AugGPT:利用 ChatGPT 进行文本数据增强
- 摘要
- 1 介绍
- 2 相关工作
- 2.1 数据增强
- 2.2 小样本学习
- 2.3 超大型语言模型
- 2.4 ChatGPT:现在与未来
- 3 数据集
- 3.1 亚马逊数据集
- 3.2 症状数据集
- 3.3 PubMed20k数据集
- 4 方法
- 4.2 使用 ChatGPT 进行数据增强
- 4.3 小样本文本分类
- 4.4 Baseline Methods
- 4.5 Prompt Design
- 4.6 评估指标
- 4.6.1 Embedding Similarity
- 4.6.2 TransRate
- 4.7 ChatGPT 的直接分类性能
- 5 EXPERIMENT RESULTS
- 5.1 分类性能比较
- 5.2 增强数据集的评估
- 5.3 与 ChatGPT 的性能比较
- 结论
摘要
文本数据增强是克服许多自然语言处理(NLP)任务中样本量有限的挑战的有效策略。这一挑战在小样本学习场景中尤为突出,其中目标域中的数据通常更加稀缺且质量较低。缓解此类挑战的一种自然且广泛使用的策略是执行数据增强,以更好地捕获数据不变性并增加样本量。
然而,当前的文本数据增强方法要么无法确保生成的数据的正确标记(缺乏忠实性),要么无法确保生成的数据足够的多样性(缺乏紧凑性),或者两者兼而有之。受到大型语言模型最近成功的启发,特别是 ChatGPT 的发展,它证明了语言理解能力的提高,在这项工作中,我们提出了一种基于 ChatGPT 的文本数据增强方法(称为 AugGPT)。 AugGPT 将训练样本中的每个句子重新表述为多个概念相似但语义不同的样本。然后,增强的样本可以用于下游模型训练。少样本学习文本分类任务的实验结果表明,在测试准确性和增强样本的分布方面,所提出的 AugGPT 方法比最先进的文本数据增强方法具有优越的性能。
1 介绍
自然语言处理 (NLP) 的有效性在很大程度上依赖于训练数据的质量和数量。由于隐私问题或注释成本,可用的训练数据有限,这是实践中的一个常见问题,因此训练一个准确的 NLP 模型以很好地推广到未见过的样本可能具有挑战性。
训练数据不足的挑战在少样本学习(FSL) 场景中尤为突出,在原始(源)域数据上训练的模型预计只能从新(目标)域中的几个示例进行泛化 [1] 。许多 FSL 方法在克服各种任务中的这一挑战方面显示出了有希望的结果。现有的FSL方法主要侧重于通过更好的架构设计[2]、[3]来提高模型的学习和泛化能力,利用预训练的语言模型作为基础,然后使用有限的样本[4]和元进行微调-学习[2]、[5]或基于提示的方法[6]、[7]、[8]、[9]。然而,这些方法的性能本质上仍然受到源域和目标域中数据质量和数量的限制。
