一、前言
单位同事每人都办理了一个192新手机号,一打过来不知道是谁,又懒的一个个保存姓名。一想是不是可以批量导入呢?电子表格号码名单我有啊,试试吧。
二、实践
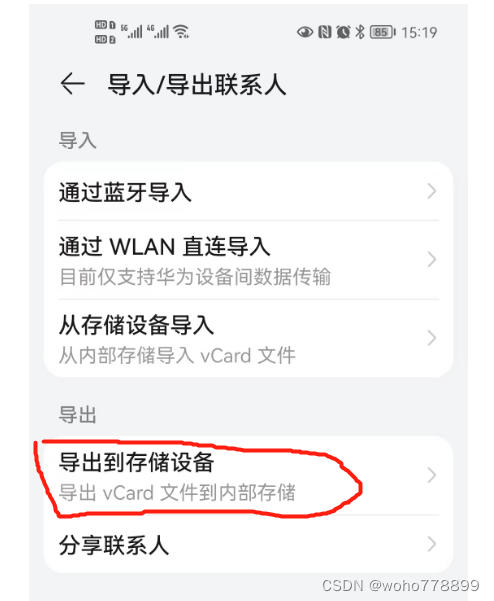
1.先下载手机联系人文件看看吧。在手机联系人设置中有个导出选项(华为手机为例):
导出文件为00001.vcf,用文本编辑强行打开,是一个个卡片:

2.下载VCF编辑软件试试。
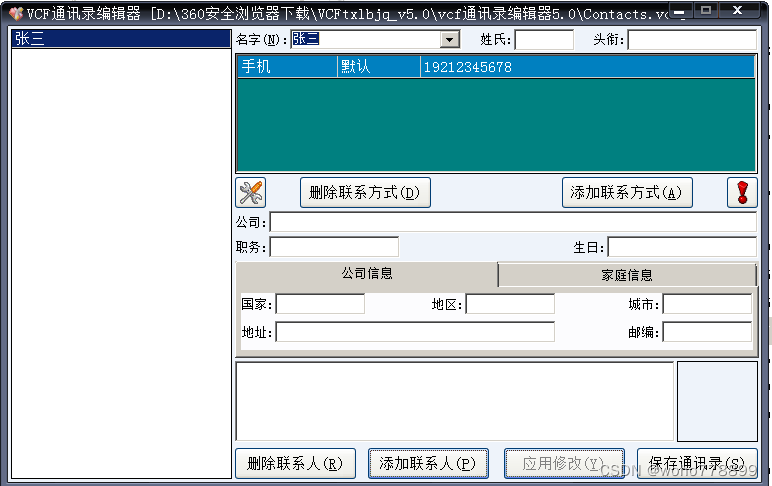
这一款(A款),居然打不开vcf文件,不咋地。
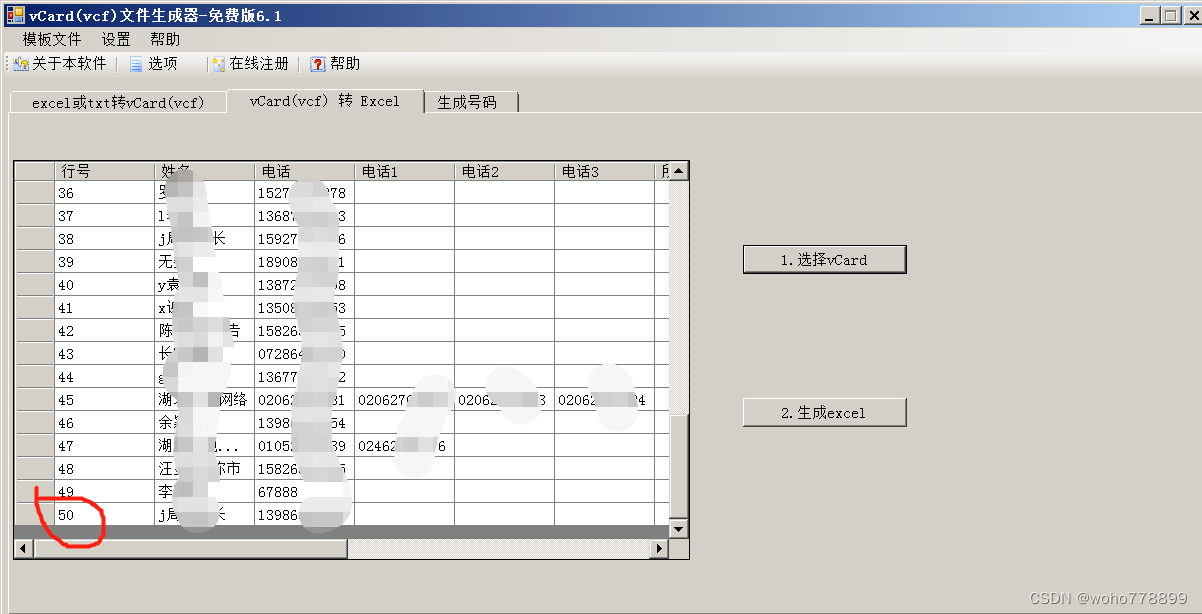
这一款(B款),可以读出vcf文件,只能读50个,要注册收费,麻烦;电子表格转成vcf文件后,不能正常导入手机(没有ENCODING=QUOTED-PRINTABLE转换,3.0版),不咋地。
3.折腾
问题还没解决啊(同时,还整了另外一款转换的也没弄成),在A款(名字叫VCF通讯录编辑器)手动输入2个姓名电话试试,将那个contacts.vcf文件导入手机,可以。
也就是说,只要把电子表格文件导入就解决问题了,出了意外:
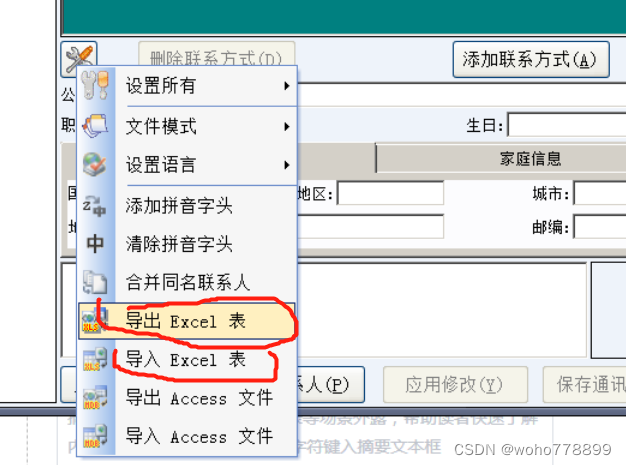
导入、导出都无法完成,什么鬼气,Excel版本问题?不管了,导出Access文件试试,可以。
Access文件类型mdb,数据库文件,启动Access2007,打开联系人那张表,把电子表格里的姓名、电话号码复制粘贴到对应字段后保存(在Access里面,通过导入xls重新生存一张新表,在VCF通讯录编辑器导入时也会出错,NND没时间研究)。
返回VCF通讯录编辑器,再通过导入Access文件,可以了,保存通讯录。
contacts.vcf文件通过微信传手机,选择联系人打开文件,点击导入VCF文件,成功。
三、思考
VCF格式文件,文本可见,应该是很单纯的,怎么这么难搞。

这个UID要不要不影响。

这几项(单位地址、家庭地址、公司等)也不重要。

这个图片项,太大了,最好是不要。
这里面,除了电话号码外,最重要的一句就是这句了:N;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:;=E9=83=90=AF=E6=38;
quoted-printable编码
可译为“可打印字符引用编码”,在Python里操作认识一下:
>>> import quopri
>>> s='你好'
>>> type(s)
<class 'str'>
>>> b=s.encode()
>>> type(b)
<class 'bytes'>
>>> qe=quopri.encodestring(b)
>>> type(qe)
<class 'bytes'>
>>> qe
b'=E4=BD=A0=E5=A5=BD' #一个汉字转3字节utf8编码,分别用“=”分开
>>> s='hello'
>>> b=s.encode()
>>> qe=quopri.encodestring(b)
>>> qe
b'hello' #ASC字符字母无变化
>>> s=' ' #Tab键
>>> b=s.encode()
>>> qe=quopri.encodestring(b)
>>> qe
b'=09' #Tab键的qp码
>>> s='='
>>> b=s.encode()
>>> qe=quopri.encodestring(b)
>>> qe
b'=3D' #等号的qp码
>>> s=' '#空格
>>> b=s.encode()
>>> qe=quopri.encodestring(b)
>>> qe #空格的qp码
b'=20'
>>> s='`~!@#$%^&*()+'#其他字符
>>> b=s.encode()
>>> qe=quopri.encodestring(b)
>>> qe
b'`~!@#$%^&*()+' #其他字符的qp码无变化
>>> s='你好hello我很好=好=GOOD'
>>> b=s.encode()
>>> qe=quopri.encodestring(b)
>>> qe
b'=E4=BD=A0=E5=A5=BDhello=E6=88=91=E5=BE=88=E5=A5=BD=3D=E5=A5=BD=3DGOOD'
>>> #混合字符样式qp码字符的编码类型除了utf-8,还有(一)GB系列:
>> b=s.encode('gb2312') >>> b
b'\xc4\xe3\xba\xc3'
