歌词生成相较于普通文本生成,需要配合特定的乐曲,并演唱。因而要求,每句歌词演唱的长度正好合拍,即不同曲子,每句歌词的字符个数是要受限制于乐曲。
本文暂不考虑曲配词问题,只是将问题抽象为,在已知歌词每句的字数时,如何生成一个文本,满足字数格式。歌词的押韵没有古诗那么严格,但押韵的歌词朗朗上口,更易演唱,对于歌词生成还是很重要的。总之,歌词生成应当满足两个条件:
(1) 每句的字数可控
(2) 押韵
针对上述两个问题,发表在ACL2020的《Rigid Formats Controlled Text Generation》【1】,可以很好地解决字数可控和押韵问题。该论文将其模型称为SongNet。既可以读作“宋(词)Net”(论文本身是为了生成宋词),又可以读作“Song Net”(歌词网络),一语双关。
1. SongNet简述

SongNet是基于BERT【2】做的改进。相较于BERT,SongNet有如下不同:
将格式信息embedding,输入到模型
通过mask使得BERT具有生成能力

接下来首先介绍,SongNet所属的领域:条件文本生成。
2. 条件文本生成
文本生成领域分为三个部分,自由文本生成(Generic / Free-Text Generation )、条件文本生成(Conditional Text Generation)以及受约束的文本生成(Constrained Text Generation),条件文本生成和受约束的文本生成两者并没有明确的界限,该文将文本生成领域看做两个部分自由文本生成和条件文本生成。【3】
自由文本生成是,没有显式地给出条件的文本生成任务,即只要不是条件文本生成,便是自由文本生成任务。其概率公式如下,

相较于条件文本生成,自由文本生成,只是去建模文本的一个前后依赖。
条件文本生成是,在已知条件情况下,生成满足条件的文本的任务。该任务的概率表示如下,

即,模型需要建模一个条件概率,p(x|c),其中c是条件的向量表示,x是单个文本的向量表示,<i表示在第i个时间步之前的文本。
实际情况下,条件文本生成的应用更多,狭义的包括根据主题生成文本、根据情感生成文本,广义的角度来看,机器翻译也可以看做条件文本生成,对于中-英翻译任务,可以看做条件为中文,然后生成英文文本。
例如,生成一个情绪为积极乐观的文本。(文本情绪为积极乐观,即是条件)
条件文本生成的关键在于,如何将条件加入到模型中,常见方法有两种:
将条件进行embedding:无论训练还是生成截断,条件作为输入编码,进行embedding
重加权:在生成阶段,用条件信息重新调整每个时间步下,每个词生成的概率值。
SongNet采用的是第一种方式,将条件进行embedding。
3. Embedding
该章节主要介绍,Embedding的发展,即从Token Embedding(字符编码)到Position Embedding(位置编码),有了这些前置知识,能更好地理解条件Embedding。
最初的Embedding:Token Embedding
embedding是,将离散的符号组成的序列数据,转化为由词向量(word vector)表示的矩阵的过程。
token embedding是, 将自然语言文本转化为词向量(word vector)表示的矩阵的过程。只包含了文本的字符序列信息。
机器学习模型是在做数值的运算s,而自然语言文本是由离散的符号表示的,无法直接进行加法、乘法等运算,更无法进行反向传播,因而需要将文本数值化(连续化),这个过程即是embedding。通用的方案是,将文本切分成token,接着id化,然后再将每个token用一个向量来表示,该过程即完成了embedding工作。
embedding的过程可以分解为如下的过程:
1. token化:将文本切分成token,token指的是代表文本的组成元素的符号,常用的是字、子词或者词。
2. id化:每个token都对应着一个id号,用id号表示token。
3. embedding:将id转化为向量。通常id号对应着向量的embedding的权重表中的位置。对于每个id,查找权重表中其对应的向量,拼接成整个文本。
如下为对文本“无谓人海的拥挤”进行embedding。
文本:无畏人海的拥挤
第一步:token化(字为单位,空格分割各个token),token化的结果为无 畏 人 海 的 拥 挤 的
第二步:id化,假设,无的id为0,依此类推,重复的字用第一次出现的id号表示
则id化的结果为0 1 2 3 4 5 3
第三步:embedding,(只截取用到的)假设,V的大小为6,dim的大小为6
假设embedding的权重矩阵为 W =[[1,2,3,4,5,6],[7,8,9,10,11,12],[13,14,15,16,17,18],[19,20,21,22,23,24],[25,26,27,28,29,30],[31,32,33,34,35,36]]
则该文本的embeddding为E = [[1,2,3,4,5,6],[7,8,9,10,11,12],[13,14,15,16,17,18],[19,20,21,22,23,24],[25,26,27,28,29,30],[31,32,33,34,35,36],[19,20,21,22,23,24]]
3.1 Position Embedding
但只有字符信息,并不能很好的表示文本。如下,
文本一:我喜欢这个电影,因为它不包含人性的思考。
文本二:我不喜欢这个电影,因为它包含人性的思考。
文本一和文本二的意思完全相反,但对于自然语言模型而言,尤其是self-attention的模型,难以识别字符位置的不同导致的文本差异。
如下为self-attention的公式。dense为全连接层。

