目录
1.简介
2.RepVGG详情
2.1 RepVGG Block
2.2 结构重参数化
2.2.1融合Conv2d和BN,将三个分支上的卷积算子和BN算子都转化为卷积算子(包括卷积核和偏置)
2.2.2 将每个分支都扩充为一个3x3卷积核加一个偏置,然后进行相加融合。
3.多种配置
4.RepVGG模型代码(已经对其中的各个模块的功能进行注释)
1.简介
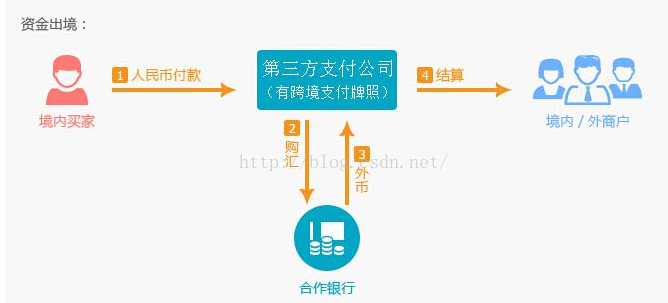
主要创新点为结构重参数化。在训练时,网络的结构是多分支进行的,而在推理时则将分支的参数进行重参数化,合为一个分支来进行的,所以推理的速度要比多分支网络快很多,并且精度也比单分支的网络更高。
2.RepVGG详情
2.1 RepVGG Block
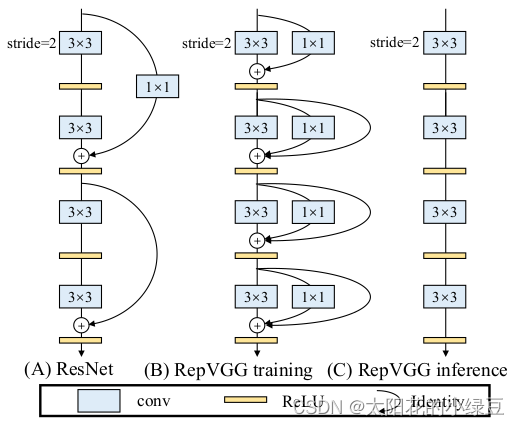
整个RepVGG网络结构很简单,就是不断地堆叠RepVGG Block,所以了解了RepVGG Block就基本了解了整个RepVGG网络结构。下图中,左图为stride=2进行下采样时的RepVGG Block结构,右图为stride=1时的RepVGG Block结构。可以看到一般不进行下采样时,RepVGG Block有三个分支,分别是卷积核为3x3的主分支、卷积核为1x1的shortcut分支和只含BN层的shortcut分支。

这里有几个问题,
一、为什么多分支结构的精度会比单分支高?
二、为什么单分支结构会比多分支结构速度快了将近一倍?
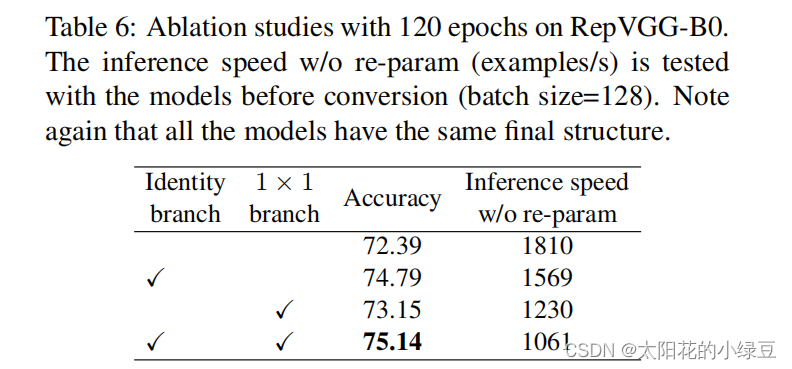
先来说第一个问题,为什么多分支结构的精度会比单分支高?因为之前的模型像Inception系列、ResNet以及DenseNet等模型,我们能够发现这些模型都并行了多个分支。至少根据现有的一些经验来看,并行多个分支一般能够增加模型的表征能力。在论文的表6中,作者也做了个简单的消融实验,证明了增加分支是能够提升精度的。
接着是第二个问题,为什么单分支结构会比多分支结构速度快了将近一倍?根据论文
3.1章节的内容可知,采用单路模型会更快、更省内存并且更加的灵活。
更快:主要是考虑到模型在推理时硬件计算的并行程度以及MAC(memory access cost),对于多分支模型,硬件需要分别计算每个分支的结果,有的分支计算的快,有的分支计算的慢,而计算快的分支计算完后只能干等着,等其他分支都计算完后才能做进一步融合,这样会导致硬件算力不能充分利用,或者说并行度不够高。而且每个分支都需要去访问一次内存,计算完后还需要将计算结果存入内存(不断地访问和写入内存会在IO上浪费很多时间)。
但是这里的说法又有一个问题,在结构重参数化之前,最耗时的是3x3卷积的时间,1x1卷积和恒等映射的时间比较短,需要等3x3的卷积时间结束之后,才继续走下一个模块,所以应该可以理解成,重参数化之前的时间其实就是一个3x3卷积操作的时间加上三个分支融合的时间呢?然而在重参数化之后,3x3卷积还是存在的,所以总的时间还是3x3卷积的时间,也就是说,结构重参数化之后所节省的时间仅仅只是一个三分支融合的时间,但是为什么最后的结果却节省了将近一倍的时间,这里不太理解。
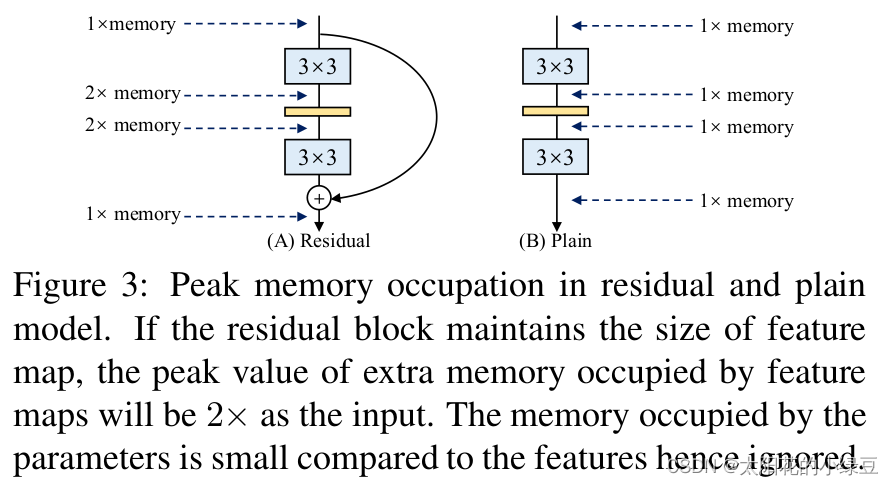
更省内存:在论文的图3当中,作者举了个例子,如图(A)所示的Residual模块,假设卷积层不改变channel的数量,那么在主分支和shortcut分支上都要保存各自的特征图或者称Activation,那么在add操作前占用的内存大概是输入Activation的两倍,而图(B)的Plain结构占用内存始终不变。
更加灵活:作者在论文中提到了模型优化的剪枝问题,对于多分支的模型,结构限制较多剪枝很麻烦,而对于Plain结构的模型就相对灵活很多,剪枝也更加方便。
除此之外,在多分支转化成单路模型后很多算子进行了融合(比如Conv2d和BN融合),使得计算量变小了,而且算子减少后启动kernel的次数也减少了(比如在GPU中,每次执行一个算子就要启动一次kernel,启动kernel也需要消耗时间)。而且现在的硬件一般对3x3的卷积操作做了大量的优化,转成单路模型后采用的都是3x3卷积,这样也能进一步加速推理。
2.2 结构重参数化
在了解了RepVGG Block后就到了这篇文章最重要的、也是最核心的部分,结构重参数化。也就是如何将三个分支的内容最后融合到一个主分支当中。
这个过程主要分为两步,
一、将三个分支中的卷积算子和BN算子都融合为卷积算子(一个卷积核加一个偏置的形式)
二、将三个分支上的卷积算子都化为3x3卷积核和偏置的形式,相加得到最终的主分支上的结果。
下图就能完美体现这两个过程
