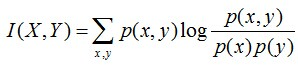ℹ️ 本文参考自 [d2l] Information Theory
此外,本文所提到的 log ( ⋅ ) \log(\cdot) log(⋅) 如无特殊说明均指 log 2 ( ⋅ ) \log_2(\cdot) log2(⋅)。
目录
- 一、自信息(Self-information)
- 二、熵(Entropy)
- 2.1 联合熵(Joint Entropy)
- 2.2 条件熵(Conditional Entropy)
- 2.3 互信息(Mutual Information)
- 2.4 点互信息(Pointwise Mutual Information)
- 三、相对熵(KL散度)
- 四、交叉熵(Cross-Entropy)
- 4.1 二元交叉熵(Binary Cross-Entropy)
一、自信息(Self-information)
先来看一个例子。掷一个质地均匀的骰子,会有 6 6 6 种可能的结果,且每种结果发生的概率均为 1 / 6 1/6 1/6。现在:
- 设事件 X = { 点数不大于 6 } X=\{\text{点数不大于}6\} X={点数不大于6},则显然 P ( X ) = 1 \mathbb{P}(X)=1 P(X)=1;此外,这句话是废话,它并没有告诉我们任何信息,因为掷一个骰子得到的点数肯定不会超过 6 6 6;
- 设事件 X = { 点数不大于 5 } X=\{\text{点数不大于}5\} X={点数不大于5},则显然 P ( X ) = 5 / 6 \mathbb{P}(X)=5/6 P(X)=5/6;此外,这句话包含了一些信息,但并不多,因为我们差不多能够猜到结果;
- 设事件 X = { 点数正好等于 2 } X=\{\text{点数正好等于}2\} X={点数正好等于2},则显然 P ( X ) = 1 / 6 \mathbb{P}(X)=1/6 P(X)=1/6;此外,这句话的信息量要比上面那句话更大,因为 { 点数正好等于 2 } \{\text{点数正好等于}2\} {点数正好等于2} 包含了 { 点数不大于 5 } \{\text{点数不大于}5\} {点数不大于5} 的信息在里面。
从这个例子可以看出,一个事件 X X X 所包含的信息量和它发生的概率有关系。概率越小信息量越大,概率越大信息量越少。
设事件 X X X 所包含的信息量为 I ( X ) I(X) I(X),其发生的概率为 p ≜ P ( X ) p\triangleq \mathbb{P}(X) p≜P(X),那么我们如何寻找 I ( X ) I(X) I(X) 与 p p p 之间的关系呢?
首先,我们有以下常识:
- 观测一个几乎确定的事件得到的信息量几乎是 0 0 0;
- 共同观测两个随机变量得到的信息量不超过分别观测两个随机变量得到的信息量的和,且该不等式取等当且仅当两个随机变量相互独立。
设事件 X = { A 与 B 同时发生,其中 A 、 B 相互独立 } X=\{A与B同时发生,其中A、B相互独立\} X={A与B同时发生,其中A、B相互独立},则显然 P ( X ) = P ( A ) P ( B ) \mathbb{P}(X)=\mathbb{P}(A)\mathbb{P}(B) P(X)=P(A)P(B),而根据上述常识,又有 I ( X ) = I ( A ) + I ( B ) I(X)=I(A)+I(B) I(X)=I(A)+I(B)。不妨设 I ( ∗ ) = f ( P ( ∗ ) ) I(*)=f(\mathbb{P}(*)) I(∗)=f(P(∗)),则
f ( P ( A ) ⋅ P ( B ) ) = f ( P ( X ) ) = I ( X ) = I ( A ) + I ( B ) = f ( P ( A ) ) + f ( P ( B ) ) f(\mathbb{P}(A)\cdot \mathbb{P}(B))=f(\mathbb{P}(X))=I(X)=I(A)+I(B)=f(\mathbb{P}(A))+f(\mathbb{P}(B)) f(P(A)⋅P(B))=f(P(X))=I(X)=I(A)+I(B)=f(P(A))+f(P(B))
