来源:知乎
链接:https://zhuanlan.zhihu.com/p/261298869
基础知识
原理务必理解透彻。
锁存器的结构-DFF的结构-建立保持时间-亚稳态-STA-CDC。
亚稳态的成因,危害,解决方法。
建立保持时间的计算,违例的Fix,流片前和流片后。还有复位的Recovery Removal time。
CDC的解决方法。
低功耗常见设计方法,动态-静态功耗计算和分析。例如两种情况对比功耗大小。
竞争和冒险的区别、成因、危害、处理方法。
毛刺的成因、危害、处理方法。
时序约束的意义和做法。(时钟约束,IO约束,例外约束)。
OCV - PVT。
Resolution time的成因以及HVT,SVT,LVT Cell的Resolution time的区别。
ASIC设计和FPGA设计的Flow。
高阻态的意义和用法。
Verilog 延时模型。
手撕代码
不仅能闭眼写,而且懂原理,会根据题目要求写出不同变种(例如最少资源占用)的代码。
异步fifo。格雷码的镜像对称。格雷码和二进制的互相转换。
同步fifo。
除法器。
Wallace乘法器。
Booth乘法器。
Booth+Wallace乘法器。
超前进位加法器。
边沿检测,输入消抖,毛刺消除。
异步复位同步释放。
三种计数器。二进制,移位,移位+反向。
无毛刺时钟切换。
串行-并行CRC。(ARM)。
线性反馈移位寄存器。
握手实现CDC。
AXI-S接口,2T一次传输,1T一次传输,1T一次传输还要寄存器寄存。(Nvidia考题)Xilinx有例程。
其他简单功能的HDL实现以及状态转换图。(序列检测 ,回文序列检测(NVIDIA),奇、偶、半分频,小数分频,自动售货机)。
题目部分
最大项,最小项,组合逻辑变换为与非/或非形式,卡诺图化简。典型数电考题。
常用元件的门电路实现。(非,与非,或非,锁存器(两种),DFF)。
MOS管实现门电路。
MUX或者MUX+Inverter实现异或,或者其他简单逻辑功能。
门电路实现逻辑表达式。这个是典型的数电考题。
门电路真值表。特别是输入为X和Z的时候。
门电路实现同步时序逻辑。这个是典型的数电考题。1.状态转换图或者状态转换表。2.状态化简。3.状态分配。4.卡诺图化简求出状态方程,驱动方程,和输出方程,自启动修改。5.画出逻辑图。例如售货机的门电路D触发器实现。
门电路实现波形。常见的计数器,线性反馈移位等等。本质上还是实现时序逻辑功能。
门电路实现Verilog代码。
Verilog常用语法,例如两操作数运算符和一操作数运算符,task和function区别,时钟激励的写法,可综合/不可综合语句。还有操作数有X和Z时的返回值。
FIFO深度计算,一般就是背靠背。
其他问题
偶尔被问到,挺有启发意义。
if,case,三目运算符的区别。其实现代工具综合出来区别不大。
超高速(Gbps)CDC时格雷码的不可靠问题。
串扰。
ESD。
闩锁效应。
上拉下拉电阻。
线与,OC,OD门。
施密特触发器。
CMOS与TTL电平,相互驱动关系。
Cordic算法。
Latch+time borrowing。
FPGA的基本资源与内部构造。对于FDCE,LDCE的实现。
FPGA的时钟资源及构造。
Cache+MMU,TLB,中断,DMA,大小端,流水线,超标量,超流水,超长指令字,数据冒险,控制冒险,分支预测,乱序执行,LRU等等计算机体系结构常识。(进程/线程调度,CPU调度,内存调度,总线分配)。
同步时钟和异步时钟。时钟相移之后还是同步的吗?倍频或者分频呢?