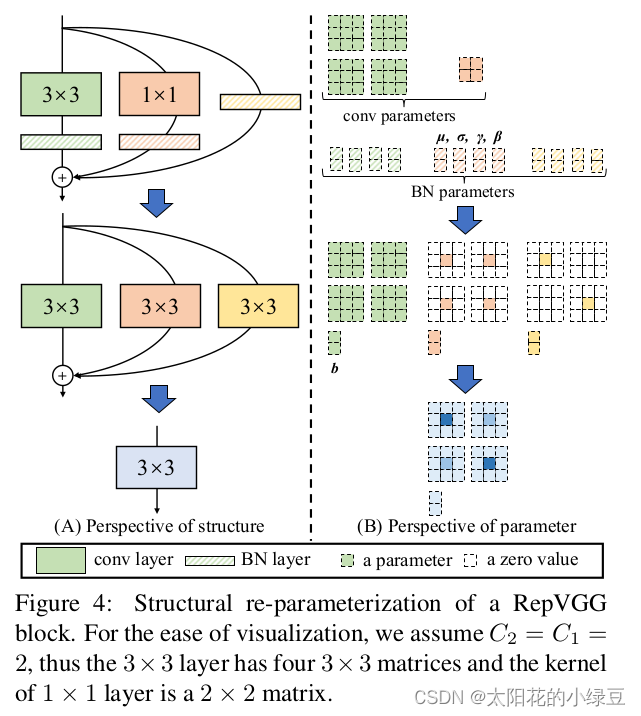
2.2.1融合Conv2d和BN,将三个分支上的卷积算子和BN算子都转化为卷积算子(包括卷积核和偏置)
因为Conv2d和BN两个算子都是做线性运算,所以可以融合成一个算子。如果不了解卷积层的计算过程以及BN的计算过程的话建议先了解后再看该部分的内容。这里还需要强调一点,融合是在网络训练完之后做的,所以现在讲的默认都是推理模式,注意BN在训练以及推理时计算方式是不同的。
对于特征图第i个通道BN的计算公式如下(推理模式),主要包含4个参数:μ(均值)、σ^2(方差)、γ和β,其中μ和σ^2是训练过程中统计得到的,γ和β是训练学习得到的,ϵ是一个非常小的常量,防止分母为零。
![]()
首先是BN的转换公式,对于通道 i 来说,其中M代表的是输入BN层的特征图,这里忽略了ϵ。
![]()
将上式展开后,我们知道其中的Mi其实就是第i个通道的特征图,而输入BN的特征图是通过卷积层得到的,所以M也可以写成输入卷积层的特征图与卷积核乘积的形式。所以可以得到下式,
![]()
其中W′ 和b ′ 是新的权重和偏置。假设M=x(特征图每个像素值)*W(卷积核权重值),那么M*(γ/σ)就等价于x*(W*γ/σ),也就是把卷积核中每个值都乘以γ/σ。偏置bi就为剩下的常数部分了。
通过这一步我们就得到了主分支上新的3x3卷积核和一个偏置、第二分支上新的1x1卷积核和偏置、第三分支上的偏置了。
2.2.2 将每个分支都扩充为一个3x3卷积核加一个偏置,然后进行相加融合。
首先主分支本身就是3x3卷积核,所以不需要变化。
1x1的卷积核在外面一圈补0,就变成了3x3的卷积核。注意,为了保证输入输出特征图高宽不变,此时需要将padding设置成1(原来卷积核大小为1x1时padding为0)。
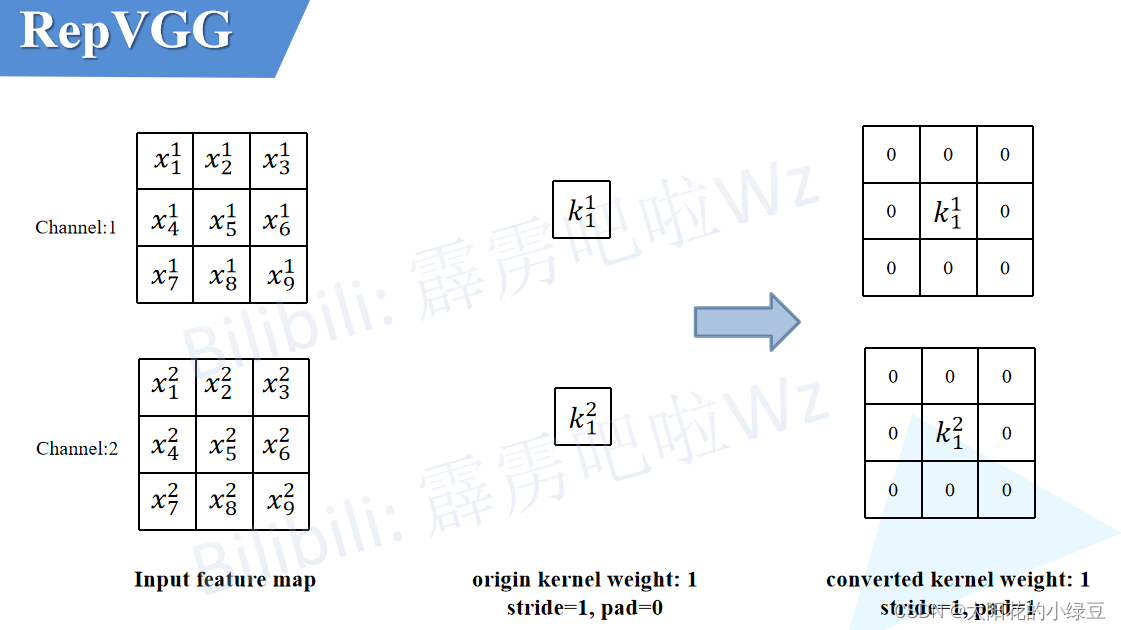
最后的BN层本身没有卷积核,我们就添加一个只进行恒等映射的3x3卷积核,使输入输出特征图不变。
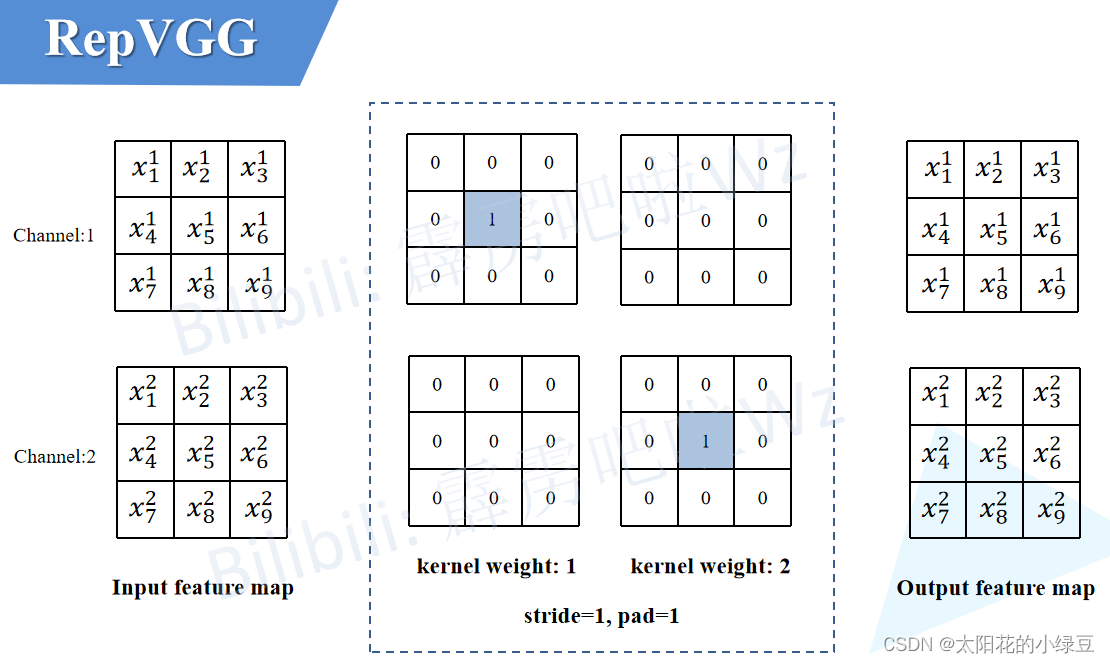
最后将这三个分支的卷积层参数和偏置分别相加就完成和结构重参数化了。

最后再看看这张图理解一下
3.多种配置
在论文中对模型进一步细分有RepVGG-A、RepVGG-B以及RepVGG-Bxgy三种配置。
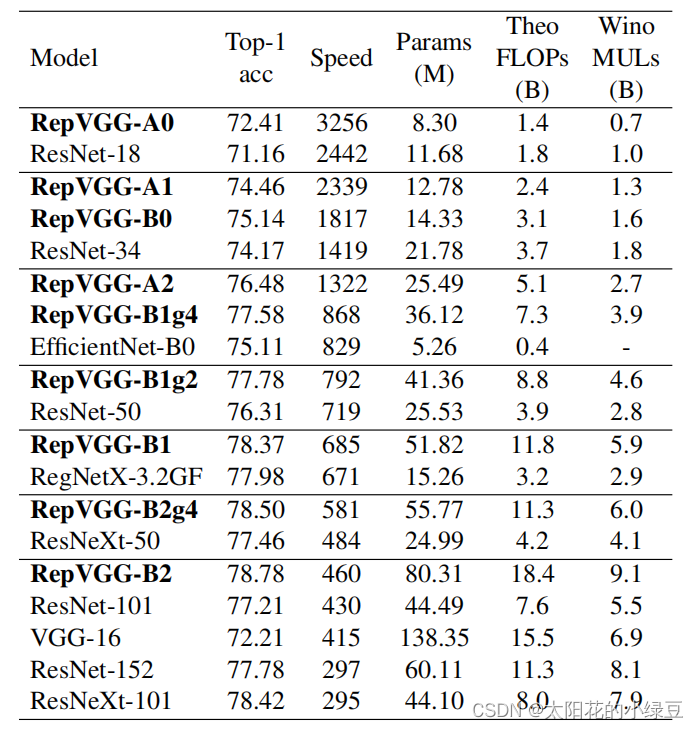
根据下表2可以看出RepVGG-B比RepVGG-A要更深。可以细看这两种配置在每个stage重复block的次数。RepVGG-A中的base Layers of each stage为1, 2, 3, 14, 1而RepVGG-B中的base Layers of each stage为1, 4, 6, 16, 1,更加详细的模型配置可以看下表3. 其中a代表模型stage2~4的宽度缩放因子,b代表模型最后一个stage的宽度缩放因子。

其中RepVGG-Bxgy配置是在RepVGG-B的基础上加入了组卷积(Group Convolution),其中gy表示组卷积采用的groups参数为y,注意并不是所有卷积层都采用组卷积,根据源码可以看到,是从Stage2开始(索引从1开始)的第2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26的卷积层采用组卷积。
4.RepVGG模型代码(已经对其中的各个模块的功能进行注释)
# --------------------------------------------------------
# RepVGG: Making VGG-style ConvNets Great Again (https://openaccess.thecvf.com/content/CVPR2021/papers/Ding_RepVGG_Making_VGG-Style_ConvNets_Great_Again_CVPR_2021_paper.pdf)
# Github source: https://github.com/DingXiaoH/RepVGG
# Licensed under The MIT License [see LICENSE for details]
# --------------------------------------------------------
import torch.nn as nn
import numpy as np
import torch
import copy
from se_block import SEBlock
