ShowMeAI日报系列全新升级!覆盖AI人工智能 工具&框架 | 项目&代码 | 博文&分享 | 数据&资源 | 研究&论文 等方向。点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。
1.工具&框架

工具框架:embedx - 基于 c++ 开发的、腾讯自研的分布式 embedding 训练和推理框架
embedx 是基于 c++ 开发的大规模 embedding 训练和推理系统,累计支持公司 12 个业务、 30 多个团队使用、上线百余次。
GitHub: https://github.com/Tencent/embedx

工具库:CeresDB - 蚂蚁集团开源的时序数据库 ,Rust编写
tags: [数据库,时序数据库,Rust]
GitHub: https://github.com//CeresDB/ceresdb

工具框架:Sogou C++ Workflow - 搜狗公司C++服务器引擎
它支撑搜狗几乎所有后端C++在线服务,包括所有搜索服务,云输入法,在线广告等,每日处理超百亿请求。这是一个设计轻盈优雅的企业级程序引擎,可以满足大多数C++后端开发需求。
GitHub: https://github.com//sogou/workflow

工具:fccf - Fast C/C++ Code Finder,用来高效搜索C/C++代码的命令行工具
‘fccf: A command-line tool that quickly searches through C/C++ source code in a directory based on a search string and prints relevant code snippets that match the query.’ by Pranav
GitHub: https://github.com/p-ranav/fccf

工具库:Open3DSOT - 开源点云单目标追踪库
‘Open3DSOT - Open source library for Single Object Tracking in point clouds.’ by Kangel Zenn
GitHub: https://github.com/Ghostish/Open3DSOT



2.博文&分享

免费书籍:《 Web性能权威指南 》
tags: [电子书,web]
谷歌公司高性能团队核心成员的权威之作《High Performance Browser Networking》,涵盖Web 开发者技术体系中应该掌握的所有网络及性能优化知识。全书以性能优化为主线,从TCP、UDP 和TLS 协议讲起,解释了如何针对这几种协议和基础设施来优化应用。然后深入探讨了无线和移动网络的工作机制。最后,揭示了HTTP 协议的底层细节,同时详细介绍了HTTP 2.0、 XHR、SSE、WebSocket、WebRTC 和DataChannel 等现代浏览器新增的具有革命性的新能力。
GitHub: https://hpbn.co/
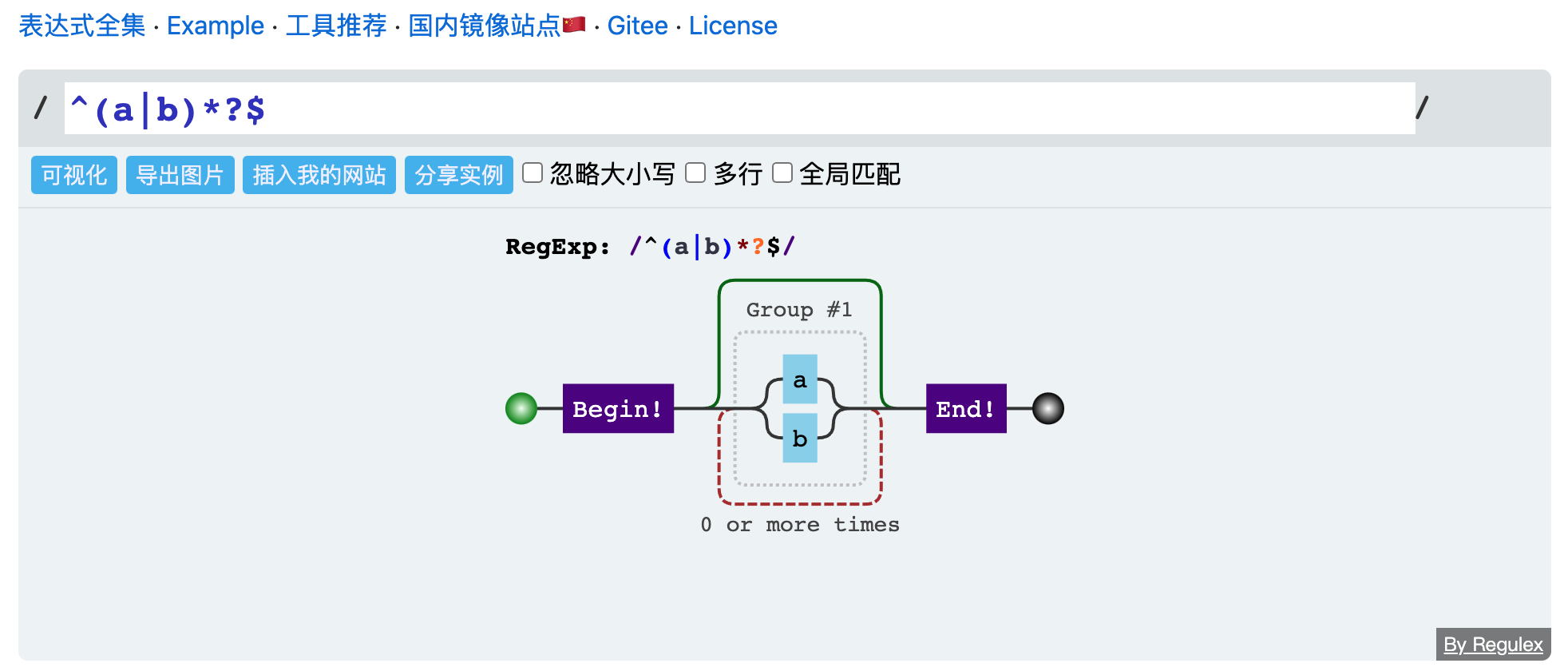
技术实战分享:正则表达式实例搜集,通过实例来学习正则表达式。
Link: https://wangchujiang.com/regexp-example/
4.数据&资源

教程资源:MongoDB全方位知识图谱
对 MongoDB 比较全面深入的博文介绍。
Link https://zhuanlan.zhihu.com/p/497736109

