词频统计
在很多情况下我们会遇到这样的问题·,给你一篇文章,让你统计其中多次出现的词语。这就是词频统计问题。当然不我们的文本可以是英文、可以是中文、也可以是其他国家的文字。首先我们来分析这个问题的IPO:
I(输入):从文件读取一段文本,或者从键盘输入文本,通常情况下是从文件中读取
P(处理过程):把每个词语及其出现次数当作一个键值对进行处理
O(输出):输出每个词及其出场频率。
英文文章的词频统计
首先我们来看文本为英文的情况:
统计一段英文文本中,单词出现次数,并输出出场次数前三的单词。
I(输入):从文件中读取一篇文章,考虑到有的单词出现在句首需为大写,事实上大写和小写应为一个单词,但是统计的时候会把大写和小写分开,因此把所有大写转化为小写。然后一段文本里面会出现各种各样的符号,这些符号会影响单词频率的排名,因此要把这些符号去掉,这里可以采用字符串的replace方法把其他符号替换为空格符。然后就是我们的单词每出现一次次数就要加1。清楚了这些以后我们整体的编程思路就有了:下面就是我们的代码展示环节
#读取文件
test=open("D:\pythonDemo\EnglishDemo.txt",'r')
#将文件内容全部变为小写存储在test中
test=(test.read()).lower()
#利用循环将其他字符替换为空格
for str in'.,%()-"—':test=test.replace(str," ")
#将单词以空格分隔开形成列表
words=test.split()
#创建一个空的字典counts
counts={}
for word in words:#将列表中的元素当作键,出现次数当作值,每出现一次值+1,第一次出现时值为0+1counts[word]=counts.get(word,0)+1
#将所有键值对提取出来并转化为列表类型
items=list(counts.items())
#列表类型的sort方法进行排序
items.sort(key=lambda x:x[1],reverse=True)
for i in range (3):word,count=items[i]print("{0:<10}{1:>5}".format(word,count))
#注意,第20行的key系数可以写成:
'''
def f(x):return x[1]
#这里的x[1]表示使用列表的第二个元素来排序,我们的键值对中值(第二个元素)才是出场次数
'''结果为:
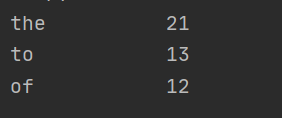
由此我们得到了一个结论:
一篇文章中,冠词和介词出现的次数挺多的,就和我们写文章一定会出现而且出现次数较多的土也地和白勺的一样。[手动滑稽]
其中比较难懂的地方我做了注释大家可以康康,相信聪明的你们一定可以拿下的,积极开动你们的小脑袋瓜。
英语文本的话我当时用的是今年的高考英语一卷D篇阅读,文本文件我本来想导入的,但是导入完直接就自动生成新的一篇了,那我就把链接附上吧,大家可以当个例子练练手⸜(๑⃙⃘’ᵕ’๑⃙⃘)⸝⋆︎*。
中文文章的词频统计
说完了英语文章如何做词频统计下面我们来说一下中文文章的词频统计。
中文文章的词频统计和英文文章的统计代码大差不差,就是需要我们从中引入一个jieba库,如果需要可以使用结巴库的add_word()方法手动添加新词。
话不多说上代码让大家感受一下:
import jieba
def p(x):return x[1]
#打开文件并读取
test=open("D:\pythonDemo\YuwenDemo.txt",'r',encoding='UTF-8').read()
#用jieba库的lcut对文章进行精准分词,并得到一个列表类型
words=jieba.lcut(test)
#创建空字典
counts={}
for word in words:#若字符长度为1则不可能组成词语且可能会为标点符号,因此排除他们if len(word)==1:continue# 把分出的词当作键,出现次数为值,初次出现时为0+1,随后每出现一次次数+1else:counts[word]=counts.get(word,0)+1
#将counts中的所有键值对取出并制成列表类型
items=list(counts.items())
#将列表中元素排序
items.sort(key=p,reverse=True)
print("出现次数前十的词语为:")
for i in range(10):word,count=items[i]print("{0:<10}{1:>5}".format(word,count))
第一次敲代码的时候没有考虑单个字符的情况,因为我觉得中文分词库不会吧标点也算作一个字符,于是我就没有在第一个for循环中添加if else排除单个字符,得到的结果为:
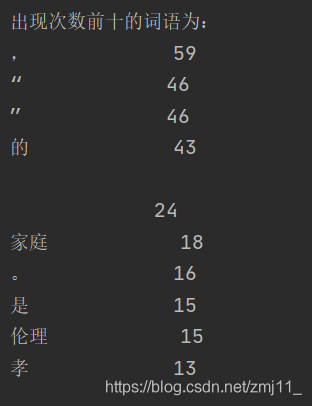
我当时人都傻了我,涨姿势了,分词库原来还会把符号也作为一个词语分出来,那就老老实实排除单个字符吧,于是我就添加上了if-else结构去除单字符,得到的结果如下:

这结果不就很奈斯吗。
好了,聪明的你学废了吗
下面我把用到的两篇文章附在下面啦,大家自取吧ฅ(๑ ̀ㅅ ́๑)ฅ
我是例子,快点我