>>> b=s.encode('gbk') >>> b #cp936好象跟GBK差不多
b'\xc4\xe3\xba\xc3'
>>> b=s.encode('gb18030') >>> b
b'\xc4\xe3\xba\xc3'
相关补充(来自网络):
GB2312(1980年)一共收录了7445个字符,汉字区的内码范围高字节从B0-F7,低字节从A1-FE。
1995年的汉字扩展规范GBK1.0收录了21886个符号。
2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平 台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
从ASCII、 GB2312、GBK到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码 中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。
(二)U系列:
>>> s='你好'
>>> b=s.encode('unicode_escape')
>>> b
b'\\u4f60\\u597d'
>>>len(b)
12 #一个汉字6字节
>>> b[0]
92 #返回“\”的ascii值
>>> b[1]
117 #返回“u”的ascii值,后面类似
>>> bin(b[1])
'0b1110101' #字符u的ascii
>>> b[1].bit_length()
7 #二进制长度7
>>> type(b[1])
<class 'int'> #python数据类型:整数型
>>> b[1].to_bytes(1,"big")
b'u' #返回ascii代码
相关补充(来自网络):
Unicode 也是一种字符编码方法,不过它是由国际组织设计,可以容纳全世界所有语言文字的编码方案。Unicode的学名是"Universal Multiple-Octet Coded Character Set",简称为UCS。而Unicode只与ASCII兼容,与GB码不兼容。例如“你”字的Unicode编码是4f60,而GB码是c4e3。
UCS有两种格式:UCS-2和UCS-4。顾名思义,UCS-2就是用两个字节编码,UCS-4就是用4个字节(实际上只用了31位,最高位必须为0)编码。UCS-2有2^16=65536个码位,UCS-4有2^31=2147483648个码位。
怎样传输这些编码,是由UTF(UCS Transformation Format)规范规定的,常见的UTF规范包括UTF-8、UTF-7、UTF-16、UTF-32。
>>> b=s.encode('utf8') #默认,可省:b=s.encode()
>>> b
b'\xe4\xbd\xa0\xe5\xa5\xbd' #utf8编码:一个汉字3字节,每字节长度为8
>>> b[0]
228
>>> b[0].bit_length()
8
>>> bin(b[0])
'0b11100100'
>>> b[0].to_bytes(1,'big')
b'\xe4'
b=s.encode('utf-16') >>> b #utf16编码:一个汉字4字节,两个6,三个8
b'\xff\xfe`O}Y'
>>> b=s.encode('utf-32') >>> b #utf32编码:一个汉字8字节,两个12,三个16
b'\xff\xfe\x00\x00`O\x00\x00}Y\x00\x00'
>>> b=s.encode('utf7') >>> b
b'+T2BZfQ-' #utf7编码:一个汉字5字节,两个8,三个10,四个13,,332递增型
(三)其他:
>>> s='你好'
>>> b=s.encode('big5')
>>> len(b)
4
>>> b
b'\xa7A\xa6n' #BIG5编码:一个汉字2字节,长:前8后7
>>> b[0].bit_length()
8
>>> b[1].bit_length()
7
相关补充(来自网络):
UTF-8编码字节含义
- 对于UTF-8编码中的任意字节B,如果B的第一位为0,则B独立的表示一个字符(ASCII码);
- 如果B的第一位为1,第二位为0,则B为一个多字节字符中的一个字节(非ASCII字符);
- 如果B的前两位为1,第三位为0,则B为两个字节表示的字符中的第一个字节;
- 如果B的前三位为1,第四位为0,则B为三个字节表示的字符中的第一个字节;
- 如果B的前四位为1,第五位为0,则B为四个字节表示的字符中的第一个字节;
