1、《长津湖》观后
2018 年有了孩子后,近 3 年没有再看过电影。
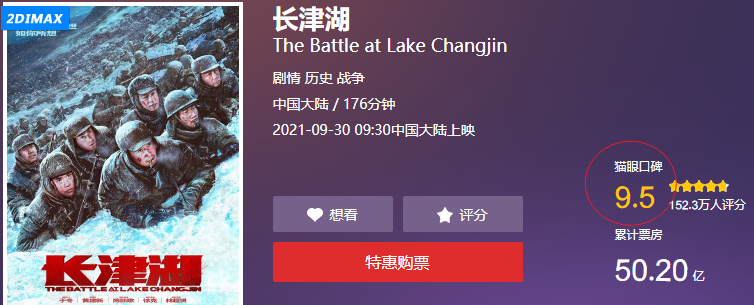
念于《长津湖》的确大热,我对战争片心念神往、对中国近现代史非常好奇,加上老婆的男神段奕宏参演。一拍即合,我俩在国庆假期的最后一天看了这部鸿篇巨制、热血催泪电影。

《长津湖》电影海报
宏大的战争场面、天壤之别的中美装备、物质条件差异、零下40度的恶劣的环境这些都已深深的印在我的脑海里。电影相对真实的还原了历史,这些历史是眼睛可以看到的,耳朵可以听到的,恰是之前学生阶段无法学到的或学的不够深刻的地方。
中学阶段学过魏巍的《谁是最可爱的人》,当时是全篇背下课文的。但是:我刚才自己又逐字逐句完整的读了一遍,不一样、完全不一样......
边读边浑身起了鸡皮疙瘩,之前的懵懂、不懂现在全懂了,之前的死记硬背现在全都理解了。
思绪万千也感慨万千......
电影里的雷公、伍千里、伍万里等是最可爱的人,数以百万的志愿军战士都是最可爱的人。
前辈们的出生入死,就是为了我们不再打仗。
没有他们,就不会有我们的万家灯火。
上面仅是我的一点感触,大家的反馈如何呢?
本文结合 ELK(Elasticsearch、Logstash、Kibana)实现了《长津湖》15万+影评数据的可视化分析。
2、动手之前我的几点疑问与思考
Q1:数据从哪里来?
Q2:原始数据就够了吗?需不需要清洗?如何清洗?
Q3:有哪些字段?如何建模?
Q4:做哪些维度的分析?
Q5:如何做可视化分析?
这么一分析,就知道:数据是大前提,没有了数据的基础,清洗、建模、可视化分析都是“空中楼阁”。
如果从一个小项目的角度出发,我的初步构想数据流图如下:
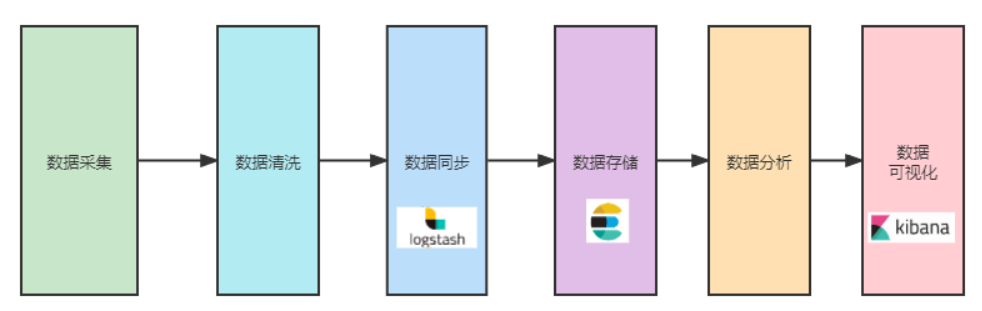
其中:
数据采集:解决数据源头问题,得到初始数据。
数据清洗:确保 Logstash 环节能同步,做必要的特殊字符清洗处理。
数据同步:同步选型logstash_input_csv,logstash input、output、filter 环环相扣,协同搞定。
数据存储:基于建模实现数据落地存储,方便检索、聚合、后续可视化分析。
数据分析:实际分析哪些维度可以可视化,有没有偏差,有偏差需要调整建模,重新导入或者 reindex 数据。
数据可视化:基于数据存储的特定维度,实现可视化分析。待可视化分析的维度,在建模阶段就要敲定。以上,大的框架已初步搞定,剩下就是各个小模块的填充工作。
3、影评数据获取可行性分析
如前所述,数据分析的前提是:先拿到数据。
可供采集选型:mao眼、豆ban等。由于豆ban评论字段较少,可供分析的维度自然少一些,所以选择mao眼影评数据。

站在 N 多前辈mao眼影评采集 + 分析的基础上,猫眼有 API 能拿到全量的 json 形式的评论数据,基本确立了可行性。
确立可行性之后,要看能拿到哪些字段,以便后续建模和可视化分析。
