前言
机器学习主要分为三类:有监督学习、无监督学习和强化学习。在本文中,我们将介绍无监督学习(Unsupervised Learning)的原理、常见算法和应用领域。
文章目录
- 前言
- 一、原理
- 二、算法
- 1️⃣K均值聚类
- 2️⃣DBSCAN
- 3️⃣主成分分析
- 4️⃣t-SNE
- 5️⃣关联规则挖掘
- 三、应用领域
- 1️⃣图像分割
- 2️⃣推荐系统
- 3️⃣社交网络分析
- 4️⃣自动驾驶
- 四、总结
- 【免费赠书】
- 注:抽奖方式为<脚本随机抽取>,会在我的主页动态如期公布中奖者,包邮到家。
一、原理
无监督学习是机器学习中的一种重要方法,与监督学习相对应。它的目标是从无标签的数据中发现隐藏的结构和模式,而不需要预先定义的目标变量。
无监督学习的核心思想是通过对数据的统计特性和相似性进行分析,来发现数据中的潜在结构和模式。
与监督学习不同,无监督学习不需要事先标记好的训练数据,而是通过对数据的自动处理和聚类来进行学习。
无监督学习可以分为两类问题:聚类和降维。 聚类问题是将数据分成不同的组或簇,使得同一组内的数据相似度高,不同组之间的相似度低。降维问题是将高维数据映射到低维空间,以减少特征维度和数据复杂性。
二、算法
无监督学习中有许多经典的算法,下面介绍其中一些常见的算法:
1️⃣K均值聚类
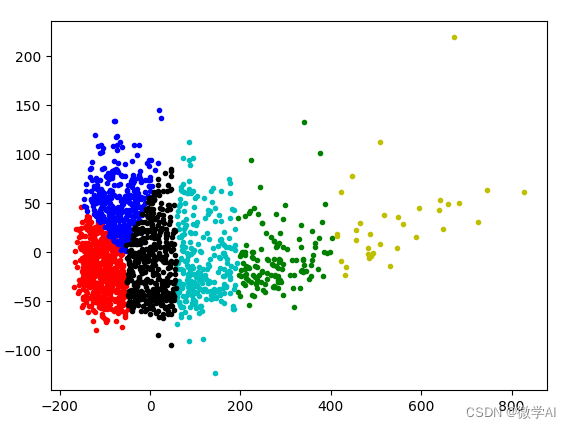
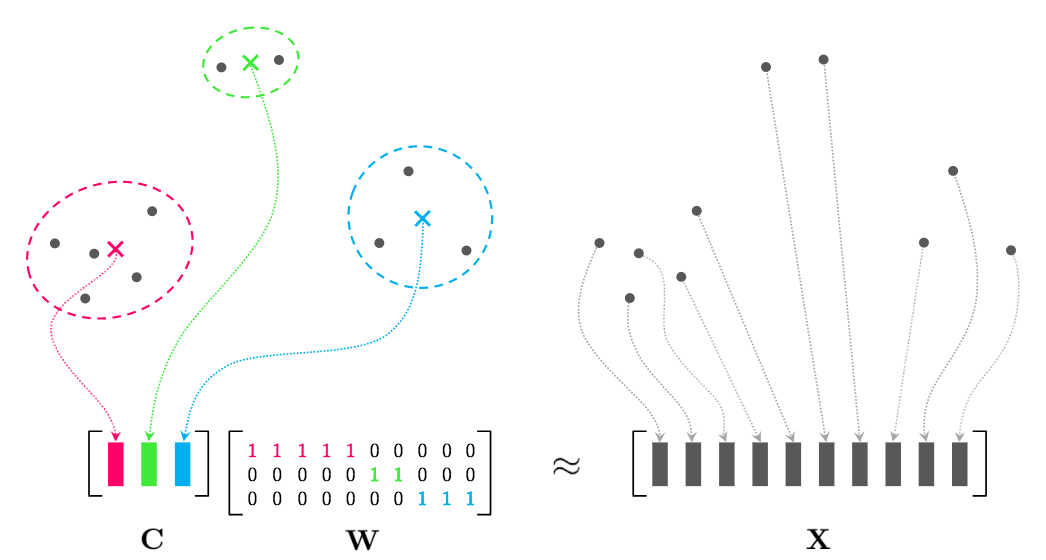
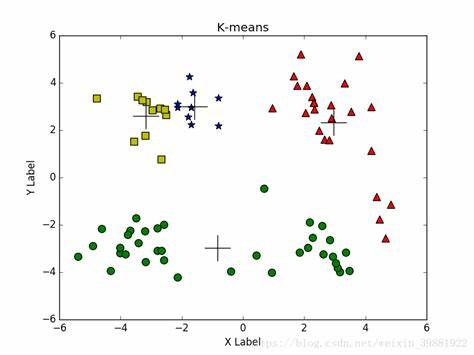
K均值聚类是一种常用的聚类算法。它将数据分成K个簇,每个簇由其质心(簇中心)来表示。算法的核心思想是通过最小化数据点与其所属簇质心之间的距离来进行聚类。
