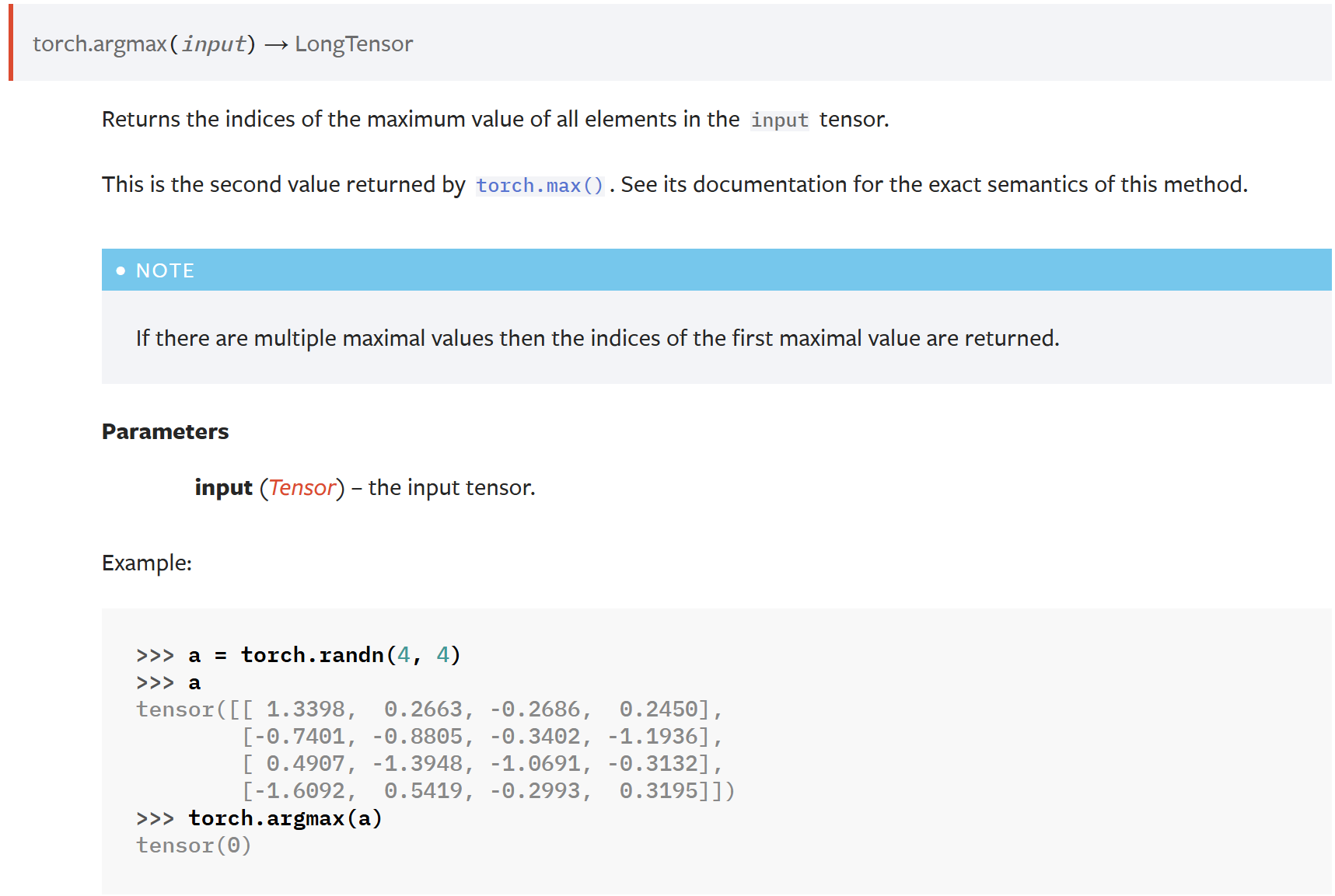
近期,澎峰科技与沐曦完成了对PerfXLM(推理引擎)、PerfXCloud(大模型服务平台)与沐曦的曦云系列通用计算GPU的联合测试,测试结果表明PerfXLM、PerfXCloud软件与沐曦GPU产品实现了全面兼容。

-
PerfXLM高性能大模型推理引擎与沐曦GPU硬件平台完成适配,PerfXLM采用云边端一体架构,支持云端和本地大模型推理。经过双方联合测试,PerfXLM对沐曦GPU硬件平台的兼容性、稳定性和可靠性上取得极大领先,部分指标实现了对NVIDIA A100的反超。PerfXLM 针对部分大模型的计算性能优化成果堪称卓越,多个主流模型在在该平台的推理总吞吐速度实现了最高达到50%的性能提升。标志着双方在CUDA生态兼容上实现再次突破。

-
PerfXCloud大模型服务平台与沐曦的GPU硬件平台完成适配,并完成了超80种大模型的推理、微调(包括Qwen系列、Yi-Coder系列、DeepSeek系列、Llama系列、ChatGLM系列等)支持,兼容性在国内处于领先地位。未来,双方将不断丰富模型仓库,以满足多样化的应用需求,为用户提供更优质和便捷的模型服务,帮助智算中心升级进化为超级AI Foundry。

此次合作,为国产计算软硬融合和产业链合作建立了示范。未来,双方将以市场需求为导向,共同探索更多可能性,为实现大模型人工智能技术的自主可控和可持续发展贡献力量。