【Kaggle竞赛树叶分类1】https://www.kaggle.com/c/classify-leaves
任务是预测叶子图像的类别。该数据集包含 176 个类别、18353 张训练图像、8800 张测试图像。每个类别至少有 50 张图像用于训练。测试集平均分为公共和私人排行榜。本次比赛的评估指标是分类准确度。本章的内容是介绍Baseline。下一章将介绍提升分类准确度的tricks和模型
环境:将使用google colab pro作为代码运行和云服务器平台。
#先分配GPU
!nvidia-smi
from google.colab import drive
drive.mount('/content/drive/')
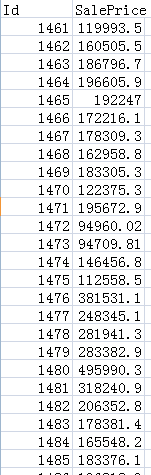
首先,将数据导入colab云端硬盘中,其中有一个images文件夹,一个train表格,test表格,和1个上交预测结果的表格。

可以看到Images文件夹中有很多形状不同的叶子。

1.Baseline(简单的resnet)
感谢Neko Kiku提供的Baseline,来自https://www.kaggle.com/nekokiku/simple-resnet-baseline
首先导入需要的包
# 首先导入包
import torch
import torch.nn as nn
import pandas as pd
import numpy as np
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import os
import matplotlib.pyplot as plt
import torchvision.models as models
# This is for the progress bar.
from tqdm import tqdm
import seaborn as sns
使用pd.read_csv将训练集表格读入,然后看看label文件长啥样,image栏是图片的名称,label是图片的分类标签。
labels_dataframe = pd.read_csv('/content/drive/MyDrive/classify-leaves/train.csv')
labels_dataframe.head(5)

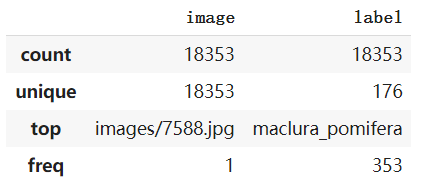
使用pd.describe()函数生成描述性统计数据,统计数据集的集中趋势,分散和行列的分布情况,不包括 NaN值。可以看到训练集总共有18353张图片,标签有176类。
labels_dataframe.describe()
用条形图可视化176类图片的分布(数目)。
#function to show bar lengthdef barw(ax): for p in ax.patches:val = p.get_width() #height of the barx = p.get_x()+ p.get_width() # x- position y = p.get_y() + p.get_height()/2 #y-positionax.annotate(round(val,2),(x,y))#finding top leavesplt.figure(figsize = (15,30))
#类别特征的频数条形图(x轴是count数,y轴是类别。)
ax0 =sns.countplot(y=labels_dataframe['label'],order=labels_dataframe['label'].value_counts().index)
barw(ax0)
plt.show()

把label标签按字母排个序,这里仅显示前10个。
#把label文件排个序
leaves_labels = sorted(list(set(labels_dataframe['label'])))
n_classes = len(leaves_labels)
print(n_classes)
leaves_labels[:10]
176
[‘abies_concolor’,
‘abies_nordmanniana’,
‘acer_campestre’,
‘acer_ginnala’,
‘acer_griseum’,
‘acer_negundo’,
‘acer_palmatum’,
‘acer_pensylvanicum’,
‘acer_platanoides’,
‘acer_pseudoplatanus’]
把label和176类zip一下再字典,把label转成对应的数字。
把label转成对应的数字
class_to_num = dict(zip(leaves_labels, range(n_classes)))
class_to_num
{‘abies_concolor’: 0,
‘abies_nordmanniana’: 1,
‘acer_campestre’: 2,
‘acer_ginnala’: 3,
‘acer_griseum’: 4,
‘acer_negundo’: 5,
‘acer_palmatum’: 6,
‘acer_pensylvanicum’: 7,
‘acer_platanoides’: 8,
‘acer_pseudoplatanus’: 9,
‘acer_rubrum’: 10,
…
‘ulmus_pumila’: 173,
‘ulmus_rubra’: 174,
‘zelkova_serrata’: 175}
再将类别数转换回label,方便最后预测的时候使用。
# 再转换回来,方便最后预测的时候使用
num_to_class = {v : k for k, v in class_to_num.items()}
创建树叶数据集类LeavesData(Dataset),用来批量管理训练集、验证集和测试集。
1.定义__init__初始化函数
其中,csv_path是csv文件路径,file_path是图像文件所在路径,valid_ratio是验证集比例为0.2,resize_height和resize_width是调整后的照片尺寸256×256,mode参数最重要,这里决定是“训练数据集”还是“验证数据集”还是“测试数据集”:(train/val/test_dataset = LeavesData(train_path, img_path, mode='train/valid/test')。
用pandas读取csv文件,self.data_info = pd.read_csv(csv_path, header=None) 去掉表头部分。(注意test的cvs路径是不一样的)
然后计算数据集的长度,例如读取data的长度乘上(1-0.2)就是训练集数据的长度self.train_len。
当mode==“train”:
使用np.asarray(self.data_info.iloc[1:self.train_len, 0])读取第1列(图片名称列),从第2行开始读到self.train_len是训练集的图像名称。
使用np.asarray(self.data_info.iloc[1:self.train_len, 1])读取第2列(图片标签列),从第2行开始读到self.train_len是训练集的图像标签。
当mode==“valid”:
使用np.asarray(self.data_info.iloc[self.train_len:, 0])读取第1列(图片名称列),从第self.train_len行开始读完是验证集的图像名称。
使用np.asarray(self.data_info.iloc[self.train_len:, 1])读取第2列(图片标签列),从第self.train_len行开始读完是验证集的图像标签。
当mode==“test”:
test的cvs路径不同,有一个另外的test.csv,使用np.asarray(self.data_info.iloc[1:, 0])读取测试集图像名称列的所有名称。
2.定义__getitem__函数, 示例对象p可以通过p[key]取值,这里返回每一个index对应的图片数据和对应的标签。
single_image_name = self.image_arr[index]从image_arr中得到index对应的文件名,然后使用img_as_img = Image.open(self.file_path + single_image_name)读取图像文件。
对训练集的图片,定义一系列的transform。包括resize到224×224,0.5的概率随机水平翻转,ToTensor等。(这个Baseline其实只做了随机水平翻转的图像增强,没有其他操作,有改进余地)
对验证集和测试集的图片,transform里不做数据增强,仅resize后ToTensor。
保存transform后的图像img_as_img = transform(img_as_img)
对于训练集和验证集,通过label = self.label_arr[index]返回图像的string label和 number_label = class_to_num[label]返回number label。而测试集,直接返回img_as_img。
# 继承pytorch的dataset,创建自己的
class LeavesData(Dataset):def __init__(self, csv_path, file_path, mode='train', valid_ratio=0.2, resize_height=256, resize_width=256):"""Args:csv_path (string): csv 文件路径img_path (string): 图像文件所在路径mode (string): 训练模式还是测试模式valid_ratio (float): 验证集比例"""# 需要调整后的照片尺寸,我这里每张图片的大小尺寸不一致#self.resize_height = resize_heightself.resize_width = resize_widthself.file_path = file_pathself.mode = mode# 读取 csv 文件# 利用pandas读取csv文件self.data_info = pd.read_csv(csv_path, header=None) #header=None是去掉表头部分# 计算 lengthself.data_len = len(self.data_info.index) - 1self.train_len = int(self.data_len * (1 - valid_ratio))if mode == 'train':# 第一列包含图像文件的名称self.train_image = np.asarray(self.data_info.iloc[1:self.train_len, 0]) #self.data_info.iloc[1:,0]表示读取第一列,从第二行开始到train_len# 第二列是图像的 labelself.train_label = np.asarray(self.data_info.iloc[1:self.train_len, 1])self.image_arr = self.train_image self.label_arr = self.train_labelelif mode == 'valid':self.valid_image = np.asarray(self.data_info.iloc[self.train_len:, 0]) self.valid_label = np.asarray(self.data_info.iloc[self.train_len:, 1])self.image_arr = self.valid_imageself.label_arr = self.valid_labelelif mode == 'test':self.test_image = np.asarray(self.data_info.iloc[1:, 0])self.image_arr = self.test_imageself.real_len = len(self.image_arr)print('Finished reading the {} set of Leaves Dataset ({} samples found)'.format(mode, self.real_len))def __getitem__(self, index):# 从 image_arr中得到索引对应的文件名single_image_name = self.image_arr[index]# 读取图像文件img_as_img = Image.open(self.file_path + single_image_name)#如果需要将RGB三通道的图片转换成灰度图片可参考下面两行
# if img_as_img.mode != 'L':
# img_as_img = img_as_img.convert('L')#设置好需要转换的变量,还可以包括一系列的nomarlize等等操作if self.mode == 'train':transform = transforms.Compose([transforms.Resize((224, 224)),transforms.RandomHorizontalFlip(p=0.5), #随机水平翻转 选择一个概率transforms.ToTensor()])else:# valid和test不做数据增强transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor()])img_as_img = transform(img_as_img)if self.mode == 'test':return img_as_imgelse:# 得到图像的 string labellabel = self.label_arr[index]# number labelnumber_label = class_to_num[label]return img_as_img, number_label #返回每一个index对应的图片数据和对应的labeldef __len__(self):return self.real_len
定义一下不同数据集的csv_path,并通过更改mode修改数据集类的实例对象。