除了模型开发之外,文本数据增强还可以克服样本量限制并与 NLP 中的其他 FSL 方法一起使用[10]、[11]。数据增强通常与模型无关,并且不涉及底层模型架构的更改,这使得这种方法特别实用并适用于广泛的任务。在 NLP 中,有多种类型的数据增强方法。传统的文本级数据增强方法依赖于对现有样本库的直接操作。一些常用的技术包括同义词替换、随机删除和随机插入[12]。 最近的方法利用语言模型来生成可靠的样本,以实现更有效的数据增强,包括反向翻译[13]和潜在空间中的词向量插值[14]。然而,现有的数据增强方法在生成文本数据的准确性和多样性方面受到限制,并且在许多应用场景中仍然需要人工注释[12]、[15]、[16]。
GPT 系列 [6]、[17] 等(非常)大型语言模型 (LLM) 的出现为生成类似于人类标记数据 [18] 的文本样本带来了新的机会,这显着减轻了人类注释者的负担[19]。法学硕士以自我监督的方式进行培训,随着开放领域中可用文本语料库的数量而扩展。 LLM 的大参数空间还允许它们存储大量知识,而大规模预训练(例如训练 GPT 中的自回归目标)使 LLM 能够编码丰富的事实知识以用于语言生成,即使在非常特定的领域也是如此 [ 20]。此外,ChatGPT 的训练遵循 Instruct-GPT [21] 的训练,后者利用人类反馈的强化学习(RLHF),从而使其能够对输入产生更多信息和公正的响应。
受到语言模型在文本生成方面成功的启发,我们提出了一种名为 AugGPT 的新数据增强方法,该方法利用 ChatGPT 生成用于少镜头文本分类的辅助样本。我们通过在通用领域和医学领域数据集上进行实验来测试 AugGPT 的性能。所提出的 AugGPT 方法与现有数据增强方法的性能比较显示句子分类准确性实现了两位数的提高。对生成的文本样本的忠实性和紧凑性的进一步研究表明,AugGPT 可以生成更加多样化的增强样本,同时保持其准确性(即与原始标签的语义相似性)。我们预计法学硕士的发展将带来人类水平的注释性能,从而彻底改变小样本学习和 NLP 中的其他任务领域。
2 相关工作
2.1 数据增强
2.2 小样本学习
2.3 超大型语言模型
2.4 ChatGPT:现在与未来
3 数据集
我们首先使用开放域数据集 Amazon 来验证我们方法的有效性。然后,我们以临床自然语言处理(clinical NLP)为任务,在两个流行的公共基准上进行实验。临床 NLP 中特别需要数据增强,因为专家注释的巨大负担和严格的隐私法规使得大规模数据标记不可行。我们将在以下部分详细描述这些数据集。
3.1 亚马逊数据集
Amazon [74]、[75]、[76] 包含来自 24 个产品类别的客户评论。任务是将评论分类到各自的产品类别中。由于原始亚马逊产品数据集众所周知很大,因此我们从每个类别中抽取了 300 个样本的子集。
3.2 症状数据集
该数据集发布在 Kaggle1 上。它包含超过8小时的常见医学症状描述的音频数据。我们使用音频数据对应的文本转录本进行样本去重,并将其作为模型输入。预处理后的数据集包括7个症状类别的231个样本。每个例子代表一个描述所提供症状的句子,任务是将句子分类为相应的症状
3.3 PubMed20k数据集
PubMed 20K 数据集中的摘要经过预处理并分割成单个句子。每个句子都标有以下五个类别之一:背景、目标、方法、结果或结论。任务是将输入句子映射到相应的类别。