utf-8汉字编码3字节模板了:1110xxxx 10xxxxxx 10xxxxxx。
例如“汉”字的Unicode编码是6C49。6C49在0800-FFFF之间,将6C49写成二进制是:0110 110001 001001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。三字节编码从“E”开始。
四、代码实现
1.先来个操作界面。就用TKinter。
部分代码如下:
from tkinter import *
from tkinter import filedialog
import os
import openpyxlroot= Tk()
root.title('电子表格转vcf(qq:35386940)')
root.geometry('640x500') # 这里的乘号不是 * ,而是小写英文字母 x
root.resizable(False,False)#固定窗口大小def run_xls2vcf():passreturn #添加按钮
btn21 = Button(root, text='xlsx → vcf', command=run_xls2vcf)#添加按钮
btn21.place(relx=0.7, rely=0.05, relwidth=0.2, relheight=0.1)#放置位子:百分比
#设置文本框
txt=Text(root)#设置文本框
txt.insert('end','Hello!(Ctrl+C复制)')
txt.pack(padx=3,pady=103)#边缘点距root.mainloop()上面这个太LOW了,经过不断完善,最后弄成了下面的样子:
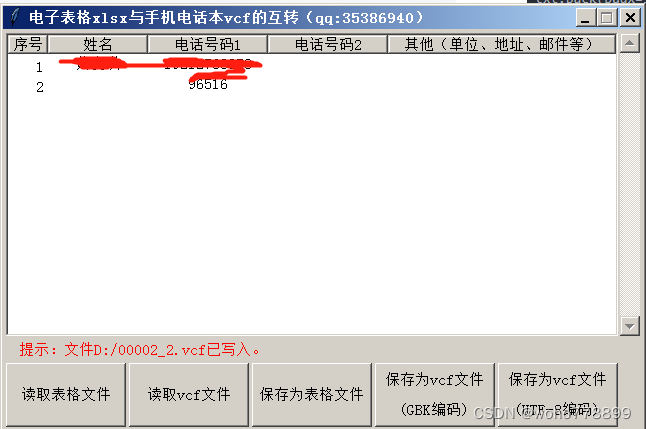
操作界面代码:
#1添加按钮
#按钮1
btn1 = Button(root, text='读取表格文件', command=read_xlsx)#命令指向自定义名
btn1.place(x=3, y=333, width=120, height=64)#放置位子大小;(relx=0.1, rely=0.85, relwidth=0.18, relheight=0.1)#百分比
#按钮2
btn2 = Button(root, text='读取vcf文件', command=read_vcf)#命令指向自定义名
btn2.place(x=126, y=333, width=120, height=64)#放置位子大小;
#按钮3
btn3 = Button(root, text='保存为表格文件', command=write_xlsx)#命令指向自定义名
btn3.place(x=249, y=333, width=120, height=64)#放置位子大小;
#按钮4
btn4 = Button(root, text='保存为vcf文件\n\n(GBK编码)', command=write_vcf_unicode)#命令指向自定义名
btn4.place(x=372, y=333, width=120, height=64)#放置位子大小;
#按钮5
btn4 = Button(root, text='保存为vcf文件\n\n(UTF-8编码)', command=write_vcf_utf8)#命令指向自定义名
btn4.place(x=495, y=333, width=120, height=64)#放置位子大小;#2.1设置一个框架容器
frame = Frame(root)
frame.place(x=3, y=3, width=634, height=303)#放置坐标大小#2.2容器内添加滚动条并绑定
scrollBar=Scrollbar(frame) #框架里设置
#绑定
scrollBar.pack(side=RIGHT, fill=Y)#靠右,y方向填满#2.3容器内添加Treeview组件,列,显示表头(不显示tree结构),带垂直滚动条,然后设置并绑定
tree_date =ttk.Treeview(frame,columns=('no','name','phone1','phone2','address'),show="headings",yscrollcommand=scrollBar.set)
# 设置列宽度
tree_date.column('no',width=40,anchor='se') #右对齐
tree_date.column('name',width=100,anchor='center')#中心对齐