train_path = '/content/drive/MyDrive/classify-leaves/train.csv'
test_path = '/content/drive/MyDrive/classify-leaves/test.csv'
# csv文件中已经images的路径了,因此这里只到上一级目录
img_path = '/content/drive/MyDrive/classify-leaves/'train_dataset = LeavesData(train_path, img_path, mode='train')
val_dataset = LeavesData(train_path, img_path, mode='valid')
test_dataset = LeavesData(test_path, img_path, mode='test')
print(train_dataset)
print(val_dataset)
print(test_dataset)
Finished reading the train set of Leaves Dataset (14681 samples found)
Finished reading the valid set of Leaves Dataset (3672 samples found)
Finished reading the test set of Leaves Dataset (8800 samples found)
<main.LeavesData object at 0x7f08e85cb790>
<main.LeavesData object at 0x7f08e85ddfd0>
<main.LeavesData object at 0x7f08e6c73f90>
定义data loader,设置batch_size。
# 定义data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=8, shuffle=False,num_workers=5)val_loader = torch.utils.data.DataLoader(dataset=val_dataset,batch_size=8, shuffle=False,num_workers=5)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=8, shuffle=False,num_workers=5)
User warning: This DataLoader will create 5 worker processes in total. Our suggested max number of worker in current system is 2, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
展示数据
# 给大家展示一下数据长啥样
def im_convert(tensor):""" 展示数据"""image = tensor.to("cpu").clone().detach()image = image.numpy().squeeze()image = image.transpose(1,2,0)image = image.clip(0, 1)return imagefig=plt.figure(figsize=(20, 12))
columns = 4
rows = 2dataiter = iter(val_loader)
inputs, classes = dataiter.next()for idx in range (columns*rows):ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[])ax.set_title(num_to_class[int(classes[idx])])plt.imshow(im_convert(inputs[idx]))
plt.show()
UserWarning: This DataLoader will create 5 worker processes in total. Our suggested max number of worker in current system is 2, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary. cpuset_checked))

# 看一下是在cpu还是GPU上
def get_device():return 'cuda' if torch.cuda.is_available() else 'cpu'device = get_device()
print(device)
cuda
# 是否要冻住模型的前面一些层
def set_parameter_requires_grad(model, feature_extracting):if feature_extracting:model = modelfor param in model.parameters():param.requires_grad = False
# resnet34模型
def res_model(num_classes, feature_extract = False, use_pretrained=True):model_ft = models.resnet34(pretrained=use_pretrained)set_parameter_requires_grad(model_ft, feature_extract)num_ftrs = model_ft.fc.in_featuresmodel_ft.fc = nn.Sequential(nn.Linear(num_ftrs, num_classes))return model_ft
# 超参数
learning_rate = 3e-4
weight_decay = 1e-3
num_epoch = 50
model_path = './pre_res_model.ckpt'