PLL+MMCM。他们的输入输出,使用的注意点等等。
计算机网络常识。NAT,地址映射,TCP/IP 4层网络模型。
同步复位和异步复位的区别,特别是资源消耗,有复位和无复位的综合实现区别。
PMOS管和NMOS管的结构以及区别,增强型和耗尽型。采用不同的MOS管实现电路的速度区别。电子导电比空穴能力强。(兆易创新)。
IC设计常用术语。
Verilog二维数组初始化。常用于FIFO设计。
Verilog仿真模型推进。这个可以看Verilog设计指南的解析。
2态数据类型与4态数据类型对仿真速度的影响。
还有一些术语的解释。这个外企题目常见,外企面试也常见。我有次被问到MMU,当时没反应过来,事后才想起应该是Memory Manage Unit。
基础知识
1、锁存器的结构-DFF的结构-建立保持时间-亚稳态-STA-CDC。
1.1 锁存器的结构
锁存器即Latch,数电中称之为电平触发D 触发器,也即D 型锁存器,由电平触发SR 触发器改进得到。
其工作特点是在电平为有效电平(高电平或低电平)期间,才能接受信号并输出,否则保持不变;
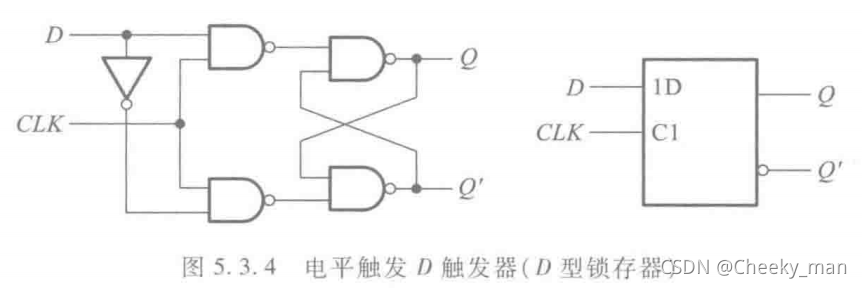
1.2 DFF的结构
D 触发器——DFF,数电中称之为边沿触发D 触发器,由两个D-Latch组成而来。
工作特点:触发器的次态仅取决于时钟信号的上升沿或下降沿到达时输入的逻辑状态,而在这之前或之后,输入信号的变化对触发器输出的状态没有影响。
这一点有效地提高了触发器的抗干扰能力,也提高了电路的工作可靠性。
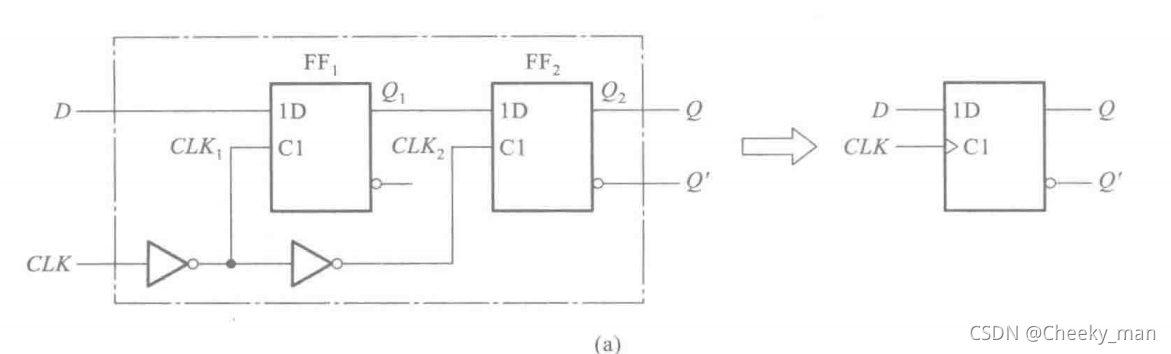
FF1、FF2为D-Lacth。
1.3 建立时间和保持时间
setup time 和 hold time概念
- 建立时间:触发器在时钟上升沿到来之前,其数据输入端的数据必须保持不变的最小时间。
- 保持时间:触发器在时钟上升沿到来之后,其数据输入端的数据必须保持不变的最小时间。
关于建立时间和保持时间的约束
- Tsetup ≤ Tclk + Tskew - Tcq(max) - Tcomb(max)
- Thold ≤ Tcq + Tcomb - Tskew
- 触发器建立时间和保持时间的关系(含题目详解)_Cheeky_man的博客-CSDN博客
1.4 亚稳态
为什么触发器要满足建立时间和保持时间?
- 因为触发器内部数据的形成是需要一定的时间的,如果不满足建立和保持时间, 触发器将进入亚稳态,进入亚稳态后触发器的输出将不稳定,在 0 和 1之间变化,这时需要经过一个恢复时间, 其输出才能稳定,但稳定后的值并不一定是你的输入值。这就是为什么要用两级触发器来同步异步输入信号。这样做可以防止由于异步输入信号对于本级时钟可能不满足建立保持时间而使本级触发器产生的亚稳态传播到后面逻辑中,导致亚稳态的传播。
1.5 CDC 及 亚稳态解决方法:

- 数字IC设计知识点及综合题详解(提前批、秋招必刷基础题)——(四)亚稳态、跨时钟域(CDC)处理方法及其编程仿真代码_Cheeky_man的博客-CSDN博客


1.6 STA
建议收藏:不能不刷的100道数字IC笔/面试题!_Cheeky_man的博客-CSDN博客(二、静态时序分析和动态时序分析的比较)
静态时序分析(static timing analysis,STA)是遍历电路存在的所有时序路径,根据给定工作条件(PVT)下的时序库.lib文件计算信号在这些路径上的传播延时,检查信号的建立和保持时间是否满足约束要求,根据最大路径延时和最小路径延时找出违背时序约束的错误。
2、亚稳态的成因,危害,解决方法
建议收藏:不能不刷的100道数字IC笔/面试题!_Cheeky_man的博客-CSDN博客(九、何为亚稳态?如何消除亚稳态?)
