前期工作:
-
注册
百度翻译api的账户(个人-高级版),注册后,每个月有2百万的免费翻译字符数。 -
安装pdfminer3k
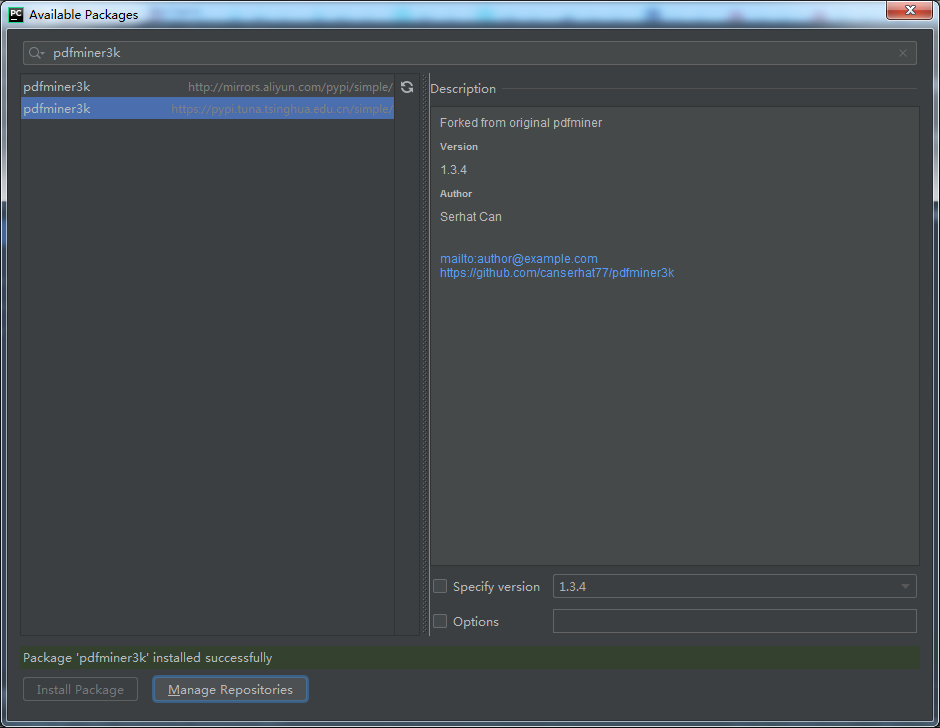
一、UI界面设计
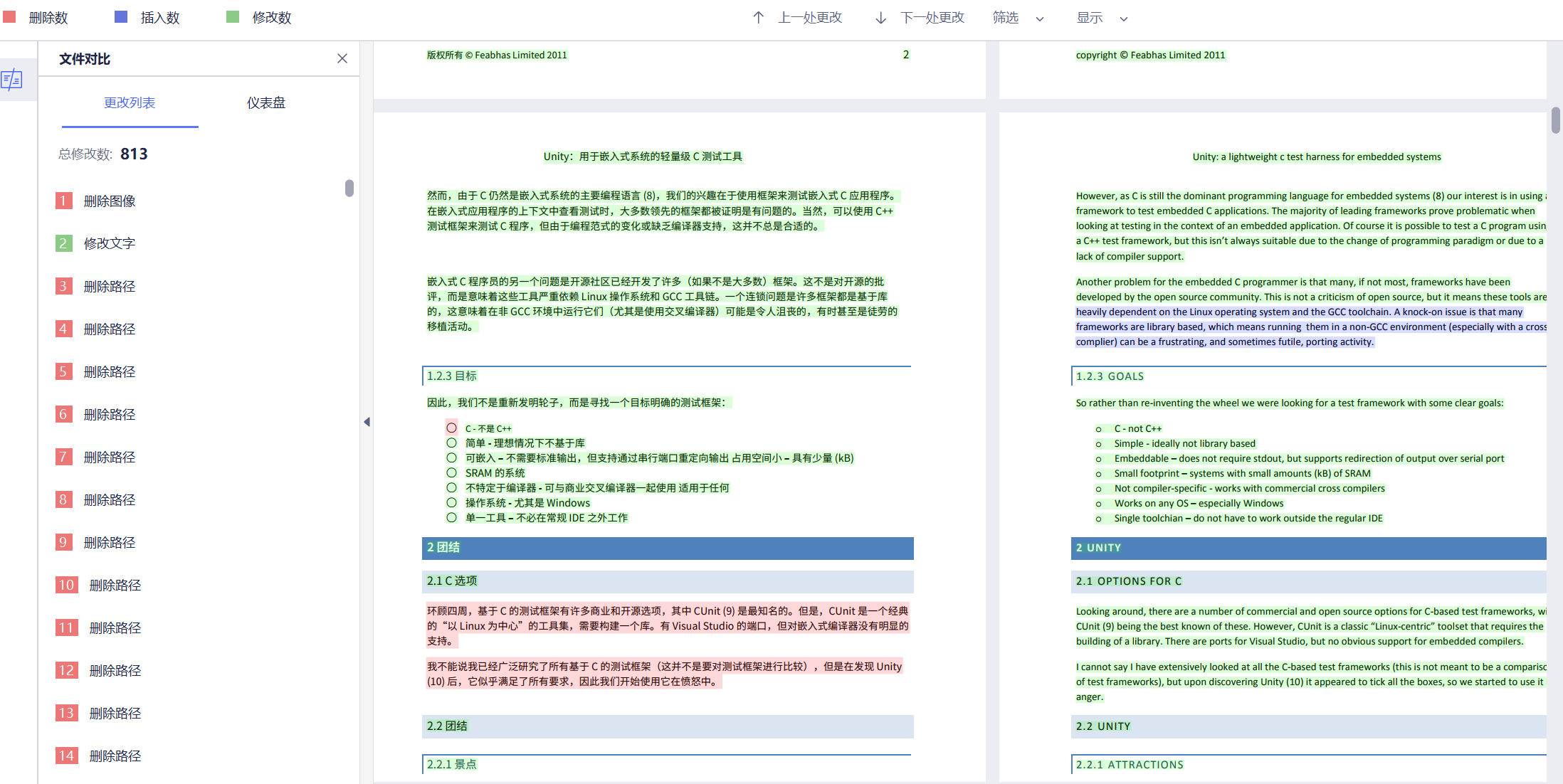
点击路径按钮时弹出文件目录选择窗口,参考文章:
PYQT5实现文件目录浏览
PyQt5-对话框控件使用(QFileDialog)
二、主程序
参考文章:python如何提取英语pdf内容并翻译
知道怎么调用百度翻译的api之后,把各个功能绑定到UI控件上。程序比较简单,结合注释理解即可。
# app.py
# -*- coding: utf-8 -*-# Form implementation generated from reading ui file 'app.ui'
#
# Created by: PyQt5 UI code generator 5.13.0
#
# WARNING! All changes made in this file will be lost!from PyQt5 import QtCore, QtGui, QtWidgetsclass Ui_Form(object):def setupUi(self, Form):Form.setObjectName("Form")Form.resize(577, 469)self.groupBox = QtWidgets.QGroupBox(Form)self.groupBox.setGeometry(QtCore.QRect(10, 120, 391, 241))self.groupBox.setObjectName("groupBox")self.bnt_add_file = QtWidgets.QPushButton(self.groupBox)self.bnt_add_file.setGeometry(QtCore.QRect(290, 30, 75, 23))self.bnt_add_file.setObjectName("bnt_add_file")self.bnt_translate = QtWidgets.QPushButton(self.groupBox)self.bnt_translate.setGeometry(QtCore.QRect(290, 200, 75, 23))self.bnt_translate.setObjectName("bnt_translate")self.files_listWidget = QtWidgets.QListWidget(self.groupBox)self.files_listWidget.setGeometry(QtCore.QRect(10, 30, 256, 192))self.files_listWidget.setObjectName("files_listWidget")self.bnt_delete_file = QtWidgets.QPushButton(self.groupBox)self.bnt_delete_file.setGeometry(QtCore.QRect(290, 70, 75, 23))self.bnt_delete_file.setObjectName("bnt_delete_file")self.groupBox_2 = QtWidgets.QGroupBox(Form)self.groupBox_2.setGeometry(QtCore.QRect(10, 10, 391, 101))self.groupBox_2.setObjectName("groupBox_2")self.label = QtWidgets.QLabel(self.groupBox_2)self.label.setGeometry(QtCore.QRect(30, 30, 54, 12))self.label.setObjectName("label")self.account = QtWidgets.QLineEdit(self.groupBox_2)self.account.setGeometry(QtCore.QRect(90, 30, 241, 21))self.account.setObjectName("account")self.password = QtWidgets.QLineEdit(self.groupBox_2)self.password.setGeometry(QtCore.QRect(90, 60, 241, 21))self.password.setObjectName("password")self.label_2 = QtWidgets.QLabel(self.groupBox_2)self.label_2.setGeometry(QtCore.QRect(30, 60, 54, 12))self.label_2.setObjectName("label_2")self.retranslateUi(Form)QtCore.QMetaObject.connectSlotsByName(Form)def retranslateUi(self, Form):_translate = QtCore.QCoreApplication.translateForm.setWindowTitle(_translate("Form", "Translate"))self.groupBox.setTitle(_translate("Form", "选择文件"))self.bnt_add_file.setText(_translate("Form", "添加文件"))self.bnt_translate.setText(_translate("Form", "全部翻译"))self.bnt_delete_file.setText(_translate("Form", "删除文件"))self.groupBox_2.setTitle(_translate("Form", "百度翻译"))self.label.setText(_translate("Form", "帐号"))self.label_2.setText(_translate("Form", "密码"))# translate.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
# @Author : {Jan__}
# @Time : 2021/2/11 15:17import sys
from PyQt5.QtWidgets import QWidget, QFileDialog, QApplication
from app import Ui_Form
import importlib
importlib.reload(sys)from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed#
import requests
import string
import time
import hashlib
import json##初始化api_url = "http://api.fanyi.baidu.com/api/trans/vip/translate"
api_id = "" ##申请的百度翻译接口的id
cyber = "" ##申请的百度翻译接口的password# 处理PDF
# 读取PDF的内容 filename是待处理的PDF的名字class MyUi(QWidget, Ui_Form):def __init__(self):super(MyUi, self).__init__() # 分别调用了2个父类的初始化函数self.setupUi(self) # UI界面控件的初始化self.signal_connect() # 信号与槽函数绑定def signal_connect(self):self.account.setText(api_id)self.password.setText(cyber)self.bnt_add_file.clicked.connect(self.bnt_add_file_slot)self.bnt_delete_file.clicked.connect(self.bnt_delete_file_slot)self.bnt_translate.clicked.connect(self.bnt_translate_slot)def bnt_add_file_slot(self):fnames, _ = QFileDialog.getOpenFileNames(self, '选择文件', "./", "Files(*.pdf *.txt)")"""参数一:设置父组件参数二:QFileDialog的标题参数三:默认打开的目录,“.”