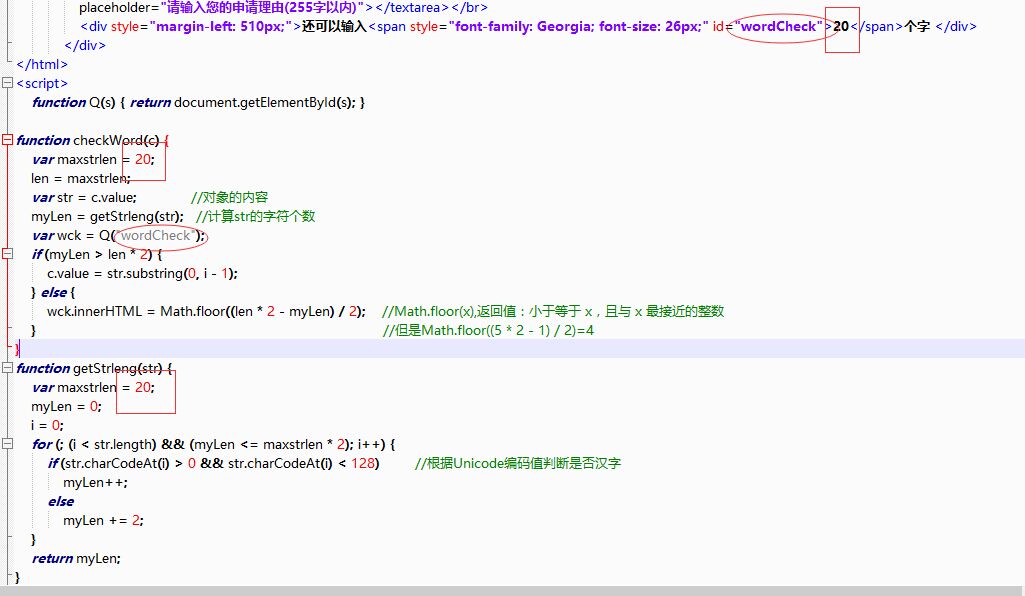
十年前AlphaGo火的时候,百度在送外卖;
十年后ChatGPT火的时候,抖音还在送外卖;
而十年前送外卖的大佬,现在出来搞AI;
所以……要搞AI,先送外卖?


公众号后台回复:“ChatGPT”,便可以下载到干货包!!
目录:

一、ChatGPT简介
ChatGPT本质是一个对话模型,它可以回答日常问题、挑战不正确的前提,甚至会拒绝不适当的请求,在去除偏见和安全性上不同于以往的语言模型。ChatGPT从闲聊、回答日常问题,到文本改写、诗歌小说生成、视频脚本生成,以及编写和调试代码均展示了其令人惊叹的能力。在OpenAI公布博文和试用接口后,ChatGPT很快以令人惊叹的对话能力“引爆”网络,本文主要从技术角度,梳理ChatGPT背后涉及的技术工作LLM,来阐述其如此强大的原因;同时思考其对我们目前的实际工作和方法论的改变,包括可复用和可借鉴之处。ChatGPT其关键能力来自三个方面:强大的基座大模型能力(InstructGPT),高质量的真实数据(干净且丰富),强化学习算法(PPO算法)。
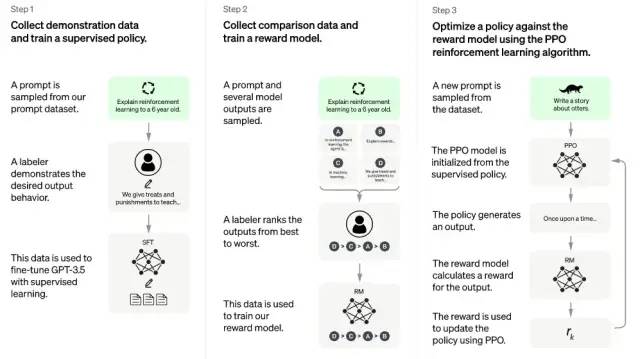
为何三段式的训练方法就可以让ChatGPT如此强大?其实,以上的训练过程蕴含了上文我们提到的关键点,而这些关键点正是ChatGPT成功的原因:
强大的基座模型能力(InstructGPT);
大参数语言模型(GPT3.5);
高质量的真实数据(精标的多轮对话数据和比较排序数据);
性能稳定的强化学习算法(PPO算法)
二、InstructGPT及其相关工作
我们需要注意的是,ChatGPT的成功,是在前期大量工作基础上实现的,非凭空产生的“惊雷”。ChatGPT是InstructGPT的兄弟模型(sibling model),后者经过训练以遵循Prompt中的指令,提供详细的响应。InstructGPT是OpenAI在2022年3月在Training language models to follow instructions with human feedback文献中提出的工作,整体流程和以上的ChatGPT流程基本相同,除了在数据收集和基座模型(GPT3 vs GPT 3.5),以及第三步初始化PPO模型时略有不同。此篇可以视为RLHF(基于人类反馈的强化学习,使用人工结果打分来调整模型) 1.0的收官之作。一方面,从官网来看,这篇文章之后暂时没有发布RLHF的新研究,另一方面这篇文章也佐证了Instruction Tuning的有效性。
在InstuctGPT的工作中,与ChatGPT类似,给定Instruction,需要人工写回答。首先训练一个InstructGPT的早期版本,使用完全人工标注的数据,数据分为3类:Instruction+Answer,Instruction+多个examples和用户在使用API过程中提出的需求。从第二类数据的标注,推测ChatGPT可能用检索来提供多个In Context Learning的示例,供人工标注。剩余步骤与以上ChatGPT相同。尤其需要重视但往往容易被忽视的,即OpenAI对于数据质量和数据泛化性的把控,这也是OpenAI的一大优势:
1)寻找高质量标注者:寻找在识别和回应敏感提示的能力筛选测试中,表现良好的labeler;
2)使用集外标注者保证泛化性:即用未经历以上1)步骤的更广大群体的标注者对训练数据进行验证,保证训练数据与更广泛群体的偏好一致。
