学习目标:
-
OpenAI API介绍
-
学习如何通过 Golang 使用 OpenAI 的 API
-
OpenAI 的常用的参数及其说明
-
了解OpenAI API 中令牌(tokens)
-
OpenAI API 提供了几个不同的终端点(endpoints)和模式(modes)
-
复杂和实际应用的例子
学习内容:
》OpenAI API介绍:
OpenAI API 是由 OpenAI 提供的一项服务,它允许开发者通过编程方式与 OpenAI 的强大自然语言处理模型进行交互。这些模型基于深度学习技术,可以用于各种任务,包括文本生成、自动摘要、翻译、对话生成等。
以下是关于 OpenAI API 的一些重要说明:
-
模型:OpenAI API 基于 GPT(生成式预训练)架构,提供了多个预训练的语言模型,如 GPT-3、GPT-2 等。这些模型在大规模数据集上进行了训练,以提供强大的文本生成和理解能力。
-
访问方式:你可以通过发送 HTTP 请求到 OpenAI API 来与模型进行交互。API 支持多种编程语言和开发环境,你可以使用 HTTP 客户端库发送请求,并通过 API 提供的终端点进行文本生成和其他任务。
-
授权和身份验证:在使用 OpenAI API 之前,你需要获得一个 API 密钥,并将其用作身份验证的凭证。通过在请求头中添加身份验证标头,你可以将 API 密钥传递给 OpenAI API 以进行身份验证。
-
请求和参数:你可以通过在请求体中提供适当的参数来指定所需的任务和模型行为。例如,你可以提供一个提示(prompt)来启动文本生成,或者指定生成的最大长度、温度等参数。
-
付费:OpenAI API 是一项付费服务。使用 API 进行文本生成和其他操作会消耗资源,并按照 OpenAI 的定价模型进行计费。确保在使用 API 之前了解相关的定价和费用信息。
请注意,OpenAI 可能会更新其 API 的功能、定价和可用性,并且可能有特定的使用规则和限制。建议你查阅 OpenAI 的官方文档以获取最新的 API 说明和相关细节。
》学习如何通过 Golang 使用 OpenAI 的 API:
若要在 Golang 中调用 OpenAI 的 API,你可以遵循以下步骤:
1. 安装所需的库:
首先,你需要安装 `go` 的 HTTP 请求库,例如 `net/http` 或 `github.com/go-resty/resty`。使用以下命令之一安装所需的库:
go get -u net/http
go get -u github.com/go-resty/resty
2. 获取 OpenAI API 密钥:
要获取 OpenAI API 密钥,你需要访问 OpenAI 的官方网站并注册一个账号。一旦注册成功,你可以按照以下步骤获得 API 密钥:
-
登录到 OpenAI 官方网站:打开 OpenAI 官方网站并使用你的注册账号登录。
-
导航到 API 部分:在登录后,导航到 OpenAI 网站的 API 部分。你可以查找和访问有关 API 的相关文档和信息。
-
创建 API 密钥:按照指示创建一个新的 API 密钥。这通常涉及提供你的身份验证信息和相关的开发项目信息。
-
获取 API 密钥:一旦你完成 API 密钥的创建,OpenAI 将向你提供一个唯一的 API 密钥。这个密钥通常是一个字符串,你需要在调用 OpenAI API 时使用它来进行身份验证。
请注意,上述步骤是一般性的指导,实际的过程可能因 OpenAI 官方网站的更新或变化而有所不同。对于中车或其他特定组织,你可能需要遵循他们的特定流程或与他们的相关团队联系以获取 OpenAI API 密钥。
3. 创建 HTTP 请求:
在 Golang 中,你可以使用上述库之一创建 HTTP 请求。以下是使用 `net/http` 库的示例代码:
package mainimport ("fmt""io/ioutil""net/http")func main() {apiKey := "YOUR_OPENAI_API_KEY"url := "https://api.openai.com/v1/engines/davinci-codex/completions"reqBody := `{"prompt": "Hello, world!","max_tokens": 10}`req, err := http.NewRequest("POST", url, bytes.NewBuffer([]byte(reqBody)))if err != nil {fmt.Println("Error creating request:", err)return}req.Header.Set("Authorization", "Bearer "+apiKey)req.Header.Set("Content-Type", "application/json")client := &http.Client{}resp, err := client.Do(req)if err != nil {fmt.Println("Error sending request:", err)return}defer resp.Body.Close()respBody, err := ioutil.ReadAll(resp.Body)if err != nil {fmt.Println("Error reading response:", err)return}fmt.Println("Response:", string(respBody))}在上述代码中,将 `YOUR_OPENAI_API_KEY` 替换为你自己的 OpenAI API 密钥。`reqBody` 定义了请求的 JSON 数据,其中包括提示和生成的最大令牌数。根据你的需求进行相应的更改。
4. 发送请求并处理响应:
通过调用 `client.Do(req)` 来发送请求,并使用 `ioutil.ReadAll` 读取响应的内容。你可以根据需要进行进一步的处理和解析。
请注意,这只是一个基本的示例代码,供你了解如何在 Golang 中调用 OpenAI 的 API。根据 OpenAI API 的具体要求和功能,你可能需要进行更多的配置和参数设置。确保查阅 OpenAI API 的文档以了解更多详细信息,并根据需要进行适当的调整。
》OpenAI 的常用的参数及其说明
1. OpenAI API 一些常用的参数及其说明:
1. `engine`(string):指定要使用的模型引擎,如 "davinci"、"curie" 或 "gpt-3.5-turbo"。不同的模型引擎具有不同的性能和能力。
2. `prompt`(string):用于提示模型生成文本的起始内容。可以提供一个或多个句子作为提示。
3. `max_tokens`(int):限制生成文本的最大令牌数。令牌是模型处理文本的基本单位。通过控制令牌数量,可以控制生成文本的长度。
4. `temperature`(float):控制生成文本的多样性。较高的温度值(大于1.0)会使输出更随机和多样化,而较低的温度值(小于1.0)会使输出更加确定和一致。
5. `max_response_length`(int):限制生成响应的最大长度(以字符为单位)。可以使用此参数截断生成的文本,以避免返回过长的响应。
6. `stop`(string 或数组):指定一个或多个字符串作为停止标记,当模型生成包含停止标记的文本时,会停止生成并返回结果。
7. `n`(int):指定要生成的候选响应数量。模型会生成多个可能的响应,并根据其概率进行排序。默认情况下,`n` 的值为1,即返回最高概率的响应。
这些是 OpenAI API 中常用的一些参数,用于控制模型的行为和生成的文本输出。你可以根据你的具体需求和任务进行适当的参数设置。请注意,不同的模型可能支持不同的参数,具体的参数设置和默认值可能会有所不同。建议查阅 OpenAI 的官方文档以获取最新的参数说明和相关细节。
2. Golang 调用 OpenAI API 并设置所有参数:
示例代码的方式进行操作:
package mainimport ("fmt""log""os"openai "github.com/openai/openai-go/v2"
)func main() {apiKey := "YOUR_API_KEY"openai.SetAPIKey(apiKey)engine := "davinci"prompt := "Once upon a time"maxTokens := 50temperature := 0.8maxResponseLength := 200stop := []string{"\n", "The end"}n := 5// 创建 OpenAI 请求req := &openai.CompletionRequest{Model: engine,Prompt: &prompt,MaxTokens: &maxTokens,Temperature: &temperature,MaxResponseSize: &maxResponseLength,Stop: stop,N: &n,}// 发送请求并获取响应client := openai.NewCompletionClient()response, err := client.CreateCompletion(req)if err != nil {log.Fatal(err)}// 解析响应并获取生成的文本generatedTexts := make([]string, len(response.Choices))for i, choice := range response.Choices {generatedTexts[i] = choice.Text}// 输出生成的文本fmt.Println(generatedTexts)
}在上述示例代码中,将 `YOUR_API_KEY` 替换为你自己的 OpenAI API 密钥。然后,你可以根据你的需求设置 `engine`、`prompt`、`maxTokens`、`temperature`、`maxResponseLength`、`stop` 和 `n` 参数的值。
使用 OpenAI 的 Go SDK(`openai-go`),我们可以创建一个 `CompletionRequest` 对象,并将参数设置为该对象的字段。然后,我们通过调用 `CreateCompletion()` 方法来发送请求并获取响应。
最后,我们解析响应并提取生成的文本,将其存储在 `generatedTexts` 切片中,并输出结果。
请确保在运行示例代码之前,已经使用 `go get` 命令安装了 `openai-go` 包。
》了解OpenAI API 中令牌(tokens):
在 OpenAI API 中,"token" 是指文本的最小处理单位。在语言模型中,文本会被分割成一系列的令牌,每个令牌可以是单词、标点符号、空格或其他字符。模型在生成文本时,实际上是逐个令牌地进行处理和预测。
了解令牌对于使用 OpenAI API 很重要,因为一些 API 参数(如 `max_tokens`)是以令牌数来计算的。通过控制令牌数量,你可以控制生成文本的长度。
你可以使用 OpenAI 的 `tiktoken` Python 包来计算文本中的令牌数量。以下是一个简单的示例代码:
import openai
from openai import tiktokenopenai.api_key = 'YOUR_API_KEY'text = "Hello, how are you?"token_count = tiktoken.count(text)
print("Token count:", token_count)将 `YOUR_API_KEY` 替换为你的 OpenAI API 密钥。在上述示例中,我们使用 `tiktoken.count()` 函数来计算给定文本中的令牌数量,并打印输出。
另外,OpenAI 还提供了一种查看令牌数量的在线工具,称为 "tiktoken"。你可以在 OpenAI 文档中找到 "tiktoken" 的链接,并使用它来计算任意文本的令牌数量。这个工具对于调试和检查令牌数量非常有用。
1.在 OpenAI API 中,令牌(tokens)的数量通常与 API 的费用相关:
每次调用 API 时,你会被计费的令牌数量取决于你请求的文本输入和模型生成的文本输出。
API 请求的费用基于两个因素:
1. 输入令牌:这是指你发送给 API 的文本输入的令牌数量。通常,较长的输入文本会占用更多的令牌,并因此产生更高的费用。
2. 输出令牌:这是指模型生成的响应文本的令牌数量。生成的文本越长,占用的令牌数量越多,因此会产生更高的费用。
你可以使用 OpenAI 的 `tiktoken` Python 包来计算文本中的令牌数量,以了解你的输入和输出所占用的令牌数量。根据 API 请求中使用的令牌数量,可以在 OpenAI 的定价页面上查看相应的费用详情。
请注意,不同模型和终端点的费用可能会有所不同。此外,OpenAI 可能会根据需求和市场情况调整定价和计费方式。因此,建议查阅 OpenAI 的官方文档和定价信息,以了解最准确和最新的计费细节。
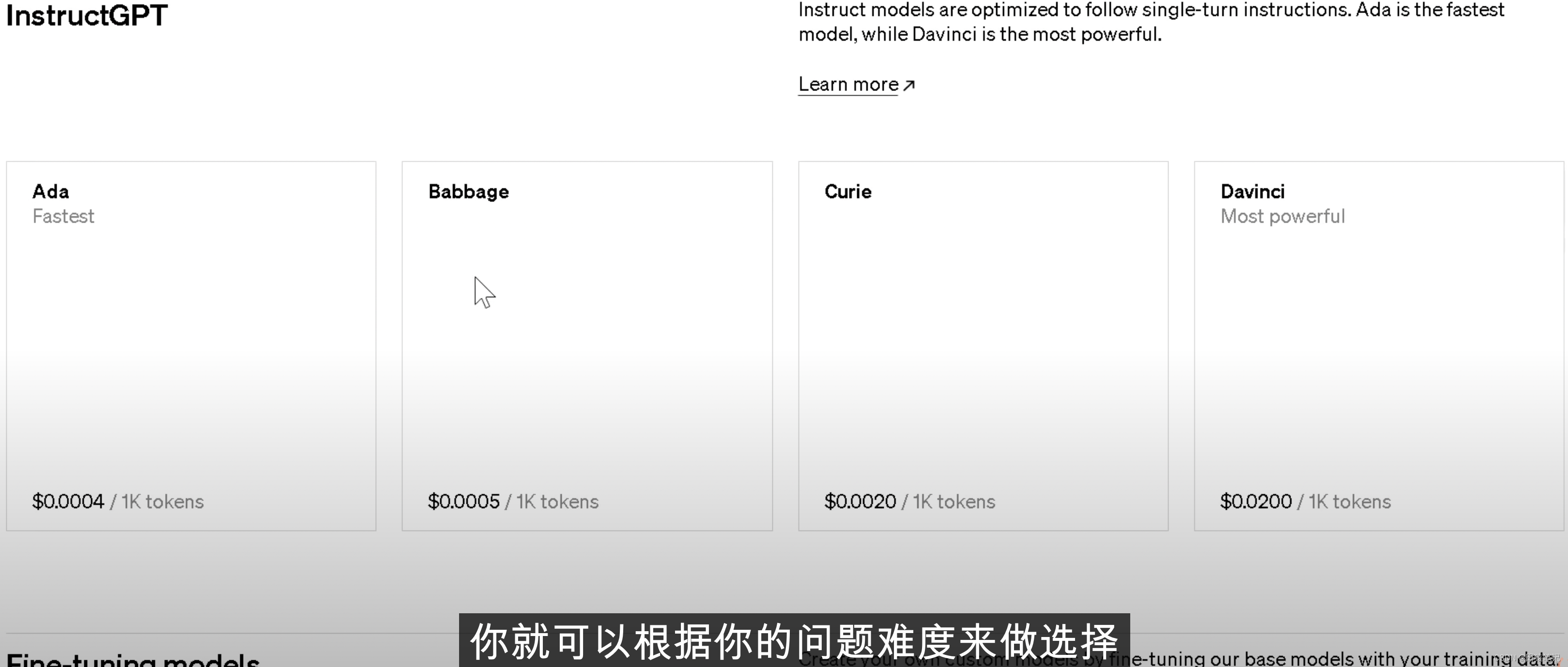