亚稳态:触发器无法在某个规定时间内达到一个可确认的状态;
成因:触发器的建立时间和保持时间不满足,使得输出端 Q 在时钟边沿到来后比较长的一段时间内处于不确定的状态,并且Q稳定后的值是随机的,与输入D无关;
解决方法:
(1)使用同步器(多级寄存器):比如常用的2级或者多级FF打拍的方法(最常见的方法)
(2)降低频率:如果能满足功能要求,降低频率能够减少亚稳态的发生。(在高性能要求下并不实用)
(3)避免变化过快或者过于频繁的信号进行跨时钟采样。(在高性能要求下并不实用)
(4)采用更快的触发器:更快的触发器,也可以亚稳态的产生
3、建立、保持时间的计算,违例的Fix,流片前和流片后,还有复位的Recovery Removal time。
Tclk→q + Tlogic + Tsetup + Tsetup_slack = Tclk + Tskew;
Tclk→q + Tlogic = Tholdup + Tholdup_slack + Tskew
从上面的分析可以看到:
- 数据跑得越快(TDelay越小),时钟传输时延越大(clock skew越大)对建立时间的满足越有利,而对保持时间的满足越不利,相反则对满足保持时间越有利,对满足建立时间越不利。
- 建立时间还跟时钟周期有关系,时钟周期越小,越容易发生建立时间违例,而保持时间则跟时钟周期没有关系。
- 在设计中,我们常常关注的是建立时间是否满足要求,因为它关系到我们能使用的最小时钟周期有多小,能否跑到预定的工作频率,而因为时钟通常都是走专门的快速线路,很难存在时钟传输时延过大的问题,所以一般也不会出现保持时间违例的情况。
建立时间公式:Tsetup + Tdq + Tdata ≤ Tclk + Tskew
Tdata = (Tcomb+T逻辑组合布线延迟)
保持时间公式:Tdq + Tdata - Tskew ≥ Tholdsetup&hold time 违约修复主要参照上面的公式进行
对于建立时间违例的解决办法按优先级有:
- 首先是修改代码,找到关键路径上的源寄存器和目的寄存器,拆分它们之间的组合逻辑。插入寄存器是最简单粗暴的办法,实际上在设计之初,如果我们精心设计的话,是可以在算法级对组合逻辑进行分解的,好的时序是设计出来的,不是约束出来的;
如果修改代码实在解决不了,在使用约束关键路径的办法;
- 买更好更快的芯片,更好的芯片意味着更低的Tsu要求,更小的Tpd、Tcomb;
- 降低工作频率,即提高时钟周期。
对于保持时间违例的解决办法按优先级有:
- 增加Tdata = (Tcomb+T逻辑组合布线延迟),具体操作是在data line上(两个触发器之间的组合逻辑块部分)插入buffer,反相器或者delay cell去增加Tdata;
- 增加前级D触发器的驱动延迟;
- 减小Tskew,减小时钟偏移;
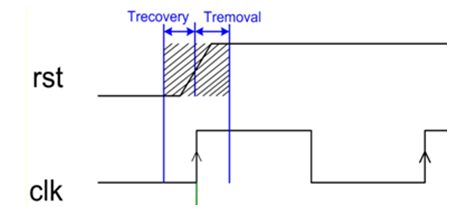
复位时间(recovery)
复位信号释放(对于低电平有效的复位信号指上升沿),与紧跟其后的第一个时钟上升沿之间的最小时间。
撤销时间(removal)
时钟信号的上升沿,与紧跟其后异步复位信号从有效到无效的最小时间。
4、CDC的解决方法
单bit:
- 高频采低频
- 电平同步器(双锁存)
- 边沿同步器
- 脉冲同步器
- 低频采高频
- 脉冲同步器
多bit:
- 异步FIFO+双端口RAM
- 握手信号
5、低功耗常见设计方法,动态-静态功耗计算和分析。
5.1 SoC 低功耗电路设计方法
针对功耗来源,提出了低功耗设计常用方法。
降低电源电压;
减小负载电容;
减少MOS管数量;
减小连线电容
减少电荷分享的影响(对动态电路)
节点开关活动因子的影响;
从算法和体系结构角度优化;
选择具有低功耗功能器件;
时钟门控;
提高工艺:
- 使用新型低功耗器件和材料,减少晶体管尺寸,如从28nm到16nm等。
时钟门控:
- 频繁的信号翻转会造成很大的短路电流,以及对负载电容进行频繁的充放电,即增大所谓的内部功耗(Internal Power)和切换功耗(Switch Power)。
多电压域技术:
- 芯片的动态功耗正比于电压值的平方,静态功耗正比于电压值,因此芯片的电压域管理策略对芯片的功耗影响很大。
- 多电压域技术是按照芯片功能和应用需要,将不同的逻辑模块放置在不同的电压域中,这些电压域由电源管理模块分别独立供电,使得不同的逻辑模块可以在不同的电压下工作。
