该文章主要记录在学习SQL的过程,觉得比较好的一个SQL题,作为记录学习。
题目背景:
请你获取薪水第二多的员工的emp_no以及其对应的薪水salary,
若有多个员工的薪水为第二多的薪水,则将对应的员工的emp_no和salary全部输出,并按emp_no升序排序。
数据集如下;
有一个薪水表salaries简况如下:
| emp_no | salary | from_date | to_date |
| 10001 | 88958 | 2002-06-22 | 9999-01-01 |
| 10002 | 72527 | 2001-08-02 | 9999-01-01 |
| 10003 | 43311 | 2001-12-01 | 9999-01-01 |
如下提供三种方法,其中第一种方法明显有缺陷,仅供参考学习,也避免避坑。
第一种方法:该方法为错误的解决方案
select emp_no,salary
from salaries
where to_date = '9999-01-01'
order by salary desc limit 1,1
//salary降序排列,从1+1的位置取一个记录第二种方法:通过去重的方式,对salary进行去重的方式排序后,再筛选。
select emp_no, salary from salaries
where to_date = '9999-01-01' and salary =
(select distinct salary from salaries order by salary desc limit 1,1) 第三种方法:通过使用排序窗口函数,该方法为自己在测试的时候用的,测试通过。
select f.emp_no,f.salary from
(select emp_no, salary,dense_rank()over(order by salary desc )
as emp_num from salaries ) f where f.emp_num = 2 注意:以下提供两种方法,限定在不能使用排序函数order by的情况进行,故上述的两种方法又不能使用。
第四种方法:通过建立多次的子查询。
selcet s.emp_no,s.salary from salaries s
where s.salary =
(selcet max(s.salary) from salaries s where s.salary < #定位出第二大的薪水信息
(select max(s.salary) from salaries) #定位出第一大的薪水信息这种方法适合TOP查询,一旦多了之后,子查询的次数过多,是该方法的弊端。
第五种方法:该方法稍微烧脑一些,用到的方法为表的自连接。在讲述表的自连接时,先说明下表连接的几种方式,参考文章。逐步演示其过程
1)源数据表如下:
| emp_no | salary | from_date | to_date |
| 10001 | 88958 | 2002-06-26 | 9999-01-01 |
| 10002 | 72527 | 2001-08-02 | 9999-01-01 |
| 10003 | 43311 | 2001-12-01 | 9999-01-01 |
| 10004 | 74057 | 2001-11-27 | 9999-01-01 |
2)表的自连接(交叉连接查询)select * from salary s1 ,salary s2;

3)select * from salary s1 ,salary s2 where s1.salary<=s2.salary;在自连接的情况下,定位出比自己大的那部分数据。

4)在通过分组的方式,count统计在每个组的数量(由于每个组下,自连接表里的数据都是大于等于自己的,虽然自连接表2中没有进行排序,但通过计数统计却能实现在当前组别下,自己是第几,因为自己总是在最后一名)。
select s1.salary,s1.emp_no,count(distinct s2.salary) as emp_num
from salary s1 ,salary s2 where s1.salary<=s2.salary group by s1.salary;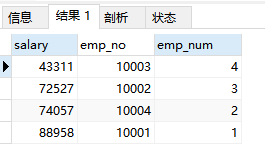
最后在通过where查询得出我们想要的结果。