初步公开可获取的可用字段如下:
comment_id:评论id,全局唯一。
approve:评论点赞数。
reply:评论回复数。
comment_time:评论时间。
sureViewed:是否真实观看。
nickName:昵称。
gender:性别。
cityName:城市。
userLevel:用户等级。
user_id:用户id。
score:评分。
content:评论内容。
cai 集过程非本文重点,所以略过。
初始 CSV 数据如下图所示:

4、可分析数据字段及预期可视化内容
4.1 评论时间走势图
横轴:comment_time。
纵轴:评论数。
4.2 性别比例饼图
基于字段:gender
4.3 城市分布Top图
横轴:人数。
纵轴:城市。
4.4 用户等级饼图
基于字段:userLevel。
4.5城市地理位置坐标图城市分布图
基于字段:cityName。
遇到问题:没有坐标信息,如何通过地图可视化?
4.6 评分饼图
基于字段:score。
遇到问题:字符串类型不能处理,需要类型转换,如何做?
4.7 评论内容词云
基于字段:content
遇到问题:content 正文内容如何形成词云呢?
4.8 评论点赞+再评论混合排行榜
基于字段:approve。
4.9 情感分析
遇到问题:需要根据content 生成情感值
后面再扩展
5、数据清洗
5.1 采集环节清洗
比如:数据要基于键值评论 id 去重,以确保避免数据重复。
数据同步环节清洗。
比如:去掉 message 字段,避免 ES 端重复存储。
比如:csv 中特定的引号等特殊字符要处理掉。
比如:csv 格式要逐行规范,避免同步大量报错。
5.2 数据预处理清洗
下面的建模、预处理小节详细介绍。
6、数据建模
6.1 数据建模的重要性
数据建模非常重要,建模起到了承上启下的衔接作用。
一方面:csv 的数据要逐个字段映射为 ES 的字段。
字段类型设置要保证全局可用、支持未来可扩展。
重复建模需要 reindex 操作,数据量越大,时间成本越高。
另一方面:可视化部分要基于 ES 字段。
ES 字段设置的不规范,会导致后面数据没法进行可视化或者效果不好。
6.2 遇到问题及解决方案
Q1:content 正文内容如何形成词云呢?
解决方案:content 这么大的字段,通常设置为:text 类型。
但是,咱们需要可视化词云,所以需要在 text 基础上,开启:fielddata。
类似词云分词,之前文章也分析过,所以轻车熟路。
Q2:已有字段不足以支撑可视化分析?
解决方案:加字段,新字段数据结合预处理添加。
新增字段包括:
(1)director tag 字段 用途:形成导演词云。
(2)starring 明星 tag 字段 用途:形成明星词云。
(3)location 坐标字段 用途:绘制坐标锚点。
Q3:日期字段类型多且不一致导致同步报错,如何解决?