import torch.utils.checkpoint as checkpointdef conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):# 该模块负责建立一个卷积层和BN层result = nn.Sequential()result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,kernel_size=kernel_size, stride=stride, padding=padding, groups=groups, bias=False))result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))return resultclass RepVGGBlock(nn.Module):# 该模块用来产生RepVGGBlock,当deploy=False时,产生三个分支,当deploy=True时,产生一个结构重参数化后的卷积和偏置def __init__(self, in_channels, out_channels, kernel_size,stride=1, padding=0, dilation=1, groups=1, padding_mode='zeros', deploy=False, use_se=False):super(RepVGGBlock, self).__init__()self.deploy = deployself.groups = groupsself.in_channels = in_channelsassert kernel_size == 3assert padding == 1padding_11 = padding - kernel_size // 2self.nonlinearity = nn.ReLU()if use_se:# Note that RepVGG-D2se uses SE before nonlinearity. But RepVGGplus models uses SE after nonlinearity.self.se = SEBlock(out_channels, internal_neurons=out_channels // 16)else:self.se = nn.Identity()if deploy:# 当deploy=True时,产生一个结构重参数化后的卷积和偏置self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,padding=padding, dilation=dilation, groups=groups, bias=True, padding_mode=padding_mode)else:# 当deploy=False时,产生三个分支self.rbr_identity = nn.BatchNorm2d(num_features=in_channels) if out_channels == in_channels and stride == 1 else Noneself.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, groups=groups)self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride, padding=padding_11, groups=groups)print('RepVGG Block, identity = ', self.rbr_identity)def forward(self, inputs):# 当结构重参数化时,卷积和偏置之后跟上一个SE模块和非线性激活模块if hasattr(self, 'rbr_reparam'):return self.nonlinearity(self.se(self.rbr_reparam(inputs)))# 如果没有线性映射shortcut时,则第三个分支输出为0if self.rbr_identity is None:id_out = 0else:id_out = self.rbr_identity(inputs)# 训练时输出为三个分支输出结果相加,再加上SE模块和非线性激活return self.nonlinearity(self.se(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out))# Optional. This may improve the accuracy and facilitates quantization in some cases.