相应的示例为下图。

如图,self-attention相当于对所有的e进行了两两运算,这过程中并没有建模序列,因而说self-attention基本上没有序列建模能力。
因而,NLPer提出了Position Embedding【4】,即将每个token的位置,通过运算变成向量,然后与原本的token embedding进行add操作,作为文本的表示。从而加强模型对token的位置敏感性,该过程也是在建模句法特征。
该过程体现一个思路,将模型难以建模的特征通过embedding,融入模型中,从而增强其建模能力。
对于条件文本生成,可以将条件看做是文本中难以建模的信息,然后进行embedding。
回顾文章开始提到的两个要求,字数可控和押韵,两者均是目前文本生成模型所缺乏的,作者提出了Token Embeddings、Format and Rhyme Embeddings、Segment Embeddings、Intra-Position Embeddings四个额外的格式信息embedding来增强模型对字数可控和押韵的表现。
4. 格式信息embedding
格式信息的embedding也类似token embedding的步骤,第一w步也是进行token化,由于信息本身并不是离散的符号,因而第一步需要将其表示为离散的符号。
4.1 Format and Rhyme Embeddings
对于每句歌词,用标点符号用c1表示,最后一个字用符号c2表示,其他字符用c0表示。
例如:我听见远方下课钟声响起(11个字,1个标点)
其Format and Rhyme Embeddings = [c0,c0,c0,c0,c0,c0,c0,c0,c0,c0,c2,c1] 10个c0,1个c2,一个c1。
这样可以让押韵的那个字单独获得一种表示,从而让模型注意到该位置的字与其他字符的不同,从而做到押韵。
4.2 Intra-Position Embeddings
对于每句歌词,将字符位置从右到左,依次用p[位置索引]的方式表示。
例如:我听见远方下课钟声响起,(11个字,1个标点)
其Intra-Position Embeddings = [p11,p10,p9,p8,p7,p6,p5,p4,p3,p2,p1,p0]
Intra-Position Embeddings是为了让模型在生成第一个字的时候,就知道这句歌词有几个字;从右到左的顺序,使得p1正好指向韵脚,更好押韵。
4.3 Segment Embeddings
类似BERT的Segment Embedding,第一句每个字符的segment Embeddings为s0,第二句每个字符的segment Embeddings为s1。
对于歌词:
我听见雨滴落在青青草地
我听见远方下课钟声响起
可是我没有听见
你的声音认真呼唤我姓名
其Segment Embeddings为
s0,s0,s0,s0,s0,s0,s0,s0,s0,s0,s0,s0,
s1,s1,s1,s1,s1,s1,s1,s1,s1,s1,s1,s1,
s2,s,2,s2,s2,s2,s,2,s2,s2,s2,s,2,s2,s2,
s3,s3,s3,s3,s3,s3,s3,
s4,s4,s4,s4,s4,s4,s4,s4,
Segment Embeddings可以使模型确定每个字在所在的句子顺序。
4.4 如何将如上的格式信息融合到模型中
这三种embedding都兼顾到了字数可控和押韵。
SongNet将上述三种的embedding的符号(s0、s1、c0、c1、p0、p1等等)看做字(token),加入到vocab中,与文本字符(我、你等等)经过同一个embedding层,得到向量,再相加。
即,将Intra-Position Embeddings、Segment Embeddings、Format and Rhyme Embeddings相加得到format_embedding。
相应代码为:
x = self.tok_embed(ys_inp) + self.pos_embed(ys_inp) + self.tok_embed(ys_tpl) + self.tok_embed(ys_seg) + self.tok_embed(ys_pos)
ys_inp:Token Embeddings的id表示
ys_tpl:Format and Rhyme Embeddings的id表示
ys_seg:Segment Embeddings的id表示
ys_pos:Intra-Position Embeddings的id表示
self.tok_embed:字符embedding层
self.pos_embed:位置embedding层
相较于embedding章节的token embedding,格式信息的embedding是用符号而不是字来表示token。也要进行id化以及embedding。
以上即为SongNet的第一个亮点,接下来阐述,SongNet是如何让BERT拥有生成能力。
5. Mask策略
原版的BERT并不具有生成能力,究其原因要从自回归语言模型说起。
5.1 自回归语言模型
自回归生成模型是文本生成常用的一种模型。通过迭代生成token,来完成整个文本的生成。
如下图,浅绿色的矩形为同一个模型(可以看做单向单层RNN网络模型),蓝色矩形为文本的token(可以看做字)。
要生成“你是谁”需要,在第一个时间步,根据”你“生成“是”;第二个时间步,根据”是“和第一个时间步传来的“你”信息,生成”谁“·····