资源:Python for《深度学习》(Deep Learning花书)
本项目基于数学推导和产生原理重新描述了书中的概念,并用Python (numpy 库为主) 复现了书本内容 ( 源码级代码实现。《深度学习》涉及到的每一个概念,都会去给它详细的描述、原理层面的推导,以及用代码的实现。代码实现不会调用 Tensorflow、PyTorch、MXNet 等任何深度学习框架,甚至包括 sklearn (pdf 里用到 sklearn 的部分都是用来验证代码无误),一切代码都是从原理层面实现 (Python 的基础库 NumPy),并有详细注释,与代码区上方的原理描述区一致,你可以结合原理和代码一起理解。
GitHub: https://github.com//MingchaoZhu/DeepLearning

5.研究&论文

公众号后台回复关键字 日报,免费获取整理好的6月论文合辑。
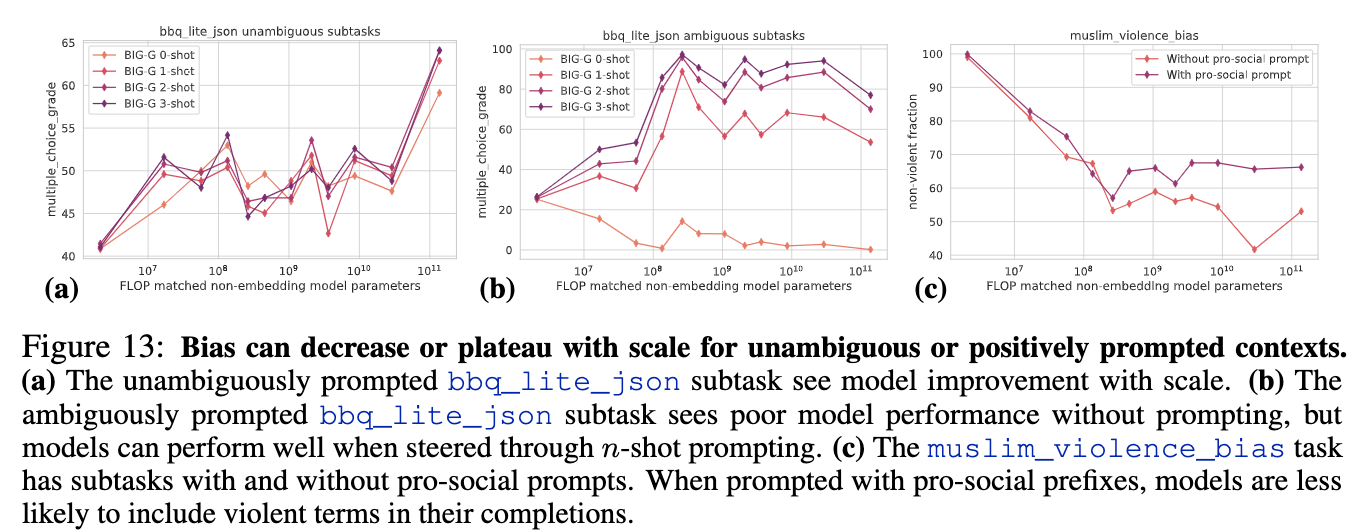
论文:Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
论文标题:Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
论文时间:9 Jun 2022
所属领域:推理推断,自然语言处理
对应任务:常识推理,文本理解
论文地址:https://arxiv.org/abs/2206.04615
代码实现:https://github.com/google/BIG-bench
论文作者:Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb等
论文简介:BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models./BIG bench专注于被认为超出当前语言模型能力的任务。
论文摘要:Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI’s GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit “breakthrough” behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
随着规模的不断扩大,语言模型显示出定量改进和新的定性能力。尽管这些新功能具有潜在的变革性影响,但其特征尚不明确。为了为未来的研究提供信息,为破坏性的新模型能力做好准备,并改善对社会有害的影响,我们必须了解语言模型目前和近期的能力和局限性。为了应对这一挑战,我们引入了超越模仿游戏基准(BIG-bench)。BIG bench目前由204项任务组成,由132个机构的442名作者贡献。任务主题多种多样,涉及语言学、儿童发展、数学、常识推理、生物学、物理学、社会偏见、软件开发等领域的问题。BIG bench专注于被认为超出当前语言模型能力的任务。我们评估了OpenAI的GPT模型、Google内部密集Transformer架构和大平台上的开关式稀疏Transformer的行为,模型大小跨越数百万到数千亿个参数。此外,一组人类专家评分员完成了所有任务,以提供一个强大的基线。研究结果包括:模型性能和校准都随规模的增加而改善,但在绝对值方面较差(与评分员性能相比);模型类的性能非常相似,尽管稀疏性带来了好处;逐渐提高和可预测的任务通常涉及大量的知识或记忆成分,而在关键尺度上表现出“突破”行为的任务通常涉及多个步骤或组件,或脆弱的指标;在背景不明确的环境中,社会偏见通常会随着规模的增加而增加,但这可以通过prompt得到改善。