解决方案:Mapping 建模全量列举。
这个 bug 解决花费近小半天时间。
最终,Mapping 敲定如下所示:
PUT changjinhu_movie_index
{"settings": {"index": {"default_pipeline": "auto_process"}},"mappings": {"properties": {"comment_id": {"type": "keyword"},"approve": {"type": "long"},"reply": {"type": "long"},"comment_time": {"type": "date","format": " yyyy-M-d H:m || yyyy-M-dd H:m || yyyy-M-dd H:mm || yyyy-M-d HH:mm || yyyy-M-dd HH:mm ||yyyy-MM-dd HH:mm || yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"},"sureViewed": {"type": "keyword"},"nickName": {"type": "text","analyzer": "ik_max_word","fields": {"keyword": {"type": "keyword"}}},"gender": {"type": "keyword"},"cityName": {"type": "text","analyzer": "ik_max_word","fields": {"keyword": {"type": "keyword"}}},"userLevel": {"type": "keyword"},"user_id": {"type": "keyword"},"score": {"type": "keyword"},"score_level": {"type": "integer","fields": {"keyword":{"type":"keyword"}}},"director": {"type": "keyword"},"starring":{"type":"keyword"},"content": {"type": "text","analyzer": "ik_max_word","fields": {"smart": {"type": "text","analyzer": "ik_smart","fielddata": true},"keyword": {"type": "keyword"}}},"location": {"type": "geo_point"}}}
}7、数据预处理
基础清洗有了,建模有了,重头戏就放在数据预处理上了。
刚才也提及:我们不止是基于 csv 已有的字段做分析,而是会扩展了很多字段。
那么面临问题是:新扩展字段的数据怎么来?
director tag 字段、starring 明星 tag 字段
最后的呈现不能全局搜索明星和导演形成词云,效率太低。
解决方案:借助 ingest 管道预处理,提前给满足给定条件的数据打上明星和导演的标记。
举例如下,借助 painless 脚本实现。
if(ctx.content.contains('易烊千玺') | ctx.content.contains('易烊') | ctx.content.contains('千玺')){ctx.starring.add('易烊千玺')}location 坐标字段