GPT3只是个语言模型,它被用来预测下一个单词,丝毫没有考虑用户想要的答案;当使用代表用户喜好的三类人工标注为微调数据后,1.3B参数的InstructGPT在多场景下的效果超越175B的GPT3。

InstructGPT当中提到很关键的一点, 当我们要解决的安全和对齐问题是复杂和主观,而它的好坏无法完全被自动指标衡量的时候,此时需要用人类的偏好来作为奖励信号来微调我们的模型。
三、InstuctGPT的前序工作:GPT与强化学习的结合
再往前回溯,其实在2019年GPT2出世后,OpenAI就有尝试结合GPT-2和强化学习。在NeurIPS 2020的Learning to Summarize with Human Feedback工作中,OpenAI在摘要生成中,利用了从人类反馈中的强化学习来训练。可以从这篇工作的整体流程图中,看出三步走的核心思想:收集反馈数据 -> 训练奖励模型 -> PPO强化学习。
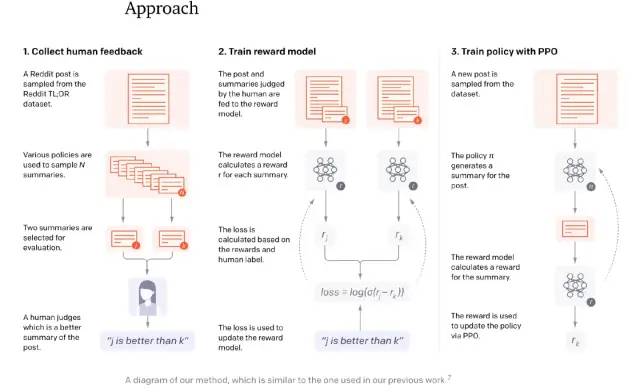
RLHF第一阶段,针对多个候选摘要,人工排序(这里就体现出OpenAI的钞能力,按标注时间计费,标注过快的会被开除);第二阶段,训练排序模型(依旧使用GPT模型);第三阶段,利用PPO算法学习Policy(在摘要任务上微调过的GPT)。文中模型可以产生比10倍更大模型容量更好的摘要效果。但文中也同样指出,模型的成功部分归功于增大了奖励模型的规模,而这需要很大量级的计算资源,训练6.7B的强化学习模型需要320 GPU-days的成本。另一篇2020年初的工作,是OpenAI的Fine-Tuning GPT-2 from Human Preferences工作,同样首先利用预训练模型,训练reward模型;进而使用PPO策略进行强化学习,整体步骤初见ChatGPT的雏形。
而RLHF(reinforcement learning from human feedback )的思想,是在更早的2017年6月的OpenAI Deep Reinforcement Learning from Human Preferences工作提出,核心思想是利用人类的反馈,判断最接近视频行为目标的片段,通过训练来找到最能解释人类判断的奖励函数,然后使用RL来学习如何实现这个目标。
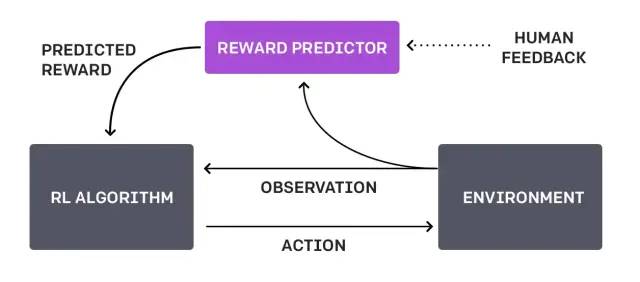
可以说,ChatGPT是站在InstructGPT以及以上理论的肩膀上完成的一项出色的工作,它们将LLM(large language model)/PTM(pretrain language model)与RL(reinforcement learning)出色结合,证明这条方向可行,同时也是未来还将持续发展的NLP甚至通用智能体的方向。
四、与ChatGPT同类型其他工作
其实近两年,利用LLM+RL以及对强化学习和NLP训练的研究,各大巨头在这个领域做了非常多扎实的工作,而这些成果和ChatGPT一样都有可圈可点之处。这里以OpenAI的WebGPT和Meta的Cicero为例。
WebGPT是2021年底OpenAI的工作,其核心思想是使用GPT3模型强大的生成能力,学习人类使用搜索引擎的一系列行为,通过训练奖励模型来预测人类的偏好,使WebGPT可以自己搜索网页来回答开放域的问题,而产生的答案尽可能满足人类的喜好。
Cicero是Meta AI 2022年底发布的可以以人类水平玩文字策略游戏的AI系统, 其同样可以与人类互动,可以使用战略推理和自然语言与人类在游戏玩法中进行互动和竞争。Cicero的核心是由一个对话引擎和一个战略推理引擎共同驱动的,而战略推理引擎集中使用了RL,对话引擎与GPT3类似。