4 方法
给定一个基础数据集 Db = {(xi , yi)} Nb i=1 ,标签空间 yi ∈ Yb ,一个新颖的数据集 Dn = {(xj , yj )} Nn j=1 ,标签空间 yj ∈ Yn ,并且Yb ∩ Yn = ∅。在少样本分类场景中,基础数据集 Db 具有相对较大的标记样本集,而新数据集 Dn 仅具有少量标记样本。在新颖的数据集上评估了少样本学习的性能。我们的目标是使用基础数据集和有限的新颖数据集来训练模型,同时在新颖数据集上实现令人满意的泛化性。
AugGPT的整体框架如图1所示,训练步骤如算法1所示。首先,我们在Db上对BERT进行微调。然后,通过使用 ChatGPT 进行数据增强来生成 Daug n。最后,我们用 Daug 微调 BERT
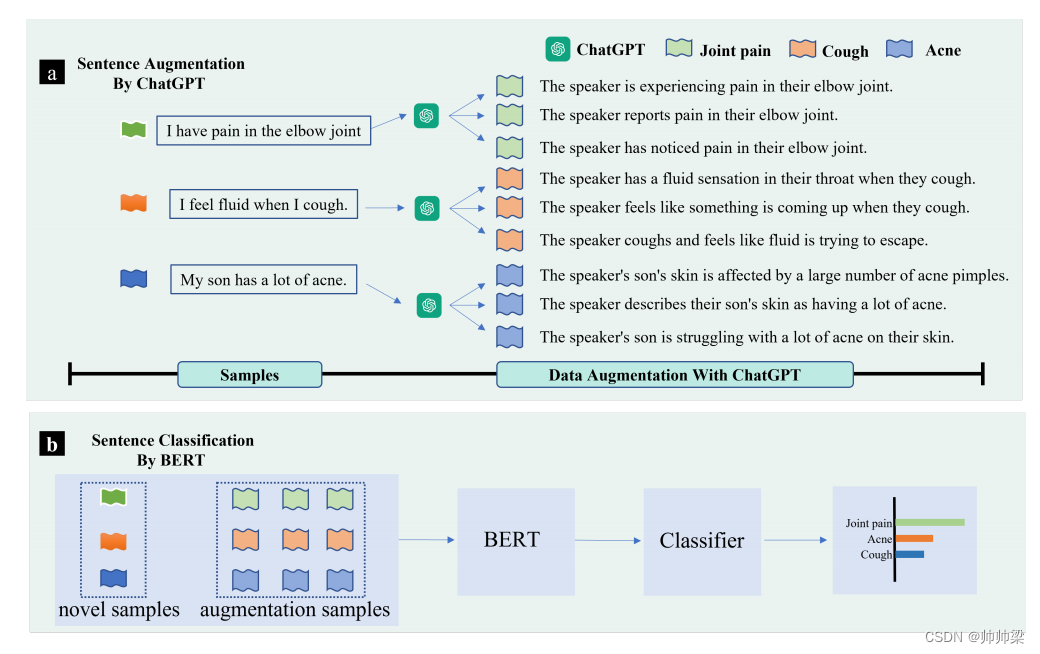
AugGPT的框架。 a(顶部面板):首先,我们应用 ChatGPT 进行数据增强。我们将所有类的样本输入 ChatGPT 并提示 ChatGPT 生成与现有标记实例保持语义一致性的样本。 b(下图):下一步,我们在少数样本和生成的数据样本上训练基于 BERT 的句子分类器,并评估模型的分类性能。
4.2 使用 ChatGPT 进行数据增强
与 GPT [47]、GPT-2 [77] 和 GPT-3 [6] 类似,ChatGPT 属于自回归语言模型家族,并使用 Transformer 解码器块 [78] 作为模型主干。
在预训练过程中,ChatGPT 被视为来自一组样本 X = {x1, x2, …, xn} 的无监督分布估计,由 m 个 token 组成的样本 xi 定义为 xi = (s1, s2, …, . …,SM)。预训练的目标是最大化以下可能性:
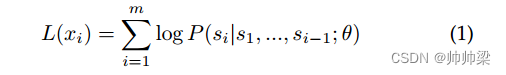
其中 θ 表示 ChatGPT 的可训练参数。
令牌由令牌嵌入和位置嵌入表示:
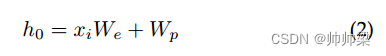
其中 We 是标记嵌入矩阵,Wp 是位置嵌入矩阵。然后使用N个transformer块来提取样本的特征:
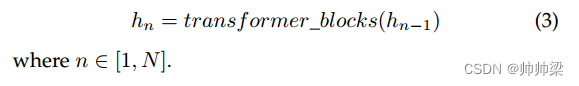
最后,预测目标token:
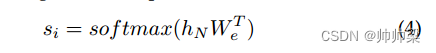
预训练后,ChatGPT 的开发人员应用人类反馈强化学习(RLHF)[21] 来微调预训练的语言模型。 RLHF 通过根据人类反馈进行微调,使语言模型与用户对各种任务的意图保持一致。
ChatGPT 的 RLHF 包含三个步骤:
监督微调(SFT): 与 GPT、GPT-2 和 GPT-3 不同,ChatGPT 使用标记数据进行进一步训练。人工智能培训师扮演用户和人工智能助手的角色,根据提示构建答案。带提示的答案将用作监督数据,用于进一步训练预训练模型。经过进一步的预训练,可以得到SFT模型.