论文:Dual-Distribution Discrepancy for Anomaly Detection in Chest X-Rays
论文标题:Dual-Distribution Discrepancy for Anomaly Detection in Chest X-Rays
论文时间:8 Jun 2022
所属领域:Methodology
对应任务:Anomaly Detection,异常检测
论文地址:https://arxiv.org/abs/2206.03935
代码实现:https://github.com/caiyu6666/ddad
论文作者:Yu Cai, Hao Chen, Xin Yang, Yu Zhou, Kwang-Ting Cheng
论文简介:During training, module A takes both known normal and unlabeled images as inputs, capturing anomalous features from unlabeled images in some way, while module B models the distribution of only known normal images. / 在训练期间,模块 A 将已知正常和未标记图像作为输入,以某种方式从未标记图像中捕获异常特征,而模块 B 仅对已知正常图像的分布进行建模。
论文摘要:Chest X-ray (CXR) is the most typical radiological exam for diagnosis of various diseases. Due to the expensive and time-consuming annotations, detecting anomalies in CXRs in an unsupervised fashion is very promising. However, almost all of the existing methods consider anomaly detection as a One-Class Classification (OCC) problem. They model the distribution of only known normal images during training and identify the samples not conforming to normal profile as anomalies in the testing phase. A large number of unlabeled images containing anomalies are thus ignored in the training phase, although they are easy to obtain in clinical practice. In this paper, we propose a novel strategy, Dual-distribution Discrepancy for Anomaly Detection (DDAD), utilizing both known normal images and unlabeled images. The proposed method consists of two modules, denoted as A and B. During training, module A takes both known normal and unlabeled images as inputs, capturing anomalous features from unlabeled images in some way, while module B models the distribution of only known normal images. Subsequently, the inter-discrepancy between modules A and B, and intra-discrepancy inside module B are designed as anomaly scores to indicate anomalies. Experiments on three CXR datasets demonstrate that the proposed DDAD achieves consistent, significant gains and outperforms state-of-the-art methods. Code is available at https://github.com/caiyu6666/DDAD
胸部 X 线(CXR)是诊断各种疾病的最典型的放射检查。由于注释昂贵且耗时,以无监督的方式检测 CXR 中的异常是非常有前途的。然而,几乎所有现有的方法都将异常检测视为一类分类(OCC)问题。他们在训练期间仅对已知正常图像的分布进行建模,并在测试阶段将不符合正常轮廓的样本识别为异常。因此,在训练阶段会忽略大量包含异常的未标记图像,尽管它们在临床实践中很容易获得。在本文中,我们提出了一种新颖的策略,即异常检测的双分布差异 (DDAD),同时利用已知的正常图像和未标记的图像。所提出的方法由两个模块组成,分别表示为 A 和 B。在训练期间,模块 A 将已知的正常和未标记图像作为输入,以某种方式从未标记图像中捕获异常特征,而模块 B 仅对已知正常图像的分布进行建模.随后,将模块 A 和 B 之间的相互差异以及模块 B 内部的内部差异设计为异常分数以指示异常。对三个 CXR 数据集的实验表明,所提出的 DDAD 实现了一致、显着的收益,并且优于最先进的方法。代码在https://github.com/caiyu6666/DDAD