关于ChatGPT(GPT3.5)的发展summary,附上一个非常好的资料推荐,并附上其梳理的流程:
资料
https://link.zhihu.com/?target=https%3A//yaofu.notion.site/How-does-GPT-Obtain-its-Ability-Tracing-Emergent-Abilities-of-Language-Models-to-their-Sources-b9a57ac0fcf74f30a1ab9e3e36fa1dc1
| 能力 | OpenAI模型 | 训练方法 | OpenAI API | OpenAI论文 | 近似的开源模型 |
| 语言生成+ 世界知识+ 上下文学习 | GPT-3初始版本大部分的能力已经存在于模型中,尽管表面上看起来很弱。 | 语言建模 | Davinci | GPT3论文 | Meta OPT |
| + 遵循人类的指令+ 泛化到没有见过的任务 | Instruct-GPT初始版本 | 指令微调 | Davinci-Instruct-Beta | Instruct-GPT论文 | T0论文Google FLAN论文 |
| + 代码理解+ 代码生成 | Codex初始版本 | 在代码上进行训练 | Code-Cushman-001 | Codex论文 | Salesforce CodeGen |
| GPT3.5系列 | |||||
| ++ 代码理解++ 代码生成++ 复杂推理 / 思维链+ 长距离的依赖 (很可能) | 现在的CodexGPT3.5系列中最强大的模型 | 在代码+文本上进行训练在指令上进行微调 | Code-Davinci-002(目前免费的版本 = 2022年12月) | Codex论文 | |
| ++ 遵循人类指令- 上下文学习- 推理能力++ 零样本生成 | 有监督的Instruct-GPT通过牺牲上下文学习换取零样本生成的能力 | 监督学习版的指令微调 | Text-Davinci-002 | InsructGPT论文 有监督部分 | T0论文Google FLAN论文 |
| + 遵循人类价值观+ 包含更多细节的生成+ 上下文学习+ 零样本生成 | 经过RLHF训练的Instruct-GPT和002模型相比,和人类更加对齐,并且更少的性能损失 | 强化学习版的指令微调 | Text-Davinci-003 | InsructGPT论文 从人类反馈中学习 | Deepmind SparrowAI2 RL4LMs |
| ++ 遵循人类价值观++ 包含更多细节的生成++ 拒绝知识范围外的问题++ 建模对话历史的能力-- 上下文学习 | ChatGPT通过牺牲上下文学习的能力换取建模对话历史的能力 | 使用对话数据进行强化学习指令微调 | Deepmind SparrowAI2 RL4LMs |
五、ChatGPT落地与思考
ChatGPT对于文字模态的AIGC应用具有重要意义,可以依附于对话形态的产品和载体大有空间,包括但不限于内容创作、客服机器人、虚拟人、机器翻译、游戏、社交、教育、家庭陪护等领域,或许都将是 ChatGPT 能快速落地的方向。其中有些方向会涉及到交互的全面改革,比如机器翻译不再是传统的文本输入->实时翻译,而是随时以助手问答的形式出现,甚至给出一个大概笼统的中文意思,让机器给出对应英文,包括对于我们目前所做的写作产品,可能也会涉及创作模式的改变和革新。有些方向会全面提升产品质量,比如已存在的客服机器人、虚拟人等。
NLP与CV相结合:ChatGPT作为文字形态的基础模型,自然可以与其他多模态结合;比如最近同为火热的Stable Diffusion模型,利用ChatGPT生成较佳的Prompt,对于AIGC内容和日趋火热的艺术创作,提供强大的文字形态的动力。
另一个讨论较多的方向,是ChatGPT对于搜索引擎的代替性;ChatGPT可以作为搜索引擎的有效补充,但至于是否能代替搜索引擎(不少人关注的地方),抛开推理成本不谈,目前只从效果上来说为时尚早。对于网络有答案的query,抽取就完全能满足,百度最近就有这样的功能。网络上没有明确答案,即使检索了相关材料(ChatGPT应该还没有这样的功能),也没人能保证生成结果的可信度,目前可能还不太成熟。
ChatGPT本身的升级:与WebGPT的结合,对信息进行实时更新,并且对于事实真假进行判断;很明显可以看到,现在的ChatGPT没有实时更新和事实判断能力,而如果结合WebGPT的自动搜索能力,让ChatGPT学会自己去海量知识库中探索和学习,将会极大提升使用方向,我们预测这可能会是GPT-4的一项能力。还有其他更多方向,包括ChatGPT与最近数理逻辑工作的结合等。
六、LLM(large language model)的发展与趋势
通过海量数据训练得到的超大参数模型蕴含了海量知识,以GPT3(175B)开端,再到LaMDA(137B)、Gopher(280B)、FLAN-T5(540B)等,业界对于LLM的探索和应用,以及如何挖掘其学到的知识,引导它们适配不同子任务达到最先进结果(state-of-the-art result,sota),一直是近两年一项极具价值及热门的工作。对于LLM的探索,从起初探索贴近预训练任务的方式构造下游任务,包括各类Prompt Engineering方式,减少微调数据量;再到用非梯度更新的方式,使大模型无需微调情况下,拥有小样本、零样本解决问题的能力,包括上下文学习(In-context learning)、上下文学习的矫正(Calibration)等;利用LLM解决更难的数理推理问题,通过一系列逻辑链(CoT,chain of thought ),深入挖掘大模型的知识和推理能力;进一步,更加看重行动驱动(Action-driven)、意图驱动与大模型的结合,使大模型从意图出发对齐人类需求;以上探索,力求在数量繁多的自然语言任务中达到初步的“质变”效果,尝试通向真正的AGI。
LLM的引入会使行业内公司划分出不同层级(此处很同意谢剑的观点):
知乎讨论话题
https://www.zhihu.com/question/575391861/answer/2834072642
Level1:LLM基础设施公司;类比为一个拥有比较强通用能力的人;Level1的公司会比较少,可能只有1-2家(比如 OpenAI、Google)
Level2:基于LLM结合场景进行商业化应用的公司(以应用为主,没有全体微调) ;类比通用能力的人去一些场景打工挣钱;Level2的公司侧重于基于LLM做出较多应用,包括从头创新做应用、已有的业务场景中升级功能。
Level3:基于LLM+领域场景数据,微调形成具备更强领域能力和一定门槛的产品,通过商业化和数据积累,持续形成业务数据-模型闭环;类比一个领域专家。Level3的公司有很强的专业性和数据积累,比如类似专项面向写作的Jasper.AI等。
七、机遇与调整并存的LLM