点表示程序运行目录,/表示当前盘符根目录参数四:对话框的文件扩展名过滤器Filter,比如使用 Image files(*.jpg *.gif) 表示只能显示扩展名为.jpg或者.gif文件设置多个文件扩展名过滤,使用双引号隔开;“All Files(*);;PDF Files(*.pdf);;Text Files(*.txt)”"""try:if fnames:# 如果列表非空,则添加到文件列表中去for f in fnames:self.files_listWidget.addItem(f)except Exception as ex:print(ex)def bnt_translate_slot(self):Directory = QFileDialog.getExistingDirectory(self, '结果保存到目录', './')num = self.files_listWidget.count()# 遍历翻译所有文件print("# 遍历翻译所有文件")for _ in range(num):filename = self.files_listWidget.item(0).text()if filename.find('pdf') >= 3:content = self.getDataFromPDF(filename)elif filename.find('txt') >= 3:content = self.getDataFromTxt(filename)else:content = ""print("读取文件失败")returnprint("读取文件成功")f = filename.split('/')CNtextfile = Directory + '/CN_' + f[-1]CNtextfile = CNtextfile.replace('.pdf', '.txt')chinese = ""clist = content.split(".") # split() 通过指定.将英文分成多个句子# 遍历翻译所有句子print("# 遍历翻译所有句子")try:for i in range(clist.__len__()):chinese += (self.translate(clist[i] + '.'))chinese += '\n'self.saveText(chinese, CNtextfile)print("翻译结束,ok")self.files_listWidget.takeItem(0)print("删除文件")except Exception as ex:print(ex)def bnt_delete_file_slot(self):num = self.files_listWidget.currentRow()self.files_listWidget.takeItem(num)print("删除文件")###使用PDFminer读取def getDataFromPDF(self, filename):try:parser = PDFParser(open(filename, 'rb')) # 以二进制打开文件 ,并创建一个pdf文档分析器doc = PDFDocument() # 创建一个pdf文档# 将文档对象和连接分析器连接起来parser.set_document(doc)doc.set_parser(parser)# 初始化文档,当前文档没有密码,设为空字符串doc.initialize("")# 判断该pdf是否支持txt转换if doc.is_extractable:# 创建一个PDF资源管理器rsrcmgr = PDFResourceManager()# 创建一个参数分析器laparamas = LAParams()# 创建一个聚合器device = PDFPageAggregator(rsrcmgr, laparams=laparamas)# 创建一个PDF页面解释器对象interpreter = PDFPageInterpreter(rsrcmgr, device)contents = "" # 保存读取的text# 依次读取每个page的内容for page in doc.get_pages():interpreter.process_page(page)layout = device.get_result() # 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等 想要获取文本就获得对象的text属性,# 