5.2 使BERT具有生成能力:Masking Multi-Head Self-Attention
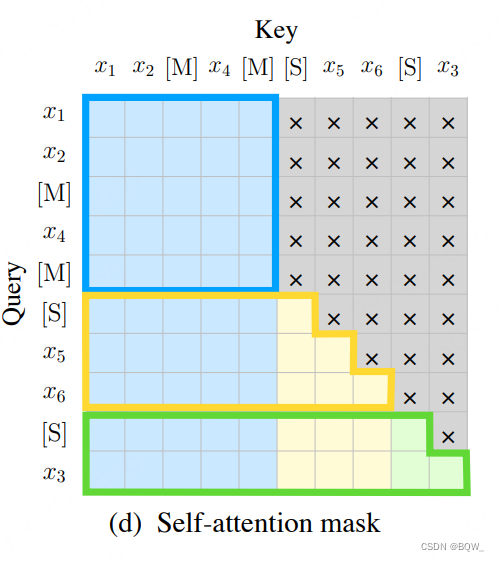
BERT是双向的transformer模型,在每个时间步知道下文(即在“你”位置,知道“是”和“谁”的信息),从而无法作为生成模型使用。
BERT的各个时间步所知道的信息可以表示为:
第一个时间步:你是谁
第二个时间步:你是谁
第三个时间步:你是谁
自回归生成模型,在各个时间步所知道的信息:
第一个时间步:你
第二个时间步:你是
第三个时间步:你是谁
两者可以通过一个三角矩阵进行转换,即mask,如下图。

SongNet就是通过上图的mask,将BERT变成自回归语言模型,其核心实现为Masking Multi-Head Self-Attention。
Masking Multi-Head Self-Attention的算法步骤是:
(1) 将embedding信息mask,得到mask_embedding
(2) 将mask_embedding输入到transformer层中,得到context_vector
注:该方案并非SongNet首创,类似的思路在19年微软的Unilm【5】模型中,有所体现。
5.3 让模型有大局观:Global Multi-Head Attention
在每个时间步,模型不应当知道格式信息,但可以知道文本整体格式的信息,从而更好地输出符合格式的文本。因而,对于格式信息,不应当进行mask操作,即没有mask的attention即是Global Multi-Head Attention。
另外,Global Multi-Head Attention还将内容信息和格式信息进行了融合。
注:该过程涉及了self attention的实现,暂不做展开。
算法步骤:
将格式信息和内容信息通过没有mask的transformer层,进行融合。
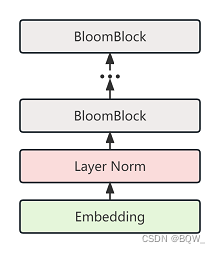
这时候再看SongNet结构图。
 可以总结出SongNet模型的算法步骤:
可以总结出SongNet模型的算法步骤:
(1) 进行格式信息的embedding,得到format_embedding
(2) 将format_embedding经过add得到format_vector
(3) 对当前时间步以前的字符信息和格式信息进行embedding,得到content_embedding
(4) 将content_embedding经过Masking Multi-Head Self-Attention得到content_vector
(5) 将content_vector与content_embedding一同输入到Global Multi-Head Attention中,得到输出
6. 总结
SongNet的架构,没有什么数学推导,更多的是符合直觉的设定。通过增加embedding,从而控制文本生成,可能成为可控文本生成领域的一个主要思路。
即:特征->符号化->embedding->融入模型
该文旨在初步介绍SongNet模型用于歌词生成,行者AI将会持续跟进歌词生成的博文推送,希望大家多多关注。
参考文献
- Li, P., Zhang, H., Liu, X. and Shi, S., 2020. Rigid Formats Controlled Text Generation. arXiv preprint arXiv:2004.08022.
- Devlin J, Chang MW, Lee K, Toutanova K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805. 2018 Oct 11.
- Garbacea, C. and Mei, Q., 2020. Neural Language Generation: Formulation, Methods, and Evaluation. arXiv preprint arXiv:2007.15780.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł. and Polosukhin, I., 2017. Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
- Dong, L., Yang, N., Wang, W., Wei, F., Liu, X., Wang, Y., Gao, J., Zhou, M. and Hon, H.W., 2019. Unified language model pre-training for natural language understanding and generation. In Advances in Neural Information Processing Systems (pp. 13063-13075).
PS:
我们是行者AI,我们在“AI+游戏”中不断前行。
如果你也对游戏感兴趣,对AI充满好奇,那就快来加入我们(hr@xingzhe.ai)。