- 例如,某一段时间内,某些性能要求不高的模块可位于低电压域中,而性能要求较高模块的供电电压相应较高,且多电压域技术也是动态电压频率缩放(Dynamic Voltage and Frequency Scaling , DVFS)、静态电压缩放(Static Voltage Scaling, SVS)、自适应电压缩放(Adaptive Voltage Scaling, AVS)设计的基础。
电源门控技术:
- 随着工艺技术的发展,由漏电流所产生的功耗所占的总功耗比例越来越大。对于诸如手机的手持移动设备中的SoC芯片,休眠模式下漏电流功耗的大小是设计者在设计时必须考虑的设计因素。
- 对于希望在休眠模式下尽量节省功耗的设计来说,最好的办法是,将处于休眠模式状态的模块的供电电源关断而保持其它模块的正常供电,这种技术叫电源门控技术。
- 电源门控技术与时钟门控技术相比,时钟门控降低的仅仅是电路的动态功耗,而电源门控不仅降低动态功耗,而且降低静态功耗。
-
时钟门控技术不影响设计电路的功能,也无须修改RTL(Register Transfer Level)代码,它在设计和实现上可以是对设计者透明的,而电源门控技术影响各模块之间的相互连接,安全进入和退出电源门控模式会增加很多额外的操作。
-
电源门控一般有两种方法来实现:
-
外部电源门控(external power gating)。实现电源门控最基本的方法,适于消耗漏电功耗较少但关断时间较长的设计。举个例子,一个SoC系统在板极上有CPU的专用电源,这个电源只提供电压给CPU。外部电源门控技术就是,可以关闭这个电源以使CPU在非活动状态时漏电功耗减小到零。但这种做法也需要最长的时间对电源门控的模块进行供电和数据的重新加载。
-
内部电源门控(on-chip power gating)。内部电源门控是指在芯片内部用一些专门的逻辑单元如电源门控单元来控制所选模块的供电情况。
-
- 外部电源门控技术与内部电源门控技术均能实现将电压域中电压关断从而最大限度地减小漏电功耗的目的,但在物理实现过程中,内部电源门控技术要复杂得多。
器件低功耗
- SOC系统中各个器件选型时,选择具备低功耗功能器件,但器件无业务工作需求时,可以进入低功耗状态。
RTL级优化
- 不同的RTL(RegisterTransferLevel,寄存器传输级)代码,也会产生不同的功耗,而且RTL代码的影响比软件代码产生的影响可能还要大。因为,RTL代码最终会实现为电路。电路的风格和结构会对功耗产生相当重要的影响。
- RTL级代码优化主要包括:
- ①对于CPU来说,有效的标准功耗管理有睡眠模式和部分未工作模块掉电。
- ②硬件结构的优化包括能降低工作电压Vdd的并行处理、流水线处理以及二者的混合处理。
- ③降低寄存电容C的片内存储器memory模块划分。
- ④降低活动因子a的信号门控、减少glitch(毛刺)的传播长度、Glitch活动最小化、FSM(有限状态机)状态译码的优化等。
- ⑤由硬件实现的算法级的功耗优化有:流水线和并行处理、Retiming(时序重定)、Unfolding(程序或算法的展开)、Folding(程序或算法的折叠)等等基本方法以及其组合。
后端综合与布线优化
功耗的精确计算
自适应阈值电压调节技术
5.2 动态功耗
动态功耗来源于:
(1)当门翻转时,负载电容充电和放电,称为翻转功耗
(2)pmos和nmos管的串并联结构都导通时的有短路电流,称为短路功耗。
5.2.1 翻转功耗
翻转功耗可以用如下公式表示:
α 称为活动因子,是电路节点从0跳变至1的概率。时钟的活动因子为1,因为它在每个周期都有上升和下降。大多数数据的活动因子为0.5,每周期只跳变一次。
C称为负载电容。
有以下办法可以降低翻转功耗:
(1)使用门控时钟
降低活动因子是降低功耗的非常有效的办法,如果一个电路的时钟完全关断,那么它的活动因子和动态功耗将降为0。Verilog在设计寄存器时采用下面写法可以综合成一个带门控的寄存器。
input reg d;
always @(posedge clk or negedge resetn) begin
if(~resetn)
q<= 1'b0;
else if(enable)
q<= d;
end
(2) 减小毛刺
毛刺会增大活动因子,有可能使门的活动因子增加到1以上。
(3)减小负载电容
电容来自于电路中的连线以及晶体管。缩短连线长度,良好的平面规划和布局可以使连线电容减小。选择较小的逻辑级数以及较小的晶体管可以减小器件的翻转电容。
(4)电压域