不难看出 log ( ⋅ ) \log(\cdot) log(⋅) 能够满足这一要求。但考虑到 log x \log x logx 在 ( 0 , 1 ] (0,1] (0,1] 上是非正的且单调递增,所以我们一般采用 − log ( ⋅ ) -\log(\cdot) −log(⋅) 来衡量一个事件的信息量。
综合以上,设事件 X X X 发生的概率为 p p p,则其信息量(又称自信息)可以这样计算:
I ( X ) = − log p (1) \textcolor{red}{I(X)=-\log p\tag{1}} I(X)=−logp(1)
- 当 ( 1 ) (1) (1) 式中的 log \log log 以 2 2 2 为底时,自信息的单位是 bit \text{bit} bit;
- 当 ( 1 ) (1) (1) 式中的 log \log log 以 e e e 为底时,自信息的单位是 nat \text{nat} nat;
- 当 ( 1 ) (1) (1) 式中的 log \log log 以 10 10 10 为底时,自信息的单位是 hart \text{hart} hart。
还可以得到:
1 nat = log 2 e bit ≈ 1.443 bit , 1 hart = log 2 10 bit ≈ 3.322 bit 1\;\text{nat}=\log_2 e\;\text{bit}\approx 1.443 \;\text{bit},\quad 1\;\text{hart}=\log_2 10\;\text{bit}\approx 3.322 \;\text{bit} 1nat=log2ebit≈1.443bit,1hart=log210bit≈3.322bit
我们知道,对于任何长度为 n n n 的二进制序列,它包含 n n n 比特的信息。例如,对于序列 0010 0010 0010,它出现的概率是 1 / 2 4 1/2^4 1/24,因此
I ( “ 0010 ” ) = − log 1 2 4 = 4 bits I(\text{“\,0010\,”})=-\log\frac{1}{2^4}=4\;\text{bits} I(“0010”)=−log241=4bits
二、熵(Entropy)
设随机变量 X X X 服从分布 D \mathcal{D} D,则 X X X 的熵定义为其信息量的期望:
H ( X ) = E X ∼ D [ I ( X ) ] (2) \textcolor{red}{H(X)=\mathbb{E}_{X\sim\mathcal{D}}[I(X)]}\tag{2} H(X)=EX∼D[I(X)](2)
若 X X X 是离散分布,则
H ( X ) = − E X ∼ D [ log p i ] = − ∑ i p i log p i H(X)=-\mathbb{E}_{X\sim\mathcal{D}}[\log p_i]=-\sum_ip_i\log p_i H(X)=−EX∼D[logpi]=−i∑pilogpi
若 X X X 是连续分布,则
H ( X ) = − E X ∼ D [ log p ( x ) ] = − ∫ p ( x ) log p ( x ) d x H(X)=-\mathbb{E}_{X\sim\mathcal{D}}[\log p(x)]=-\int p(x)\log p(x)\text{d}x H(X)=−EX∼D[logp(x)]=−∫p(x)logp(x)dx
在离散情况下,设 X X X 只取 k k k 个值,则有: 0 ≤ H ( X ) ≤ log k 0\leq H(X)\leq \log k 0≤H(X)≤logk。
📌 与信息量不同的是,这里的 X X X 是随机变量而不是事件
📌 把事件看成一个点,则信息量可以看成一个点所产生的的信息,而信息熵则代表一系列点所产生的信息的均量
📌 接下来的章节中我们都将只讨论离散情形,连续情形下的公式可类比推理
2.1 联合熵(Joint Entropy)
我们已经知道如何计算 X X X 的信息熵了,那么如何计算 ( X , Y ) (X,Y) (X,Y) 的信息熵呢?