# Initialize a model, and put it on the device specified.
model = res_model(176)
model = model.to(device)
model.device = device
# For the classification task, we use cross-entropy as the measurement of performance.
criterion = nn.CrossEntropyLoss()# Initialize optimizer, you may fine-tune some hyperparameters such as learning rate on your own.
optimizer = torch.optim.Adam(model.parameters(), lr = learning_rate, weight_decay=weight_decay)# The number of training epochs.
n_epochs = num_epochbest_acc = 0.0
for epoch in range(n_epochs):# ---------- Training ----------# Make sure the model is in train mode before training.model.train() # These are used to record information in training.train_loss = []train_accs = []# Iterate the training set by batches.for batch in tqdm(train_loader):# A batch consists of image data and corresponding labels.imgs, labels = batchimgs = imgs.to(device)labels = labels.to(device)# Forward the data. (Make sure data and model are on the same device.)logits = model(imgs)# Calculate the cross-entropy loss.# We don't need to apply softmax before computing cross-entropy as it is done automatically.loss = criterion(logits, labels)# Gradients stored in the parameters in the previous step should be cleared out first.optimizer.zero_grad()# Compute the gradients for parameters.loss.backward()# Update the parameters with computed gradients.optimizer.step()# Compute the accuracy for current batch.acc = (logits.argmax(dim=-1) == labels).float().mean()# Record the loss and accuracy.train_loss.append(loss.item())train_accs.append(acc)# The average loss and accuracy of the training set is the average of the recorded values.train_loss = sum(train_loss) / len(train_loss)train_acc = sum(train_accs) / len(train_accs)# Print the information.print(f"[ Train | {epoch + 1:03d}/{n_epochs:03d} ] loss = {train_loss:.5f}, acc = {train_acc:.5f}")# ---------- Validation ----------# Make sure the model is in eval mode so that some modules like dropout are disabled and work normally.model.eval()# These are used to record information in validation.valid_loss = []valid_accs = []# Iterate the validation set by batches.for batch in tqdm(val_loader):imgs, labels = batch# We don't need gradient in validation.# Using torch.no_grad() accelerates the forward process.with torch.no_grad():logits = model(imgs.to(device))# We can still compute the loss (but not the gradient).loss = criterion(logits, labels.to(device))# Compute the accuracy for current batch.acc = (logits.argmax(dim=-1) == labels.to(device)).float().mean()# Record the loss and accuracy.valid_loss.append(loss.item())valid_accs.append(acc)# The average loss and accuracy for entire validation set is the average of the recorded values.valid_loss = sum(valid_loss) / len(valid_loss)valid_acc = sum(valid_accs) / len(valid_accs)# Print the information.print(f"[ Valid | {epoch + 1:03d}/{n_epochs:03d} ] loss = {valid_loss:.5f}, acc = {valid_acc:.5f}")# if the model improves, save a checkpoint at this epochif valid_acc > best_acc:best_acc = valid_acctorch.save(model.state_dict(), model_path)print('saving model with acc {:.3f}'.format(best_acc))
Downloading: “https://download.pytorch.org/models/resnet34-b627a593.pth” to /root/.cache/torch/hub/checkpoints/resnet34-b627a593.pth
100%
83.3M/83.3M [25:06<00:00, 58.0kB/s]
0%| | 0/1836 [00:00<?, ?it/s]/usr/local/lib/python3.7/dist-packages/torch/utils/data/dataloader.py:481: UserWarning: This DataLoader will create 5 worker processes in total. Our suggested max number of worker in current system is 2, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
cpuset_checked))
/usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /pytorch/c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
100%|██████████| 1836/1836 [29:49<00:00, 1.03it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 001/050 ] loss = 2.88494, acc = 0.29732