在windows下,新文件的默认编码是gbk编码,所以我们在写入文件的时候需要设置一个编码格式,如下:for x in layout:if (isinstance(x, LTTextBoxHorizontal)):results = x.get_text()results = results.replace("(cid:2) ", "") # 去掉连词符results = results.replace("\n", "") # 去掉换行符 因为排版问题 有的换行导致句子中断contents += (results)return contentsexcept Exception as ex:print(ex)def getDataFromTxt(self, filename):try:with open(filename, "r", encoding='utf-8') as f:text = f.read()print(text)content = text.replace("\n", "") # 去掉换行符 因为排版问题 有的换行导致句子中断f.close()return contentexcept Exception as ex:print(ex)# 将读取的content以txt格式存放到本地def saveText(self, content, Textfile):with open(Textfile, "w", encoding='utf-8') as f:f.write(content)# 翻译从pdf提取的contentdef translate(self, content):try:salt = str(time.time())[:10]final_sign = str(self.account.text()) + content + salt + self.password.text()final_sign = hashlib.md5(final_sign.encode("utf-8")).hexdigest()# from to 代表翻译的语言paramas = {'q': content,'from': 'en','to': 'zh','appid': '%s' % self.account.text(),'salt': '%s' % salt,'sign': '%s' % final_sign}response = requests.get(api_url, params=paramas).contentcontent = str(response, encoding="utf-8")json_reads = json.loads(content)if 'trans_result' in json_reads:return json_reads['trans_result'][0]['dst'] + " "else:return str(json_reads)except Exception as ex:print(ex)if __name__ == '__main__':try:app = QApplication(sys.argv) # 实例化一个应用对象,sys.argv是一组命令行参数的列表。Python可以在shell里运行,这是一种通过参数来选择启动脚本的方式。myshow = MyUi()myshow.show()sys.exit(app.exec_()) # 确保主循环安全退出except Exception as ex:print(ex)
三、问题小结
选择文件时报错:
log4cplus:ERROR No appenders could be found for logger (AdSyncNamespace).
log4cplus:ERROR Please initialize the log4cplus system properly.
解决办法:
目录不要含有中文
打开txt文件时报错:
'utf-8' codec can't decode byte 0xa1 in position 8: invalid start byte
解决办法:
txt文件保存时,编码格式需选择utf-8,参考文章:python 报错"UnicodeDecodeError: ‘utf-8’ codec can’t decode byte"的解决办法
不足:
简单翻译英文段落没问题,想翻译期刊文献就不行了,图、表、分栏这些干扰太多了。