tree_date.column('phone1',width=120,anchor='center')
tree_date.column('phone2',width=120,anchor='center')
tree_date.column('address',width=228)
# 添加列名
tree_date.heading('no',text='序号')
tree_date.heading('name',text='姓名')
tree_date.heading('phone1',text='电话号码1')
tree_date.heading('phone2',text='电话号码2')
tree_date.heading('address',text='地址')
#绑定
tree_date.pack(side=LEFT, fill=Y)#2.4滚动条与树型数据捆绑
scrollBar.config(command=tree_date.yview)
#tree_date.clipboard_clear()
#2.5添加数据
# for i in range(1,30):
# tree_date.insert('',i,text=i,values=(i,'熊大好','13412345678','22222345678','湖北荆州沙市九龙湾')) #增加一个红色状态文字标签
lbl=Label(root,textvariable=strs,foreground='red')
lbl.place(x=13,y=309)root.mainloop()
2.读取xlsx文件
电子表格读取,分两种格式,xls和xlsx,本例只读xlsx。
def read_xlsx():tree_date.delete(*tree_date.get_children())#清空前一次读数filename = filedialog.askopenfile(title=u'选择xlsx文件',initialdir=(os.path.expanduser('d:/')))#打开文件对话框if filename:#print(filename.name)if filename.name.split('.')[-1].lower() not in ['xlsx']:#txt.insert('end','\n\n'+filename.name+u'不是表格文件!')print('非电子表格文件。')strs.set('*提示:'+filename.name+'不是xlsx文件!')returnxlsx=openpyxl.load_workbook(filename.name) #读取表格文件sheet1=xlsx.worksheets[0] #读取第一个表n=sheet1.max_row #最大行m=sheet1.max_column #最大列#print('读到表格文件',filename.name,n,':行;',m,'列')strs.set('*提示:读到表格文件'+filename.name+',有'+str(n)+'行;'+str(m)+'列')global fold,lst #传递全局参数fold=filename.namelst=[]#全局数据one=[]#临时数据for i in range(1,n+1):#取出表格数据,显示并加入列表for j in range(1,m+1):if sheet1.cell(i,j).value is not None :one.append(sheet1.cell(i,j).value)else:one.append('')if i==1 and len(one)>3:#如果是第一行,判断电话号码有没5位数字,没有则当作标题n_sum=0for k in one[2]:if k>='0' and k<='9':n_sum=n_sum+1if n_sum<=5:one.clear()else:lst.append(one.copy())tree_date.insert('',n,text='',values=one) #显示到列表one.clear()return lst,fold为了读取更准确高效,提示固定了表格分栏:1序号,2姓名,3和4电话号码,5地址。标题栏进行了简单判断,设置了2个全局变量,文件名、读取到的内容。
3.读取VCF文件