奖励建模(RM):基于SFT方法,训练奖励模型以接收一对提示和响应,并输出标量奖励。人工标记者将输出从最好到最差进行排名,以构建排名数据集。
两个输出之间的损失函数定义如下:
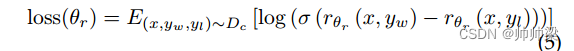
其中θr是奖励模型的参数; x 是提示, yw 是 yw 和 yl 对中的首选完成; Dc 是人类比较的数据集。
强化学习(RL):通过使用奖励模型,ChatGPT 可以使用近端策略优化(PPO)进行微调[79]。为了修复公共 NLP 数据集上的性能下降问题,RLHF 将预训练梯度混合到 PPO 梯度中,也称为 PPO-ptx:
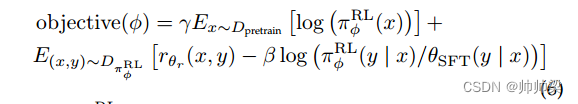
其中 π RL φ 是学习的 RL 策略,θSFT 是监督训练模型,Dpretrain 是预训练分布。 γ是预训练损失系数,控制预训练梯度的强度,β是KL(Kullback-Leibler)奖励系数,控制KL惩罚的强度。
与之前的数据增强方法相比,ChatGPT 更适合数据增强,原因如下:
ChatGPT在大规模语料库上进行预训练,因此具有更广泛的语义表达空间,有助于增强数据增强的多样性。
• 由于ChatGPT的微调阶段引入了大量的人工标注样本,使得ChatGPT生成的语言更符合人类的表达习惯。
• 通过强化学习,ChatGPT可以比较不同表达方式的优缺点,确保生成的数据是高质量的。
在 BERT 框架下,我们引入 ChatGPT 作为少镜头文本分类的数据增强工具。具体来说,ChatGPT 用于将每个输入句子重新表述为六个附加句子,从而增强了少样本样本。…
4.3 小样本文本分类
我们应用 BERT [80] 来训练少量文本分类模型。 BERT顶层的输出特征h可以写为:
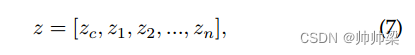
其中 zc 是特定于类的标记 CLS 的表示。对于文本分类,zc 通常被输入到特定于任务的分类器标头中以进行最终预测。然而,在FSL场景下,通过BERT微调很难达到满意的性能,因为few-shot样本规模小,容易导致过拟合,缺乏泛化能力。
为了有效解决少镜头文本分类的挑战,人们提出了许多方法。一般来说,基于大型语言模型的小样本文本分类方法有四类:元学习、提示调整、模型设计和数据增强。元学习是指通过更新元参数的任务来学习的过程[2]、[5]。基于提示的方法通过设计模板来指导大型语言模型预测正确的结果[6]、[7]、[8]、[9]。模型设计方法通过改变模型的结构来指导模型从少样本中学习[81]。数据增强使用相似的字符[22]、相似的单词语义[30]、[31]或知识库[55]、[82]来扩展样本。我们的方法直接通过大型语言模型的语言能力进行数据扩充,这是一种简单高效的数据扩充方法。
目标函数:我们的小样本学习目标函数由两部分组成:交叉熵和对比学习损失。我们将 zc 输入到全连接层,即最终预测的分类器:

其中Wc和bc是可训练参数,并以交叉熵作为目标函数之一:

其中 C 是输出维度,等于基础数据集和新颖数据集的标签空间的并集,yd 是基本事实。
然后,为了充分利用基础数据集中的先验知识来指导新数据集的学习,我们引入了对比损失函数,使同一类别的样本表示更加紧凑,不同类别的样本表示更加分离。
同一批样本对之间的对比损失定义如下:
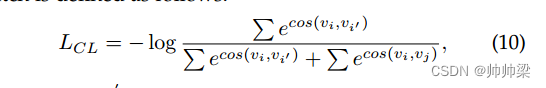
4.4 Baseline Methods
在实验部分,我们将我们的方法与其他流行的数据增强方法进行比较。对于这些方法,我们使用开源库中的实现,包括 nlpaug [83] 和 textattack [84]。
-