需要借助城市名称到城市经纬度坐标的映射关系,添加坐标字段。
这里当然可以在 csv 层面通过遍历添加或者在 ES 端通过 update_by_query 添加。
最后,我选择在 ingest 预处理环节添加,办法相对笨一些,但是效果不错,达到预期。
代码有几百行,篇幅原因,此处省略。
至此,我们就扫清了一切数据层面的障碍,接下来就是同步导入数据、数据分析&数据可视化了。
同步中规中矩,借助:logstash_input_csv 实现。
input csv 配置。
filter 添加列字段。
columns => ["comment_id","approve","reply","comment_time","sureViewed","nickName","gender","cityName","userLevel","user_id","score","content"]}output es 集群配置。
logstash 同步环节截图:

8、Kibana 可视化分析
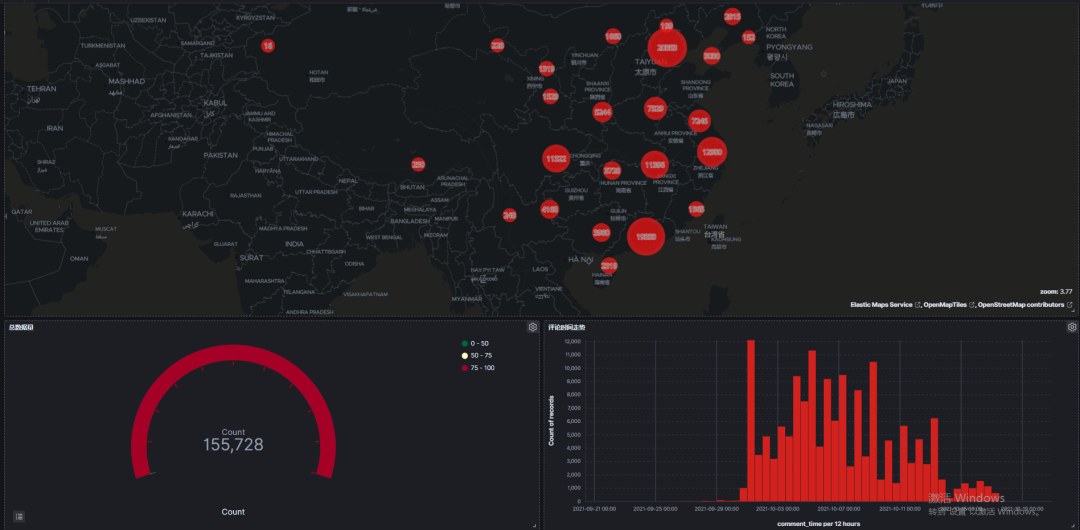
8.1 基于城市名称经纬度坐标的可视化
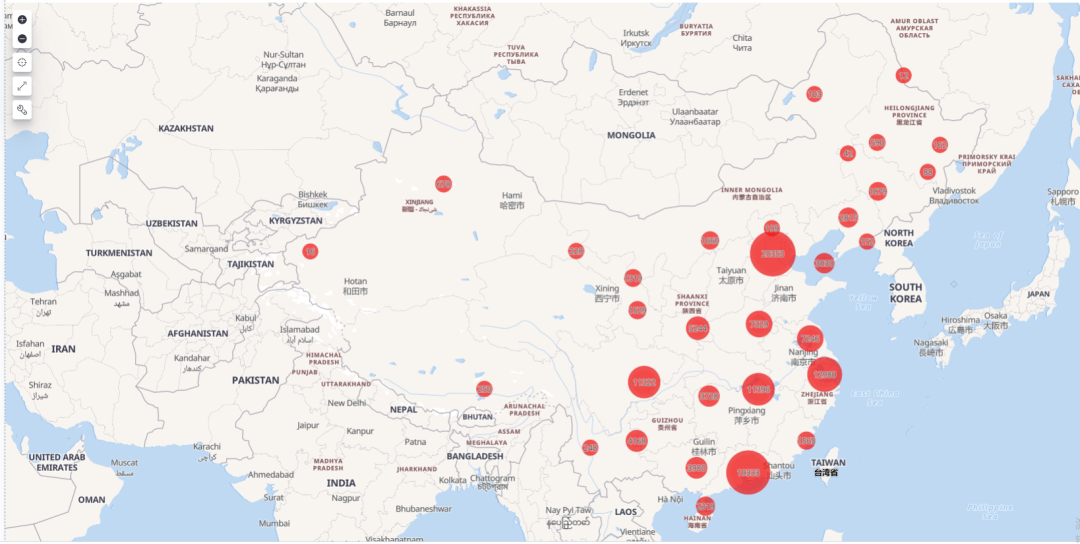
红球越大,代表观影人数阅读。
由多到少依次为:北京、深圳+广州、成都+重庆、上海等。
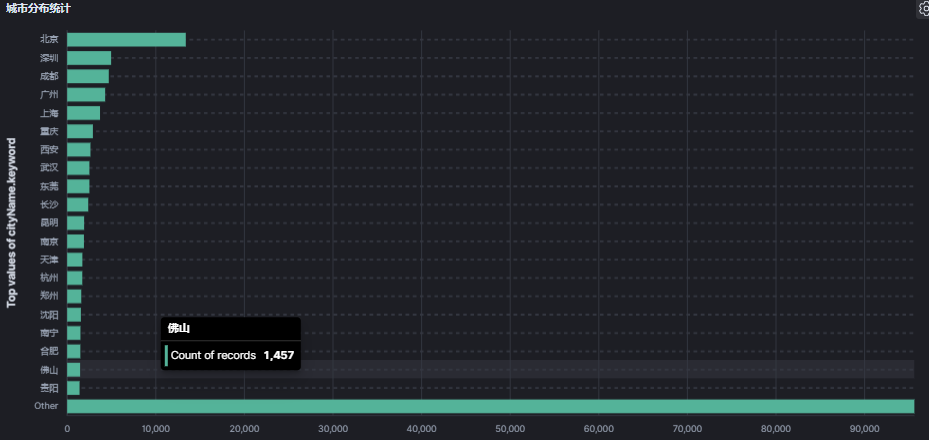
和下面的基于城市名称的统计结果一致。
8.2 总数据量统计图
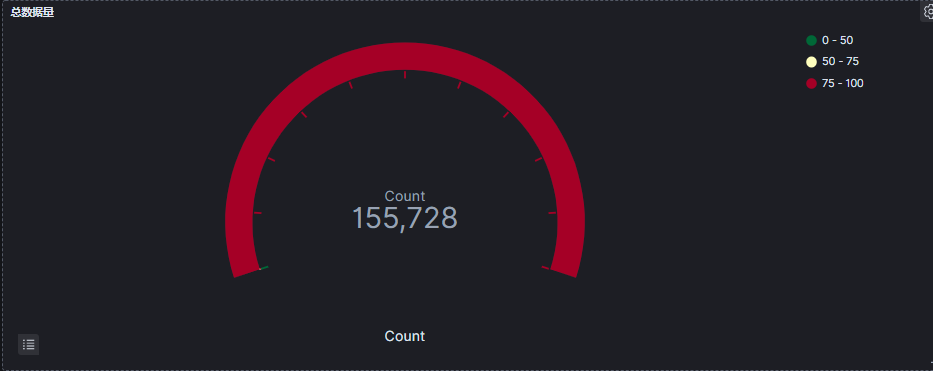
