6月12日凌晨0点,Jay Chou最新单曲《Mojito》正式上线,仅上线1小时销售量就超过百万张,预计今天这首单曲的销量仍然会继续攀升。这次新歌的歌名叫做《Mojito》,翻译成中文是莫吉托,一种巴西鸡尾酒,怪不得观看这首歌MV的时候,感受到一股很浓烈的异域风情呢。

杰伦的上一首单曲《说好不哭》是在2019.9发布的,这首歌是与老搭档方文山搭档的歌曲,当时这首歌在QQ音乐上的销量超过了1500万张,创造历史新高。而新歌《Mojito》则是与另外一位搭档黄俊郎合作的单曲,相信这首歌肯定也会有不错的销量。
好了回归到正题,既然这首歌大家反应这么大,那么大家都是怎么评论这首歌曲的呢?我们爬取了B站上面的弹幕数据,看看粉丝们都说了什么。
1.B站弹幕的爬取
B站的网页确实变化的很快,我还记得5月份的时候,弹幕的接口数据还找得到。然而今天我找了好久都没有找到,难道是今天的状态不行?没关系,在网页中虽然没找的这个弹幕数据的接口,但是我们之前找到了,我们直接拿过来用就好了。
爬取B站弹幕数据的API:https://api.bilibili.com/x/v1/dm/list.so?oid=XXX
从上述网址中我们看到了一个叫做oid的东西,后面是一串数字,不同的网页有着不同的数字串,因此我这里用“XXX”代替了。我们现在就要思考的是,这个oid我们应该怎么获取呢?不要着急下面带大家一步步查找。
我们要想知道这个oid是什么,首先要获取到cid。弹幕数据的接口我们虽然找不到,但是目录页接口还是可以找到的,网址如下。通过这个网址我们可以获取到我们要的那个cid,cid这个键对应的值,就是我们要的oid数字串。
https://api.bilibili.com/x/player/pagelist?bvid=BV1PK4y1b7dt&jsonp=jsonp

注意:由于这个MV只有一个完整的视频,所以这里只有一个cid,如果一个视频是分不同小结发布的,这里就会有多个cid,不同的cid代表不同的视频。
我们将上面接口的url地址和拿到的oid数字串进行拼接,就可以得到这首MV弹幕的真正地址啦,现在把地址提供给大家。我们只需要请求这个网址,解析网页后就可以获取我们想要的数据啦。
https://api.bilibili.com/x/v1/dm/list.so?oid=201056987