设 ( X , Y ) ∼ D (X,Y)\sim\mathcal{D} (X,Y)∼D,联合概率分布为 p i j ≜ P ( X = x i , Y = y j ) p_{ij}\triangleq \mathbb{P}(X=x_i,Y=y_j) pij≜P(X=xi,Y=yj),再记 p i = P ( X = x i ) , p j = P ( Y = y j ) p_i=\mathbb{P}(X=x_i),\,p_j=\mathbb{P}(Y=y_j) pi=P(X=xi),pj=P(Y=yj),依照信息熵的定义类似可得
H ( X , Y ) = − ∑ i j p i j log p i j (3) \textcolor{red}{H(X,Y)=-\sum_{ij}p_{ij}\log p_{ij}}\tag{3} H(X,Y)=−ij∑pijlogpij(3)
如果 X = Y X=Y X=Y,则 H ( X , Y ) = H ( X ) = H ( Y ) H(X,Y)=H(X)=H(Y) H(X,Y)=H(X)=H(Y);如果 X X X 和 Y Y Y 相互独立,则 p i j = p i ⋅ p j p_{ij}=p_i\cdot p_j pij=pi⋅pj,进而
H ( X , Y ) = − ∑ i j ( p i ⋅ p j ) ( log p i + log p j ) = − ∑ j p j ∑ i p i log p i − ∑ i p i ∑ j p j log p j = H ( X ) + H ( Y ) H(X,Y)=-\sum_{ij}(p_i\cdot p_j)(\log p_i+\log p_j)=-\sum_j p_j\sum_i p_i\log p_i-\sum_ip_i\sum_jp_j\log p_j=H(X)+H(Y) H(X,Y)=−ij∑(pi⋅pj)(logpi+logpj)=−j∑pji∑pilogpi−i∑pij∑pjlogpj=H(X)+H(Y)
此外,总有以下不等式成立:
H ( X ) , H ( Y ) ≤ H ( X , Y ) ≤ H ( X ) + H ( Y ) H(X),H(Y)\leq H(X,Y)\leq H(X)+H(Y) H(X),H(Y)≤H(X,Y)≤H(X)+H(Y)
2.2 条件熵(Conditional Entropy)
条件熵 H ( Y ∣ X ) H(Y|X) H(Y∣X) 表示在已知随机变量 X X X 的情况下随机变量 Y Y Y 的不确定性,定义为 X X X 给定条件下 Y Y Y 的条件概率分布的熵对 X X X 的数学期望:
H ( Y ∣ X ) = ∑ i p i H ( Y ∣ X = x i ) = ∑ i p i ( − ∑ j p j ∣ i log p j ∣ i ) = − ∑ i j p i j log p j ∣ i (4) H(Y|X)=\sum_i p_iH(Y|X=x_i)=\sum_i p_i \left( -\sum_j p_{j|i}\log p_{j|i}\right)=-\sum_{ij}p_{ij}\log p_{j|i}\tag{4} H(Y∣X)=i∑piH(Y∣X=xi)=i∑pi(−j∑pj∣ilogpj∣i)=−ij∑pijlogpj∣i(4)
利用 p j ∣ i = p i j / p i p_{j|i}=p_{ij}/p_i pj∣i=pij/pi 可得
H ( Y ∣ X ) = H ( X , Y ) − H ( X ) H(Y|X)=H(X,Y)-H(X) H(Y∣X)=H(X,Y)−H(X)
从上式可以看出, H ( Y ∣ X ) H(Y|X) H(Y∣X) 实际上代表了包含在 Y Y Y 但不包含在 X X X 中的信息(类似于 P ( B \ A ) = P ( A ∪ B ) − P ( A ) \mathbb{P}(B\backslash A)=\mathbb{P}(A\cup B)-\mathbb{P}(A) P(B\A)=P(A∪B)−P(A))。
2.3 互信息(Mutual Information)
给定随机变量 ( X , Y ) (X,Y) (X,Y),我们已经知道了 X X X 的信息可以用 H ( X ) H(X) H(X) 来表示; ( X , Y ) (X,Y) (X,Y) 总共的信息可以用 H ( X , Y ) H(X,Y) H(X,Y) 来表示;包含在 Y Y Y 但不包含在 X X X 中的信息可以用 H ( Y ∣ X ) H(Y|X) H(Y∣X) 来表示。那我们该用什么来衡量 X X X 和 Y Y Y 都包含的信息呢?