LLM的出现使得机遇与挑战并存,机遇在于技术革新势必会带来新赛道的机遇,挑战在于革新也会使越来越多old school方式被抛弃,跟不上节奏落伍的风险将会加大。
1)从技术演进角度来说,LLM可能使NLP形成“大一统”之势。如果说BERT让大部分中间任务基本消亡,NLP传统技艺逐渐被替代,那么LLM则会让很多NLP子领域不再具备独立研究价值,它们均会被纳入LLM技术体系;这对于相关长期从事某些子领域的研究者和从业者是一件可怕的事,累积了一定时间的子领域专家经验/技巧trick,一夜即被“暴力”的LLM击败,对相关业务和从业者挑战巨大;但另一个角度来说,当NLP整体能力到达一定阶段时,“大一统”是必然结果,之前划分较多子领域是因为没有强能力模型而需要分而治之,积极利用LLM拓展自身业务的可能性是机遇所在。
2)从LLM应用角度来说,LLM-as-a-Service 会越来越普遍,OpenAI 提供的 LLMaaS 服务已经具备较高的速度,并开始逐步探索行之有效的盈利模式,这也是下游产品的机遇。截止2021年7月,全球有300多个app在使用GPT3技术,结合gpt3demo网站的数据,其收录了158个基于GPT-3的应用;LLM使得业界能力下限提升,行业门槛下降,业务优势会聚焦在垂直领域的数据积累资源。但LLMaaS的盈利模式并不成熟,尚待检验,合理的模式应该需要涉及用户分层,而非全量用户的铺展,这些均增添了较多不确定性,此为应用层面的挑战。
3)从推理成本来说,配合LLM的模型压缩、前向加速等手段均可以降低推理成本,虽然下游产品推理的服务成本尚高,但其实作为百亿模型,完成大量高智能任务具备初步可行性,此为机遇;但在降本增效的大环境下,真正将LLM投入生产的挑战性极大,对于LLM短期在生产环境下最实际的用途主要聚焦在线下,主要围绕数据扩增、减少标注成本和数据生产。
4) 从训练投入成本来说,作为最限制LLM发展的因素,它也在不断进步,除去本身模硬件升级、模型蒸馏、加速训练技术之外,LLM的稀疏化也会持续发展,SparseGPT应该是其中有代表性的工作之一,此为机遇;当然这样的进步相比高额的投入并不够,所以在第三节中提到的对于LLM的投入,是和相关组织的技术战略相关的。在LM基建层面,目标成为何Level的公司,会影响相关的投入,但LLM绝对是具备高战略价值的投入。
5) 从国内产研角度来说,这一点其实是比较让人忧虑的;因为LLM过于高昂的成本和苛刻的使用条件,这两年国内对于LLM的研究成果较少(累积参数的大模型有,但实际有影响的成果不多),与国外差距在增大。表1可以看到,GPT3后已经更新了5~6代,而国内甚至还没有真正意义上可以匹敌GPT3的基建模型,甚至60亿~130亿的 InstructGPT能力已经超过国内大部分的所谓大模型(当然OpenAI领先太多,其也超出Google的一般大模型)。
当LLM逐渐成为垄断能力,当OpenAI、Google、DeepMind逐渐闭源时,基建模型又会成为“卡脖子”的能力,ChatGPT只是这一阶段的开始。所以笔者认为对于LLM的态度,仅从个人来说,国内大厂战略上务必重视它,积极应对挑战,不用过分悲观,寻求并抓住LLM带来的机遇;基于以上方法利用好可用的LLM,可控成本下优化自身业务,同时紧跟业界研究方向,“借好”LLM带来的新东风。
最后附上相关大语言模型进化表:
| 模型 | 参数量 | 训练数据量 | 方法和结论 | 文献 |
| GPT3 | 0.1B~175B | 约500B tokens | Transformer Decoder | Language Models are Few-Shot Learners |