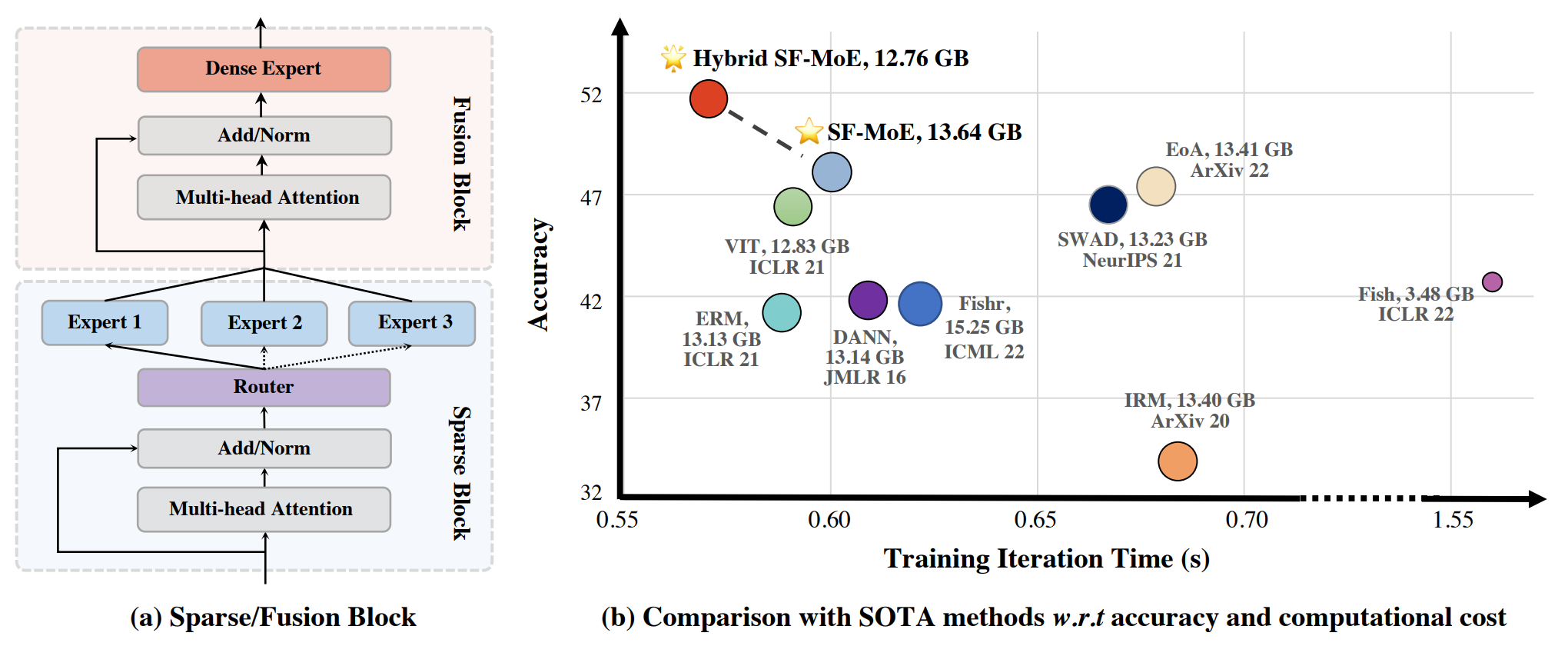
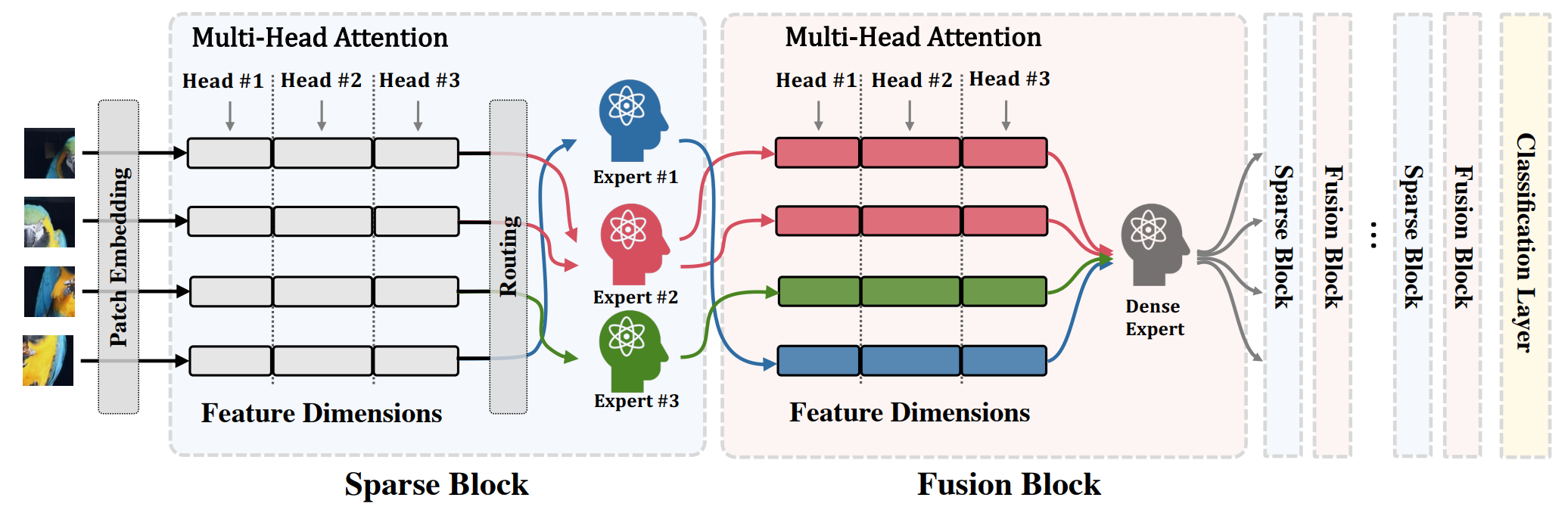
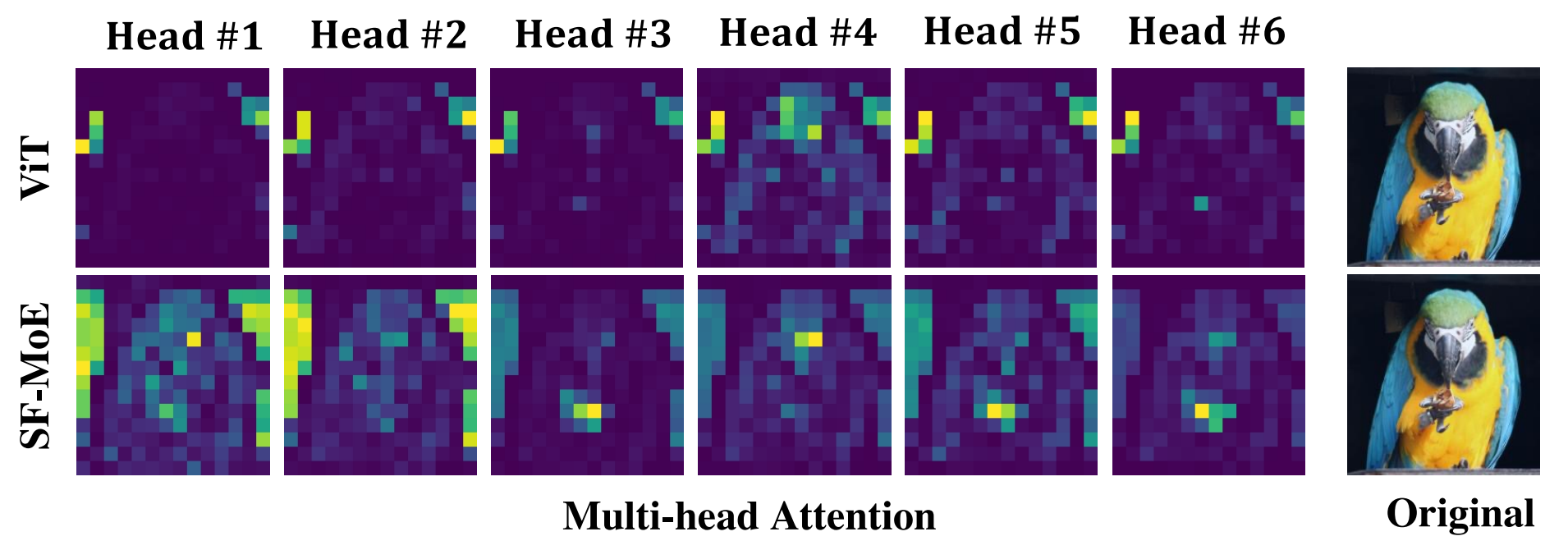
论文:Sparse Fusion Mixture-of-Experts are Domain Generalizable Learners**
论文标题:Sparse Fusion Mixture-of-Experts are Domain Generalizable Learners
论文时间:8 Jun 2022
所属领域:计算机视觉
对应任务:Domain Generalization,Object Recognition,领域泛化,物体识别
论文地址:https://arxiv.org/abs/2206.04046
代码实现:https://github.com/luodian/sf-moe-dg
论文作者:Bo Li, Jingkang Yang, Jiawei Ren, Yezhen Wang, Ziwei Liu
论文简介:To this end, we propose Sparse Fusion Mixture-of-Experts (SF-MoE), which incorporates sparsity and fusion mechanisms into the MoE framework to keep the model both sparse and predictive. / 为此,我们提出了 Sparse Fusion Mixture-of-Experts (SF-MoE),它将稀疏性和融合机制结合到 MoE 框架中,以保持模型的稀疏性和预测性。
论文摘要:Domain generalization (DG) aims at learning generalizable models under distribution shifts to avoid redundantly overfitting massive training data. Previous works with complex loss design and gradient constraint have not yet led to empirical success on large-scale benchmarks. In this work, we reveal the mixture-of-experts (MoE) model’s generalizability on DG by leveraging to distributively handle multiple aspects of the predictive features across domains. To this end, we propose Sparse Fusion Mixture-of-Experts (SF-MoE), which incorporates sparsity and fusion mechanisms into the MoE framework to keep the model both sparse and predictive. SF-MoE has two dedicated modules: 1) sparse block and 2) fusion block, which disentangle and aggregate the diverse learned signals of an object, respectively. Extensive experiments demonstrate that SF-MoE is a domain-generalizable learner on large-scale benchmarks. It outperforms state-of-the-art counterparts by more than 2% across 5 large-scale DG datasets (e.g., DomainNet), with the same or even lower computational costs. We further reveal the internal mechanism of SF-MoE from distributed representation perspective (e.g., visual attributes). We hope this framework could facilitate future research to push generalizable object recognition to the real world. Code and models are released at https://github.com/Luodian/SF-MoE-DG
域泛化(DG)旨在学习分布变化下的泛化模型,以避免冗余过度拟合大量训练数据。以前具有复杂损失设计和梯度约束的工作尚未在大规模基准上取得经验上的成功。在这项工作中,我们通过利用分布式处理跨域预测特征的多个方面来揭示专家混合 (MoE) 模型在 DG 上的泛化性。为此,我们提出了 Sparse Fusion Mixture-of-Experts (SF-MoE),它将稀疏性和融合机制结合到 MoE 框架中,以保持模型的稀疏性和预测性。 SF-MoE 有两个专用模块:1)稀疏块和 2)融合块,它们分别解开和聚合对象的不同学习信号。大量实验表明,SF-MoE 是大规模基准测试中的域泛化学习器。在 5 个大型 DG 数据集(例如 DomainNet)中,它的性能比最先进的同类产品高出 2% 以上,而计算成本相同甚至更低。我们从分布式表示的角度(例如,视觉属性)进一步揭示了 SF-MoE 的内部机制。我们希望这个框架可以促进未来的研究,将可泛化的对象识别推向现实世界。代码和模型发布在 https://github.com/Luodian/SF-MoE-DG

