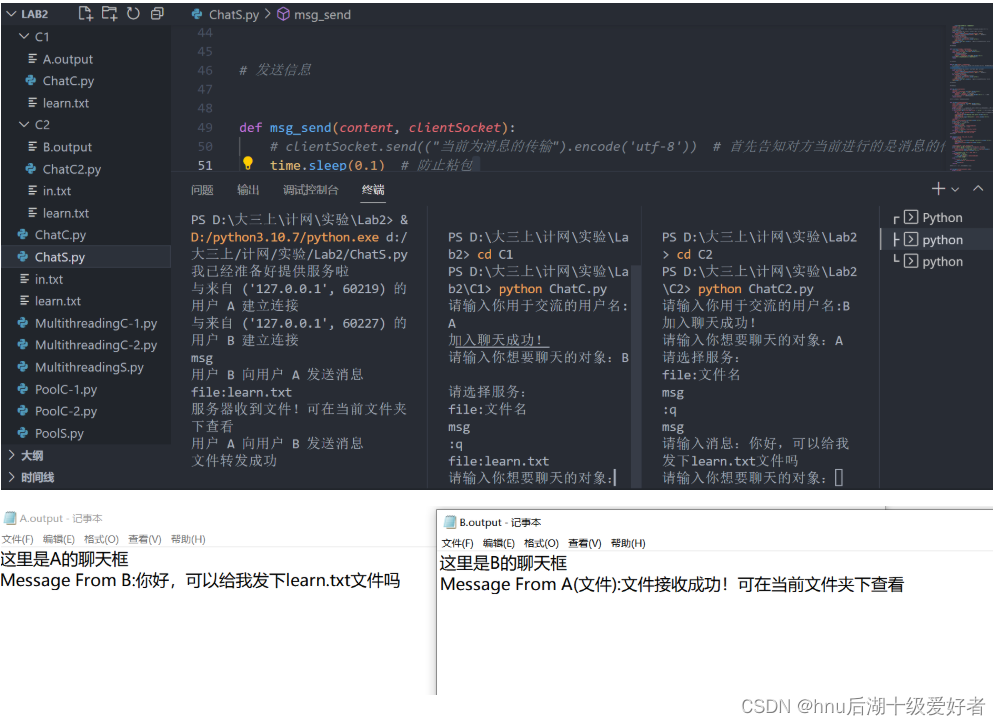
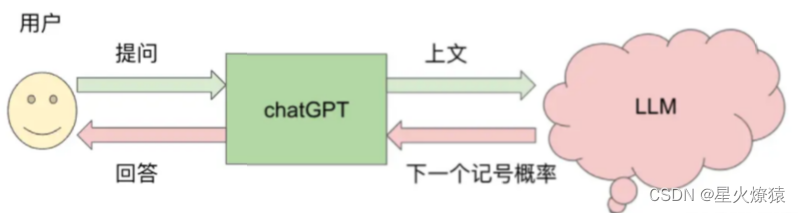
ChatGPT 背后的大语言模型有上亿个参数,有趣的是,用来训练 chatGPT 的语料大致也包含这么多个记号,所以差不多“记住”一个记号需要一个参数,看不到什么数据压缩的效果。为了方便开发者使用,又将这些参数归类到5个模型上,方便开发者使用。
五类模型
API 提供了更多的选择和参数, 用 ChatGPT 的时候是没法选后面的语言模型的, 而通过 API 你可以在目前的五种语言模型中选取:
• Ada
• Bargage
• Curie
• Davinci
• gpt-3.5-turbo
它们更多是一种人为的命名,并不是每一种模型负责不同类的交互。
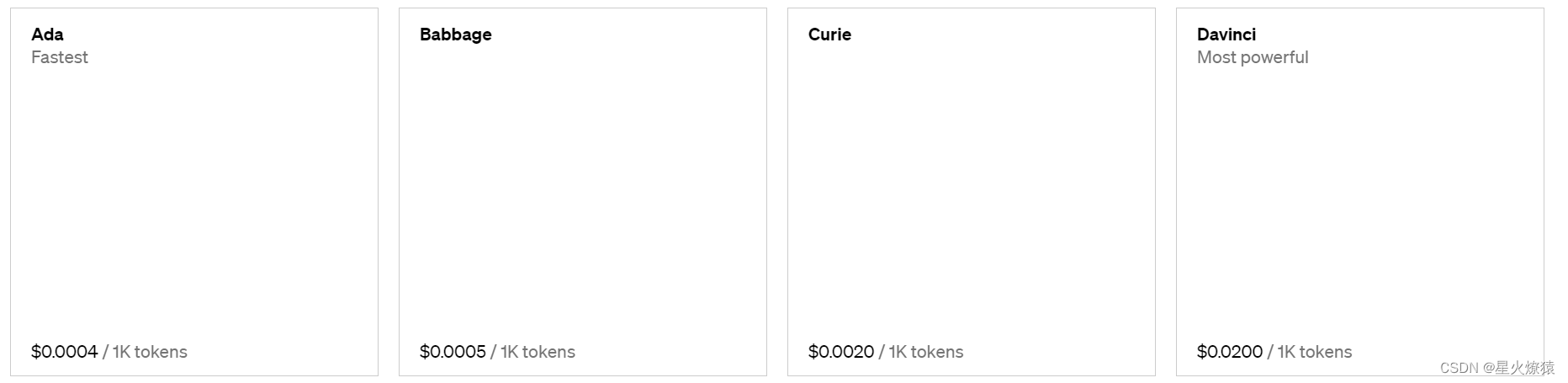
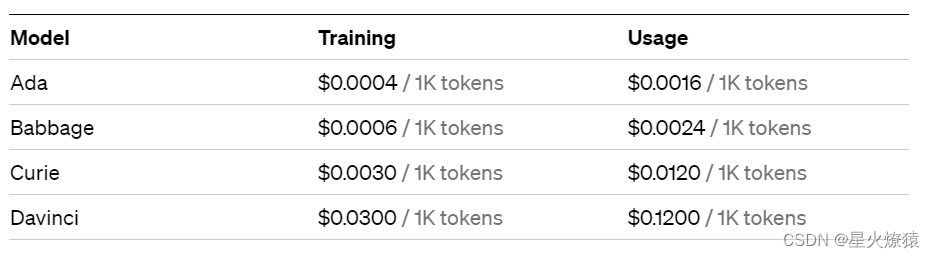
前四种模型的主要区别在于大小不同和训练数据不同,从 A 到 D 能力依次上升。 小的模型能力弱一些,但是速度快、计算成本低。API 是按流量收费的,不同的模型单价不同。所以不是说越强的模型越好 - 它们不但更贵,而且更慢。

