Python爬虫教程:如何使用Python爬取电影信息
在数字化时代,海量的影视资源唾手可得,但是当你需要获取特定类型的影视资源时,如同针在海底,费力费时。Python作为一种高效易用的编程语言,可以让你轻松爬取电影信息,无需费时费力手动搜索。本文将讲解如何使用Python爬虫爬取电影信息。
1. 准备工作
在使用Python爬取电影信息之前,我们需要准备以下工具:
- Python解释器
- Requests库
- BeautifulSoup库
- lxml库
- Chrome浏览器
安装方法:
# 安装requests库
pip install requests# 安装BeautifulSoup库
pip install beautifulsoup4# 安装lxml库
pip install lxml
Chrome浏览器用户需要下载ChromeDriver驱动。注意下载对应的版本。下载地址:https://sites.google.com/a/chromium.org/chromedriver/downloads
2. 爬虫实现
在我们开始爬虫之前,我们需要确定哪个网站需要爬取。在这里我们以豆瓣电影为例,获取TOP250电影信息。首先,我们需要找到电影信息的URL,可以通过浏览器调试工具查看。
2.1 确定URL
豆瓣电影TOP250的URL为:https://movie.douban.com/top250?start=0&filter=
2.2 发送请求
我们使用requests库发送HTTP GET请求获取网页内容。
import requestsurl = "https://movie.douban.com/top250?start=0&filter="
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"}
response = requests.get(url, headers=headers)
其中,headers是HTTP请求头,用于伪装成浏览器发送请求,防止被网站识别为爬虫。
2.3 解析网页
我们使用BeautifulSoup库解析HTML网页。
from bs4 import BeautifulSoupsoup = BeautifulSoup(response.content, "lxml")
2.4 分析网页结构
我们使用Chrome浏览器的开发工具观察网页结构,找到需要爬取的信息所在的HTML标签。
在豆瓣TOP250电影列表中,电影信息包含在类名为grid_view的<ol>标签中。每个电影信息使用类名为item的<li>标签包含。
在每个<li>标签中包含了电影的排名、电影名称、电影评分等信息。我们需要找到每个电影信息对应的HTML标签。
<ol class="grid_view"><li><div class="item"><div class="pic"><em class="">1</em><a href="https://movie.douban.com/subject/1292052/"><img alt="肖申克的救赎" class="" src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" width="100"/></a></div><div class="info"><div class="hd"><a href="https://movie.douban.com/subject/1292052/" class=""><span class="title">肖申克的救赎</span><span class="title"> / The Shawshank Redemption</span><span class="other"> / 月黑高飞(港) / 刺激1995(台)</span></a><span class="playable">[可播放]</span> </div><div class="bd"><p class="">导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br>1994 / 美国 / 犯罪 剧情 </p><div class="star"><span class="rating_num" property="v:average">9.7</span><span property="v:best" content="10.0"></span><span>1831175人评价</span></div></div></div></div></li>
</ol>
2.5 解析电影信息
我们使用BeautifulSoup库解析HTML标签,获取每个电影信息。
# 找到电影列表
movie_list = soup.find("ol", class_="grid_view")# 遍历每个电影信息
for movie in movie_list.find_all("li"):# 获取电影排名rank = movie.find("em").text# 获取电影名称和评分title = movie.find("span", class_="title").textrating = movie.find("span", class_="rating_num").textprint("排名:{}\n电影名:{}\n评分:{}\n".format(rank, title, rating))
3. 结论
以上是使用Python爬虫爬取豆瓣电影TOP250的介绍。通过本文,你将学会使用Python爬虫,获取电影信息。建议在编写爬虫时,尊重网站版权,不要过于频繁地请求同一个网站,遵守robots协议,保护自己和网站的合法权益。
最后的最后
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。
对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。
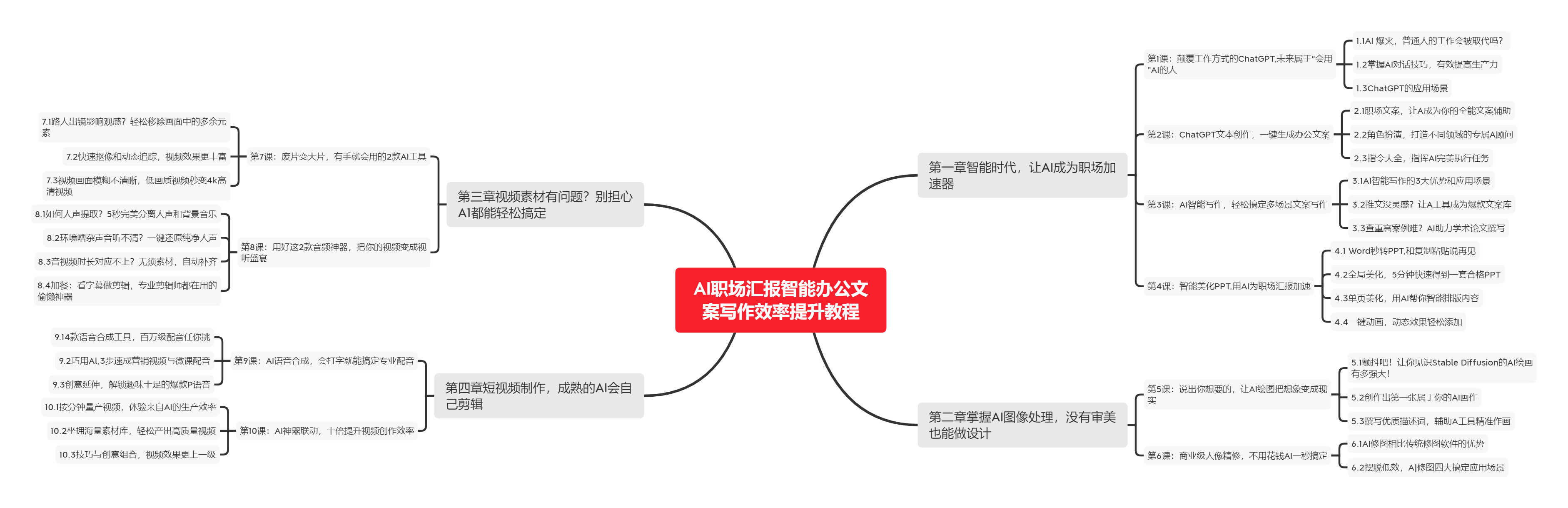
🧡AI职场汇报智能办公文案写作效率提升教程 🧡 专注于AI+职场+办公方向。
下图是课程的整体大纲

下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具

🚀 优质教程分享 🚀
- 🎄可以学习更多的关于人工只能/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 AI职场汇报智能办公文案写作效率提升教程 🧡 | 进阶级 | 本课程是AI+职场+办公的完美结合,通过ChatGPT文本创作,一键生成办公文案,结合AI智能写作,轻松搞定多场景文案写作。智能美化PPT,用AI为职场汇报加速。AI神器联动,十倍提升视频创作效率 |
| 💛Python量化交易实战 💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |