原文链接:https://arxiv.org/pdf/2211.03545v1.pdf
代码链接:https://github.com/PaddlePaddle/PaddleSpeech/tree/develop/examples/aishell3_vctk/ernie_sat
一、摘要 & 引言
1. 语音表示学习方法(Speech Representation Learning)既改善了对于单一语种语音的可理解性,又提高了单一语种语音合成任务的效果。然而,对于跨语种任务来说,其效果不太好。
2. 该论文提出了一种语音-文本联合预训练框架——在给定语音和文本的情况下,随机掩蔽(mask)语音频谱特征和音素序列,通过学习重建语音输入的被掩蔽部分,来达到语音合成(语音克隆)的目的;提出了一种新的掩蔽策略——非重叠掩蔽策略(Non-overlapping Masking Strategy)。
3. 该框架相较基于说话人(语种)嵌入的多说话人(跨语种)语音合成模型来说,效果有较大的提升。可用于跨语种语音合成、语音克隆和语音编辑。
4. 支持跨语种、多说话人语音合成;适用于域外说话人语音合成;训练&推理阶段都是端到端的,不用微调;
二、模型 & 方法
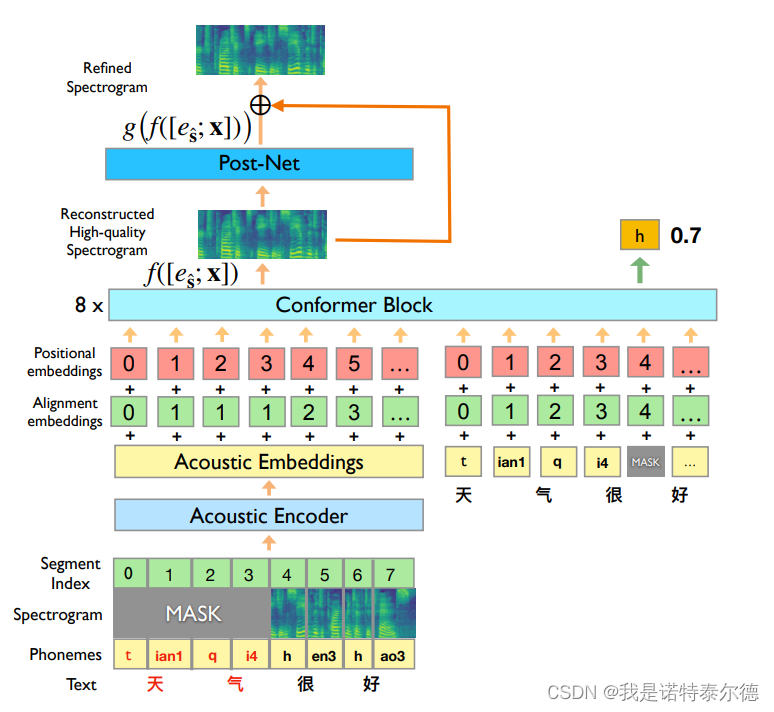
(1)输入:语音文本对 <s, x> ——声学特征 s(谱 or mel谱)、音素序列 x 。
