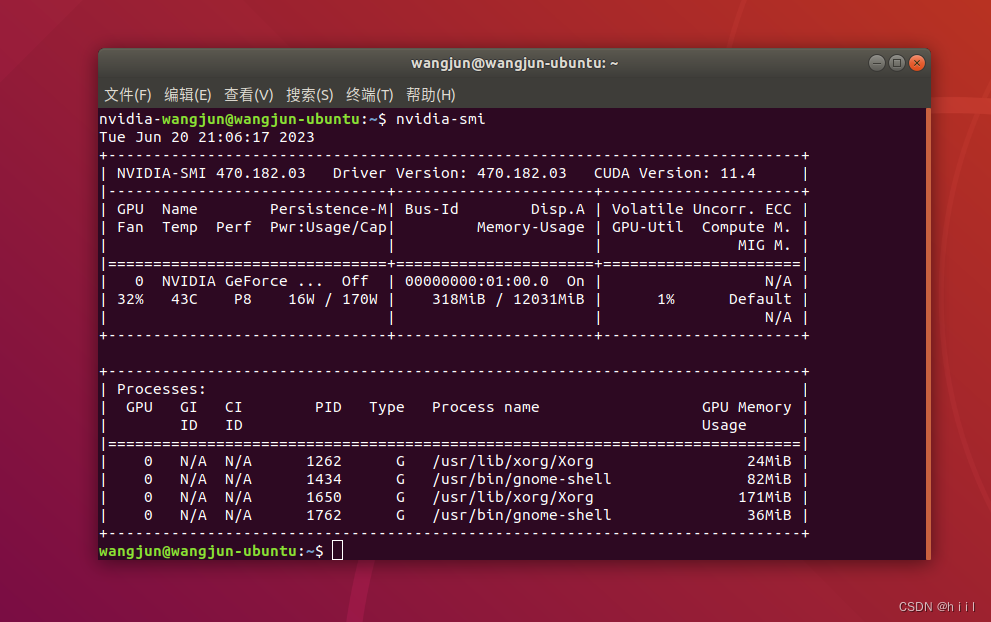
则说明有显卡驱动,可以直接跳到下一步。否则需要先安装显卡驱动,安装步骤如下。
1.注意!在安装NVIDIA驱动以前需要禁止系统自带显卡驱动nouveau:可以先通过指令
lsmod | grep nouveau查看nouveau驱动的启用情况,如果有输出表示nouveau驱动正在工作,如果没有内容输出则表示已经禁用了nouveau。禁用的方法: 禁用nouveau
2.安装有好几种方法,这里介绍一种比较简单的方法,即在‘软件和更新’里面下载。选中合适的版本,点击应用更改,下载完成之后重启即可,再次用nvidia-smi查看。
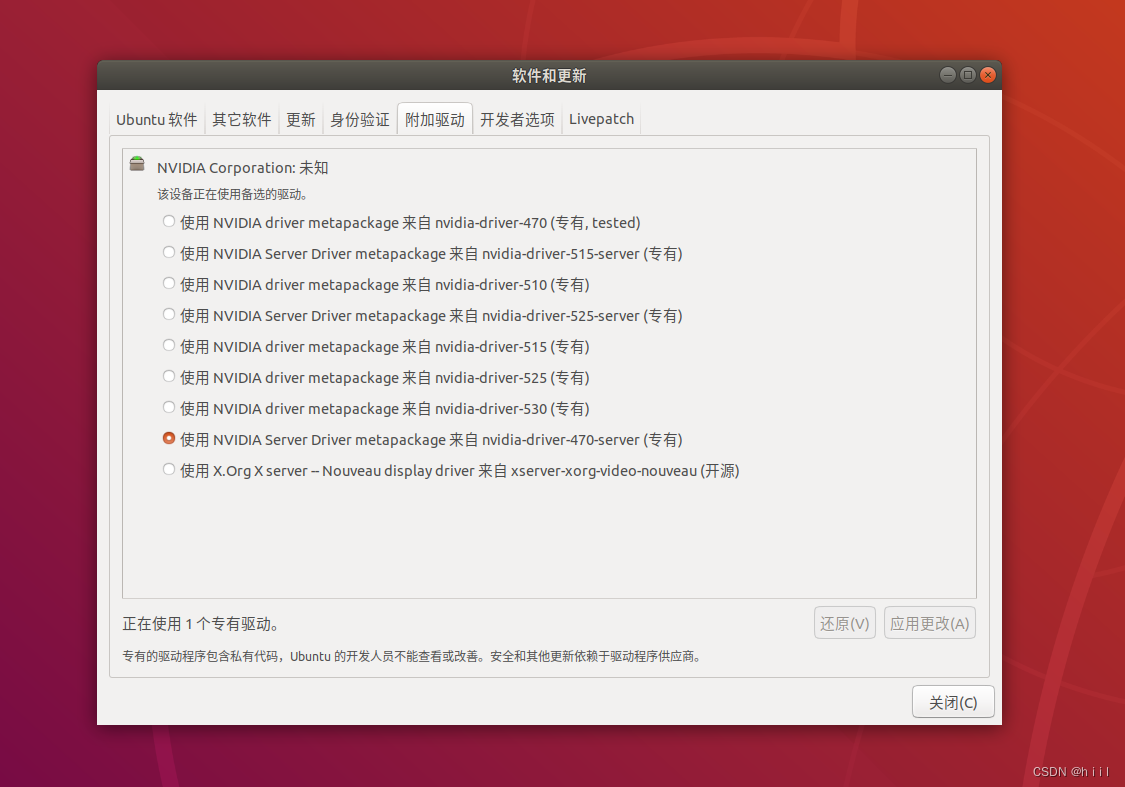
本文档的重点不在此,如果想用其他方法,参考:Ubuntu安装显卡驱动详细步骤![]() https://blog.csdn.net/m0_54792870/article/details/112980817?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168733445516782425129780%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=168733445516782425129780&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-3-112980817-null-null.142^v88^control_2,239^v2^insert_chatgpt&utm_term=ubuntu%E5%AE%89%E8%A3%85%20%E6%98%BE%E5%8D%A1%E9%A9%B1%E5%8A%A8&spm=1018.2226.3001.4187
https://blog.csdn.net/m0_54792870/article/details/112980817?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522168733445516782425129780%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=168733445516782425129780&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-3-112980817-null-null.142^v88^control_2,239^v2^insert_chatgpt&utm_term=ubuntu%E5%AE%89%E8%A3%85%20%E6%98%BE%E5%8D%A1%E9%A9%B1%E5%8A%A8&spm=1018.2226.3001.4187
2.cuda安装
cuda的版本需要根据显卡来选择,运行nvidia-smi之后,可以看到显卡支持的最高cuda版本,那么我们安装的cuda版本要小于等于这个上限。但是又不能太低,有的显卡型号比较新,装了太老的cuda反而会出问题。我查到的是11.4,于是安装了cuda11.3,具体步骤如下:
(1)首先,进入下面的网址,点击对应版本的cuda。cuda选择官网
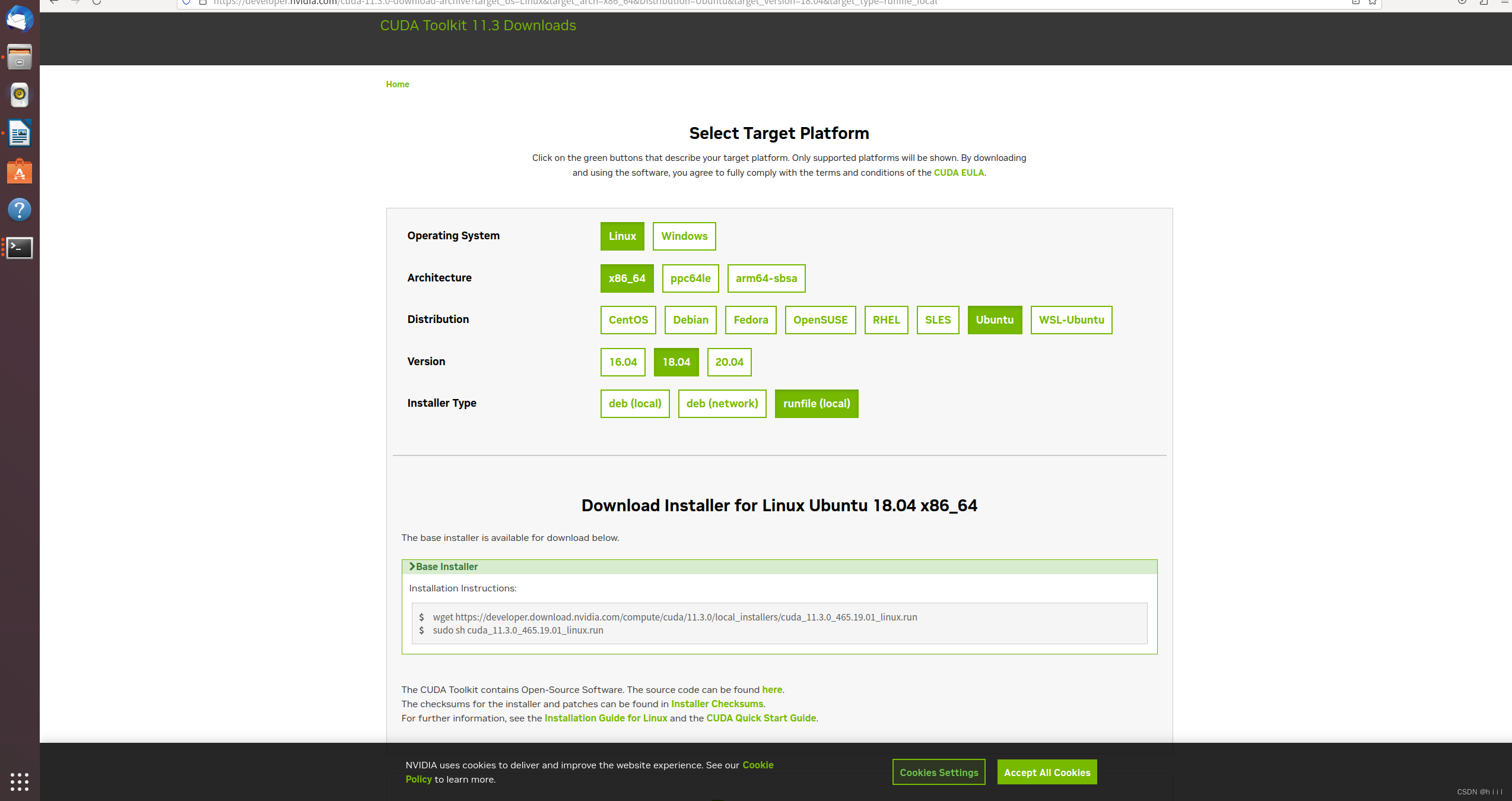
(2)在终端中运行生成的两个指令,分别是下载和安装cuda。下载到99%时出现段错误(核心已转储)。参考:安装CUDA段错误(核心已转储)解决方案
(3)安装时注意有几处需要选择,第一处选择continue,第二处输入accept,第三处用空格取消driver,并选择install。这样选择防止再次安装其他版本的显卡驱动导致出问题。
(4)配置环境变量
sudu gedit ~/.bashrc在后面加上
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export PATH=$PATH:/usr/local/cuda/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda保存之后,记得source一下
source ~/.bashrc查看cuda是否安装成功
nvcc -V
3.环境配置
下面正式开始配环境啦。
(1)下载安装openmpi,我也不知道这个到底需不需要,安了没有副作用。
wget https://download.open-mpi.org/release/open-mpi/v4.1/openmpi-4.1.4.tar.gz
解压
cd openmpi-4.1.4./configure –prefix=/usr/local/openmpimake -j8sudo make install~/.bashrc文件里添加环境变量:MPI_HOME=/usr/local/openmpi
OMPI_MCA_opal_cuda_support=true
export PATH=${MPI_HOME}/bin:$PATH
export LD_LIBRARY_PATH=${MPI_HOME}/lib:$LD_LIBRARY_PATH
export MANPATH=${MPI_HOME}/share/man:$MANPATH测试安装是否成功
cd openmpi-x.x.x/examples
make
mpirun -np 4 hello_c
(2)创建虚拟环境并安装torch
conda create -n bevfusion_mit python=3.8#在安装torch的时候指定cuda版本,不容易出问题,cu113指cuda 11.3
pip install torch==1.10.0+cu113 torchvision==0.11.0+cu113 -f https://download.pytorch.org/whl/torch_stable.html
(3)安装下列...
#安装mmcv的时候同样指定cuda和torch版本,cu113指cuda 11.3