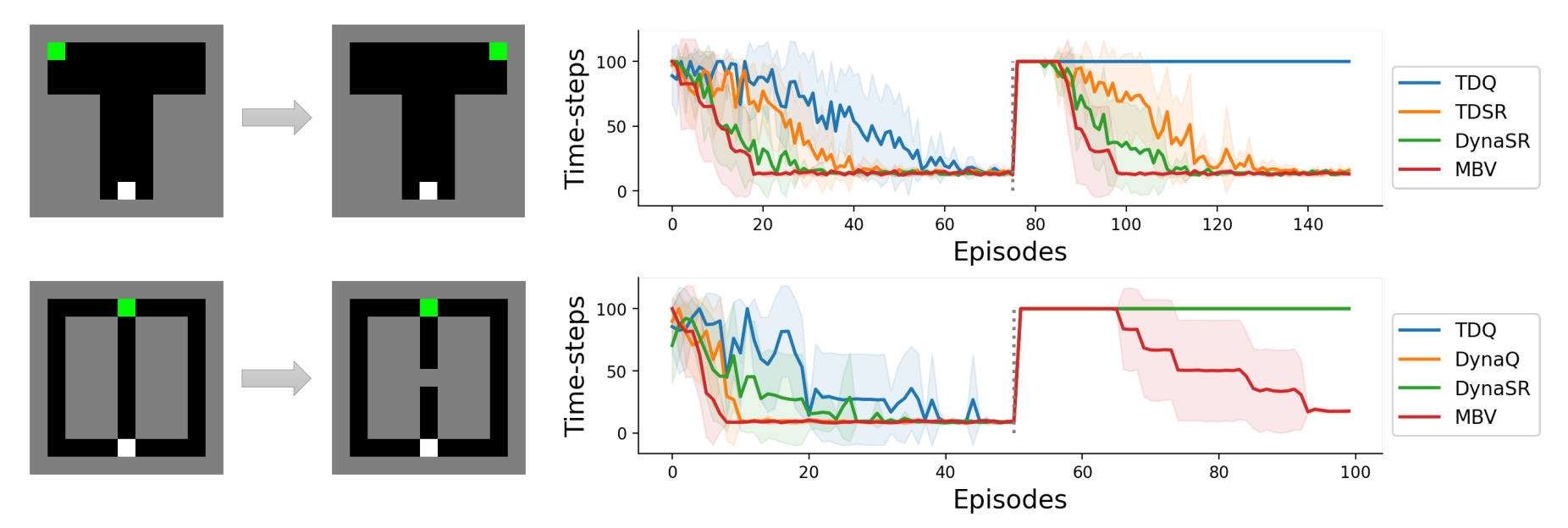
论文:Neuro-Nav: A Library for Neurally-Plausible Reinforcement Learning**
论文标题:Neuro-Nav: A Library for Neurally-Plausible Reinforcement Learning
论文时间:6 Jun 2022
所属领域:强化学习
对应任务:Decision Making,reinforcement-learning,决策,强化学习
论文地址:https://arxiv.org/abs/2206.03312
代码实现:https://github.com/awjuliani/neuro-nav
论文作者:Arthur Juliani, Samuel Barnett, Brandon Davis, Margaret Sereno, Ida Momennejad
论文简介:On the other hand, artificial intelligence researchers often struggle to find benchmarks for neurally and biologically plausible representation and behavior (e. g., in decision making or navigation). / 另一方面,人工智能研究人员通常很难找到神经和生物学上合理的表示和行为的基准(例如,在决策或导航中)。
论文摘要:In this work we propose Neuro-Nav, an open-source library for neurally plausible reinforcement learning (RL). RL is among the most common modeling frameworks for studying decision making, learning, and navigation in biological organisms. In utilizing RL, cognitive scientists often handcraft environments and agents to meet the needs of their particular studies. On the other hand, artificial intelligence researchers often struggle to find benchmarks for neurally and biologically plausible representation and behavior (e.g., in decision making or navigation). In order to streamline this process across both fields with transparency and reproducibility, Neuro-Nav offers a set of standardized environments and RL algorithms drawn from canonical behavioral and neural studies in rodents and humans. We demonstrate that the toolkit replicates relevant findings from a number of studies across both cognitive science and RL literatures. We furthermore describe ways in which the library can be extended with novel algorithms (including deep RL) and environments to address future research needs of the field.
在这项工作中,我们提出了 Neuro-Nav,这是一个用于神经似然强化学习 (RL) 的开源库。 RL 是研究生物有机体中的决策、学习和导航的最常见的建模框架之一。在利用 RL 时,认知科学家经常手工制作环境和代理以满足他们特定研究的需要。另一方面,人工智能研究人员通常很难找到神经和生物学上合理的表示和行为的基准(例如,在决策或导航中)。为了以透明性和可重复性简化这两个领域的过程,Neuro-Nav 提供了一组标准化环境和 RL 算法,这些算法取自啮齿动物和人类的规范行为和神经研究。我们证明该工具包复制了认知科学和 RL 文献中大量研究的相关发现。我们进一步描述了使用新算法(包括深度强化学习)和环境扩展库的方法,以满足该领域未来的研究需求。