15 W+的评论数据。
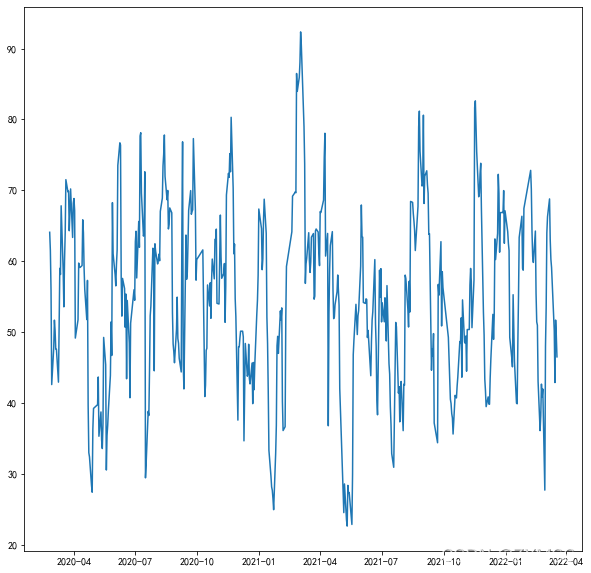
8.3 评论时间走势图
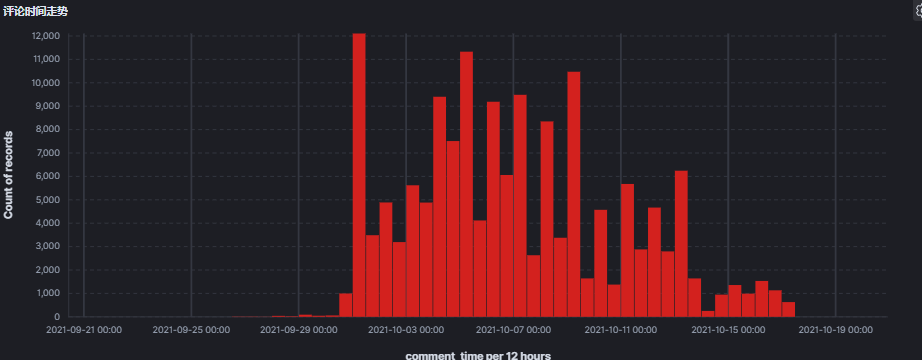
可以看出来,存在超前观看情况,9月底就有评论。
10 月1 日 迎来第1高峰,10 月 5 日迎来第2高峰。
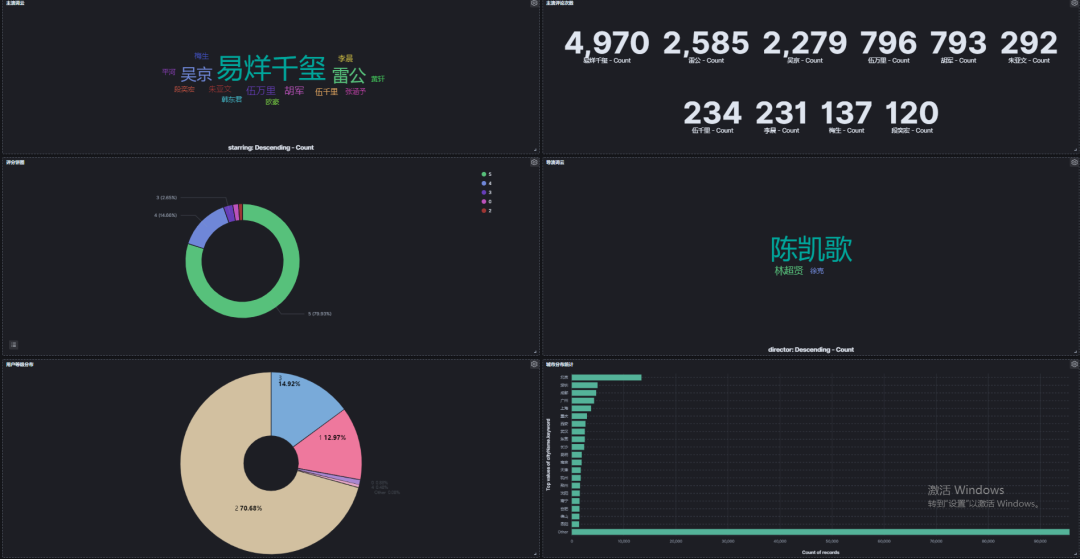
8.4 主演词云和评论次数统计图

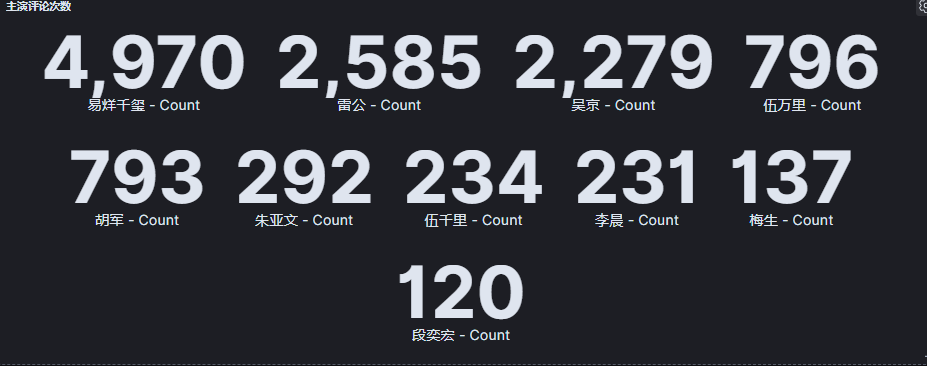
无可争议,易烊千玺作为顶级流量,关注度最高。在雷公和吴京之间关注高的是雷公。
至少说明:胡军主演的雷公深入人心。
我是在“沂蒙山小调”出来之后,哭成泪人的,太感人了。
8.5 导演词云

陈凯歌导演排在第一位,他的关注度也是最高的。
林超贤和徐克导演比较,林超贤导演的关注度要高一些。
8.6 评分统计
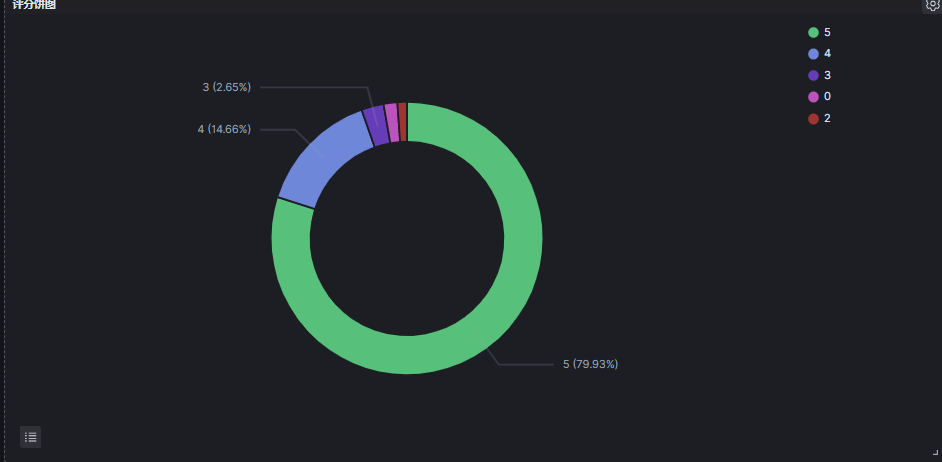
实现的时候,4分、4.5分统计为 4。
可以看出:4分之上的比率为:94.59%。
基本对应评分:9.5 分。
8.7 用户等级统计
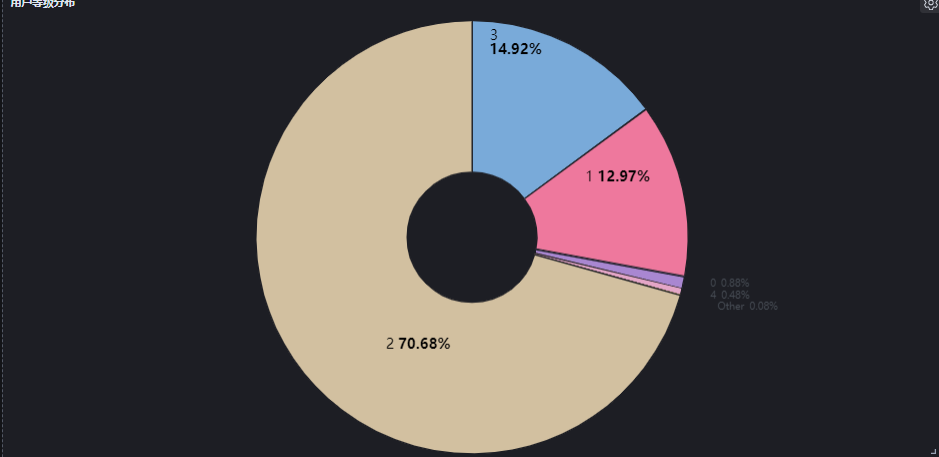
70.68% 的处于2级。
8.8 最多点赞和最多评论叠加用户信息图
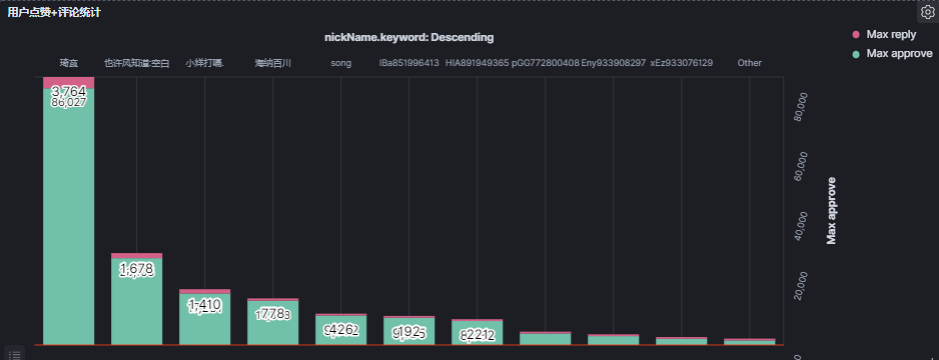
此处kibana 有文字叠加效果,看着像是bug。
8.9 总评论词云

电影好不好,观众说了算。
《长津湖》实至名归,票房破 50 亿是最好的证明。观众的评论最多的是:震撼、好看、值得、致敬、推荐、吾辈、铭记等。