pip install mmcv-full==1.4.0 -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10.0/index.htmlpip install mmdet==2.20.0conda install openmpiconda install mpi4pypip install Pillow==8.4.0pip install tqdmpip install torchpackpip install nuscenes-devkitpip install ninjapip install numpy==1.19.5pip install numba==0.48.0pip install shapely==1.8.0
(4)下载BEVFusion代码并做一些小修改
git clone https://github.com/mit-han-lab/bevfusion.git1.把mmdet3d/ops/spconv/src/indice_cuda.cu里面的4096都改成256
2.对于编译脚本 setup.py,需要把显卡算力改成自己对应的。在下面这个链接里查出你的显卡对应的算力,然后选择用哪一行:
"-gencode=arch=compute_70,code=sm_70"
"-gencode=arch=compute_75,code=sm_75"
"-gencode=arch=compute_80,code=sm_80"
"-gencode=arch=compute_86,code=sm_86"
CUDA GPUs - Compute Capability | NVIDIA Developer 查到3060显卡的算力为86.
3.开始编译
python setup.py develop
4.数据准备
(1)下载nuScenes数据集,如果有需要就下载完整版,学习代码可以下载mini
nuScenes官网:https://www.nuscenes.org/nuscenes![]() https://www.nuscenes.org/nuscenes
https://www.nuscenes.org/nuscenes

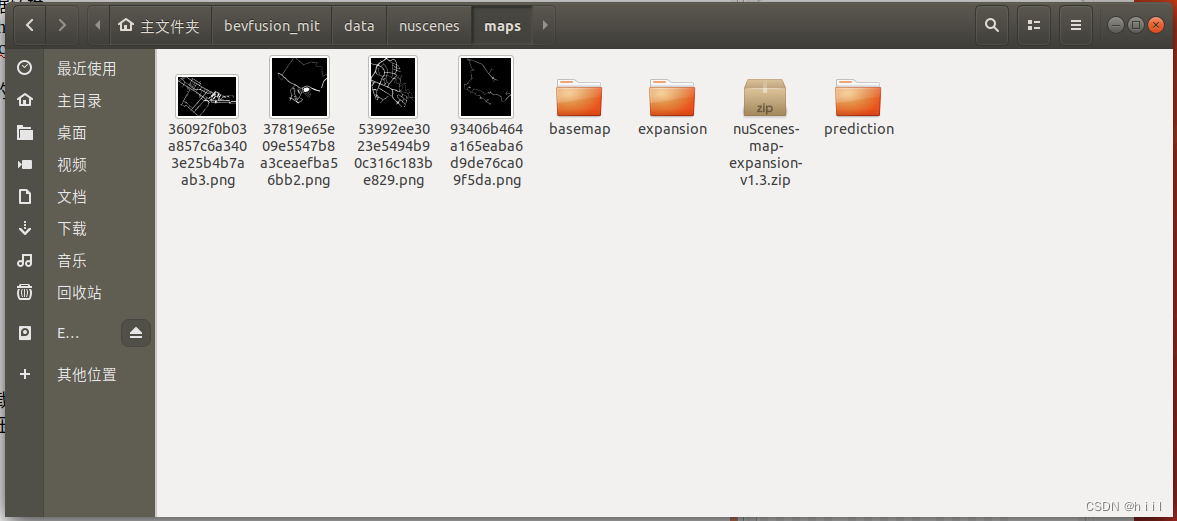
(2) 把文件夹格式改成下面这个样子,注意nuscenes这个单词全部小写。
#正常版本,结构如下:
bevfusion-mit
├── tools
├── configs
├── data
│ ├── nuscenes
│ │ ├── maps
│ │ ├── samples
│ │ ├── sweeps
│ │ ├── lidarseg (optional)
│ │ ├── v1.0-test
| | ├── v1.0-trainval#如果下载的是mini版本,结构如下:
bevfusion-mit
├── tools
├── configs
├── data
│ ├── nuscenes
│ │ ├── maps
│ │ ├── samples
│ │ ├── sweeps
│ │ ├── v1.0-mini
注意:还要下载Map expansion pack(v1.3) 然后解压到maps文件夹中。否则后面运行的时候会报错!