插入字符增强。该方法在文本中的随机位置插入随机字符,通过向数据中注入噪声来提高模型的泛化能力。
-
替代字符增强。此方法随机将选定的字符替换为其他字符。
-
交换字符增强[22]。该方法随机交换两个字符。
-
删除字符增强。该方法随机删除字符。
-
OCR 增强。 OCRugmentation 模拟 OCR 识别过程中可能出现的错误。例如,OCR工具可能会将“0”错误地识别为“o”,将“I”错误地识别为“l”。
-
拼写增强[23]。它通过故意拼写错误一些单词来创建新文本。该方法使用牛津词典提供的最有可能拼写错误的英语单词列表,例如将“because”错拼为“becouse”。
-
键盘增强[22]。它通过用 QWERTY 布局键盘中的相邻字符替换随机选择的字符来模拟拼写错误。
例如,将“g”替换为“r”、“t”、“y”、“f”、“h”、“v”、“b”或“n”。 -
SwapWordAug [24]。它随机交换文本中的单词。该方法是Wei等人提出的Easy Data Augmentation (EDA)的子方法
-
删除WordAug。 DeleteWordAug随机删除文本中的单词,这也是EDA的子方法。
-
PPDBSynonymAug [26]。它将单词替换为 PPDB 同义词库中的同义词。同义词替换可以保证语义一致性,适合分类任务。
-
WordNetSynonymAug。它将单词替换为 WordNet 同义词库中的同义词。
-
SubstituteWordByGoogleNewsEmbeddings [28]。它将单词替换为嵌入空间中前 n 个相似的单词。使用的词嵌入是用 GoogleNews 语料库预先训练的。
-
InsertWordByGoogleNewsEmbeddings [83]。它从 GoogleNews 语料库的词汇中随机选择单词并将其插入文本的随机位置。
-
CounterFittedEmbeddingAug [30],[31]。它用反拟合嵌入空间中的邻居替换单词。与 SubstituteWordByGoogleNewsEmbeddings 使用的 GoogleNews 词向量相比,反拟合嵌入引入了同义词和反义词的约束,即同义词之间的嵌入会被拉近,反之亦然。
-
ContextualWordAugUsingBert(插入)[32],[33]。该方法使用BERT根据上下文插入单词,即在输入文本的随机位置添加标记,然后让BERT预测该位置的标记
-
ContextualWordAugUsingDistilBERT(插入)。该方法使用DistilBERT代替BERT进行预测,其余与ContextualWordAugUsingBert(Insert)相同。
-
使用 RoBERTA 的 ContextualWordAug(插入)。该方法使用RoBERTA代替BERT进行预测,其余与ContextualWordAugUsingBert(Insert)相同。
-
ContextualWordAugUsingBert(替代)。该方法[32]、[33]使用BERT根据上下文来替换单词,即将文本中随机选择的单词替换为 token,然后让BERT预测该位置的token。
-
ContextualWordAugUsingDistilBERT(替代)。该方法使用DistilBERT替代BERT进行预测,其余与ContextualWordAugUsingBert(Substitute)相同
-
ContextualWordAug 使用 RoBERTA(替代)。该方法使用RoBERTA替代BERT进行预测,其余与ContextualWordAugUsingBert(Substitute)相同。
-
BackTranslationAug[38]将文本翻译成德语,然后翻译成英语,产生与原始文本不同但具有相同语义的新文本。我们使用Facebook开发的wmt19-en-de和facebook/wmt19-de-en语言翻译模型[85]进行翻译。
4.5 Prompt Design
我们设计了单轮对话和多轮对话的提示。提示如图2所示。亚马逊数据集使用多轮对话提示进行数据增强。 Symptoms 和 PubMed20K 使用单轮对话提示进行数据增强。

Fig. 2. Single-turn dialogue and multi-turn dialogues prompt
4.6 评估指标
我们采用余弦相似度和 TransRate [86] 作为评估忠实度(即生成的数据样本是否接近原始样本)和紧凑度(即每个类的样本是否足够紧凑以进行良好区分)的指标增强数据的
4.6.1 Embedding Similarity
为了评估数据增强方法生成的样本与实际样本之间的语义相似度,我们采用生成的样本与测试数据集的实际样本之间的嵌入相似度。一些最常见的相似性度量包括欧几里德距离、余弦相似性和点积相似性。在本研究中,我们选择余弦相似度来捕获潜在空间中的距离关系。余弦相似度衡量两个向量之间角度的余弦值。
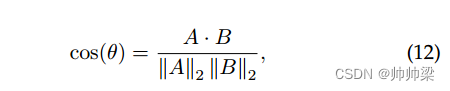
其中 A 和 B 分别表示比较的两个嵌入向量
4.6.2 TransRate
TransRate 是一种基于预训练模型提取的特征与其标签之间的互信息来量化可转移性的指标,并且单次传递目标数据。当所有类的数据协方差矩阵相同时,该度量达到最小值,从而无法区分不同类的数据,并阻止任何分类器获得比随机猜测更好的结果。因此,较高的 TransRate 可能表明数据的可学习性更好。更具体地说,从源任务 Ts 到目标任务 Tt 的知识转移测量如下:
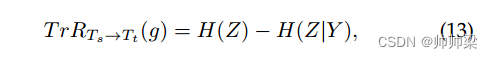
其中Y表示增强示例的标签,Z表示由预训练特征提取器g提取的延迟嵌入特征。 T rR 表示 TransRate 值。 H(·)表示香农熵[89]。
4.7 ChatGPT 的直接分类性能
关于利用 ChatGPT 进行文本数据增强的一个有趣且重要的问题是,当直接应用于 FSL 下游任务时,ChatGPT 将如何执行。因此,我们为 ChatGPT 开发了定制的提示来执行分类任务,并集成了提示 API。
对于症状数据集,我们采用了以下提示指令:“根据一个人的健康描述或症状,从以下类别中预测相应的疾病:类别。”此外,我们使用了“描述”:描述。通常,此症状对应于“CLASS”作为数据集中每个示例的提示。通过这种方式,我们可以包含少量样本(在本工作中,我们使用了两个)来促进模型适应下游任务。我们对其他两个任务使用类似设计的提示指令以及相应的示例提示来实现 ChatGPT 的少样本上下文学习
5 EXPERIMENT RESULTS
5.1 分类性能比较
5.2 增强数据集的评估
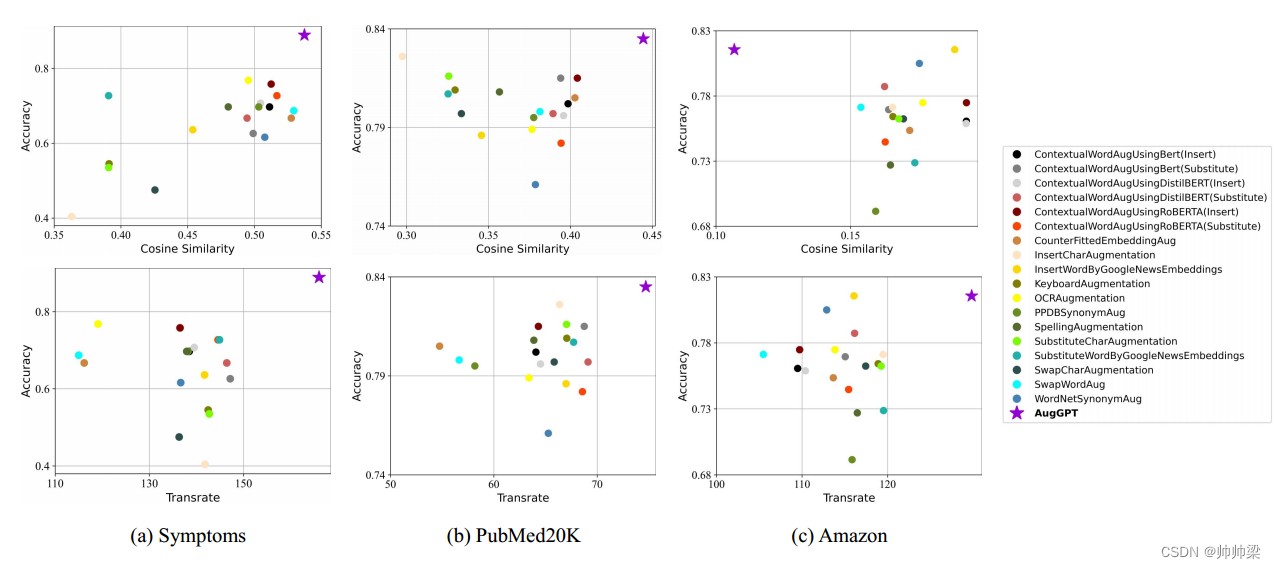
除了分类准确性之外,我们还评估潜在空间中的增强数据并将结果可视化,如图 3 所示。使用余弦相似度和 TransRate 度量来评估潜在嵌入(更多详细信息,请参阅第 4.6 节)。横轴表示余弦相似度值和Transrate值,纵轴表示分类精度。
- 由于嵌入相似度衡量的是生成数据与测试数据集之间的相似度,高相似度意味着生成数据接近真实输入数据,具有更高的忠实性和紧凑性。
- TransRate 越高表示数据的可学习性越好。因此,较高的 TransRate 分数表明增强数据的质量较高。最理想的候选方法应位于可视化的右上角。