这些都只是文字层面的语言模型,官方最近又新增了图像模型以及音频模型,大家可以去官网查看。
目前的定价,见 openai.com/pricing
API 优点
API 访问比网站访问更稳定可靠。没必要每月花 20 美元买升级版的 chatGPT plus,用 API 就够了,前提是你要懂一点编程。目前开放的 API 都不在服务器端保留状态。如果你想让机器记得前几轮说过的话,必须在发请求时把以前的对话内容再发一遍。
比如你以前跟机器已经唠了 4000 个标记了,又用 40 个标记问了一个附加问题,机器的回答就被限制在 4096 - 4000 - 40 = 56 个记号之内了。(这一点在playground页面上也可以看到。)这个太可怜了!
API 缺点
这些模型只能处理 4096 个记号的上下文,也就是说问题和答案加起来不能超过 4096 个记号,大约两千汉字。如果你想让 AI 帮你写情节连贯的长篇小说,现在还很难。
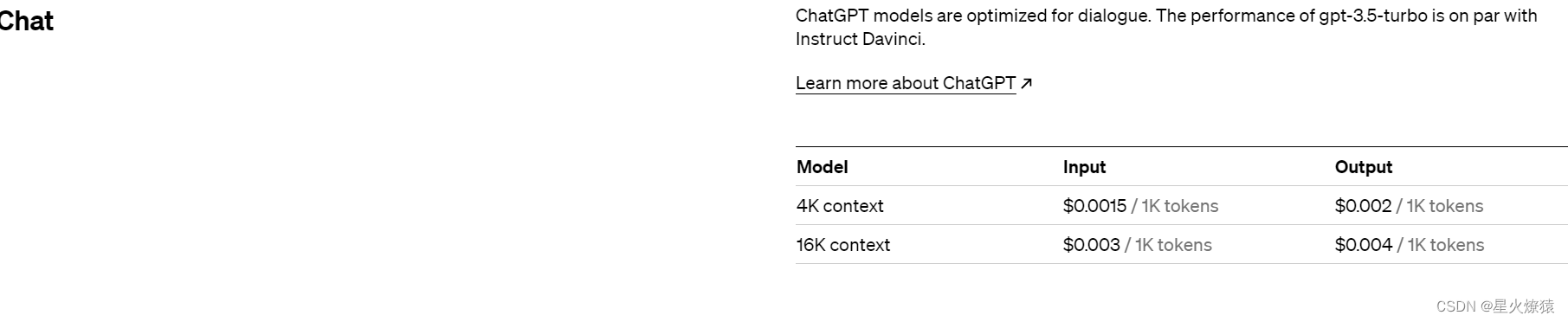
gpt-3.5-turbo 是优选
最后一种 gpt-3.5-turbo 模型是三月一号刚发布的,据说就是原汁原味的 chatGPT 用的模型。它的能力跟 Davinci 相似,但更适用于对话场景。据我测试比 Davinci 快得多,而价格只要 Davinci 的十分之一。