这里在处理词云的时候,吸取之前的教训,使用:ik_smart 粗粒度分词。
并且手动过滤掉一些单字“噪音“分词,确保更直观,相对真实的反应群众的呼声。
整体效果图:

9、小结
从构思到实现前后断断续续2个周的时间,中间清洗、预处理花费时间比较多。
类似影评分析国内基本用 python 结合 echarts 居多,而强大的 ELK 基本都能覆盖到,本文做了初步验证。
大家有好的想法也欢迎留言交流。
最后,我想以《谁是最可爱的人》中的一段话结束本篇文章,算作是对先辈们的缅怀,正如《长津湖》宣传海报所说:“如今繁华盛世、如您所愿”。
“亲爱的朋友们,当你坐上早晨第一列电车驰向工厂的时候,当你扛上犁耙走向田野的时候,当你喝完一杯豆浆、提着书包走向学校的时候,当你坐到办公桌前开始这一天工作的时候,当你往孩子口里塞苹果的时候,当你和爱人一起散步的时候……朋友,你是否意识到你是在幸福之中呢?你也许很惊讶地说:“这是很平常的呀!”可是,从朝鲜归来的人,会知道你正生活在幸福中。请你意识到这是一种幸福吧,因为只有你意识到这一点,你才能更深刻了解我们的战士在朝鲜奋不顾身的原因。朋友!你是这么爱我们的祖国,爱我们的伟大领袖毛主席,你一定会深深地爱我们的战士,——他们确实是我们最可爱的人!”
推荐
1、重磅 | 死磕 Elasticsearch 方法论认知清单(2021年国庆更新版)
2、Elasticsearch 7.X 进阶实战私训课(口碑不错)
3、项目实战 01:将唐诗三百首写入 Elasticsearch 会发生什么?
更短时间更快习得更多干货!
已带领70位球友通过 Elastic 官方认证!
中国仅通过百余人

比同事抢先一步学习进阶干货!