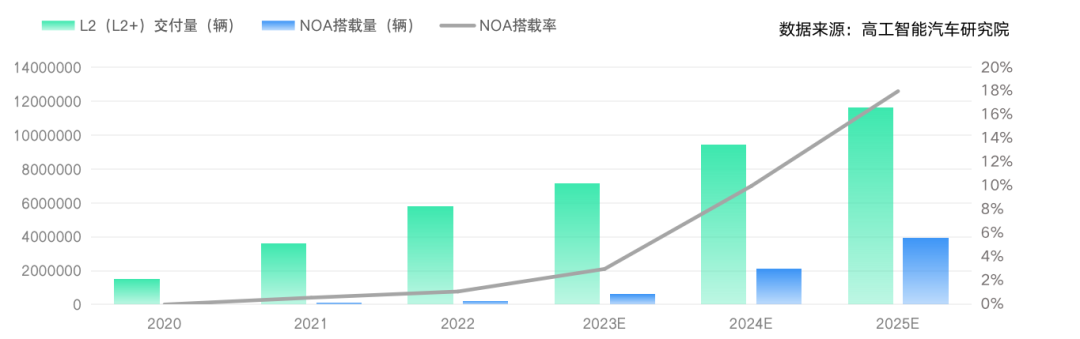
首先明确我指的动态数据是什么。
名词定义:动态数据在这里指的是网页中由Javascript动态生成的页面内容,即网页源文件中没有,在页面加载到浏览器后动态生成的。
下面进入正题。
抓取静态页面很简单,通过Java获取到html源码,然后分析源码即可得到想要的信息。如获取中国天气网中杭州的天气,只需要找到对应的html页面( http://www.weather.com.cn/weather/101210101.shtml)。
假设我需要输入城市名称获取改城市的天气,数据源还是采用中国天气网。首先要做的是根据城市找到对应的页面。通过简单分析发现,城市与页面的URL有对应,如杭州对应101210101,所以程序的关键就是找到城市与页面的对应关系。
发现该网站的搜索框有中国大多数城市的链接,可以得到城市与_id的对应关系。找到突破口,开始行动。进入首页,查看其源代码,找到搜索框所在位置。
原来数据是通过Javascript动态加进去的,用Chrome的inspect element看到以下内容。

目前可以做的是利用Chrome将html复制到文件,然后解析该文件得到城市与URL的关系。问题是万一网站的城市与URL对应关系有变化,这就很被动还需改程序.