如图3所示,AugGPT在Symptoms数据集和PubMed20K数据集上的忠实度和紧凑性方面都产生了高质量的样本。在开放域 Amazon 数据集上,AugGPT 还生成具有更高 TransRate 的高质量样本。
我们采用了两个评估指标来评估新增强数据的真实性和紧凑性。
左上图显示了 Symptoms 数据集上所有数据增强方法的余弦相似度度量和最终精度,左下图显示了 Symptoms 数据集上所有数据增强方法的 TransRate 度量和最终精度。在中间和底部面板中,我们分别绘制了 Amazon 和 PubMed20K 数据集上所有数据增强方法的余弦相似度和 TransRate 值。在图片的右侧,我们列出了所有具有不同颜色和形状的增强方法。
5.3 与 ChatGPT 的性能比较
结论
在本文中,我们提出了一种用于少样本分类的新型数据增强方法。与其他方法不同,我们的模型在语义级别扩展有限的数据以增强数据的一致性和鲁棒性,这比当前大多数文本数据增强方法具有更好的性能。随着 LLM 的进步及其多任务学习器的本质 [77],我们设想 NLP 中的一系列任务可以以类似的方式得到增强甚至取代。
尽管 AugGPT 在数据增强方面显示出了可喜的结果,但它也有一定的局限性。例如,在识别和增强医学文本时,由于缺乏 ChatGPT 的领域知识,AugGPT 可能会产生错误的增强结果。在未来的工作中,我们将研究通过模型微调、上下文学习(即时工程)、知识蒸馏、风格迁移,将通用领域的 LLM(例如 ChatGPT)适应特定领域的数据(例如医学文本)。 ETC
AugGPT已经证明增强结果可以有效提高下游分类任务的性能。未来研究的一个有希望的方向是针对更广泛的下游任务研究 AugGPT。例如,鉴于ChatGPT具有强大的提取关键点和理解句子的能力,它可以用于文本摘要等任务。
具体来说,ChatGPT 对于特定领域的科学论文摘要 [90] 和临床报告摘要 [91] 可能很有价值。由于隐私问题和需要专家知识来生成带注释的摘要,公开可用的特定领域科学论文摘要数据集和临床报告数据集很少,并且通常以小规模提供。然而,ChatGPT 可以通过生成不同表示风格的多种增强摘要样本来解决这一挑战。 ChatGPT 生成的数据通常很简洁,这对于进一步增强训练模型的泛化能力很有价值。
DALLE2 [92] 和 Stable Diffusion [93] 等生成图像模型的急剧兴起为将 AugGPT 应用于计算机视觉中的小样本学习任务提供了机会。例如,准确的语言描述可用于指导生成模型从文本生成图像或基于现有图像生成新图像,作为少样本学习任务的数据增强方法,特别是与高效的微调方法相结合时[94] ,[95]例如 LoRA for Stable Diffusion。因此,来自大型语言模型的先验知识可以促进更快的领域适应和更好的计算机视觉生成模型的小样本学习。
最近的研究表明,大型语言模型(LLM),例如 GPT-3 和 ChatGPT,能够解决心智理论(ToM)任务,这些任务以前被认为是人类独有的[96]。虽然法学硕士的类似 ToM 的能力可能是绩效提高的意外副产品,但认知科学与人脑之间的潜在联系是一个值得探索的领域。认知和脑科学的进步也可以用来启发和优化法学硕士的设计。例如,有人认为 BERT 模型中的神经元的激活模式和人脑网络中的神经元的激活模式可能具有相似之处,并且可以耦合在一起 [97]。这为利用脑科学的先验知识发展法学硕士提供了一个有前途的新方向。随着研究人员继续研究法学硕士与人脑之间的联系,我们可能会发现增强人工智能系统性能和能力的新方法,从而在该领域取得令人兴奋的突破。

![[科研神器]如何让ChatPDF帮你日读文献300篇](https://img-blog.csdnimg.cn/66e83634e6ed40cb8dd7df2cdd5dd77f.png)