这里还有最后一点需要提醒大家的。观察目录页的那个接口(网址如下),里面有一串字符串BV1PK4y1b7dt,我们先不管这个参数是什么,我们只关心这个字符串从哪里来的呢?
https://api.bilibili.com/x/player/pagelist?bvid=BV1PK4y1b7dt&jsonp=jsonp
最后我们观察这首MV的原始网址(网址如下),原来这个字符串就在这首MV的原始网址中。好了,说到这里,我就将B站弹幕数据爬取的一些参数的来龙去脉,给大家讲清楚了,下面我们开始代码部分吧。
https://www.bilibili.com/video/BV1PK4y1b7dt?t=1
代码如下:
import requests
import json
import chardet
import re
from pprint import pprint
# 1.根据bvid请求得到cid
def get_cid():url = 'https://api.bilibili.com/x/player/pagelist?bvid=BV1PK4y1b7dt&jsonp=jsonp'res = requests.get(url).textjson_dict = json.loads(res)#pprint(json_dict)return json_dict["data"][0]["cid"]# 2.根据cid请求弹幕,解析弹幕得到最终的数据
"""
注意:哔哩哔哩的网页现在已经换了,那个list.so接口已经找不到,但是我们现在记住这个接口就行了。
"""
def get_data(cid):final_url = "https://api.bilibili.com/x/v1/dm/list.so?oid=" + str(cid)final_res = requests.get(final_url)final_res.encoding = chardet.detect(final_res.content)['encoding']final_res = final_res.textpattern = re.compile('<d.*?>(.*?)</d>')data = pattern.findall(final_res)#pprint(final_res)return data# 3.保存弹幕列表
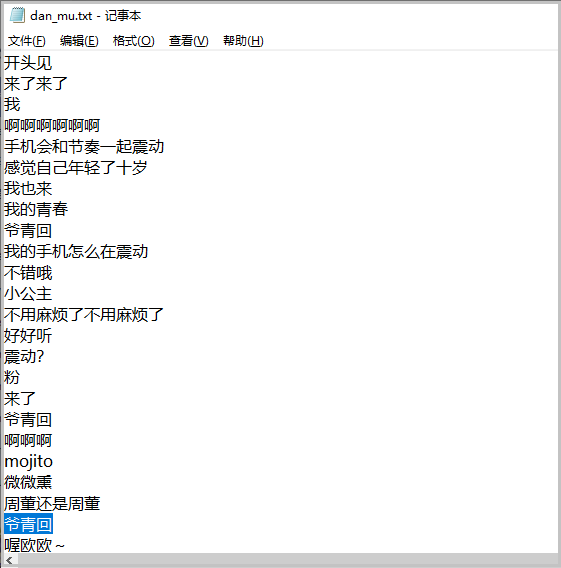
def save_to_file(data):with open("dan_mu.txt", mode="w", encoding="utf-8") as f:for i in data:f.write(i)f.write("\n")cid = get_cid()
data = get_data(cid)
save_to_file(data)
结果如下:
2.词云图的制作
# 1 导入相关库
import pandas as pd
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from imageio import imreadimport warnings
warnings.filterwarnings("ignore")# 2 读取文本文件,并使用lcut()方法进行分词
with open("dan_mu.txt",encoding="utf-8") as f:txt = f.read()
txt = txt.split()
data_cut = [jieba.lcut(x) for x in txt]
data_cut
# 3 读取停用词
with open(r"G:\6Tipdm\wordcloud\data\stoplist.txt",encoding="utf-8") as f:stop = f.read()
stop = stop.split()
stop = [" ","道","说道","说"] + stop
# 4 去掉停用词之后的最终词
s_data_cut = pd.Series(data_cut)
all_words_after = s_data_cut.apply(lambda x:[i for i in x if i not in stop])
# 5 词频统计
all_words = []
for i in all_words_after:all_words.extend(i)
word_count = pd.Series(all_words).value_counts()
# 6 词云图的绘制
# 1)读取背景图片
back_picture = imread(r"G:\6Tipdm\wordcloud\jay1.jpg")# 2)设置词云参数
wc = WordCloud(font_path="G:\\6Tipdm\\wordcloud\\simhei.ttf",background_color="white",max_words=2000,mask=back_picture,max_font_size=200,random_state=42)
wc2 = wc.fit_words(word_count)# 3)绘制词云图
plt.figure(figsize=(16,8))
plt.imshow(wc2)
plt.axis("off")
plt.show()
wc.to_file("ciyun.png")
结果如下:

从词云图可以看到,整个弹幕屏幕都是表达了粉丝对于《Mojito》这首歌的热爱,可能有些词语显得有些莫名其妙,像震动、手机等词语,但是看过MV的人都知道确实都是赞美之词。
首先,啊啊啊这个感叹词出现的次数是最多的,难道大家是刚刚听到这首歌,惊喜之情无法用言语来表达?只好借用这样的感叹词来表达自己内心的激动?这可不是我的风格,我要是喜欢就会用直白的话表达出来。
其次,手机、震动这样的词出现的也很多。我刚刚看到这样的词语时候,我很莫名其妙。一首新歌MV和手机震动有啥关系呢?这原来是一个梗,恕我当时也没怎么关注,含义就是:周杰伦新歌销量太好,网友调侃便说结论手机一直在震动。如果你也不知道这是一个什么梗,提供一个网址给大家了解一下。
https://www.ixiumei.com/a/20190917/364084.shtml
我们还可以注意到,有一个词的频率出现次数也是很高的,那就是爷青回。哈哈,刚刚看到这个词语的人肯定是很懵逼的,这是什么意思呢?其实就是爷的青春回来了的意思。不得不说周杰伦的歌确实影响了我们这一代人,新歌一发布,不少人感叹:杰伦,回不去了吗?虽然我们的年纪在慢慢长大,但是我们却始终习惯停留在青春的状态。
当然像爱、好听、粉、亿遍这样的词语大家也都知道是什么意思,我也就不详细说明了,总的来说从整个词云图来看,基本上是0差评。《Mojito》整首歌给我的感觉就是节奏欢快,周杰伦虽然成了无数人的青春,不少人也是感叹青春回不去了吗?但是在这个炎炎夏日聆听这首欢快的歌曲,也是及其不错的。
关注微信公众号『数据分析与统计学之美』,后台回复“code”自动获取本文完整数据和代码。

好文一定要 点再看 和朋友一起分享!