(3)接下来运行数据转换的脚本
#同样的,如果是正常版本,运行:
python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes#如果是mini版本,运行:
python tools/create_data.py nuscenes --root-path ./data/nuscenes/ --version v1.0-mini --out-dir data/nuscenes/ --extra-tag nuscenes转换的过程如下所示:

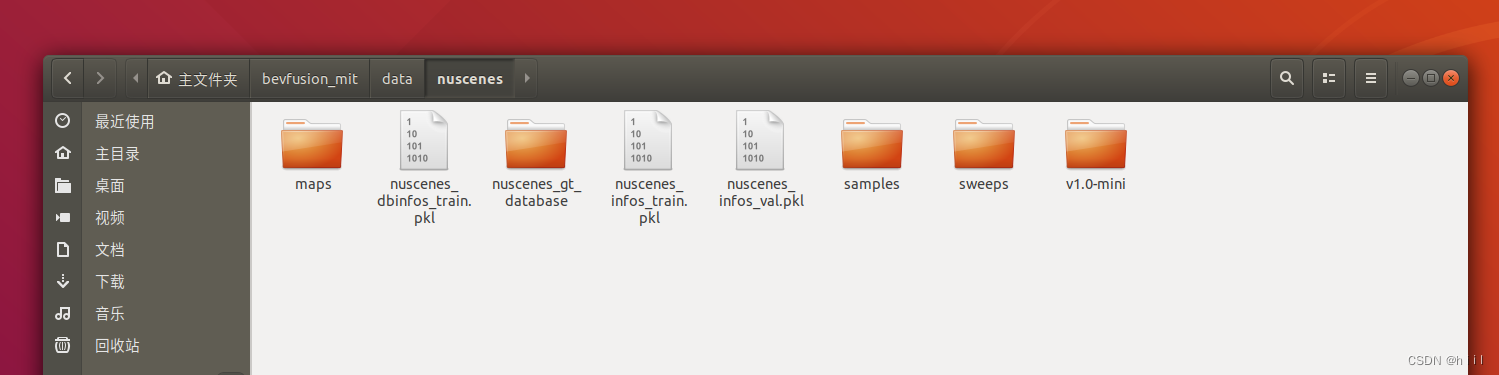
完成之后,文件夹是这样的,增加了几个.pkl文件和nuscenes_database。
#正常版本:
├── data
│ ├── nuscenes
│ │ ├── maps
│ │ ├── samples
│ │ ├── sweeps
│ │ ├── lidarseg (optional)
│ │ ├── v1.0-test
| | ├── v1.0-trainval
│ │ ├── nuscenes_database
│ │ ├── nuscenes_infos_train.pkl
│ │ ├── nuscenes_infos_val.pkl
│ │ ├── nuscenes_infos_test.pkl
│ │ ├── nuscenes_dbinfos_train.pkl#mini版本
├── data
│ ├── nuscenes
│ │ ├── maps
│ │ ├── samples
│ │ ├── sweeps
│ │ ├── v1.0-mini
│ │ ├── nuscenes_database
│ │ ├── nuscenes_infos_train.pkl
│ │ ├── nuscenes_infos_val.pkl
│ │ ├── nuscenes_dbinfos_train.pkl
我用的是mini,全部完成之后是这样的:
(4)下载预训练权重
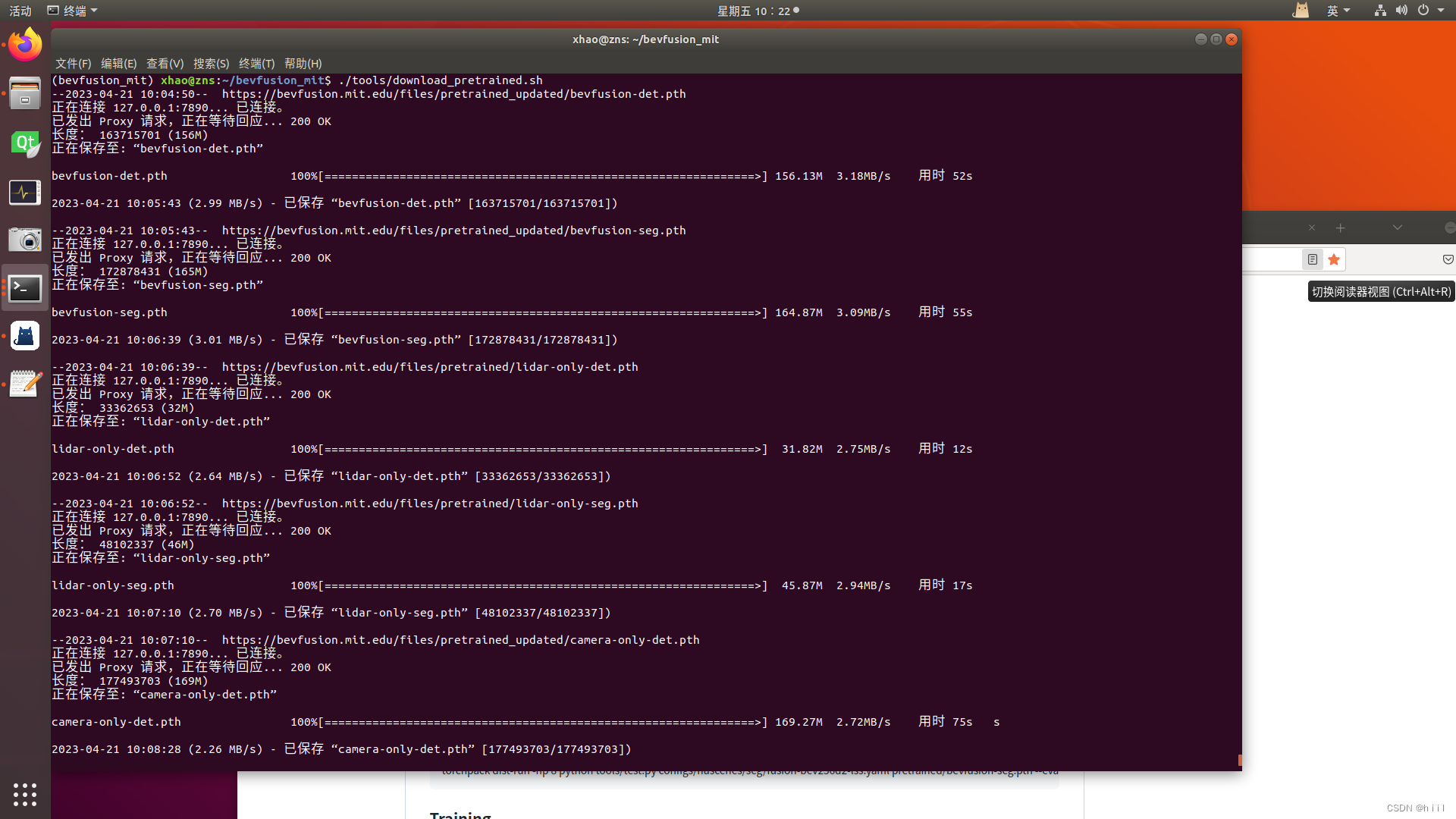
5.终端训练与测试
(1)训练,官方给的是分布式训练:
torchpack dist-run -np 1 python tools/train.py configs/nuscenes/det/transfusion/secfpn/camera+lidar/swint_v0p075/convfuser.yaml --model.encoders.camera.backbone.init_cfg.checkpoint pretrained/swint-nuimages-pretrained.pth --load_from pretrained/lidar-only-det.pth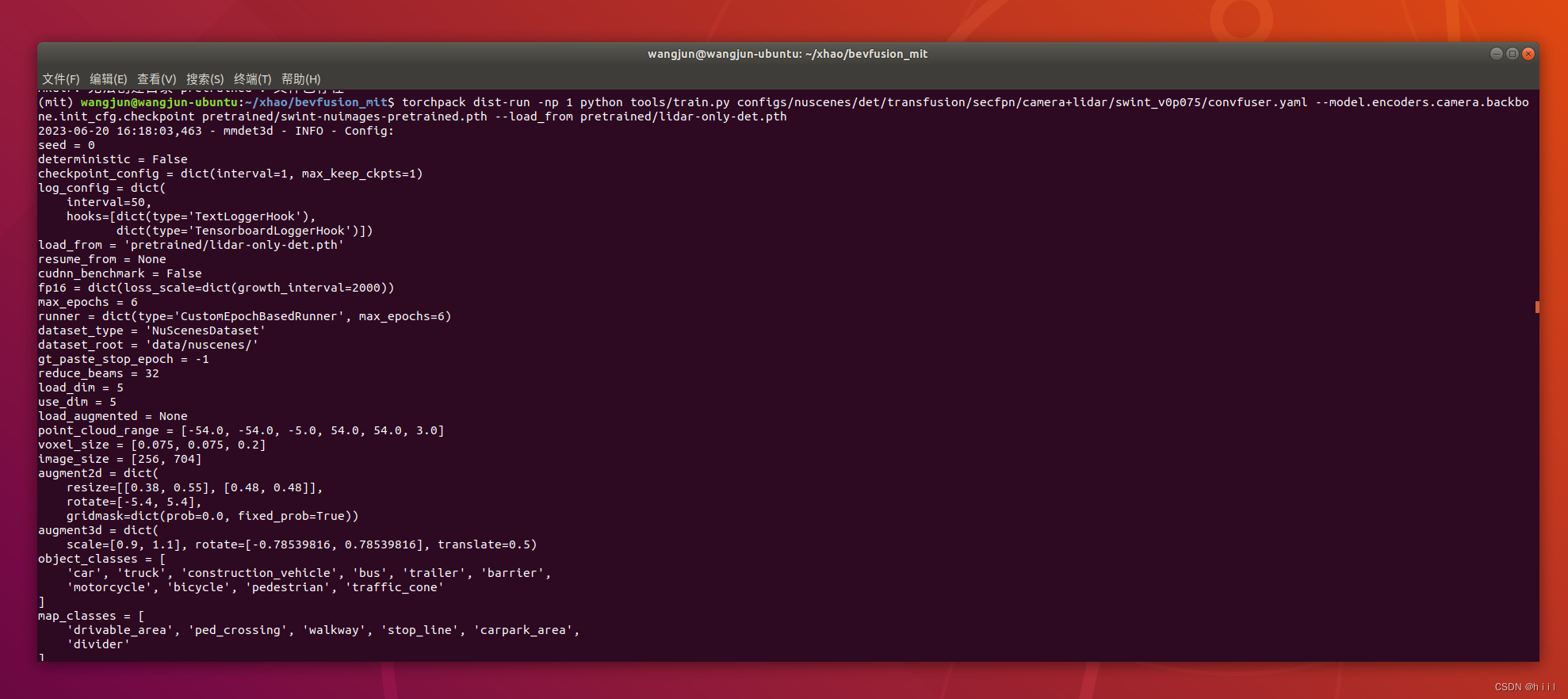
训练结束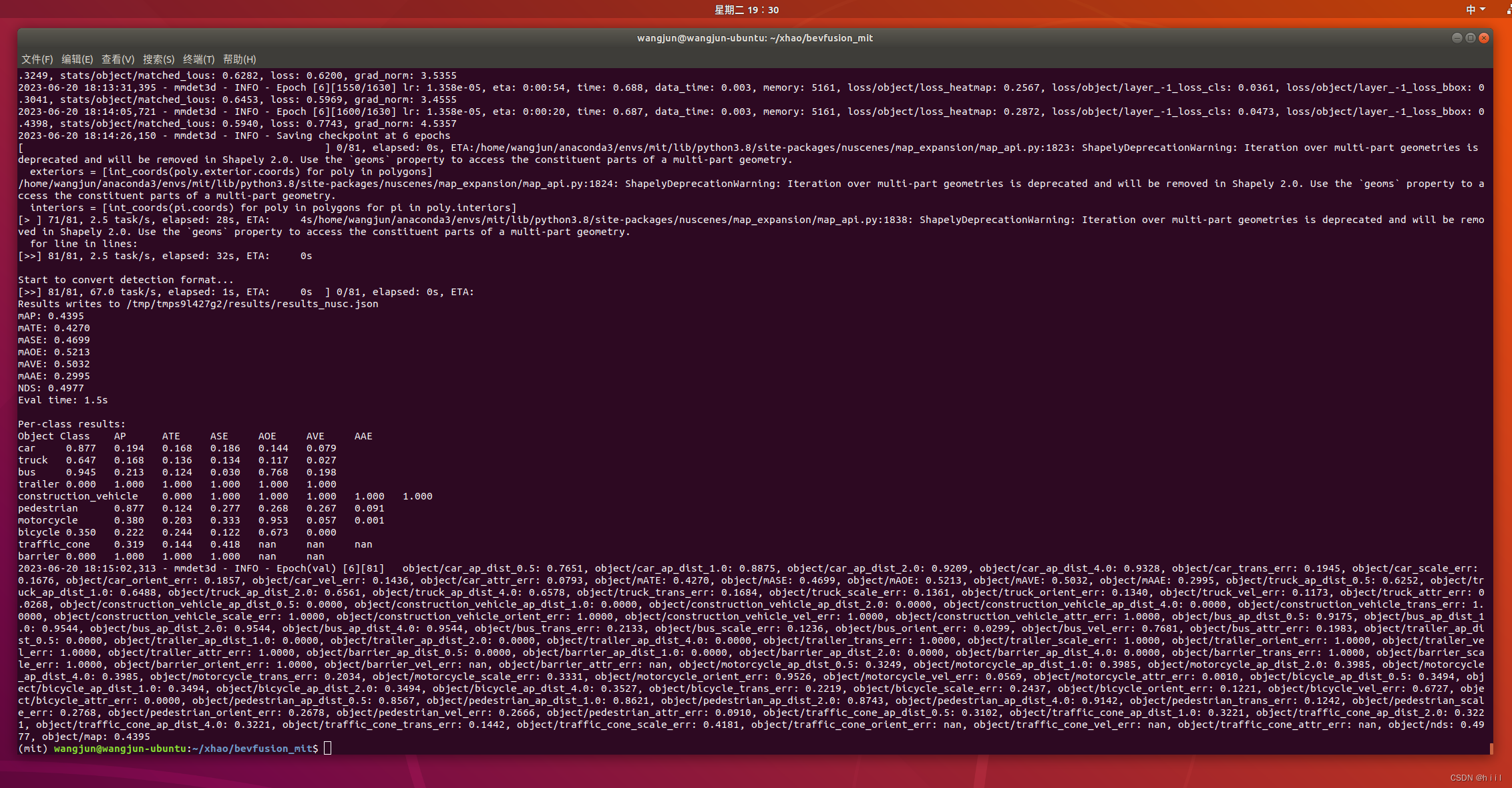
训练时如果报显存溢出,把这两个调到最小:
(2)测试:
torchpack dist-run -np 1 python tools/test.py configs/nuscenes/det/transfusion/secfpn/camera+lidar/swint_v0p075/convfuser.yaml pretrained/bevfusion-det.pth --eval bbox