论文:AdaSpeech: Adaptive** Text to Speech for Custom Voice
论文标题:AdaSpeech: Adaptive Text to Speech for Custom Voice
论文时间:ICLR 2021
所属领域:语音
对应任务:语音合成,文本转语音
论文地址:https://arxiv.org/abs/2103.00993
代码实现:https://github.com/rishikksh20/AdaSpeech , https://github.com/tuanh123789/AdaSpeech
论文作者:Mingjian Chen, Xu Tan, Bohan Li, Yanqing Li u, Tao Qin, Sheng Zhao, Tie-Yan Liu
论文简介:2) To better trade off the adaptation parameters and voice quality, we introduce conditional layer normalization in the mel-spectrogram decoder of AdaSpeech, and fine-tune this part in addition to speaker embedding for adaptation. / 2)为了更好地权衡自适应参数和语音质量,我们在 AdaSpeech 的 mel-spectrogram 解码器中引入了条件层归一化,并在说话人嵌入的基础上对这部分进行了微调以进行自适应。
论文摘要:Custom voice, a specific text to speech (TTS) service in commercial speech platforms, aims to adapt a source TTS model to synthesize personal voice for a target speaker using few speech data. Custom voice presents two unique challenges for TTS adaptation: 1) to support diverse customers, the adaptation model needs to handle diverse acoustic conditions that could be very different from source speech data, and 2) to support a large number of customers, the adaptation parameters need to be small enough for each target speaker to reduce memory usage while maintaining high voice quality. In this work, we propose AdaSpeech, an adaptive TTS system for high-quality and efficient customization of new voices. We design several techniques in AdaSpeech to address the two challenges in custom voice: 1) To handle different acoustic conditions, we use two acoustic encoders to extract an utterance-level vector and a sequence of phoneme-level vectors from the target speech during training; in inference, we extract the utterance-level vector from a reference speech and use an acoustic predictor to predict the phoneme-level vectors. 2) To better trade off the adaptation parameters and voice quality, we introduce conditional layer normalization in the mel-spectrogram decoder of AdaSpeech, and fine-tune this part in addition to speaker embedding for adaptation. We pre-train the source TTS model on LibriTTS datasets and fine-tune it on VCTK and LJSpeech datasets (with different acoustic conditions from LibriTTS) with few adaptation data, e.g., 20 sentences, about 1 minute speech. Experiment results show that AdaSpeech achieves much better adaptation quality than baseline methods, with only about 5K specific parameters for each speaker, which demonstrates its effectiveness for custom voice. Audio samples are available at https://speechresearch.github.io/adaspeech/
自定义语音是商业语音平台中的一种特定文本到语音(TTS)服务,旨在调整源 TTS 模型以使用少量语音数据为目标说话者合成个人语音。自定义语音对 TTS 自适应提出了两个独特的挑战:1) 支持多样化的客户,自适应模型需要处理可能与源语音数据大不相同的各种声学条件,以及 2) 支持大量客户,自适应参数需要足够小以容纳每个目标扬声器,以减少内存使用量,同时保持高语音质量。在这项工作中,我们提出了 AdaSpeech,这是一种自适应 TTS 系统,用于高质量和高效地定制新语音。我们在 AdaSpeech 中设计了几种技术来解决自定义语音中的两个挑战:1)为了处理不同的声学条件,我们使用两个声学编码器在训练期间从目标语音中提取话语级向量和音素级向量序列;在推理中,我们从参考语音中提取话语级向量,并使用声学预测器来预测音素级向量。 2)为了更好地权衡自适应参数和语音质量,我们在 AdaSpeech 的 mel-spectrogram 解码器中引入了条件层归一化,并在说话人嵌入之外对这部分进行了微调以进行自适应。我们在 LibriTTS 数据集上对源 TTS 模型进行预训练,并在 VCTK 和 LJSpeech 数据集(与 LibriTTS 的声学条件不同)上对其进行微调,适应数据很少,例如 20 个句子,大约 1 分钟的语音。实验结果表明,AdaSpeech 实现了比基线方法更好的适应质量,每个说话者只有大约 5K 个特定参数,这证明了它对自定义语音的有效性。音频样本可在 https://speechresearch.github.io/adaspeech/