def read_vcf():tree_date.delete(*tree_date.get_children())#清空前一次读数filename = filedialog.askopenfile(title=u'选择vcf文件',initialdir=(os.path.expanduser('d:/')))#打开文件对话框#print(filename.name)global fold,lstfold=filename.namef_r=open(filename.name,'rb')#读取二进制文件f_io=BytesIO()#内存文件缓存quopri.decode(f_r,f_io)#直接解码文件到内存f_io.seek(0,0) #这个很重要,指针归零,否则只能getvalue,不能readline,文件操作也一样,读一遍后指针在文末,第二次操作要归零lines=f_io.readlines()#读取所有的行print('读到vcf文件',filename.name,len(lines),'行')lst=[]#lst.clear()#实际是个二维表one=[]n=0for i in lines:#print(i)if b'BEGIN:' in i:#判断是否为开始标识,是则添加行号n=n+1one.append(n)#print(one)continue #忽视下面的语句,直接下一行if b'N;CHAR'==i[:6]:st=i.decode().split(':')[1][:-2].replace(';','')if len(st)!=0:#是否有姓氏,有则添加姓one.append(st)else:one.append('')#没有添加空字符continueif b'FN;CHA'==i[:6]:st=i.decode().split(':')[1][:-2]#print(st,one)if st!=one[1]: #姓和名是否相同,不同则合在一起one[1]=one[1]+stcontinueif b'TEL'==i[:3]:st=i.decode().split(':')[1][:-2].replace(' ','')#取出电话号码,消除空格one.append(st)continueif b'ADR'==i[:3]:#取出地址信息,放在第4列位子st=i.decode().split(':')[1][:-2].replace(';','')if len(one)==4:one.append(st)else:one.append('')one.append(st)continueif b'END:VC'==i[:6]:lst.append(one.copy())#需要拷贝进去,否则one清除时,lst数据也清除了#print(one,'加入列表',len(lst)) tree_date.insert('',n,text='',values=one) #显示到列表one.clear()#print(one,'加入列表',lst[0],len(lst))print(len(lst),'条记录生存。')strs.set('提示:读到vcf文件'+filename.name+',有'+str(len(lines))+'行,'+str(len(lst))+'条记录。')return fold,lst
以字节方式读取vcf文件,直接用quopri.decode(f_r,f_o)解码转成内存文件,再读取所有的行,最后进行“行识别”,整理成列表返回。
4.保存为xlsx文件
def write_xlsx():# 创建一个Workbook对象#print(fold,'??',len(lst),lst[0])fn=fold.split('.')[0]+'_1.xlsx'#print(fn)wb = openpyxl.Workbook()#创建工作本对象(类)sh=wb.create_sheet(index=0, title="电话本")#指定为第一个sh['A1']='序号'sh['B1']='姓名'sh['C1']='电话号码1'sh['D1']='电话号码2'sh['E1']='地址'for i in lst:sh.append(i)#print(i)wb.save(fn)#保存文件strs.set('提示:文件'+fn+'已写入。')os.startfile(fn) #默认打开return
写入xlsx文件,位子在打开文件同目录,并默认打开。
5.保存为vcf文件