动态功耗与电压有平方的关系,降低电源电压可以显著降低功耗。将芯片划分成多个电压域,每个电压域可以根据特定电路的需要进行优化。例如,对于存储器采用高电源电压来保证存储单元的稳定性,对于处理器采用中等大小的电压,对运行速度较低的IO外围电路采用低电压。解决跨电压域信号传输的方法是使用电平转换器。
(5)动态电压调整DVS
CPU处理不同的任务有不同的性能要求。对于低性能要求的任务,可以使时钟频率降低到足以按预定时间完成任务的最低值,然后使电压降低到该频率下工作所需要的最小值就可以节省大量的能耗。
(6)降低频率
动态功耗正比于频率,芯片只应当工作在所要求的频率下,不能比所要求的还要快。由前面小结可以,降低频率还可以采用较低的电源电压,大大降低功耗。
(7)谐振电路
谐振电路通过使能量在储能元件如电容或电感之间来回传送而不是将能量泄放到来减小翻转功耗。
5.2.2 短路功耗
短路功耗发生在当输入发生翻转时,上拉和下拉网络同时部分导通的时候。如果输入信号翻转速率比较慢,那这两个网络将同时导通较长的一段时间,短路功耗也会比较大,增大负载电容可以减小短路功耗,原因是负载较大时,输出在输入跳变期间只翻转变化很小的一个量。
短路电流一般为负载电流的10%。当输入边沿变化速度很快时,短路功耗一般只占翻转功耗的2%-10%。
5.3 静态功耗
静态功耗主要来源于:
(1)流过截止晶体管的亚阈值泄漏电流(subthreshold leakage)
(2)流过栅介质的泄漏电流(gate leakage)
(3)源漏扩散区的p-n节泄漏电流(junction leakage)
(4)在有比电路中的竞争电流
5.3.1 降低静态功耗办法
(1)电源门控
减小静态电流最容易的方法就是关断休眠模块的电源。这一技术称为电源门控。
(2) 多种阈值电压和栅氧厚度
有选择的应用多种阈值电压可以使具有低Vt晶体管保持性能而又使具有高Vt晶体管的其他路径减少泄漏。
大多数纳米工艺的逻辑管采用薄栅氧,IO晶体管采用厚的多的栅氧以使它们能够承受较大的电压。
(3)可变阈值电压
通过体效应可以调制阈值电压。在休眠模式下应用一个反向体偏置减小泄漏。在工作模式下利用一个正向体偏置来提高性能。
(4)输入向量控制
由前面可知,堆叠效应和输入排序会引起亚阈值泄漏和栅泄漏的变化。因此,一个逻辑模块的泄漏与门的输入有关。输入向量控制是当模块置于休眠模式时,应用一组输入图案使模块的泄漏最小。这些输入向量可以通过寄存器上的置位/复位输入端或通过扫描链加入。
6、竞争和冒险的区别、成因、危害、处理方法
在组合逻辑中,由于门的输入信号通路中经过了不同的延时,导致到达该门的时间不一致叫竞争。
产生毛刺叫冒险。
如果布尔式中有相反的信号则可能产生竞争和冒险现象。
方法:接入滤波电容、引入选通脉冲、修改逻辑设计-增加冗余项
7、毛刺的成因、危害、处理方法
同上
8、时序约束的意义和做法(时钟约束,IO约束,例外约束)
FPGA设计之时序约束---常用指令与流程_wenjia7803的博客-CSDN博客
9、OCV - PVT
即便是同一种FF,在同一个芯片上不同操作条件下的延时都不尽相同,我们称这种现象为 OCV(on-chip variation)
OCV表示的是芯片内部的时序偏差,虽然很细小,但是也必须严格考虑到时序分析中去。
产生 OCV 的原因主要有PVT(Process / Voltage / Temperature)三个方面,而 STA要做的就是针对不同工艺角(Process Corner)下特定的时序模型来分析时序路径,从而保证设计在任何条件下都能满足时序要求,可以正常工作。
通常PVT对芯片性能的影响如下图所示,
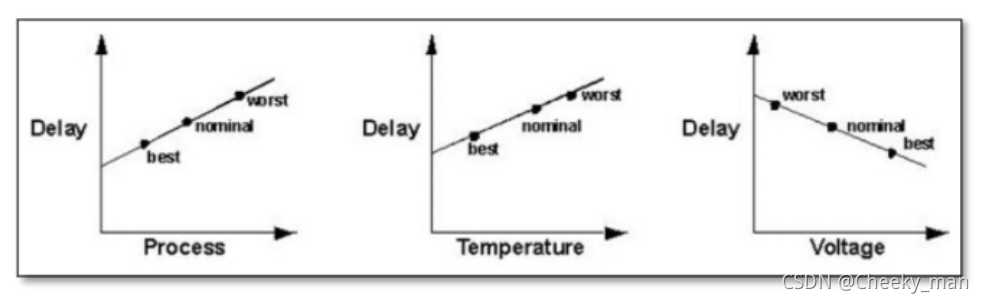
不同的 PVT条件组成了不同的 corner,另外在数字电路设计中还要考虑 RC corner的影响,排列组合后就可能有超过十种的corner要分析。但是在 FPGA 设计中的静态时序分析一般仅考虑Best Case和 Worst Case,也称作Fast Process Corner和 Slow Process Corner 分别对应极端的PVT条件。
10、Resolution time的成因以及HVT,SVT,LVT Cell的Resolution time的区别
决断时间(resolution time):