论文:Improved Denoising Diffusion Probabilistic Models**
论文标题:Improved Denoising Diffusion Probabilistic Models
论文时间:18 Feb 2021
所属领域:计算机视觉
对应任务:Denoising,Image Generation ,去噪,图像生成
论文地址:https://arxiv.org/abs/2102.09672
代码实现:https://github.com/openai/improved-diffusion , https://github.com/open-mmlab/mmgeneration , https://github.com/luping-liu/PNDM , https://github.com/vvvm23/ddpm
论文作者:Alex Nichol, Prafulla Dhariwal
论文简介:Denoising diffusion probabilistic models (DDPM) are a class of generative models which have recently been shown to produce excellent samples. / 去噪扩散概率模型 (DDPM) 是一类生成模型,最近已被证明可以产生出色的样本。
论文摘要:Denoising diffusion probabilistic models (DDPM) are a class of generative models which have recently been shown to produce excellent samples. We show that with a few simple modifications, DDPMs can also achieve competitive log-likelihoods while maintaining high sample quality. Additionally, we find that learning variances of the reverse diffusion process allows sampling with an order of magnitude fewer forward passes with a negligible difference in sample quality, which is important for the practical deployment of these models. We additionally use precision and recall to compare how well DDPMs and GANs cover the target distribution. Finally, we show that the sample quality and likelihood of these models scale smoothly with model capacity and training compute, making them easily scalable. We release our code at https://github.com/openai/improved-diffusion
去噪扩散概率模型(DDPM)是一类生成模型,最近已被证明可以产生出色的样本。我们表明,通过一些简单的修改,DDPM 还可以在保持高样本质量的同时实现有竞争力的对数似然。此外,我们发现反向扩散过程的学习方差允许以更少数量级的正向采样进行采样,而样本质量的差异可以忽略不计,这对于这些模型的实际部署很重要。我们还使用精度和召回率来比较 DDPM 和 GAN 覆盖目标分布的程度。最后,我们展示了这些模型的样本质量和可能性随着模型容量和训练计算而平滑扩展,使其易于扩展。我们在 https://github.com/openai/improved-diffusion 发布我们的代码


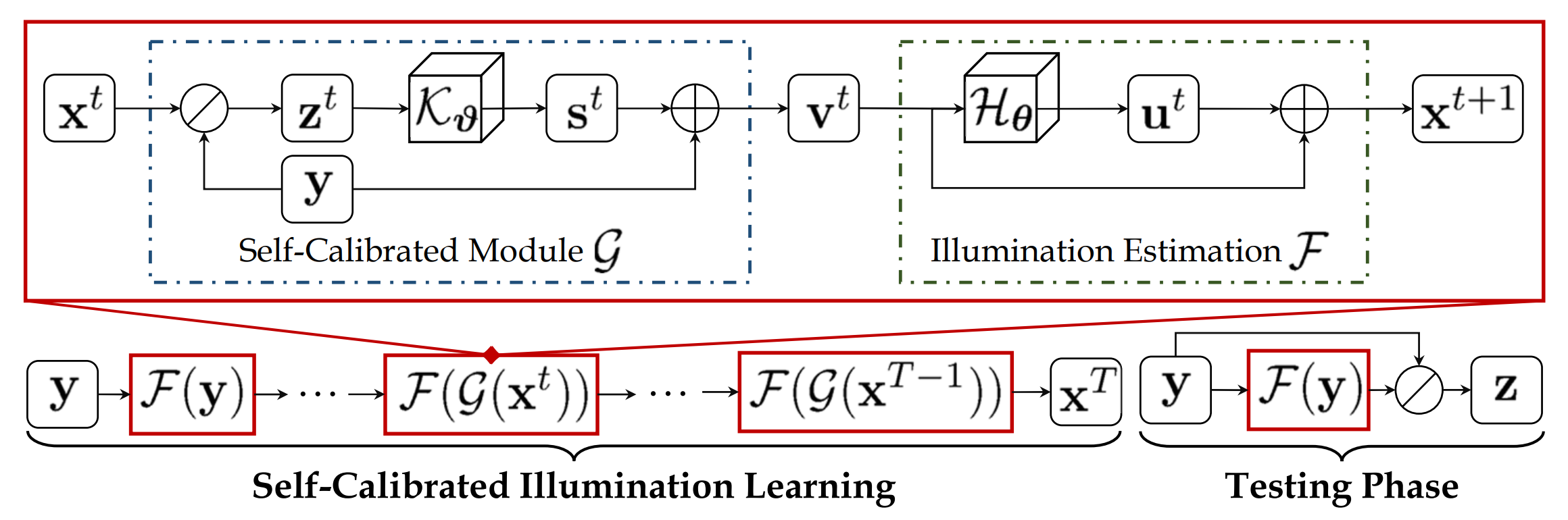
论文:Toward Fast, Flexible, and Robust Low-Light Image Enhancement**
论文标题:Toward Fast, Flexible, and Robust Low-Light Image Enhancement
论文时间:CVPR 2022
所属领域:计算机视觉
对应任务:Face Detection,Image Enhancement,Low-Light Image Enhancement,Semantic Segmentation,人脸检测,图像增强,弱光图像增强,语义分割
论文地址:https://arxiv.org/abs/2204.10137
代码实现:https://github.com/vis-opt-group/sci
论文作者:Long Ma, Tengyu Ma, Risheng Liu, Xin Fan, Zhongxuan Luo
论文简介:Existing low-light image enhancement techniques are mostly not only difficult to deal with both visual quality and computational efficiency but also commonly invalid in unknown complex scenarios. / 现有的弱光图像增强技术大多不仅难以处理视觉质量和计算效率,而且在未知的复杂场景中通常无效。
论文摘要:Existing low-light image enhancement techniques are mostly not only difficult to deal with both visual quality and computational efficiency but also commonly invalid in unknown complex scenarios. In this paper, we develop a new Self-Calibrated Illumination (SCI) learning framework for fast, flexible, and robust brightening images in real-world low-light scenarios. To be specific, we establish a cascaded illumination learning process with weight sharing to handle this task. Considering the computational burden of the cascaded pattern, we construct the self-calibrated module which realizes the convergence between results of each stage, producing the gains that only use the single basic block for inference (yet has not been exploited in previous works), which drastically diminishes computation cost. We then define the unsupervised training loss to elevate the model capability that can adapt to general scenes. Further, we make comprehensive explorations to excavate SCI’s inherent properties (lacking in existing works) including operation-insensitive adaptability (acquiring stable performance under the settings of different simple operations) and model-irrelevant generality (can be applied to illumination-based existing works to improve performance). Finally, plenty of experiments and ablation studies fully indicate our superiority in both quality and efficiency. Applications on low-light face detection and nighttime semantic segmentation fully reveal the latent practical values for SCI. The source code is available at https://github.com/vis-opt-group/SCI
现有的弱光图像增强技术大多不仅难以处理视觉质量和计算效率,而且在未知的复杂场景中通常无效。在本文中,我们开发了一种新的自校准照明 (SCI) 学习框架,用于在现实世界的弱光场景中实现快速、灵活和稳健的增亮图像。具体来说,我们建立了一个具有权重共享的级联光照学习过程来处理这个任务。考虑到级联模式的计算负担,我们构建了自校准模块,该模块实现了每个阶段结果之间的收敛,产生仅使用单个基本块进行推理的增益(在以前的工作中尚未开发),这大大降低了计算成本。然后,我们定义了无监督训练损失,以提升可以适应一般场景的模型能力。此外,我们进行了全面的探索,以挖掘 SCI 的固有属性(现有工作中缺乏的),包括操作不敏感的适应性(在不同的简单操作的设置下获得稳定的性能)和模型无关的通用性(可以应用于基于光照的现有工作以提高性能)。最后,大量的实验和消融研究充分表明了我们在质量和效率方面的优势。微光人脸检测和夜间语义分割的应用充分揭示了 SCI 的潜在实用价值。源代码可在 https://github.com/vis-opt-group/SCI 获得