# 1. Cancel the original weight decay on rbr_dense.conv.weight and rbr_1x1.conv.weight.# 2. Use like this.# loss = criterion(....)# for every RepVGGBlock blk:# loss += weight_decay_coefficient * 0.5 * blk.get_cust_L2()# optimizer.zero_grad()# loss.backward()def get_custom_L2(self):K3 = self.rbr_dense.conv.weightK1 = self.rbr_1x1.conv.weightt3 = (self.rbr_dense.bn.weight / ((self.rbr_dense.bn.running_var + self.rbr_dense.bn.eps).sqrt())).reshape(-1, 1, 1, 1).detach()t1 = (self.rbr_1x1.bn.weight / ((self.rbr_1x1.bn.running_var + self.rbr_1x1.bn.eps).sqrt())).reshape(-1, 1, 1, 1).detach()l2_loss_circle = (K3 ** 2).sum() - (K3[:, :, 1:2, 1:2] ** 2).sum() # The L2 loss of the "circle" of weights in 3x3 kernel. Use regular L2 on them.eq_kernel = K3[:, :, 1:2, 1:2] * t3 + K1 * t1 # The equivalent resultant central point of 3x3 kernel.l2_loss_eq_kernel = (eq_kernel ** 2 / (t3 ** 2 + t1 ** 2)).sum() # Normalize for an L2 coefficient comparable to regular L2.return l2_loss_eq_kernel + l2_loss_circle# This func derives the equivalent kernel and bias in a DIFFERENTIABLE way.
# You can get the equivalent kernel and bias at any time and do whatever you want,# for example, apply some penalties or constraints during training, just like you do to the other models.
# May be useful for quantization or pruning.def get_equivalent_kernel_bias(self):# 用来将三个分支中的卷积算子和BN算子都转化为3x3卷积算子和偏置,然后将3x3卷积核参数相加,偏置相加kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)# 输出将三个分支转化后的的3x3卷积核参数相加,偏置相加return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasiddef _pad_1x1_to_3x3_tensor(self, kernel1x1):# 将第二个分支中的1x1卷积核padding为3x3的卷积核if kernel1x1 is None:return 0else:return torch.nn.functional.pad(kernel1x1, [1,1,1,1])def _fuse_bn_tensor(self, branch):# 将BN层的算子转化为卷积核的乘积和偏置if branch is None:return 0, 0# 当输入的分支是序列时,记录该分支的卷积核参数、BN的均值、方差、gamma、beta和eps(一个非常小的数)if isinstance(branch, nn.Sequential):kernel = branch.conv.weightrunning_mean = branch.bn.running_meanrunning_var = branch.bn.running_vargamma = branch.bn.weightbeta = branch.bn.biaseps = branch.bn.eps# 当输入是第三个分支只有BN层时,添加一个只进行线性映射的3x3卷积核和一个偏置else:assert isinstance(branch, nn.BatchNorm2d)if not hasattr(self, 'id_tensor'):input_dim = self.in_channels // self.groupskernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)for i in range(self.in_channels):kernel_value[i, i % input_dim, 1, 1] = 1self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)kernel = self.id_tensorrunning_mean = branch.running_meanrunning_var = branch.running_vargamma = branch.weightbeta = branch.biaseps = branch.epsstd = (running_var + eps).sqrt()t = (gamma / std).reshape(-1, 1, 1, 1)# 输出新的卷积核参数(kernel * t),新的偏置(beta - running_mean * gamma / std)return kernel * t, beta - running_mean * gamma / stddef switch_to_deploy(self):# 该模块用来进行结构重参数化,输出由三个分支重参数化后的只含有主分支的blockif hasattr(self, 'rbr_reparam'):returnkernel, bias = self.get_equivalent_kernel_bias()self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels, out_channels=self.rbr_dense.conv.out_channels,kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation, groups=self.rbr_dense.conv.groups, bias=True)self.rbr_reparam.weight.data = kernelself.rbr_reparam.bias.data = bias# 用self.__delattr__删除掉之前的旧的三个分支self.__delattr__('rbr_dense')self.__delattr__('rbr_1x1')if hasattr(self, 'rbr_identity'):self.__delattr__('rbr_identity')if hasattr(self, 'id_tensor'):self.__delattr__('id_tensor')self.deploy = Trueclass RepVGG(nn.Module):# RepVGG网络def __init__(self, num_blocks, num_classes=1000, width_multiplier=None, override_groups_map=None, deploy=False, use_se=False, use_checkpoint=False):super(RepVGG, self).__init__()assert len(width_multiplier) == 4self.deploy = deployself.override_groups_map = override_groups_map or dict()assert 0 not in self.override_groups_mapself.use_se = use_seself.use_checkpoint = use_checkpointself.in_planes = min(64, int(64 * width_multiplier[0]))self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2, padding=1, deploy=self.deploy, use_se=self.use_se)self.cur_layer_idx = 1self.stage1 = self._make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride=2)self.stage2 = self._make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride=2)self.stage3 = self._make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride=2)self.stage4 = self._make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride=2)self.gap = nn.AdaptiveAvgPool2d(output_size=1)self.linear = nn.Linear(int(512 * width_multiplier[3]), num_classes)def _make_stage(self, planes, num_blocks, stride):strides = [stride] + [1]*(num_blocks-1)blocks = []for stride in strides:cur_groups = self.override_groups_map.get(self.cur_layer_idx, 1)blocks.append(RepVGGBlock(in_channels=self.in_planes, out_channels=planes, kernel_size=3,stride=stride, padding=1, groups=cur_groups, deploy=self.deploy, use_se=self.use_se))self.in_planes = planesself.cur_layer_idx += 1return nn.ModuleList(blocks)def forward(self, x):out = self.stage0(x)for stage in (self.stage1, self.stage2, self.stage3, self.stage4):for block in stage:if self.use_checkpoint:out = checkpoint.checkpoint(block, out)else:out = block(out)out = self.gap(out)out = out.view(out.size(0), -1)out = self.linear(out)return out# 只在以下layers进行组卷积
optional_groupwise_layers = [2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26]
g2_map = {l: 2 for l in optional_groupwise_layers}
g4_map = {l: 4 for l in optional_groupwise_layers}def create_RepVGG_A0(deploy=False, use_checkpoint=False):return RepVGG(num_blocks=[2, 4, 14, 1], num_classes=1000,width_multiplier=[0.75, 0.75, 0.75, 2.5], override_groups_map=None, deploy=deploy, use_checkpoint=use_checkpoint)def create_RepVGG_A1(deploy=False, use_checkpoint=False):return RepVGG(num_blocks=[2, 4, 14, 1], num_classes=1000,width_multiplier=[1, 1, 1, 2.5], override_groups_map=None, deploy=deploy, use_checkpoint=use_checkpoint)def create_RepVGG_A2(deploy=False, use_checkpoint=False):return RepVGG(num_blocks=[2, 4, 14, 1], num_classes=1000,width_multiplier=[1.5, 1.5, 1.5, 2.75], override_groups_map=None, deploy=deploy, use_checkpoint=use_checkpoint)def