训练和测试中可能遇到的问题以及方法:
1.找不到maps中的一些东西。
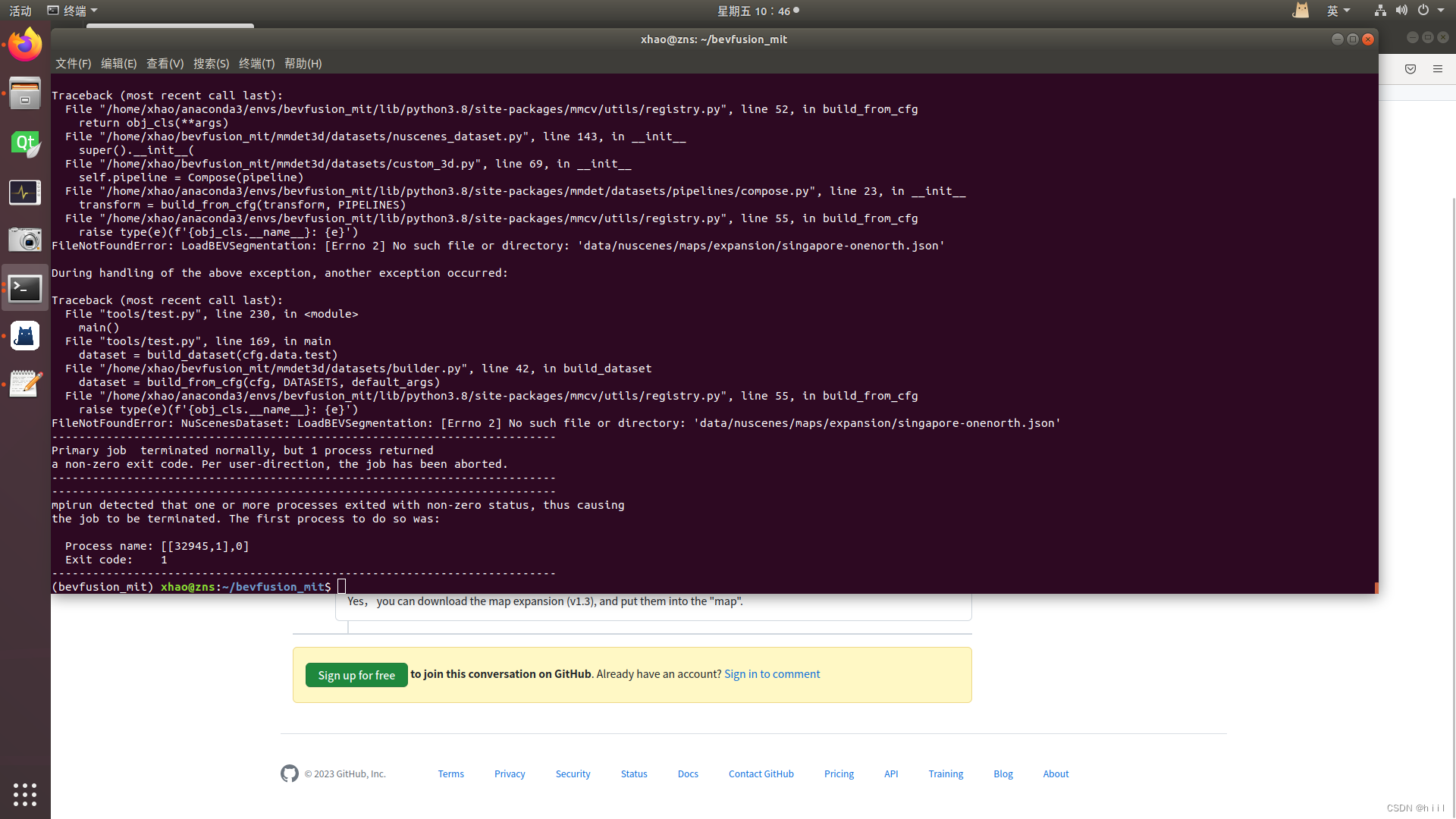
解决方法,下载Map expansion pack(v1.3) 然后解压到maps文件夹中。
2.算力设置不匹配。

3.cuda和torch的版本不匹配
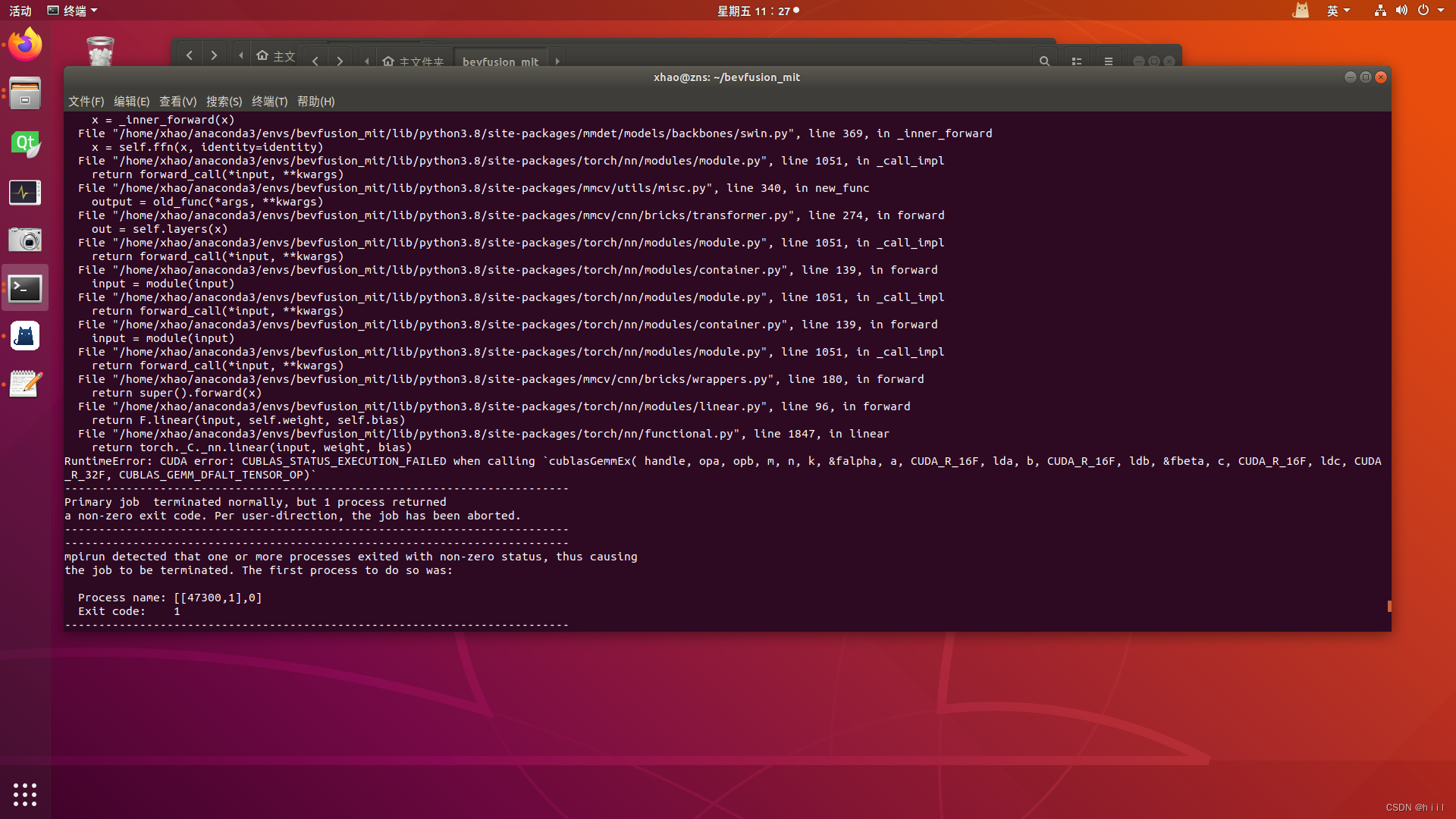
解决:Pytorch环境配置——cuda、、cudnn、torch、torchvision对应版本
4.如果报错中包含setuptools,看一下版本,65.0的太新了,卸载重新下59.5.0,解决。
6.用pycharm 进行 debug
想要利用pycharm对代码进行debug,就不得不把运行语句改成python xxx.py --config,但是目前为止上述都是分布式的语句,前面带了torchpack dist-run -np这句话,而pycharm是不认识的,因此需要把原来的训练或测试脚本改成普通的。经过探索,还是没能把tools/train.py改好,但是把tools/test.py改好了。需要对tools/test.py做两点改动:
(1)注释dist.init()
(2)把distributed=True 改成False
此时终端测试语句就可以变成:
python tools/test.py configs/nuscenes/det/transfusion/secfpn/camera+lidar/swint_v0p075/convfuser.yaml pretrained/bevfusion-det.pth --eval bbox
相应的,现在就可以在pycharm中配置BEVFusion的测试了
(1)打开项目,并选择虚拟环境。Ubuntu pycharm配置Conda环境
(2)配置debug的configrations,打开Run/Debug configurations。
(3) 添加python。选择要运行的脚本,填入配置的参数,选择运行的文件夹。注意文件夹不对的话无法访问相对路径。
(4)打断点,进行debug
这个BEVFusion(mit)的环境安装,以及部署复现的教程就写到这了,后面将对代码进行深入学习。可能还会发一些心得和记录。