100%|██████████| 459/459 [07:19<00:00, 1.04it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 001/050 ] loss = 1.85143, acc = 0.44254
saving model with acc 0.443
100%|██████████| 1836/1836 [01:19<00:00, 23.16it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 002/050 ] loss = 1.62668, acc = 0.53425
100%|██████████| 459/459 [00:10<00:00, 44.53it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 002/050 ] loss = 1.39950, acc = 0.58170
saving model with acc 0.582
100%|██████████| 1836/1836 [01:19<00:00, 22.95it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 003/050 ] loss = 1.24036, acc = 0.63780
100%|██████████| 459/459 [00:10<00:00, 41.91it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 003/050 ] loss = 1.44742, acc = 0.59395
saving model with acc 0.594
100%|██████████| 1836/1836 [01:19<00:00, 22.96it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 004/050 ] loss = 1.02399, acc = 0.70023
100%|██████████| 459/459 [00:11<00:00, 41.64it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 004/050 ] loss = 1.16287, acc = 0.65550
saving model with acc 0.656
100%|██████████| 1836/1836 [01:20<00:00, 22.88it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 005/050 ] loss = 0.87128, acc = 0.74183
100%|██████████| 459/459 [00:10<00:00, 44.33it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 005/050 ] loss = 1.14484, acc = 0.67102
saving model with acc 0.671
100%|██████████| 1836/1836 [01:19<00:00, 23.00it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 006/050 ] loss = 0.74960, acc = 0.77805
100%|██████████| 459/459 [00:10<00:00, 44.43it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 006/050 ] loss = 1.21709, acc = 0.65033
100%|██████████| 1836/1836 [01:20<00:00, 22.87it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 007/050 ] loss = 0.67045, acc = 0.80726
100%|██████████| 459/459 [00:10<00:00, 42.45it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 007/050 ] loss = 1.02132, acc = 0.69336
saving model with acc 0.693
100%|██████████| 1836/1836 [01:19<00:00, 22.96it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 008/050 ] loss = 0.60571, acc = 0.82360
100%|██████████| 459/459 [00:10<00:00, 41.83it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 008/050 ] loss = 0.94301, acc = 0.71405
saving model with acc 0.714
100%|██████████| 1836/1836 [01:20<00:00, 22.92it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 009/050 ] loss = 0.54798, acc = 0.84654
100%|██████████| 459/459 [00:10<00:00, 44.57it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 009/050 ] loss = 1.00583, acc = 0.69989
100%|██████████| 1836/1836 [01:21<00:00, 22.65it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 010/050 ] loss = 0.50714, acc = 0.85743
100%|██████████| 459/459 [00:10<00:00, 44.41it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 010/050 ] loss = 0.97437, acc = 0.71732
saving model with acc 0.717
100%|██████████| 1836/1836 [01:20<00:00, 22.68it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 011/050 ] loss = 0.46519, acc = 0.87187
100%|██████████| 459/459 [00:10<00:00, 44.30it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 011/050 ] loss = 0.85209, acc = 0.74646
saving model with acc 0.746
100%|██████████| 1836/1836 [01:19<00:00, 22.97it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 012/050 ] loss = 0.43385, acc = 0.88126
100%|██████████| 459/459 [00:11<00:00, 41.42it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 012/050 ] loss = 0.93491, acc = 0.73883
100%|██████████| 1836/1836 [01:20<00:00, 22.85it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 013/050 ] loss = 0.43501, acc = 0.88242
100%|██████████| 459/459 [00:10<00:00, 43.96it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 013/050 ] loss = 1.04578, acc = 0.70234
100%|██████████| 1836/1836 [01:21<00:00, 22.52it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 014/050 ] loss = 0.38774, acc = 0.89985