create_RepVGG_B0(deploy=False, use_checkpoint=False):return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,width_multiplier=[1, 1, 1, 2.5], override_groups_map=None, deploy=deploy, use_checkpoint=use_checkpoint)def create_RepVGG_B1(deploy=False, use_checkpoint=False):return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,width_multiplier=[2, 2, 2, 4], override_groups_map=None, deploy=deploy, use_checkpoint=use_checkpoint)def create_RepVGG_B1g2(deploy=False, use_checkpoint=False):return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,width_multiplier=[2, 2, 2, 4], override_groups_map=g2_map, deploy=deploy, use_checkpoint=use_checkpoint)def create_RepVGG_B1g4(deploy=False, use_checkpoint=False):return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,width_multiplier=[2, 2, 2, 4], override_groups_map=g4_map, deploy=deploy, use_checkpoint=use_checkpoint)def create_RepVGG_B2(deploy=False, use_checkpoint=False):return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=None, deploy=deploy, use_checkpoint=use_checkpoint)def create_RepVGG_B2g2(deploy=False, use_checkpoint=False):return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=g2_map, deploy=deploy, use_checkpoint=use_checkpoint)def create_RepVGG_B2g4(deploy=False, use_checkpoint=False):return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=g4_map, deploy=deploy, use_checkpoint=use_checkpoint)def create_RepVGG_B3(deploy=False, use_checkpoint=False):return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,width_multiplier=[3, 3, 3, 5], override_groups_map=None, deploy=deploy, use_checkpoint=use_checkpoint)def create_RepVGG_B3g2(deploy=False, use_checkpoint=False):return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,width_multiplier=[3, 3, 3, 5], override_groups_map=g2_map, deploy=deploy, use_checkpoint=use_checkpoint)def create_RepVGG_B3g4(deploy=False, use_checkpoint=False):return RepVGG(num_blocks=[4, 6, 16, 1], num_classes=1000,width_multiplier=[3, 3, 3, 5], override_groups_map=g4_map, deploy=deploy, use_checkpoint=use_checkpoint)def create_RepVGG_D2se(deploy=False, use_checkpoint=False):return RepVGG(num_blocks=[8, 14, 24, 1], num_classes=1000,width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=None, deploy=deploy, use_se=True, use_checkpoint=use_checkpoint)func_dict = {