2️⃣DBSCAN
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法。它将数据点分为核心点、边界点和噪声点,并通过密度可达性来判断数据点是否属于同一簇。
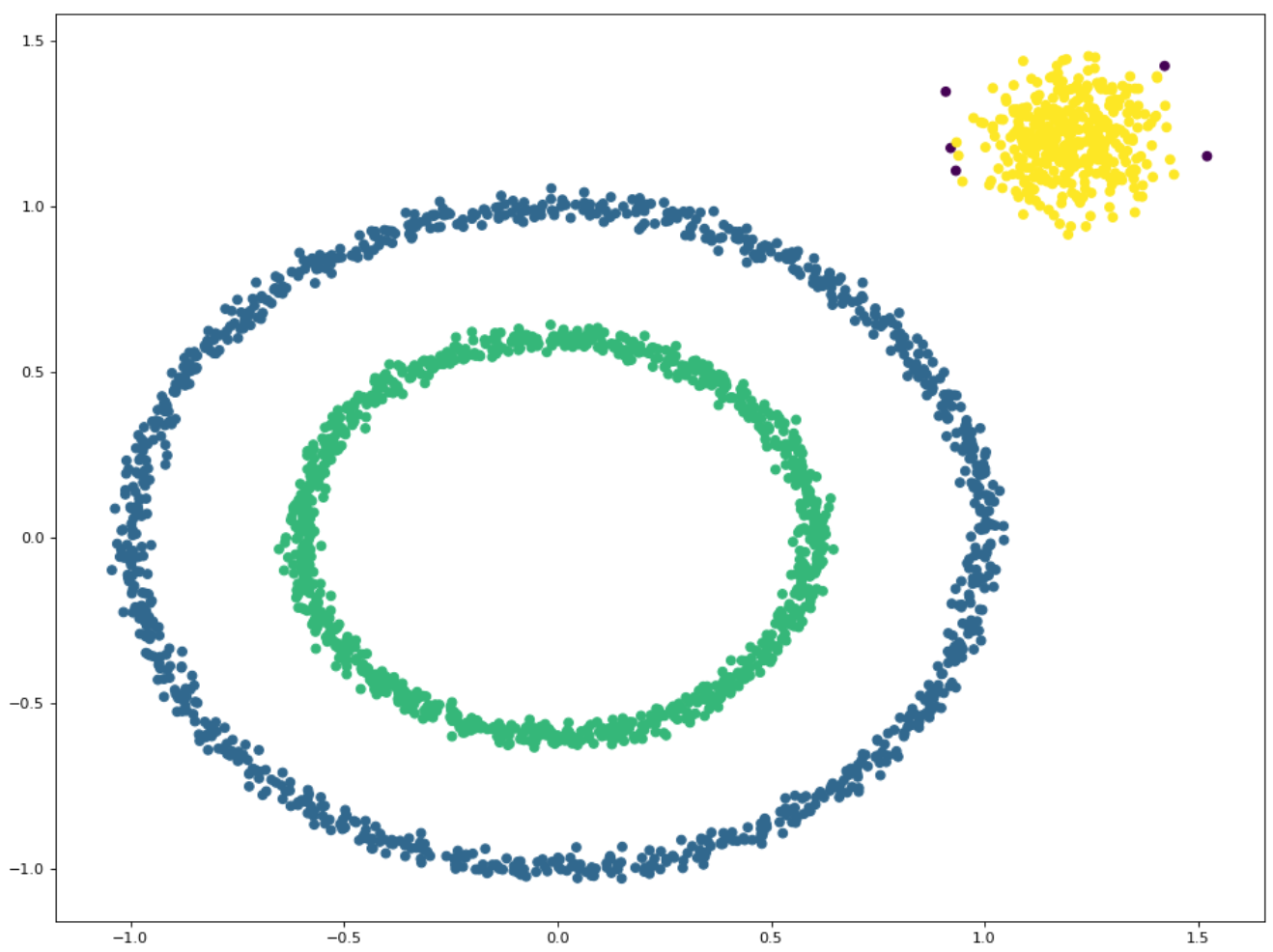
3️⃣主成分分析
主成分分析(Principal Component Analysis,PCA)是一种常用的降维算法。它通过线性变换将高维数据投影到低维空间,以保留最重要的特征。PCA的目标是找到一组正交基,使得投影后的数据具有最大的方差。
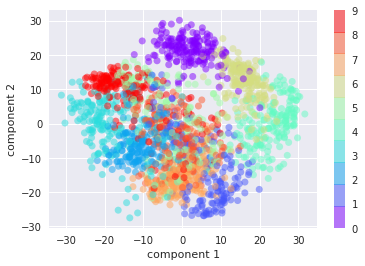
4️⃣t-SNE
t-SNE(t-distributed Stochastic Neighbor Embedding)是一种用于可视化高维数据的降维算法。它通过保持数据点之间的相对距离关系,将高维数据映射到低维空间。t-SNE在可视化聚类和分类问题上表现出色。
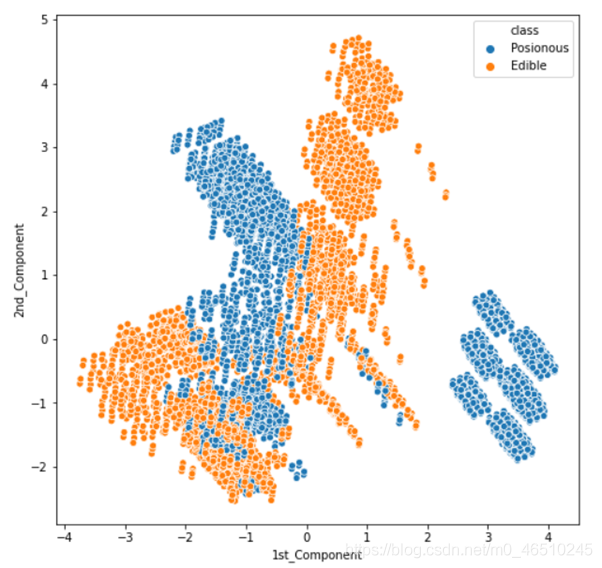
5️⃣关联规则挖掘
关联规则挖掘是一种用于发现数据集中的频繁项集和关联规则的算法。它通过分析数据中的项之间的关联性,来发现隐藏的关联模式。关联规则挖掘在市场篮子分析、推荐系统等领域有广泛应用。
三、应用领域
无监督学习在各个领域都有广泛的应用,下面介绍其中一些常见的应用领域:
1️⃣图像分割
在计算机视觉领域,无监督学习被用于图像分割任务。通过对图像中的像素进行聚类,可以将图像分成不同的区域,以便进行对象识别、图像分析等进一步处理。

2️⃣推荐系统