100%|██████████| 459/459 [00:10<00:00, 44.30it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 014/050 ] loss = 0.93275, acc = 0.74237
100%|██████████| 1836/1836 [01:20<00:00, 22.92it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 015/050 ] loss = 0.38537, acc = 0.90039
100%|██████████| 459/459 [00:10<00:00, 44.22it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 015/050 ] loss = 0.78336, acc = 0.77179
saving model with acc 0.772
100%|██████████| 1836/1836 [01:20<00:00, 22.89it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 016/050 ] loss = 0.36106, acc = 0.90632
100%|██████████| 459/459 [00:10<00:00, 41.92it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 016/050 ] loss = 0.87527, acc = 0.74864
100%|██████████| 1836/1836 [01:20<00:00, 22.84it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 017/050 ] loss = 0.34255, acc = 0.91129
100%|██████████| 459/459 [00:10<00:00, 43.93it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 017/050 ] loss = 0.71106, acc = 0.77968
saving model with acc 0.780
100%|██████████| 1836/1836 [01:21<00:00, 22.64it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 018/050 ] loss = 0.33877, acc = 0.91306
100%|██████████| 459/459 [00:10<00:00, 43.65it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 018/050 ] loss = 0.84530, acc = 0.77042
100%|██████████| 1836/1836 [01:20<00:00, 22.76it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 019/050 ] loss = 0.33504, acc = 0.91333
100%|██████████| 459/459 [00:10<00:00, 44.42it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 019/050 ] loss = 0.73149, acc = 0.79194
saving model with acc 0.792
100%|██████████| 1836/1836 [01:21<00:00, 22.54it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 020/050 ] loss = 0.31704, acc = 0.91966
100%|██████████| 459/459 [00:11<00:00, 41.64it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 020/050 ] loss = 0.78000, acc = 0.78241
100%|██████████| 1836/1836 [01:20<00:00, 22.85it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 021/050 ] loss = 0.30846, acc = 0.92279
100%|██████████| 459/459 [00:11<00:00, 41.41it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 021/050 ] loss = 0.77147, acc = 0.77996
100%|██████████| 1836/1836 [01:20<00:00, 22.76it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 022/050 ] loss = 0.29753, acc = 0.92940
100%|██████████| 459/459 [00:10<00:00, 43.68it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 022/050 ] loss = 0.97358, acc = 0.73911
100%|██████████| 1836/1836 [01:20<00:00, 22.84it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 023/050 ] loss = 0.29279, acc = 0.92926
100%|██████████| 459/459 [00:10<00:00, 43.87it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 023/050 ] loss = 0.84524, acc = 0.76471
100%|██████████| 1836/1836 [01:20<00:00, 22.85it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 024/050 ] loss = 0.29530, acc = 0.92776
100%|██████████| 459/459 [00:11<00:00, 39.90it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 024/050 ] loss = 0.92027, acc = 0.75054
100%|██████████| 1836/1836 [01:20<00:00, 22.75it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 025/050 ] loss = 0.28310, acc = 0.92960
100%|██████████| 459/459 [00:11<00:00, 41.53it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 025/050 ] loss = 0.82169, acc = 0.77342
100%|██████████| 1836/1836 [01:20<00:00, 22.78it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 026/050 ] loss = 0.28442, acc = 0.93076
100%|██████████| 459/459 [00:10<00:00, 43.48it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 026/050 ] loss = 0.67502, acc = 0.79902
saving model with acc 0.799
100%|██████████| 1836/1836 [01:19<00:00, 22.97it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 027/050 ] loss = 0.25820, acc = 0.94016
100%|██████████| 459/459 [00:10<00:00, 44.15it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 027/050 ] loss = 1.05258, acc = 0.71514