》OpenAI API 提供了几个不同的终端点(endpoints)和模式(modes):
OpenAI API 提供了几个不同的终端点(endpoints)和模式(modes),以满足不同的自然语言处理任务和需求。以下是一些常见的终端点和模式:
1. Completions 终端点:
`davinci`、`curie` 和 `babbage` 是 OpenAI API 中的三个主要模型,每个模型都可以用于生成文本的补全。你可以向 Completions 终端点发送请求,提供一个文本片段作为提示(prompt),然后模型会生成续写或补全的文本。
2. Chat 终端点:
Chat 模式适用于对话生成任务。你可以使用 Chat 终端点构建一个多轮对话系统,与模型进行交互并生成连续的对话响应。你可以提供一个历史消息列表,其中包含之前的对话内容和模型的响应,以便模型了解上下文并生成适当的回复。
OpenAI API 的 Chat 终端点目前提供了三个不同的模型,它们分别是:
1). `gpt-3.5-turbo`:这是 OpenAI API 提供的最新的、最强大的 Chat 模型。它基于 GPT-3.5 架构,具有出色的对话生成能力。该模型在多个任务和应用中表现出色,能够生成连贯、准确的回复。
2). `davinci`:这是之前的 Chat 模型,基于 GPT-3 架构。尽管已经有了更先进的模型(如 gpt-3.5-turbo),但 `davinci` 仍然可以用于对话生成,并提供高质量的回复。
3). `curie`:这是 GPT-3.5-turbo 之前的 Chat 模型,它基于 GPT-3.5 架构。虽然不如 gpt-3.5-turbo 强大,但 `curie` 仍然是一个有效的对话生成模型,并在多个应用中发挥作用。
这些 Chat 模型在不同的对话生成任务中具有广泛的应用,并可以根据你的具体需求选择适当的模型。请注意,随着 OpenAI 不断改进和发布新的模型,可能会有新的模型可用。建议查阅 OpenAI 的官方文档以获取最新的模型列表和相关细节。
3. Translation 终端点:
OpenAI API 还提供了用于机器翻译的终端点。你可以发送一个包含待翻译文本的请求,指定源语言和目标语言,模型将返回翻译后的文本。
这些终端点和模式是 OpenAI API 提供的一些常见选项,用于不同的自然语言处理任务。你可以根据你的需求选择适当的终端点和模式,并根据 API 文档提供的指南来构建请求和解析响应。
请注意,OpenAI 可能会在未来更新和添加更多的终端点和模式,以提供更多功能和灵活性。确保查阅 OpenAI 的官方文档以获取最新的终端点和模式信息,并了解如何正确使用它们。
4. Golang 调用 OpenAI API 的不同终端点和模式:
你需要构建适当的 HTTP 请求,并发送到相应的终端点。以下是一个示例代码,演示如何在 Golang 中调用 OpenAI API 的 Completions 终端点和 Chat 终端点。
首先,确保你已经安装了 Golang 的 HTTP 请求库,例如 `net/http`。
1. Completions 终端点示例代码:
package mainimport ("bytes""encoding/json""fmt""io/ioutil""net/http"
)func main() {apiKey := "YOUR_OPENAI_API_KEY"url := "https://api.openai.com/v1/engines/davinci-codex/completions"reqBody := map[string]interface{}{"prompt": "Once upon a time","max_tokens": 50,}reqJSON, err := json.Marshal(reqBody)if err != nil {fmt.Println("Error marshaling request:", err)return}req, err := http.NewRequest("POST", url, bytes.NewBuffer(reqJSON))if err != nil {fmt.Println("Error creating request:", err)return}req.Header.Set("Authorization", "Bearer "+apiKey)req.Header.Set("Content-Type", "application/json")client := &http.Client{}resp, err := client.Do(req)if err != nil {fmt.Println("Error sending request:", err)return}defer resp.Body.Close()respBody, err := ioutil.ReadAll(resp.Body)if err != nil {fmt.Println("Error reading response:", err)return}fmt.Println("Response:", string(respBody))
}在上述代码中,将 `YOUR_OPENAI_API_KEY` 替换为你自己的 OpenAI API 密钥。`reqBody` 定义了请求的 JSON 数据,包括提示(prompt)和生成的最大令牌数(max_tokens)。根据你的需求进行相应的更改。
2. Chat 终端点示例代码:
package mainimport ("bytes""encoding/json""fmt""io/ioutil""net/http"
)func main() {apiKey := "YOUR_OPENAI_API_KEY"url := "https://api.openai.com/v1/chat/completions"reqBody := map[string]interface{}{"messages": []map[string]string{{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Who won the world series in 2020?"},},}reqJSON, err := json.Marshal(reqBody)if err != nil {fmt.Println("Error marshaling request:", err)return}req, err := http.NewRequest("POST", url, bytes.NewBuffer(reqJSON))if err != nil {fmt.Println("Error creating request:", err)return}req.Header.Set("Authorization", "Bearer "+apiKey)req.Header.Set("Content-Type", "application/json")client := &http.Client{}resp, err := client.Do(req)if err != nil {fmt.Println("Error sending request:", err)return}defer resp.Body.Close()respBody, err := ioutil.ReadAll(resp.Body)if err != nil {fmt.Println("Error reading response:", err)return}fmt.Println("Response:", string(respBody))
}在上述
代码中,同样需要将 `YOUR_OPENAI_API_KEY` 替换为你自己的 OpenAI API 密钥。`reqBody` 定义了请求的 JSON 数据,其中 `messages` 列表包含了对话的历史消息。你可以根据需要添加更多的消息。
这些示例代码演示了如何使用 Golang 调用 OpenAI API 的不同终端点和模式。你可以根据你的具体需求修改这些代码,并添加适当的错误处理和其他逻辑。记得查阅 OpenAI API 的官方文档,了解请求和响应的详细说明。
》复杂和实际应用的例子:
例子1:
如果你想修改代码以分析指定评论的情感,并将评论内容和情感分析结果打印出来,可以按照以下方式修改代码:
import openaidef analyze_sentiment(comment):# 设置OpenAI API密钥openai.api_key = 'YOUR_API_KEY'# 调用OpenAI GPT-3.5模型进行情感分析response = openai.Completion.create(engine='text-davinci-003',prompt=f"分析以下评论的情感:{comment}\n情感分析结果",max_tokens=1,temperature=0,n=1,stop=None,logprobs=None)# 解析API响应,获取情感分析结果sentiment = response.choices[0].text.strip()return sentiment# 要分析的评论
comment = "这部电影太精彩了!"# 进行情感分析
result = analyze_sentiment(comment)
print(f"评论: {comment}")
print(f"情感分析结果: {result}")这样修改后,代码将使用指定的评论进行情感分析,并打印出评论内容和情感分析结果。请确保将`YOUR_API_KEY`替换为您的OpenAI API密钥。
例子2:
当使用多个 `#` 符号时,它们可以用于将输入文本分为不同的部分,从而影响模型的生成行为。下面是一个示例:
import openaidef generate_text(prompt):openai.api_key = 'YOUR_API_KEY'response = openai.Completion.create(engine='text-davinci-003',prompt=prompt,max_tokens=50,temperature=0.8,n=1,stop=None,logprobs=None)generated_text = response.choices[0].text.strip()return generated_textprompt = """
输入一句话,让模型继续生成下一句:
#在一个遥远的星系中,
#在宇宙的尽头,
#人类探险家发现了一颗神秘的行星。
"""output = generate_text(prompt)
print(output)在上述示例中,我们使用了三个 `#` 符号将输入文本分为三个部分。这些部分是:在一个遥远的星系中, 在宇宙的尽头, 人类探险家发现了一颗神秘的行星。模型将从最后一个 `#` 符号之后开始生成文本。例如,生成的文本可能是:
人类探险家发现了一颗神秘的行星。行星上存在着奇特的生物,它们拥有超凡的智慧和力量。人类开始探索这个神秘的行星,希望揭开它的秘密。
通过使用多个 `#` 符号,我们可以对模型的生成行为进行一定的控制和引导,从而生成符合我们期望的文本。请注意,示例中的生成结果是根据模型的行为进行估计的,实际结果可能因模型的训练和数据等因素而有所不同。
例子3:
在您提供的例子中,使用了三个 `#` 符号将输入文本分为三个部分。第一个部分是 "分析以下评论的情感:",第二个部分是评论的内容 "这部电影太精彩了!",第三个部分是 "情感分析结果:"。
这种分割的结构可以帮助模型理解您的意图和输入的组织方式。在进行情感分析时,模型将根据给定的评论内容生成与情感相关的文本结果。
以下是一个示例代码,使用您提供的 `prompt` 进行情感分析:
import openaidef analyze_sentiment(comment):openai.api_key = 'YOUR_API_KEY'response = openai.Completion.create(engine='text-davinci-003',prompt=comment,max_tokens=1,temperature=0,n=1,stop=None,logprobs=None)sentiment = response.choices[0].text.strip()return sentimentprompt = """
分析以下评论的情感:
###
这部电影太精彩了!
###
情感分析结果:
"""result = analyze_sentiment(prompt)
print(result)在上述代码中,我们使用了您提供的 `prompt` 作为情感分析的输入,并将结果打印出来。请确保将 `YOUR_API_KEY` 替换为您的有效的 OpenAI API 密钥。
注意:在这个例子中,模型将直接对整个 `prompt` 进行情感分析,并生成一个与情感相关的文本结果。具体的情感分析结果将取决于模型的训练和数据,以及可能的后处理步骤。
原创比较不容易,希望大家能点点赞,对我的支持。你们的支持,就是我的动力.
未经授权禁止转载