一个触发器一旦进入亚稳态状态,则无法预测触发器的输出电平,也无法预测什么时候可以稳定在某个确定的电平上,此时触发器的输出端Q在较长时间内处于振荡状态,不等于输入端D。这段时间称作决断时间(resolution time)。经过resolution time之后,输出端Q将会稳定在某个电平上,但是这个稳定之后的电平与输入端D是没有关系的。
HVT/SVT/LVT
在数字后端设计中,不同的cell单元库具有不同的阈值电压。阈值电压越低,该单元的速度越快,功耗也会越大。好比晶体管就像一个电容,电容的电压充到阈值电压才能导通,阈值电压越低,充满电的速度就会越快。通常的单元库根据不同的阈值电压,可以分为SLVT, LVT, RVT, HVT。他们的速度大小按快到慢依次排列为SLVT, LVT, RVT, HVT。 功耗大小却正好相反。
11、ASIC设计和FPGA设计的Flow
ASIC设计流程:前端设计+后端设计(与工艺相关)
前端设计:
RTL级代码----功能仿真----逻辑综合----等价性检查,形式验证----静态时序分析----
后端设计:
布局规划—布局布线----版图物理验证(包括LVS和DRC等)----流片
- RTL级代码:使用verilog语言进行描述我们想要实现的电路功能
- 功能仿真:检查代码有没有语法问题或者实现的功能和我们预计设计的是否相同
- 逻辑综合:把代码语言描述的模块转化成包含与,或,非,寄存器等基本的逻辑单元的网表
- 形式验证:从功能上,对综合后的网表进行验证,检查验证生成的网表功能是否与设计的电路功能相同
- 静态时序分析:从时序上,进行验证,检查电路是否存在时序上的问题
- 布局规划:规划芯片上的各种功能电路的摆放位置
- 布局布线:连接单元和功能块之间的互连布线线
- 版图物理验证:对完成布线的物理版图进行功能和时序上的验证(包括DRC和LVS等)
- 流片
FPGA设计流程: RTL级代码----功能仿真-----逻辑综合-----门级仿真-----布局布线----时序仿真----版级验证与仿真
对于设计而言,我们想要设计一个芯片,首先我们要明确我们设计的芯片旨在解决什么样的问题,具有什么样的功能。
我们根据目的去设计电路,把电路按照功能模块或接口划分,使用硬件描述语言verilog或HDL去实现逻辑设计,生成RTL级的代码
然后我们对这个代码进行功能仿真,检查代码有没有语法问题或者实现的功能跟我们预计的是否相同(代码行为的正确性)
接着我们把它进行逻辑综合,(逻辑综合需要有约束条件,约束条件就是你希望综合出来的电路在面积,时序等目标参数上达到的标准,)
由于逻辑综合需要基于特定的库,不同的库,基本单元电路的对应的面积和时序参数都是不一样的,所以我们还需要进行后仿真也就是门级仿真,从功能和时序两方面对综合后的网表进行验证,保证电路的正确性,以及逻辑综合后生成的网表并没有改变原先电路设计的功能
是自带工具完成。接下来我们对芯片的面积做一个规划,确定每个单元的位置,并完成互连布线(连接单元和功能块之间的互连布线线)
然后我们再做一个时序仿真,电路提取,加延迟,仿真后包含延迟信息,接近于真实电路的行为
烧到板子上,进行仿真,测试
FPGA设计和ASIC设计有本质的区别,FPGA是一种可编程门阵列逻辑电路器件,是基于SRAM查找表逻辑形成的结构,FPGA最终生成的是产生可以实现所需功能电路的编程数据;
FPGA设计流程:在后仿真(时序仿真)后,产生用于编程的下载文件,烧录到板子上,进行测试和运行,前面基本差不多,但也有区别
————————————————
版权声明:本文为CSDN博主「不吐普通皮」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_43308040/article/details/90707470
12、高阻态的意义和用法
高阻态:
- 指的是电路的一种输出状态,既不是高电平也不是低电平;
- 如果高阻态接入下一级电路的话,对下级电路无任何影响,效果等同于没接;
- 如用万用表测量的话,有可能是高电平也有可能是低电平,随负载而定。
高阻态的实质:
- 电路分析时高阻态可做开路理解。
- 你可以把它看作输出(输入)电阻非常大,它的极限可以认为悬空。也就是说理论上高阻态不是悬空,它是对地或对电源电阻极大的状态。而实际应用上与引脚的悬空几乎是一样的。
高阻态的意义:
- 当门电路的输出上拉管导通而下拉管截止时,输出为高电平;反之就是低电平;
- 如上拉管和下拉管都截止时,输出端就相当于浮空(没有电流流动),其电平随外部电平高低而定,即该门电路放弃对输出端电路的控制 。
典型应用:
- 在总线连接的结构上。总线上挂有多个设备,设备于总线以高阻的形式连接。这样在设备不占用总线时自动释放总线,以方便其他设备获得总线的使用权。
- 大部分单片机I/O使用时都可以设置为高阻输入,如凌阳,AVR等等。高阻输入可以认为输入电阻是无穷大的,认为I/O对前级影响极小,而且不产生电流(不衰减),而且在一定程度上也增加了芯片的抗电压冲击能力。
13、Verilog 延时模型
[SV]Verilog中的延时模型_元直的博客-CSDN博客
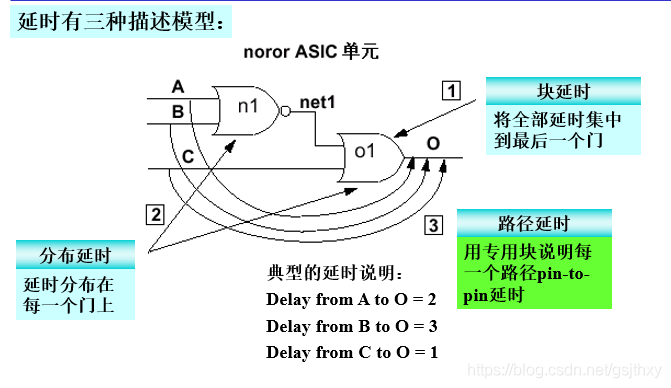
块延时(Lumped Delay)
- 块延时方法是将全部延时集中到最后一个门上。这种模型简单但不够精确,只适用于简单电路。因为当到输出端有多个路径时不能描述不同路径的不同延时。
- 可以用这种方法描述器件的传输延时,并且使用最坏情况下的延时(最大延时)。
`timescale 1ns/ 1nsmodule noror( Out, A, B, C);output Out;input A, B, C;nor n1 (net1, A, B);or #3 o1 (Out, C, net1);endmodule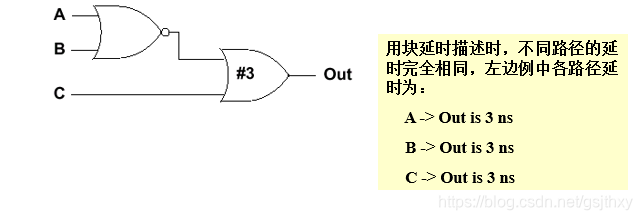
分布延时(Distributed Delays)
分布延时方法是将延时分散到每一个门。在相同的输出端上,不同的路径有不同的延时。分布延时有两个缺点:
– 在结构描述中随规模的增大而变得异常复杂。
– 仍然不能描述基本单元 (primitive) 中不同引脚上的不同延时。
`timescale 1ns/ 1nsmodule noror( Out, A, B, C);output Out;input A, B, C;nor #2 n1 (net1, A, B);or #1 o1 (Out, C, net1);endmodule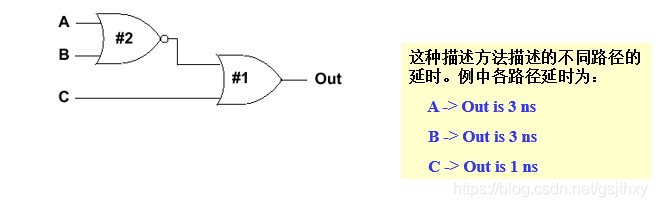
模块路径延时(Module Path Delays)
在专用的specify块描述模块从输入端到输出端的路径延时。
– 精确性:所有路径延时都能精确说明。
– 模块性:时序与功能分开说明
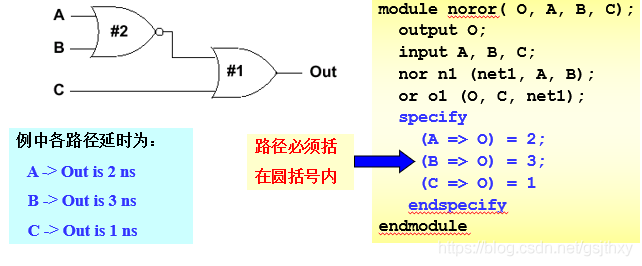
手撕代码
不仅能闭眼写,而且懂原理,会根据题目要求写出不同变种(例如最少资源占用)的代码。
1、异步fifo、格雷码的镜像对称、格雷码和二进制的互相转换
异步FIFO的设计详解(格雷码计数+两级DFF同步)_Mr.翟的博客-CSDN博客_异步fifo格雷码
2、同步fifo
同步fifo设计_正在努力的ICer的博客-CSDN博客_同步fifo![]() https://blog.csdn.net/IamSarah/article/details/76022015?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163219130716780271541136%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=163219130716780271541136&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_v2~hot_rank-2-76022015.pc_v2_rank_blog_default&utm_term=%E5%90%8C%E6%AD%A5FIFO&spm=1018.2226.3001.4450
https://blog.csdn.net/IamSarah/article/details/76022015?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163219130716780271541136%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=163219130716780271541136&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_v2~hot_rank-2-76022015.pc_v2_rank_blog_default&utm_term=%E5%90%8C%E6%AD%A5FIFO&spm=1018.2226.3001.4450
3、除法器
基于减法的除法器
对于32的无符号除法,被除数a除以除数b,他们的商和余数一定不会超过32位。