论文:Point-to-Voxel Knowledge Distillation for LiDAR Semantic Segmentation
论文标题:Point-to-Voxel Knowledge Distillation for LiDAR Semantic Segmentation
论文时间:CVPR 2022
所属领域:计算机视觉
对应任务:3D Semantic Segmentation,Knowledge Distillation,LIDAR Semantic Segmentation,Semantic Segmentation,3D语义分割,知识蒸馏,LIDAR语义分割,语义分割
论文地址:https://arxiv.org/abs/2206.02099
代码实现:https://github.com/cardwing/codes-for-pvkd
论文作者:Yuenan Hou, Xinge Zhu, Yuexin Ma, Chen Change Loy, Yikang Li
论文简介:This article addresses the problem of distilling knowledge from a large teacher model to a slim student network for LiDAR semantic segmentation. / 本文解决了将知识从大型教师模型提取到小型学生网络以进行 LiDAR 语义分割的问题。
论文摘要:This article addresses the problem of distilling knowledge from a large teacher model to a slim student network for LiDAR semantic segmentation. Directly employing previous distillation approaches yields inferior results due to the intrinsic challenges of point cloud, i.e., sparsity, randomness and varying density. To tackle the aforementioned problems, we propose the Point-to-Voxel Knowledge Distillation (PVD), which transfers the hidden knowledge from both point level and voxel level. Specifically, we first leverage both the pointwise and voxelwise output distillation to complement the sparse supervision signals. Then, to better exploit the structural information, we divide the whole point cloud into several supervoxels and design a difficulty-aware sampling strategy to more frequently sample supervoxels containing less-frequent classes and faraway objects. On these supervoxels, we propose inter-point and inter-voxel affinity distillation, where the similarity information between points and voxels can help the student model better capture the structural information of the surrounding environment. We conduct extensive experiments on two popular LiDAR segmentation benchmarks, i.e., nuScenes and SemanticKITTI. On both benchmarks, our PVD consistently outperforms previous distillation approaches by a large margin on three representative backbones, i.e., Cylinder3D, SPVNAS and MinkowskiNet. Notably, on the challenging nuScenes and SemanticKITTI datasets, our method can achieve roughly 75% MACs reduction and 2x speedup on the competitive Cylinder3D model and rank 1st on the SemanticKITTI leaderboard among all published algorithms. Our code is available at https://github.com/cardwing/Codes-for-PVKD
本文解决了将知识从大型教师网络提取到小型学生网络以进行 LiDAR 语义分割的问题。由于点云的内在挑战,即稀疏性、随机性和变化的密度,直接采用以前的蒸馏方法会产生较差的结果。为了解决上述问题,我们提出了点到体素知识蒸馏(PVD),它从点级和体素级转移隐藏的知识。具体来说,我们首先利用逐点和逐像素输出蒸馏来补充稀疏的监督信号。然后,为了更好地利用结构信息,我们将整个点云划分为几个超体素,并设计一种难度感知采样策略,以更频繁地对包含频率较低的类和远处物体的超体素进行采样。在这些超体素上,我们提出了点间和体素间亲和力蒸馏,其中点和体素之间的相似性信息可以帮助学生网络更好地捕捉周围环境的结构信息。我们对两个流行的 LiDAR 分割基准进行了广泛的实验,即 nuScenes 和 SemanticKITTI。在这两个基准上,我们的 PVD 在三个具有代表性的主干网络(即 Cylinder3D、SPVNAS 和 MinkowskiNet)上始终优于以前的蒸馏方法。值得注意的是,在具有挑战性的 nuScenes 和 SemanticKITTI 数据集上,我们的方法可以在竞争性 Cylinder3D 模型上实现降低大约75% 的MACs和 2 倍的加速,并且在所有已发布算法中的 SemanticKITTI 排行榜上排名第一。我们的代码可在 https://github.com/cardwing/Codes-for-PVKD


我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。

- 作者:韩信子@ShowMeAI
- 历史文章列表
- 专题合辑&电子月刊
- 声明:版权所有,转载请联系平台与作者并注明出处 - 欢迎回复,拜托点赞,留言推荐中有价值的文章、工具或建议,我们都会尽快回复哒~