在推荐系统领域,无监督学习被用于发现用户的兴趣和行为模式。通过对用户的历史行为数据进行聚类和关联规则挖掘,可以为用户提供个性化的推荐结果。
3️⃣社交网络分析
在社交网络分析领域,无监督学习被用于发现社交网络中的社区结构和关系。通过对用户之间的交互数据进行聚类和网络分析,可以揭示社交网络的组织结构和信息传播模式。
4️⃣自动驾驶
在自动驾驶领域,无监督学习被用于对环境和道路进行感知和理解。通过对传感器数据进行聚类和降维,可以提取出道路、车辆和行人等重要特征,以支持自动驾驶决策和控制。
四、总结
无监督学习在聚类、降维和关联规则挖掘等问题上有广泛应用,为我们理解数据和解决实际问题提供了有力的工具和方法。随着数据规模的不断增大和应用场景的不断扩展,无监督学习将在各个领域发挥越来越重要的作用。
【免费赠书】

【!参与方式!】
点赞+收藏+任意评论本文
截止日期:2023-07-20 晚上21:00
注:抽奖方式为<脚本随机抽取>,会在我的主页动态如期公布中奖者,包邮到家。
【内容简介↓】
本书借助ChatGPT与Python轻松实现办公自动化,让没有编程经验的普通办公人员也能驾驭Python,实现多个场景的办公自动化,提升工作效率!
本书全面系统地介绍了Python语言在常见办公场景中的自动化解决方案。内容包括Python语言基础知识,Python读写数据常见方法,用Python自动操作Excel,用Python自动操作Word 与 PPT,用Python自动操作文件和文件夹、邮件、PDF 文件、图片、视频,用Python进行数据可视化分析及进行网页交互,借助ChatGPT轻松进阶Python办公自动化。
当当购买链接:《Python自动化办公应用大全(ChatGPT版)》