首先将a转换成高32位为0,低32位为a的temp_a。把b转换成高32位为b,低32位为0的temp_b。
在每个周期开始时,先将temp_a左移一位,末尾补0,然后与b比较,是否大于b,是则temp_a = temp_a - temp_b + 1,否则继续往下执行。
上面的移位、比较和减法(视具体情况而定)要执行32次,执行结束后,temp_a的高32位即为余数,低32位即为商。
举例说明:
a = 1101; b = 0010; a ÷ b = 13 ÷ 2 = 6余1;
①temp_a = 0000_1101; temp_b = 0010_0000;
②temp_a = temp_a << 1 = 0001_1010 < temp_b; 继续移位;
③temp_a = temp_a << 1 = 0011_ 0100 > temp_b;不用移位,直接计算求值
④temp_a = temp_a - temp_b + 1 = 0001(余数)_0101(商)
verilog 代码
/*
* module:div_rill
* file name:div_rill.v
* syn:yes
* author:network
* modify:rill
* date:2012-09-07
*/module div_rill
(
input[31:0] a,
input[31:0] b,output reg [31:0] yshang,
output reg [31:0] yyushu
);reg[31:0] tempa;
reg[31:0] tempb;
reg[63:0] temp_a;
reg[63:0] temp_b;integer i;always @(a or b)
begintempa <= a;tempb <= b;
endalways @(tempa or tempb)
begintemp_a = {32'h00000000,tempa};temp_b = {tempb,32'h00000000}; for(i = 0;i < 32;i = i + 1)begintemp_a = {temp_a[62:0],1'b0};//左移并补0if(temp_a[63:32] >= tempb)temp_a = temp_a - temp_b + 1'b1;elsetemp_a = temp_a;endyshang <= temp_a[31:0];yyushu <= temp_a[63:32];
endendmodule/*************** EOF ******************/testbench 代码
/*
* module:div_rill_tb
* file name:div_rill_tb.v
* syn:no
* author:rill
* date:2012-09-07
*/`timescale 1ns/1nsmodule div_rill_tb;reg [31:0] a;
reg [31:0] b;
wire [31:0] yshang;
wire [31:0] yyushu;initial
begin#10 a = $random()%10000;b = $random()%1000;#100 a = $random()%1000;b = $random()%100;#100 a = $random()%100;b = $random()%10; #1000 $stop;
enddiv_rill DIV_RILL
(
.a (a),
.b (b),.yshang (yshang),
.yyushu (yyushu)
);endmodule
/******** EOF ******************/仿真结果:
4、Wallace乘法器
5、Booth乘法器
6、Booth+Wallace乘法器
Booth压缩+华莱士树Wallace乘法器的通俗理解_ainu412的博客-CSDN博客_华莱士树乘法器原理
7、超前进位加法器
超前进位加法器(较为详细讲解)_UESTC_ICER的博客-CSDN博客_超前进位加法器
8、边沿检测,输入消抖,毛刺消除
FPGA基础入门篇(四) 边沿检测电路_摆渡沧桑-CSDN博客_边沿检测
一个DFF:有毛刺(触发无滞后)
两个DFF:避免毛刺(触发有滞后)
下降沿:tri_2 & (~tri_1)
上升沿:(~tri_2) & tri_1
双边沿:tri_1 ^ tri_2