答案是互信息,其定义如下(可以理解为集合 X X X 与 Y Y Y 的交集):
I ( X , Y ) = H ( X , Y ) − H ( Y ∣ X ) − H ( X ∣ Y ) (5) \textcolor{red}{I(X,Y)=H(X,Y)-H(Y|X)-H(X|Y)}\tag{5} I(X,Y)=H(X,Y)−H(Y∣X)−H(X∣Y)(5)
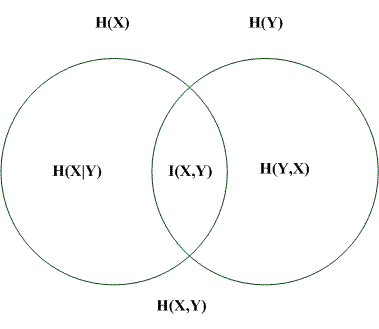
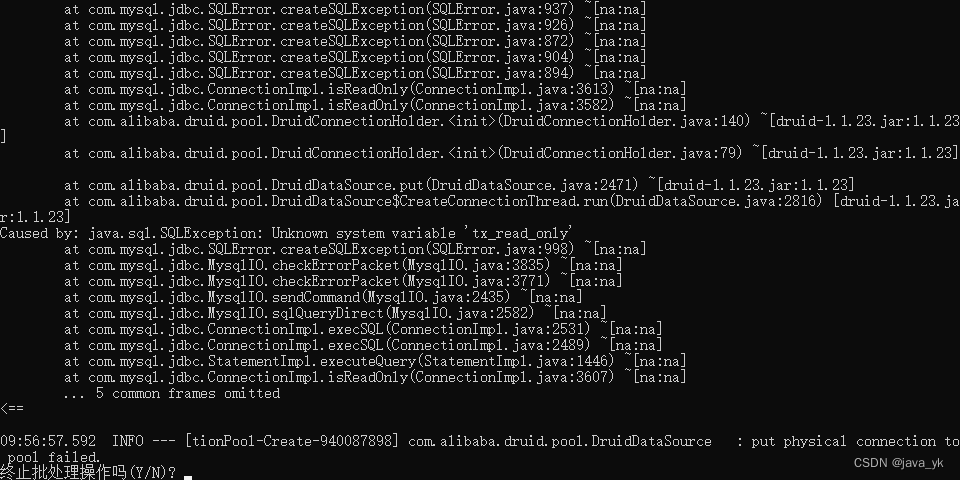
熵、联合熵、条件熵、互信息之间的关系如下:

从上图还可以得到:
I ( X , Y ) = H ( X ) − H ( X ∣ Y ) I ( X , Y ) = H ( Y ) − H ( Y ∣ X ) I ( X , Y ) = H ( X ) + H ( Y ) − H ( X , Y ) \begin{aligned} I(X,Y)&=H(X)-H(X|Y) \\ I(X,Y)&=H(Y)-H(Y|X) \\ I(X,Y)&=H(X)+H(Y)-H(X,Y) \end{aligned} I(X,Y)I(X,Y)I(X,Y)=H(X)−H(X∣Y)=H(Y)−H(Y∣X)=H(X)+H(Y)−H(X,Y)
我们将 ( 5 ) (5) (5) 式展开得到
I ( X , Y ) = − ∑ i j p i j log p i j + ∑ i j p i j log p j ∣ i + ∑ i j p i j log p i ∣ j = ∑ i j p i j ( log p j ∣ i + log p i ∣ j − log p i j ) = ∑ i j p i j log p i j p i ⋅ p j = E ( X , Y ) ∼ D [ log p i j p i ⋅ p j ] \begin{aligned} I(X,Y)&=-\sum_{ij}p_{ij}\log p_{ij}+\sum_{ij}p_{ij}\log p_{j|i}+\sum_{ij}p_{ij}\log p_{i|j} \\ &=\sum_{ij}p_{ij}(\log p_{j|i}+\log p_{i|j}-\log p_{ij}) \\ &=\sum_{ij} p_{ij} \log \frac{p_{ij}}{p_i\cdot p_j} \\ &=\mathbb{E}_{(X,Y)\sim \mathcal{D}}\left[\log \frac{p_{ij}}{p_i\cdot p_j}\right] \end{aligned} I(X,Y)=−ij∑pijlogpij+ij∑pijlogpj∣i+ij∑pijlogpi∣j=ij∑pij(logpj∣i+logpi∣j−logpij)=ij∑pijlogpi⋅pjpij=E(X,Y)∼D[logpi⋅pjpij]
互信息的一些性质:
- 对称性: I ( X , Y ) = I ( Y , X ) I(X,Y)=I(Y,X) I(X,Y)=I(Y,X);
- 非负性: I ( X , Y ) ≥ 0 I(X,Y)\geq 0 I(X,Y)≥0;
- I ( X , Y ) = 0 I(X,Y)=0 I(X,Y)=0 ⇔ \;\Leftrightarrow\; ⇔ X X X 与 Y Y Y 相互独立;
2.4 点互信息(Pointwise Mutual Information)
点互信息定义为:
PMI ( x i , y j ) = log p i j p i ⋅ p j (6) \textcolor{red}{\text{PMI}(x_i,y_j)=\log \frac{p_{ij}}{p_i\cdot p_j}} \tag{6} PMI(xi,yj)=logpi⋅pjpij(6)
结合 2.3 节,我们会发现有如下关系成立(好比信息熵是信息量的期望一样,互信息也是点互信息的期望)
I ( X , Y ) = E ( X , Y ) ∼ D [ PMI ( x i , y j ) ] I(X,Y)=\mathbb{E}_{(X,Y)\sim \mathcal{D}}\left[\text{PMI}(x_i,y_j)\right] I(X,Y)=E(X,Y)∼D[PMI(xi,yj)]
PMI 的值越高,表示 x i x_i xi 与 y j y_j yj 的相关性越强。PMI 常用于 NLP 任务中计算两个单词之间的相关性,但如果语料库不足,可能会出现 p i j = 0 p_{ij}=0 pij=0 的情况,这就导致两个单词的互信息为 − ∞ -\infty −∞,因此需要做一个修正:
PPMI ( x i , y j ) = max ( 0 , PMI ( x i , y j ) ) \text{PPMI}(x_i,y_j)=\max(0,\text{PMI}(x_i,y_j)) PPMI(xi,yj)=max(0,PMI(xi,yj))
上述的 PPMI 又称为正点互信息(Positive PMI)。
三、相对熵(KL散度)
相对熵(Relative Entropy)又称为KL散度(Kullback–Leibler divergence),后者是其更常用的名字。
设随机变量 X X X 服从概率分布 P P P,现在我们尝试用另外一个概率分布 Q Q Q 来估计 P P P(假设 Y ∼ Q Y\sim Q Y∼Q)。记 p i = P ( X = x i ) , q i = P ( Y = x i ) p_i=\mathbb{P}(X=x_i),\,q_i=\mathbb{P}(Y=x_i) pi=P(X=xi),qi=P(Y=xi),则KL散度定义为
D KL ( P ∥ Q ) = E X ∼ P [ log p i q i ] = ∑ i p i log p i q i (7) D_{\text{KL}}(P\Vert Q)=\mathbb{E}_{X\sim P}\left[\log \frac{p_i}{q_i}\right]=\sum_ip_i\log \frac{p_i}{q_i}\tag{7} DKL(P∥Q)=EX∼P[logqipi]=i∑pilogqipi(7)
KL散度的一些性质:
- 非对称性: D KL ( P ∥ Q ) ≠ D KL ( Q ∥ P ) D_{\text{KL}}(P\Vert Q)\neq D_{\text{KL}}(Q\Vert P) DKL(P∥Q)=DKL(Q∥P);
- 非负性: D KL ( P ∥ Q ) ≥ 0 D_{\text{KL}}(P\Vert Q)\geq 0 DKL(P∥Q)≥0,等式成立当且仅当 P = Q P=Q P=Q;
- 若存在 x i x_i xi 使得 p i > 0 , q i = 0 p_i>0,\,q_i=0 pi>0,qi=0,则 D KL ( P ∥ Q ) = ∞ D_{\text{KL}}(P\Vert Q) =\infty DKL(P∥Q)=∞。
KL散度被用来衡量两个概率分布之间的差异。如果两个分布完全相等,则KL散度为 0 0 0。因此,KL散度可以用作多分类任务的损失函数。
📌 由于KL散度不满足对称性,因此它不是严格意义上的 “距离”
四、交叉熵(Cross-Entropy)
我们将 ( 7 ) (7) (7) 式拆解
D KL ( P ∥ Q ) = ∑ i p i log p i − ∑ i p i log q i D_{\text{KL}}(P\Vert Q)=\sum_i p_i\log p_i-\sum_i p_i\log q_i DKL(P∥Q)=i∑pilogpi−i∑pilogqi
若令 CE ( P , Q ) = − ∑ i p i log q i \text{CE}(P,Q)=-\sum_i p_i\log q_i CE(P,Q)=−∑ipilogqi,则上式可写成
D KL ( P ∥ Q ) = CE ( P , Q ) − H ( P ) D_{\text{KL}}(P\Vert Q)=\text{CE}(P,Q)-H(P) DKL(P∥Q)=CE(P,Q)−H(P)
而 CE ( P , Q ) \text{CE}(P,Q) CE(P,Q) 就是我们所说的交叉熵,其正式定义为
CE ( P , Q ) = − E X ∼ P [ log q i ] (8) \textcolor{red}{\text{CE}(P,Q)=-\mathbb{E}_{X\sim P}[\log q_i]}\tag{8} CE(P,Q)=−EX∼P[logqi](8)
结合KL散度的非负性,我们还可以得到 CE ( P , Q ) ≥ H ( P ) \text{CE}(P,Q)\geq H(P) CE(P,Q)≥H(P),该不等式又称为吉布斯不等式。
📌 通常 CE ( P , Q ) \text{CE}(P,Q) CE(P,Q) 也会写成 H ( P , Q ) H(P,Q) H(P,Q)
交叉熵计算一例:
P P P 是真实分布,而 Q Q Q 是估计分布,考虑三分类问题,对于某个样本,其真实标签和预测结果列在下表中:
| 类别 1 | 类别 2 | 类别 3 | |
|---|---|---|---|
| target | 0 | 1 | 0 |
| prediction | 0.2 | 0.7 | 0.1 |
从上表可以看出,该样本真实情况是属于类别 2,且 p 1 = 0 , p 2 = 1 , p 3 = 0 , q 1 = 0.2 , q 2 = 0.7 , q 3 = 0.1 p_1=0,p_2=1,p_3=0,q_1=0.2,q_2=0.7,q_3=0.1 p1=0,p2=1,p3=0,q1=0.2,q2=0.7,q3=0.1。
因此
CE ( P , Q ) = − ( 0 ⋅ log 0.2 + 1 ⋅ log 0.7 + 0 ⋅ log 0.1 ) = − log 0.7 ≈ 0.5146 \text{CE}(P,Q)=-(0\cdot \log 0.2+1\cdot \log 0.7+0\cdot \log 0.1)=-\log 0.7\approx 0.5146 CE(P,Q)=−(0⋅log0.2+1⋅log0.7+0⋅log0.1)=−log0.7≈0.5146
📶 当给定了数据集, H ( P ) H(P) H(P) 就成了一个常数,因此KL散度和交叉熵都能够用作多分类问题的损失函数。当真实分布 P P P 是 One-Hot 向量时,则有 H ( P ) = 0 H(P)=0 H(P)=0,此时交叉熵等于KL散度
4.1 二元交叉熵(Binary Cross-Entropy)
二元交叉熵(BCE)是交叉熵的一个特例
BCE ( P , Q ) = − ∑ i = 1 2 p i log q i = − ( p 1 log q 1 + p 2 log q 2 ) = − ( p 1 log q 1 + ( 1 − p 1 ) log ( 1 − q 1 ) ) \begin{aligned} \text{BCE}(P,Q)&=-\sum_{i=1}^2p_i\log q_i \\ &=-(p_1\log q_1+p_2\log q_2) \\ &=-(p_1\log q_1+(1-p_1)\log (1-q_1))\qquad \end{aligned} BCE(P,Q)=−i=1∑2pilogqi=−(p1logq1+p2logq2)=−(p1logq1+(1−p1)log(1−q1))
BCE 可用作二分类或多标签分类的损失函数。
📌 交叉熵损失前通常接Softmax,而二元交叉熵损失前通常接Sigmoid
📌 二分类情景下,输出层既可以采用一个神经元+Sigmoid也可以采用两个神经元+Softmax,两者等价,但使用前者训练起来更快一些
BCE 还可通过 MLE 得到。给定 n n n 个样本: x 1 , x 2 , ⋯ , x n x_1,x_2,\cdots,x_n x1,x2,⋯,xn,每个样本的标签 y i y_i yi 非 0 0 0 即 1 1 1( 1 1 1 代表正类, 0 0 0 代表负类),神经网络的参数简记为 θ \theta θ。我们的目标是寻找最优的 θ \theta θ 使得 y ^ i = P θ ( y i ∣ x i ) \hat{y}_i=\mathbb{P}_{\theta}(y_i|x_i) y^i=Pθ(yi∣xi)。设 x i x_i xi 被分类为正类的概率为 π i = P θ ( y i = 1 ∣ x i ) \pi_i=\mathbb{P}_{\theta}(y_i=1|x_i) πi=Pθ(yi=1∣xi),则对数似然函数为
ℓ ( θ ) = log L ( θ ) = log ∏ i = 1 n π i y i ( 1 − π i ) 1 − y i = ∑ i = 1 n y i log π i + ( 1 − y i ) log ( 1 − π i ) \begin{aligned} \ell(\theta)&=\log L(\theta) \\ &=\log \prod_{i=1}^n \pi_i^{y_i}(1-\pi_i)^{1-y_i} \\ &=\sum_{i=1}^ny_i\log \pi_i+(1-y_i)\log (1-\pi_i) \end{aligned} ℓ(θ)=logL(θ)=logi=1∏nπiyi(1−πi)1−yi=i=1∑nyilogπi+(1−yi)log(1−πi)
最大化 ℓ ( θ ) \ell(\theta) ℓ(θ) 等价于最小化 − ℓ ( θ ) -\ell(\theta) −ℓ(θ),而后者就是二元交叉熵损失。