(2)非重叠掩蔽策略:分别对声学特征以及音素序列进行掩蔽。
a. 对声学特征:随机几个掩蔽范围,范围大小由参数 确定;
![]()
b. 对音素序列:在 a 中未被掩蔽的部分中,随机选取一半掩蔽;
![]()
被掩蔽部分都使用随机初始化向量 替代。
(3)输入层:采用非线性前馈层作为声学信息编码器(Acoustic Encoder),将被掩蔽后的声学特征 编码为声学嵌入向量
,被掩蔽后的音素序列
编码为音素嵌入向量
。
为了加强语音和文本之间的联系,分别将二者的位置编码信息(Positional Encoding)以及对齐信息(Alignment Information)与嵌入向量合并(相加)。
(4)编码器:采用 Conformer 架构作为编码器的主要架构,输入为声学向量和文本向量的拼接。
(5)训练损失:由谱特征重构损失和文本信息重构损失两个部分构成。
![]()
其中谱特征重构损失包含经过 Post-Net 前的谱特征重构损失以及经过 Post-Net 后的谱特征重构损失,采用MAE损失计算:
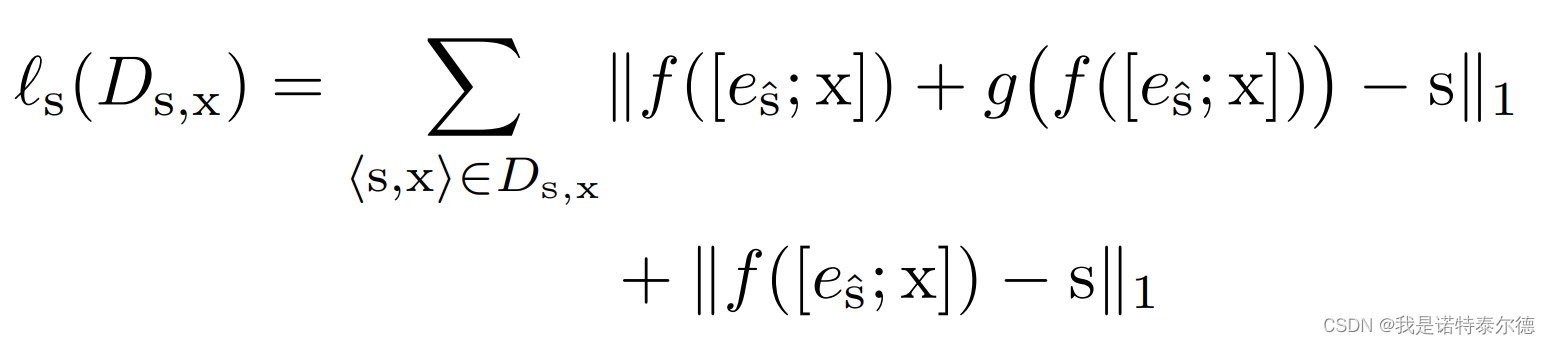
文本信息重构损失为经过 Conformer Block后得到的重构文本信息与真实文本信息的损失,采用交叉熵损失计算:
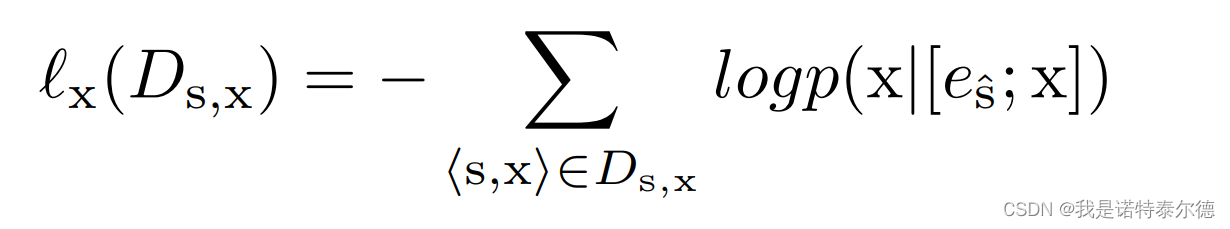