| LaMDA | 137B | 1.56T words | Transformer Decoder三大目标:质量、安全和根基性(事实正确性)。质量分为合理性、特异性和趣味性;主要根据以上评测指标来约束生成,将生成和排序融合到一起,同时增加了两个任务来融入知识(输入对话上下文,输出知识查询语句;输入知识查询语句,输出生成的最终结果) | LaMDA: Language Models for Dialog Applications |
| WebGPT | 760M、13B、175B | Demonstraions: 6209Comprisons:21548 | 其核心思想是使用GPT3模型强大的生成能力,学习人类使用搜索引擎的一系列行为,通过训练奖励模型来预测人类的偏好,使WebGPT可以自己搜索网页来回答开放域的问题,而产生的答案尽可能满足人类的喜好。 | WebGPT: Browser-assisted question-answering with human feedback |
| FLAN-T5 | 540B | 1800个任务 | 任务的指令 与数据进行拼接。统一的输入输出格式(4种类型),引入chain-of-thought,大幅提高任务数量,大幅提高模型体积; | Scaling Instruction-Finetuned Language Models |
| Sparrow(Chinchilla) | 70B | / | 核心为从人类反馈中学习,创造更安全的对话助手。 | Improving alignment of dialogue agents via targeted human judgements |
| Gopher | 44M~ 280B | 10.5TB | 堆参数的大模型 | Scaling Language Models: Methods, Analysis & Insights from Training Gopher |
| RETRO(Retrieval Transformer) | 172M~7.5B | / | 以 Gopher为基础改进语言模型架构,降低了训练资源成本,并检索增强。在只使用4%的参数量的基础上,RETRO模型获得了与Gopher和 Jurassic-1 模型相当的性能,在大多数测试集上表现优异。 | Improving language models by retrieving from trillions of tokens |
| PaLM | 8B、62B、540B | 780B tokens 包括网页、书籍、维基百科、代码、社交对话 | Transformer Decoder | PaLM: Scaling Language Modeling with Pathways |
| InstructGPT | 1.3B、6B、175B | 微调数据1w+,Reward Model 4w+,PPO无标注数据4w+ | GPT3.5 Finetune+RLHF指令微调 | Training language models to follow instructions with human feedback |
| ChatGPT | / | 推测和InstructGPT差不多 | GPT3.5 (codex基础上)Finetune+RLHF+解决对齐问题 | / |
申明:本文参考了较多网络资料,属于资料整合类,如有侵权请联系作者添加引用或者删除。