def write_vcf_gbk():fn=fold.split('.')[0]+'_1.vcf'n=len(lst)print(fn,',长度:',n)b=b''# b'BEGIN:VCARD\r\n', b'VERSION:2.1\r\n', # b'N;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:;\xe5\xbc\xa0;;;\r\n', # b'FN;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:\xe5\xbc\xa0\r\n', # b'TEL;CELL:136 2717 7377\r\n', # ADR;HOME;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:;;=E6=B7=B1;;;;# b'END:VCARD\r\n'for i in lst:m=len(i)b=b+b'BEGIN:VCARD\r\nVERSION:2.1\r\n'if m>1 and i[1]:name_qp=quopri.encodestring(i[1].encode())b=b+b'N;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:;'+name_qp+b';;;\r\n'b=b+b'FN;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:'+name_qp+b'\r\n'if m>2 and i[2] :no_qp='TEL;CELL:'+(str(i[2]))+'\r\n'b=b+no_qp.encode()if m>3 and i[3]:no_qp='TEL;CELL:'+(str(i[3]))+'\r\n'b=b+no_qp.encode()if m>4 and i[4]:adr_qp=quopri.encodestring(i[4].encode())b=b+b'ADR;HOME;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:;;'+adr_qp+b';;;;\r\n'b=b+b'END:VCARD\r\n'fs=open(fn,'w',encoding='gbk')#默认是UTF8,转成unicode,不然低于50条记录,华为手机不认fs.write(b.decode())#字节先还原成Utf8字符,再转Uni后写入文件strs.set('提示:文件'+fn+'已写入。')print('已写入文件:',fn)returndef write_vcf_utf8():fn=fold.split('.')[0]+'_2.vcf'n=len(lst)print(fn,',长度:',n)b=b''for i in lst:m=len(i)b=b+b'BEGIN:VCARD\r\nVERSION:2.1\r\n'if m>1 and i[1]:name_qp=quopri.encodestring(i[1].encode())b=b+b'N;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:;'+name_qp+b';;;\r\n'b=b+b'FN;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:'+name_qp+b'\r\n'if m>2 and i[2] :no_qp='TEL;CELL:'+(str(i[2]))+'\r\n'b=b+no_qp.encode()if m>3 and i[3]:no_qp='TEL;CELL:'+(str(i[3]))+'\r\n'b=b+no_qp.encode()if m>4 and i[4]:adr_qp=quopri.encodestring(i[4].encode())b=b+b'ADR;HOME;CHARSET=UTF-8;ENCODING=QUOTED-PRINTABLE:;;'+adr_qp+b';;;;\r\n'b=b+b'END:VCARD\r\n'fs=open(fn,'wb')#默认是UTF8,二进制直接写fs.write(b)#print('已写入文件:',fn)strs.set('提示:文件'+fn+'已写入。')return
考虑到可能存在不同手机的要求,打包文件时采取了2种编码格式:gbk和uft8,姓名地址分别用quopri.encodestring(str_s.encode())进行了转换。
实测
如出现: ,有可能已经导入成功,如没有导入,换一种编码试试。
,有可能已经导入成功,如没有导入,换一种编码试试。
有了这个工具,可以把手机电话本全部导出,转成电子表格整理一下,然后再导回手机。