100%|██████████| 1836/1836 [01:20<00:00, 22.72it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 028/050 ] loss = 0.27306, acc = 0.93498
100%|██████████| 459/459 [00:11<00:00, 41.43it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 028/050 ] loss = 0.74109, acc = 0.79194
100%|██████████| 1836/1836 [01:20<00:00, 22.72it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 029/050 ] loss = 0.25399, acc = 0.94022
100%|██████████| 459/459 [00:11<00:00, 41.59it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 029/050 ] loss = 0.74668, acc = 0.79956
saving model with acc 0.800
100%|██████████| 1836/1836 [01:20<00:00, 22.75it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 030/050 ] loss = 0.26396, acc = 0.93566
100%|██████████| 459/459 [00:10<00:00, 43.71it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 030/050 ] loss = 0.80433, acc = 0.77669
100%|██████████| 1836/1836 [01:20<00:00, 22.84it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 031/050 ] loss = 0.25115, acc = 0.94063
100%|██████████| 459/459 [00:10<00:00, 43.26it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 031/050 ] loss = 0.66077, acc = 0.81427
saving model with acc 0.814
100%|██████████| 1836/1836 [01:20<00:00, 22.69it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 032/050 ] loss = 0.24273, acc = 0.94553
100%|██████████| 459/459 [00:10<00:00, 41.88it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 032/050 ] loss = 0.93427, acc = 0.74129
100%|██████████| 1836/1836 [01:20<00:00, 22.68it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 033/050 ] loss = 0.24818, acc = 0.94322
100%|██████████| 459/459 [00:11<00:00, 41.72it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 033/050 ] loss = 0.76651, acc = 0.78431
100%|██████████| 1836/1836 [01:20<00:00, 22.77it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 034/050 ] loss = 0.24138, acc = 0.94329
100%|██████████| 459/459 [00:10<00:00, 43.85it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 034/050 ] loss = 0.93631, acc = 0.72903
100%|██████████| 1836/1836 [01:20<00:00, 22.68it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 035/050 ] loss = 0.24026, acc = 0.94390
100%|██████████| 459/459 [00:10<00:00, 42.41it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 035/050 ] loss = 0.65207, acc = 0.82271
saving model with acc 0.823
100%|██████████| 1836/1836 [01:21<00:00, 22.39it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 036/050 ] loss = 0.24207, acc = 0.94485
100%|██████████| 459/459 [00:10<00:00, 44.10it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 036/050 ] loss = 0.67647, acc = 0.80855
100%|██████████| 1836/1836 [01:20<00:00, 22.70it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 037/050 ] loss = 0.23292, acc = 0.94805
100%|██████████| 459/459 [00:11<00:00, 41.70it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 037/050 ] loss = 0.71829, acc = 0.80365
100%|██████████| 1836/1836 [01:20<00:00, 22.83it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 038/050 ] loss = 0.22858, acc = 0.94778
100%|██████████| 459/459 [00:10<00:00, 43.45it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 038/050 ] loss = 0.85242, acc = 0.76961
100%|██████████| 1836/1836 [01:20<00:00, 22.81it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 039/050 ] loss = 0.21976, acc = 0.95098
100%|██████████| 459/459 [00:10<00:00, 41.77it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 039/050 ] loss = 0.65653, acc = 0.82108
100%|██████████| 1836/1836 [01:20<00:00, 22.77it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 040/050 ] loss = 0.23334, acc = 0.94669
100%|██████████| 459/459 [00:10<00:00, 43.96it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 040/050 ] loss = 0.85666, acc = 0.76225
100%|██████████| 1836/1836 [01:20<00:00, 22.68it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 041/050 ] loss = 0.21785, acc = 0.95275
100%|██████████| 459/459 [00:11<00:00, 41.72it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 041/050 ] loss = 0.67848, acc = 0.81481
100%|██████████| 1836/1836 [01:20<00:00, 22.79it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 042/050 ] loss = 0.22512, acc = 0.95071
100%|██████████| 459/459 [00:10<00:00, 43.75it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 042/050 ] loss = 0.68756, acc = 0.81209
100%|██████████| 1836/1836 [01:21<00:00, 22.55it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 043/050 ] loss = 0.20363, acc = 0.95724
100%|██████████| 459/459 [00:10<00:00, 43.42it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 043/050 ] loss = 0.63618, acc = 0.82435
saving model with acc 0.824
100%|██████████| 1836/1836 [01:20<00:00, 22.78it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 044/050 ] loss = 0.22648, acc = 0.95180
100%|██████████| 459/459 [00:10<00:00, 42.78it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 044/050 ] loss = 0.79378, acc = 0.78758
100%|██████████| 1836/1836 [01:20<00:00, 22.79it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 045/050 ] loss = 0.21423, acc = 0.95466
100%|██████████| 459/459 [00:10<00:00, 41.88it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 045/050 ] loss = 0.75594, acc = 0.79003
100%|██████████| 1836/1836 [01:20<00:00, 22.86it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 046/050 ] loss = 0.20894, acc = 0.95350
100%|██████████| 459/459 [00:10<00:00, 43.71it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 046/050 ] loss = 0.67508, acc = 0.81699
100%|██████████| 1836/1836 [01:21<00:00, 22.60it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 047/050 ] loss = 0.21762, acc = 0.95302
100%|██████████| 459/459 [00:10<00:00, 43.69it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 047/050 ] loss = 0.75096, acc = 0.79439
100%|██████████| 1836/1836 [01:20<00:00, 22.69it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 048/050 ] loss = 0.19921, acc = 0.95881
100%|██████████| 459/459 [00:11<00:00, 41.06it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 048/050 ] loss = 1.03199, acc = 0.72386
100%|██████████| 1836/1836 [01:22<00:00, 22.31it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 049/050 ] loss = 0.21469, acc = 0.95527
100%|██████████| 459/459 [00:10<00:00, 42.83it/s]
0%| | 0/1836 [00:00<?, ?it/s][ Valid | 049/050 ] loss = 0.66678, acc = 0.80664
100%|██████████| 1836/1836 [01:21<00:00, 22.61it/s]
0%| | 0/459 [00:00<?, ?it/s][ Train | 050/050 ] loss = 0.20026, acc = 0.95861
100%|██████████| 459/459 [00:10<00:00, 41.93it/s][ Valid | 050/050 ] loss = 0.81344, acc = 0.77451
saveFileName = '/content/drive/MyDrive/classify-leaves/submission.csv'
## predict
model = res_model(176)# create model and load weights from checkpoint
model = model.to(device)
model.load_state_dict(torch.load(model_path))# Make sure the model is in eval mode.
# Some modules like Dropout or BatchNorm affect if the model is in training mode.
model.eval()# Initialize a list to store the predictions.
predictions = []
# Iterate the testing set by batches.
for batch in tqdm(test_loader):imgs = batchwith torch.no_grad():logits = model(imgs.to(device))# Take the class with greatest logit as prediction and record it.predictions.extend(logits.argmax(dim=-1).cpu().numpy().tolist())preds = []
for i in predictions:preds.append(num_to_class[i])test_data = pd.read_csv(test_path)
test_data['label'] = pd.Series(preds)
submission = pd.concat([test_data['image'], test_data['label']], axis=1)
submission.to_csv(saveFileName, index=False)
print("Done!!!!!!!!!!!!!!!!!!!!!!!!!!!")
0%| | 0/1100 [00:00<?, ?it/s]
UserWarning: This DataLoader will create 5 worker processes in total. Our suggested max number of worker in current system is 2, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
cpuset_checked))
100%|██████████| 1100/1100 [00:23<00:00, 47.40it/s]
Done!!!