(6)跨语种语音合成预训练:将中文数据集与英文数据集混合训练。
三、对于跨语种多说话人语音克隆场景的应用
采用基于提示的解码方法(Prompt-based Decoding Method)
1. 将源语种提示文本与目标语种文本拼接在一起;
2. 使用预先训练好的持续时长预测器(Duration Predictor)预测目标语音的长度;
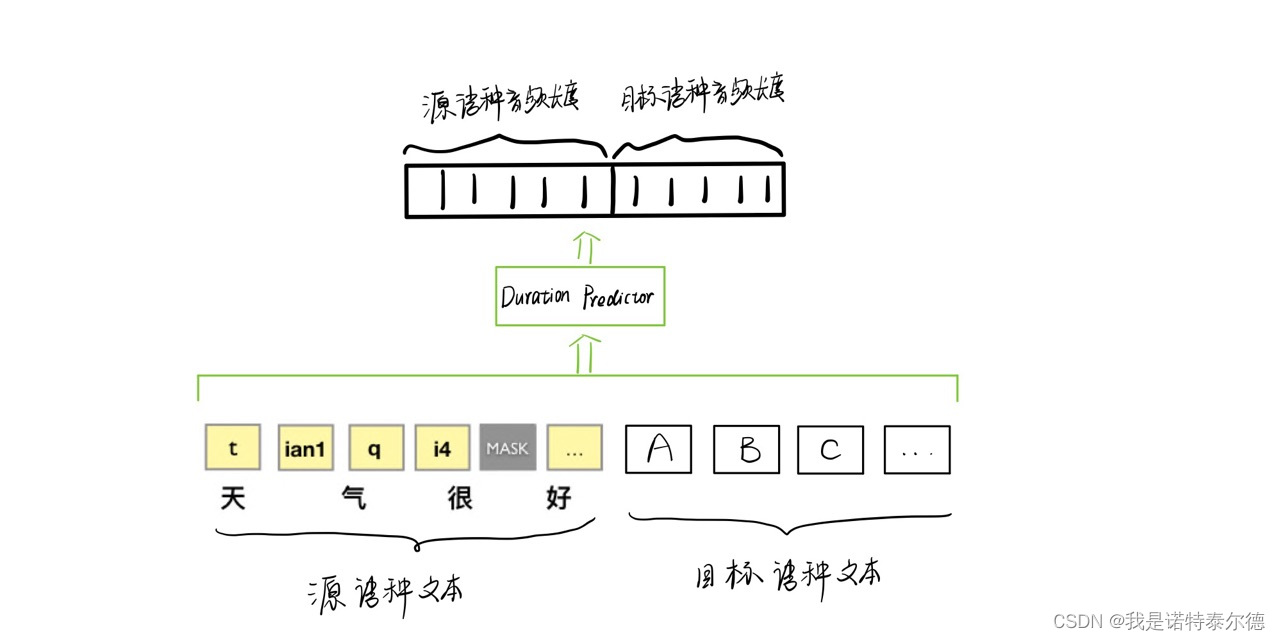
3. 在源语种语音后拼接相同长度的随机初始化掩码向量,将未知的目标语种语音视为被掩蔽的部分;
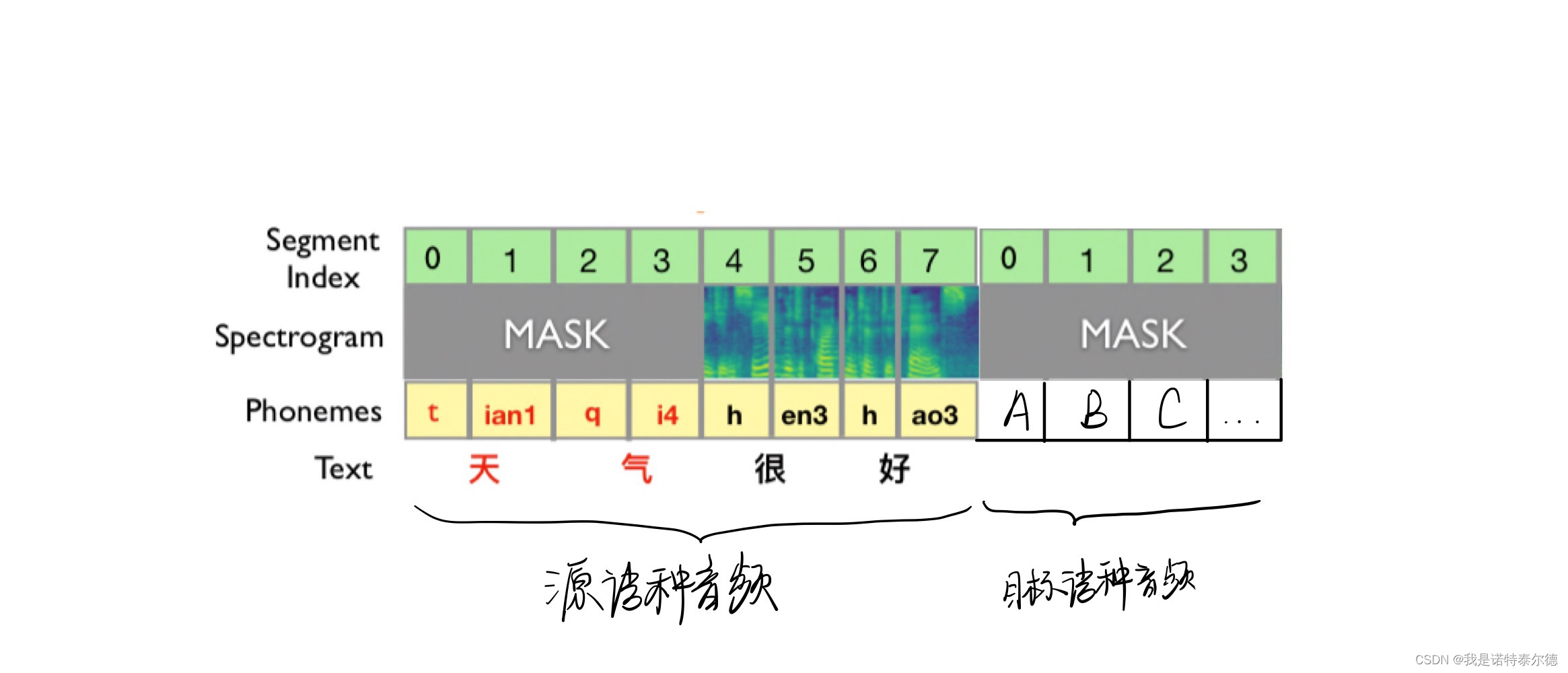
4. 将拼接好的语音和文本送入编码器,重建被掩蔽部分,得到目标语种音频。
四、实验
1. 数据集:中文数据集AISHELL3 & 英文数据集VCTK。中文包含 193 个音素,英文包含 73 个音素,经过合并得到 262 个跨语种音素。
2. 模型结构:非线性前馈层、8 层Conformer编码器和 5 层一维卷积Post-Net。
3. 实验结果:略。
包含个人理解,欢迎批评指正。

![[工具分享] 如何快速的添加海外客户的whatsApp和line进入通讯录](https://img-blog.csdnimg.cn/02f9265e362545b5ad90f2427562c124.png)