'RepVGG-A0': create_RepVGG_A0,
'RepVGG-A1': create_RepVGG_A1,
'RepVGG-A2': create_RepVGG_A2,
'RepVGG-B0': create_RepVGG_B0,
'RepVGG-B1': create_RepVGG_B1,
'RepVGG-B1g2': create_RepVGG_B1g2,
'RepVGG-B1g4': create_RepVGG_B1g4,
'RepVGG-B2': create_RepVGG_B2,
'RepVGG-B2g2': create_RepVGG_B2g2,
'RepVGG-B2g4': create_RepVGG_B2g4,
'RepVGG-B3': create_RepVGG_B3,
'RepVGG-B3g2': create_RepVGG_B3g2,
'RepVGG-B3g4': create_RepVGG_B3g4,
'RepVGG-D2se': create_RepVGG_D2se, # Updated at April 25, 2021. This is not reported in the CVPR paper.
}
def get_RepVGG_func_by_name(name):return func_dict[name]# Use this for converting a RepVGG model or a bigger model with RepVGG as its component
# Use like this
# model = create_RepVGG_A0(deploy=False)
# train model or load weights
# repvgg_model_convert(model, save_path='repvgg_deploy.pth')
# If you want to preserve the original model, call with do_copy=True# ====================== for using RepVGG as the backbone of a bigger model, e.g., PSPNet, the pseudo code will be like
# train_backbone = create_RepVGG_B2(deploy=False)
# train_backbone.load_state_dict(torch.load('RepVGG-B2-train.pth'))
# train_pspnet = build_pspnet(backbone=train_backbone)
# segmentation_train(train_pspnet)
# deploy_pspnet = repvgg_model_convert(train_pspnet)
# segmentation_test(deploy_pspnet)
# ===================== example_pspnet.py shows an exampledef repvgg_model_convert(model:torch.nn.Module, save_path=None, do_copy=True):if do_copy:model = copy.deepcopy(model)for module in model.modules():if hasattr(module, 'switch_to_deploy'):module.switch_to_deploy()if save_path is not None:torch.save(model.state_dict(), save_path)return model











![[工具分享] 如何快速的添加海外客户的whatsApp和line进入通讯录](https://img-blog.csdnimg.cn/02f9265e362545b5ad90f2427562c124.png)